收藏!改善TensorFlow模型的4种方法-你需要了解的关键正则化技术(2)
上一篇文章和同学们分享了两种方法,今天我们继续分享另外两种方法。
Batch Normalization
批处理规范化背后的主要思想是,在我们的案例中,我们通过使用几种技术(sklearn.preprocessing.StandardScaler)来规范化输入层,从而提高了模型性能,因此,如果输入层受益于规范化,为什么不规范化隐藏层,这将进一步改善并加快学习速度。
要将其添加到TensorFlow模型中,只需在层后添加 tf.keras.layers.BatchNormalization()。
让我们看一下代码。
model9 = Sequential([
Dense(512, activation='tanh', input_shape = X_train[0].shape),
Dense(512//2, activation='tanh'),
tf.keras.layers.BatchNormalization(),
Dense(512//4, activation='tanh'),
Dense(512//8, activation='tanh'),
Dense(32, activation='relu'),
Dense(3, activation='softmax')
])
model9.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['acc', 'mse'])
hist9 = model9.fit(X_train, y_train, epochs=350, validation_data=(X_test,y_test), verbose=2)
在这里,如果您注意到我已经删除了batch_size的选项。这是因为仅在将tf.keras.BatchNormalization() 用作正则化时添加了batch_size参数 ,这会导致模型的性能非常差。我试图在互联网上找到原因,但找不到。如果您确实想在训练时使用batch_size,也可以将优化器从sgd 更改 为 rmsprop 或 adam 。
训练后,让我们评估模型。
loss9, acc9, mse9 = model9.evaluate(X_test, y_test)
print(f"Loss is {loss9},\nAccuracy is {acc9 * 100},\nMSE is {mse9}")

1个批处理归一化验证集的准确性不如其他技术。让我们来绘制损失和acc以获得更好的直觉。

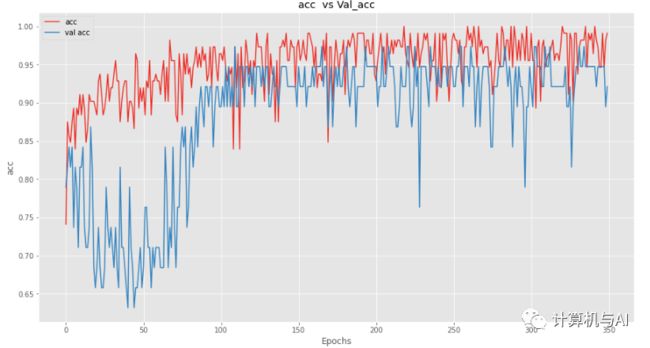
在这里,我们可以看到我们的模型在验证集和测试集上的表现不佳。让我们向所有层添加归一化以查看结果。
model11 = Sequential([
Dense(512, activation='tanh', input_shape = X_train[0].shape),
tf.keras.layers.BatchNormalization(),
Dense(512//2, activation='tanh'),
tf.keras.layers.BatchNormalization(),
Dense(512//4, activation='tanh'),
tf.keras.layers.BatchNormalization(),
Dense(512//8, activation='tanh'),
tf.keras.layers.BatchNormalization(),
Dense(32, activation='relu'),
tf.keras.layers.BatchNormalization(),
Dense(3, activation='softmax')
])
model11.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['acc', 'mse'])
hist11 = model11.fit(X_train, y_train, epochs=350, validation_data=(X_test,y_test), verbose=2)
让我们评估它。
loss11, acc11, mse11 = model11.evaluate(X_test, y_test)
print(f"Loss is {loss11},\nAccuracy is {acc11 * 100},\nMSEis {mse11}")

通过在每层中添加批处理规范化,我们获得了良好的准确性。让我们绘制Loss和准确率。

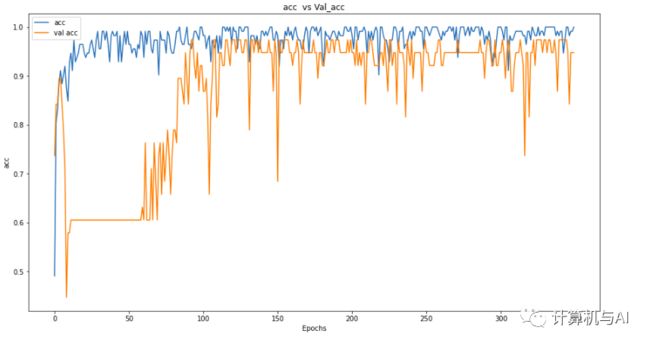
通过绘制准确度和损失,我们可以看到我们的模型在训练集上的表现仍优于验证集,但是在性能上却有所提高。
Dropout
避免正则化的另一种常见方法是使用Dropout技术。使用dropout背后的主要思想是,我们基于某种概率随机关闭层中的某些神经元。
让我们在Tensorflow中对其进行编码。
以前所有的导入都是相同的,我们只是在这里添加一个额外的导入。
为了实现DropOut,我们要做的就是从tf.keras.layers中添加一个 Dropout 层 并在其中设置一个dropout速率。
import tensorflow as tf
model7 = Sequential([
Dense(512, activation='tanh', input_shape = X_train[0].shape),
tf.keras.layers.Dropout(0.5), #dropout with 50% rate
Dense(512//2, activation='tanh'),
Dense(512//4, activation='tanh'),
Dense(512//8, activation='tanh'),
Dense(32, activation='relu'),
Dense(3, activation='softmax')
])
model7.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['acc', 'mse'])
hist7 = model7.fit(X_train, y_train, epochs=350, batch_size=128, validation_data=(X_test,y_test), verbose=2)
训练后,让我们在测试集中对其进行评估。
loss7, acc7, mse7 = model7.evaluate(X_test, y_test)
print(f"Loss is {loss7},\nAccuracy is {acc7 * 100},\nMSE is {mse7}")

哇,我们的结果非常有前途,我们的测试集执行了97%。让我们画出Loss和准确率,以获得更好的直觉。
plt.figure(figsize =(15,8))
plt.plot(hist7.history ['loss'],label ='loss')
plt.plot(hist7.history ['val_loss'],label ='val loss' )
plt.title(“ Loss vs Val_Loss”)
plt.xlabel(“
Epochs ”)plt.ylabel(“ Loss”)
plt.legend()
plt.show()
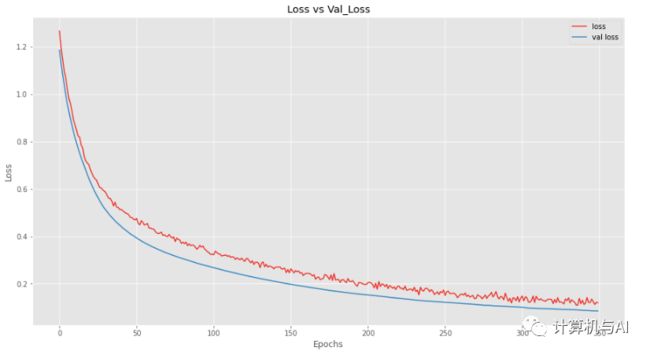
在这里,我们可以看到,与训练数据相比,我们的模型在验证数据上的表现更好,这是个好消息。
现在让我们绘制准确率。
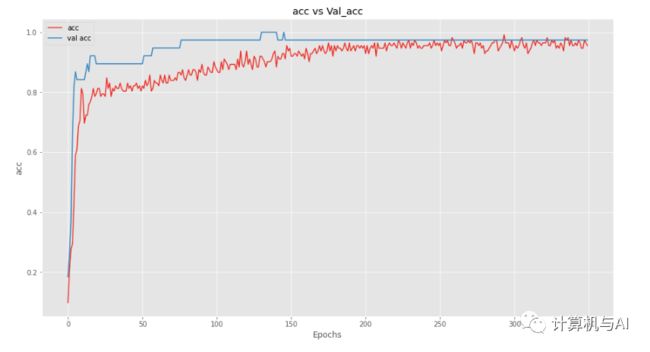
我们可以看到该模型也很好,并且不会过度拟合数据集。
最后:
本文简要介绍了如何在Tensorflow中使用不同的技术。如果您缺乏理论,我建议您在Coursera的“深度学习专业化”课程2和3中学习有关正则化的更多信息。
您还必须学习何时使用哪种技术,以及何时以及如何结合使用不同的技术,才能获得真正卓有成效的结果。
希望您现在对如何在Tensorflow 2中实现不同的正则化技术有所了解。