kimera论文阅读
文章目录
-
- 功能构成:
- Kimera线程
-
- A. Kimera-VIO:
- B. Kimera-RPGO:
- C. Kimera-Mesher:
- D. Kimera-Semantics:
- E.调试工具
功能构成:
Kimera包括四个关键模块:
Kimera-VIO的核心是基于gtsam的VIO方法[45],使用IMUpreintegration和无结构视觉因子[27],并在EuRoC数据集上实现了最佳性能[19];
Kimera-RPGO:一种鲁棒姿态图优化(RPGO)方法,利用现代技术进行异常值拒绝[46]。Kimera-RPGO增加了一个鲁棒性层,避免了由于感知混叠而导致的SLAM故障,并减轻了用户耗时的参数调整;
Kimera-Mesher:一个计算快速逐帧和多帧正则化3D网格的模块,以支持避障。该网格建立在作者和其他团队先前的算法基础上[43],[47]-[49];
Kimera-Semantics:一个使用体积方法构建较慢但更精确的全局3D网格的模块[28],并使用2D逐像素语义分割对3D网格进行语义注释。
Kimera线程
线程图2显示了Kimera的结构。Kimera将立体帧和高速率惯性测量作为输入,并返回(i)以IMU速率进行高度精确的状态估计,(ii)全球一致的轨迹估计,以及(iii)环境的多个网格,包括快速局部网格和全局语义注释网格。Kimera是高度并行化的,并使用四个线程以不同的速率(例如IMU,帧,关键帧)容纳输入和输出。在这里,我们按线程描述体系结构,而每个模块的描述将在下面的部分中给出。第一个线程包括Kimera-VIO前端(Section II-A),它获取立体图像和IMU数据,并输出特征轨迹和预集成IMU测量值。前端还发布IMU-rate状态估计。第二个线程包括(i)输出优化状态估计的Kimera-VIO后端,以及(ii)计算低延迟(< 20ms)每帧和多帧3D网格的Kimera-Mesher (Section ii - c)。这两个线程允许创建图2(b)中的每帧网格(也可以像图2©中那样带有语义标签),以及图2(d)中的多帧网格。后两个线程的运行速度较慢,旨在支持低频功能,如路径规划。第三个线程包括Kimera-RPGO (Section II-B),这是一种强大的PGO实现,可以检测环路闭合,拒绝异常值,并估计全局一致的轨迹图2(a))。最后一个线程包括Kimera-Semantics (Section II-D),它使用密集的立体和二维语义标签来获得精细的度量语义网格,使用Kimera-VIO的姿态估计。

A. Kimera-VIO:

视觉惯性里程计模块Kimera-VIO实现了[27]中提出的基于关键帧的最大后验视觉惯性估计器。在我们的实现中,估计器可以根据指定的时间范围执行完全平滑或固定滞后平滑;
![]()
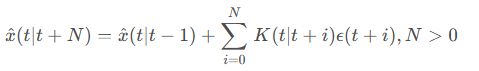
我们通常使用后者来限定估计时间。我们还将[27]扩展到单目和立体框架。Kimera-VIO包括一个(视觉和惯性)前端,负责处理原始传感器数据,以及一个后端,融合处理后的测量数据,以获得传感器状态的估计(即姿态、速度和传感器偏差)。1) VIO前端:我们的IMU前端执行非流形预积分[27],从原始IMU数据中获得两个连续关键帧之间相对状态的紧凑预积分测量。

视觉前端检测Shi-Tomasi角[51],(Shi-Tomasi角点检测是Harris的改进)


使用lucas - kanade跟踪器[52]跨帧跟踪它们,


找到左右立体匹配,并执行几何验证。我们使用5点RANSAC[53]进行单目验证,使用3点RANSAC[54]进行立体验证;代码还提供了使用IMU旋转和使用2点[55]和1点RANSAC分别执行单声道和立体声验证的选项。特征检测、立体匹配和几何验证在每个关键帧执行,而我们只跟踪中间帧的特征。
- VIO后端:在每个关键帧,预集成IMU和视觉测量被添加到固定滞后平滑(因子图),这构成了我们的VIO后端。我们使用预集成IMU模型和无结构视觉的模型[27]。因子图采用GTSAM[57]中的iSAM2[56]求解。在每次iSAM2迭代中,无结构视觉模型使用DLT估计观察到的特征的3D位置[58],并从VIO状态中解析地消除相应的3D点[59]。在消除之前,退化点(即摄像机后面或没有足够视差进行三角测量的点)和异常点(即重投影误差较大的点)被去除,提供了额外的鲁棒性层。最后,使用GTSAM将落在平滑视界之外的状态边缘化。

Simple-LIO-SAM——(七)GTSAM快速入门 - 知乎 (zhihu.com)
B. Kimera-RPGO:
鲁棒姿态图优化模块Kimera-RPGO负责(i)检测当前和过去关键帧之间的循环闭合,以及(ii)使用鲁棒PGO计算全局一致的关键帧姿态。1)环闭包检测**:环闭包检测依赖于DBoW2库**[60],使用词袋表示快速检测假定的环闭包。对于每个假定的环闭包,我们使用单声和立体几何验证(如第II-A节所述)拒绝异常环闭包,并将剩余的环闭包传递给鲁棒PGO求解器。注意,由于感知混叠,最终的循环闭包仍然可能包含异常值(例如,位于建筑物不同楼层的两个相同房间)。2)鲁棒PGO:该模块在GTSAM中实现,包括一种现代的异常值抑制方法,增量一致测量集最大化(PCM)[46],我们为单机器人和在线设置量身定制。我们分别存储里程计边缘(Kimera-VIO产生)和闭环(闭环检测产生);每次执行PGO时,我们首先使用改进版本的PCM选择最大的一致环路闭包集,然后对包含里程计和一致环路闭包的姿态图执行GTSAM。




PCM是针对多机器人的情况设计的,它只检查机器人间的闭环是否一致。我们开发了一个PCM的c++实现,它**(i)在环路闭包上增加了里程表一致性检查,(ii)增量地更新一致性测量集,以支持在线操作。里程计检查验证每个回路关闭(例如图2(a)中的l1)与里程计(图中红色部分)是一致的:在没有噪声的情况下,里程计和环路l1形成的沿周期的位姿必须构成恒等。与PCM一样,我们标记为异常值循环,其中沿周期累积的误差与使用卡方检验的测量噪声不一致**。如果在当前时间t检测到的环路通过了里程计检查,我们测试它是否与之前的环路闭包两两一致,如46。虽然PCM[46]从头开始构建邻接矩阵A E RL×L以跟踪成对一致的循环(其中L是检测到的循环闭包的数量),但我们通过增量构建矩阵A来实现在线操作。每次检测到一个新的循环时,我们向矩阵A添加一行和一列,并且只针对之前的循环测试新的循环。最后,我们使用[61]的快速最大团实现来计算最大的一致循环闭包集。一致的测量集被添加到姿态图中(连同里程计),并使用高斯-牛顿法进行优化。
C. Kimera-Mesher:
3D网格重建Kimera-Mesher可以快速生成两种类型的3D网格:
(i)每帧3D网格,(ii)在VIO固定滞后平滑中跨越关键帧的多帧3D网格。1)每帧网格:与[47]一样,我们首先对当前关键帧中成功跟踪的2D特征(由VIO前端生成)执行2D Delaunay三角剖分。(testMesher.cpp)

然后,我们使用VIO后端的3D点估计,将2D Delaunay三角剖分反向投影以生成3D网格(图2(b))。虽然逐帧网格旨在提供低延迟障碍物检测,但我们还提供了通过使用2D标签对网格进行纹理化来对结果网格进行语义标记的选项(图2©)。
2)多帧网格:多帧网格将VIO后退地平线上收集的每帧网格融合为单个网格(图2(d))。每帧和多帧3D网格都被编码为一个顶点位置列表,以及一个顶点id的三元组列表来描述三角形面。假设我们在时间t - 1已经有了一个多帧网格,对于我们生成的每个新的每帧3D网格(在时间t),我们循环遍历它的顶点和三元组,并添加在每帧网格中但在多帧网格中缺失的顶点和三元组。然后我们循环遍历多帧网格顶点,并根据最新的VIO后端估计更新它们的3D位置。最后,我们删除与在VIO时间范围之外观察到的旧特征相对应的顶点和三元组。其结果是在当前VIO时间范围内生成跨越关键帧的最新3D网格。如果在网格中检测到平面,则在VIO 后端中添加规则因子[47],这导致VIO和mesh之间的紧密耦合正则化,参见[47]了解更多细节。
D. Kimera-Semantics:
度量-语义分割我们采用了[28]中引入的捆绑光线投射技术来(i)构建精确的全局3D网格(覆盖整个轨迹),以及(ii)对网格进行语义注释。
1)全局网格:我们的实现建立在Voxblox[28]的基础上,并使用基于体素的(TSDF)模型来过滤噪声并提取全局网格。在每个关键帧,我们使用密集立体(半全局匹配[62])

从当前立体对中获得三维点云。然后我们使用Voxblox[28]应用捆绑光线投射,使用[28]中讨论的“快速”选项。这个过程在每个关键帧重复,并产生一个TSFD,从中使用行进立方体(marching cubes)提取网格[63]。
2)语义标注:Kimera-Semantics使用二维语义标注的图像(在每个关键帧产生)对全局网格进行语义标注;二维语义标签可以使用现成的工具获得,用于像素级二维语义分割,例如深度神经网络[7][9],[64]-[69]或经典的基于mrf的方法[70]。为此,在捆绑的光线投射过程中,我们还传播语义标签。使用二维语义分割,我们给密集立体图像产生的每个三维点附加一个标签。然后,对于bundle raycasting中的每一束射线,我们根据束中观察到的标签的频率建立一个标签概率向量。然后,我们仅在TSDF截断距离内(即靠近表面)沿射线传播此信息以节省计算。换句话说,我们省去了更新“空”标签概率的计算工作。当沿着射线遍历体素时,我们使用贝叶斯更新来更新每个体素的标签概率,类似于[17]。在绑定语义光线投射之后,每个体素都有一个标签概率向量,我们从中提取最可能的标签。度量语义网格最后使用行军立方体(marching cubes)提取[63]。所得网格的精度明显高于Section II-C的多帧网格,但计算速度较慢(≈0.1s,参见Section III-D)。

E.调试工具
虽然由于篇幅原因我们限制了讨论,但值得一提的是,Kimera还提供了一套评估工具,用于调试、可视化和对VIO、SLAM和度量语义重构进行基准测试。Kimera包括一个持续集成服务器(Jenkins),它可以断言代码的质量(编译、单元测试),但也可以使用evo在EuRoC的数据集上自动评估Kimera- vio和KimeraRPGO[71]。此外,我们提供Jupyter notebook来可视化中间VIO统计数据(例如,特征轨迹的质量,IMU预整合误差),以及使用Open3D自动评估3D重建的质量[72]。