第3章 你应该如何运行程序 (可选,Shell、IDE介绍,推荐看一下)
本章会有一些代码示例,但是请不要追寻这些语句的意思,这只是演示交互式的一个示例,之后的章节自然会介绍到相关语句。
我们已经介绍了许多执行Python程序的方式。本章中所讨论的都是当前常用的程序启动技术。与此同时,你将学习如何交互的输入程序代码,以及如何将代码保存至一个文件从而以你喜欢的方式运行:可以在系统命令行中运行,点击图标运行,模块导入,exec调用,以及IDLE GUI中的菜单选项等。
交互式命令行模式
我们从这一节开始介绍交互式编程的基础知识,因为它是我们运行代码的最初体验。
开始一个交互式会话
也许最简单的运行Python程序的办法就是在Python交互式命令行中输入这些程序,他们有时也称为交互式提示模式。
https://www.python.org/downloads/windows/
2021/1/19 发行版 391,测试版310a4,电信下载会很慢,联通速度很快,这与运营商国外端口策略有关
391:链接:https://pan.baidu.com/s/1SSWsOZA-xSs4ELfU49nVwA 提取码:21mc
Python版本的选择,建议下载发布版,而不是测试版,原因是Python是一个生态,里面包含很多扩展库和第三方库,使用pip安装,有时候测试版的内容并没有与现有的库完全兼容,
这事,即便最新的发布版,也可能会有这样的情况!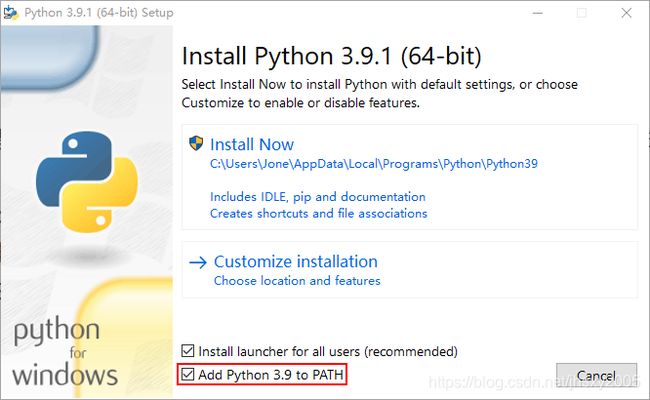 建议勾选添加路径到全局变量,安装程序会自动添加
建议勾选添加路径到全局变量,安装程序会自动添加
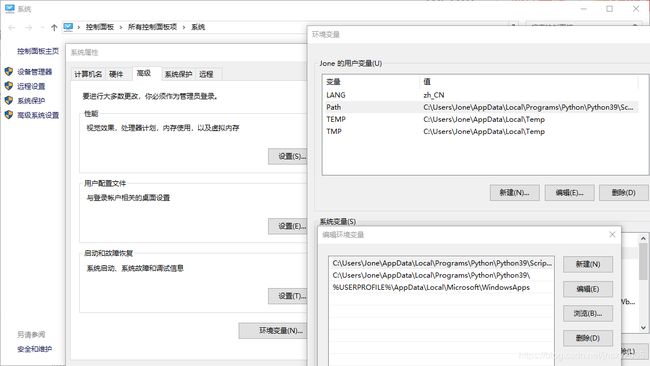 看到添加了Python39的目录和其下的脚本目录
看到添加了Python39的目录和其下的脚本目录

pip就在脚本目录中,随着安装的组件越来越多,脚本目录中会有更多的文件,例如jupyter、ipython等

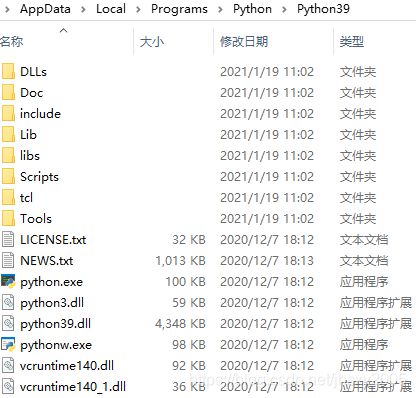 在这个版本中,26.8MB的安装包,安装后大小是89.6MB,绝大部分是pyc文件,少量.h文件以及其他文件,包含vc运行时、tk库、tcl库、加解密库、网络协议库、python解释器,总之依赖就这些。
在这个版本中,26.8MB的安装包,安装后大小是89.6MB,绝大部分是pyc文件,少量.h文件以及其他文件,包含vc运行时、tk库、tcl库、加解密库、网络协议库、python解释器,总之依赖就这些。
 预安装是安装了所有的东西,但文档是英文的,可以专门去下载中文文档
预安装是安装了所有的东西,但文档是英文的,可以专门去下载中文文档
https://docs.python.org/zh-cn/3/download.html
链接:https://pan.baidu.com/s/1N6U-G8nutDNv5Mr6d0Gy8g 提取码:06qd
但我的经验是,既然遇到这本书,就不要先去看文档了,文档里有巨量的内容,虽然pdf中有个简易的语言手册tutorial.pdf,网上的中文教程站也都是照那个抄的。而完整文档library.pdf真的是看到就头大,所以如果没有机会看到这本书,就去看网上学习站的基础教程吧!
pip:Python安装组建很简单,一个pip就能完成,但直接使用网速很慢,于是给出国内镜像站
python 清华镜像:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lib_name
tkinter & IDLE,之前提到过的GUI编程库和Python自带的编辑环境
test suite:测试组件,应该是类似于IDE的跟踪测试,除了专业的IDE例如pycharm,拥有完善的测试功能,一般的python虽然也有跟踪测试功能,但是使用起来不大方便。
py:输入py既是运行python,通过读取系统环境,而运行python.exe,但这两个进程,任何一个结束,窗口都会消失。

 禁用路径长度限制,他会向注册表注入一段信息,遗憾在UAC下无法截图!
禁用路径长度限制,他会向注册表注入一段信息,遗憾在UAC下无法截图!
WIN+R 输入py或者python 回车
或者在开始菜单寻找相关目录
之后可以右键古锭刀任务栏,以后只需要点击或者WIN+对应数字键运行即可,亦可以在桌面创建快捷图标等等启动方式

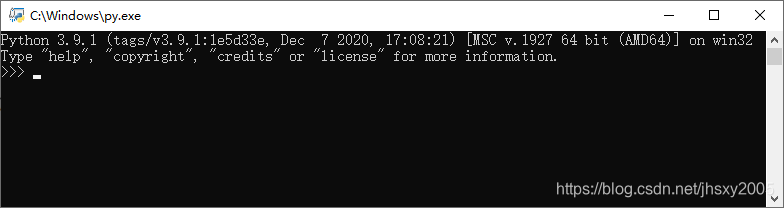 这既是交互式命令行
这既是交互式命令行
若想退出窗口,可以点击关闭图标或者Use exit() or Ctrl-Z plus Return to exit
注意,因为Windows10的窗口模式特殊性,很多输入法无法在这个窗口中输入,此时可以切换成Windows自带输入法
在交互式Python解释器的会话中,你可以输入任何Python语句或者表达式并立即运行他们。
运行的位置:代码目录
建议大家固定一个目录专门存储代码,之后可能用到的Jupyter也有相关的目录设置
交互式的运行代码

>>> print('Hello world!')
Hello world!
>>> print(2**8)
256
就是这样,在窗口中输入print(‘Hello world!’)回车,显示Hello world!
再输入print(2**8),显示256
但,在交互式命令行下,其实是不需要输入print的,就回自动显示出结果
>>> 'Hello world'
'Hello world'
>>> 2**8
256
>>> a='A'
>>> a
'A'
当输入的语句是一个数值、变量或是表达式时,他自动显示出对应的量和结果,无需再添加print。而语句是一个赋值语句时,则不会显示。
print('ABC') #这是给人看的注释,Python会略过以井字号开头的语句,之后我会在长语句与结果显示中手动写入以分割内容等
有一些置于首行的#有特殊的含义,例如UNIX的
#!/usr/local/bin/python
这里指明了python解释器在磁盘中的位置
# coding=utf-8
# -*- coding:utf-8 -*-
这个指的是声明文件中使用的编码是utf-8
为什么要使用交互式命令行模式
交互提示模式根据用户的输入运行代码并响应结果,但是,他不会吧代码保存到一个文件中,尽管这意味着你不能在交互会话中编写大量的代码,但交互提示仍然是体验语言和测试编写中的程序文件的好地方。
为什么要使用jupyter
这里就不得不开始说jupyter,但我大致预览了下,此书并没有专门介绍Jupyter。
Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
Jupyter Notebook介绍、安装及使用教程
Jupyter notebook教程系列
上面提到编写的代码无法大量,无法保存,而jupyter能够完全的解决这两个问题,而且很高效方便易用,也不受windows输入法的限制。
这里我就以安装、设置,简要搭建jupyter的工作环境,更复杂的大家可以看上面的两个链接。
安装:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jupyter
pywin32_postinstall.py
pywin32_testall.py
__pycache__ (pywin32_postinstall.cpython-39.pyc、pywin32_testall.cpython-39.pyc)
jupyter.exe
jupyter-migrate.exe
jupyter-troubleshoot.exe
pygmentize.exe
jupyter-kernel.exe
jupyter-kernelspec.exe
jupyter-run.exe
iptest.exe
iptest3.exe
ipython.exe
ipython3.exe
jupyter-qtconsole.exe
jupyter-console.exe
jsonschema.exe
jupyter-trust.exe
jupyter-nbconvert.exe
jupyter-bundlerextension.exe
jupyter-nbextension.exe
jupyter-notebook.exe
jupyter-serverextension.exe
之后pip自动下载安装了jupyter以及相关依赖组件,其中值得一提的是ipython也安装了,它属于相对pyhton增强版的交互式平台,而jupyter更像是增强版的ipython。这里不提ipython,只说jupyter。
C:\Users\Jone\AppData\Local\Programs\Python\Python39\Scripts>jupyter notebook
[W 12:59:40.942 NotebookApp] 终端不可用(错误: No module named 'winpty.cywinpty')
[I 12:59:41.673 NotebookApp] 启动notebooks 在本地路径: C:\Users\Jone\AppData\Local\Programs\Python\Python39\Scripts
[I 12:59:41.674 NotebookApp] Jupyter Notebook 6.2.0 is running at:
[I 12:59:41.674 NotebookApp] http://localhost:8888/?token=88350b78a7340bd5cf0ae0b2bf1b2ab871347ddde8da56fe
[I 12:59:41.675 NotebookApp] or http://127.0.0.1:8888/?token=88350b78a7340bd5cf0ae0b2bf1b2ab871347ddde8da56fe
[I 12:59:41.676 NotebookApp] 使用control-c停止此服务器并关闭所有内核(两次跳过确认).
[C 12:59:41.842 NotebookApp]
To access the notebook, open this file in a browser:
file:///C:/Users/Jone/AppData/Roaming/jupyter/runtime/nbserver-7228-open.html
Or copy and paste one of these URLs:
http://localhost:8888/?token=88350b78a7340bd5cf0ae0b2bf1b2ab871347ddde8da56fe
or http://127.0.0.1:8888/?token=88350b78a7340bd5cf0ae0b2bf1b2ab871347ddde8da56fe
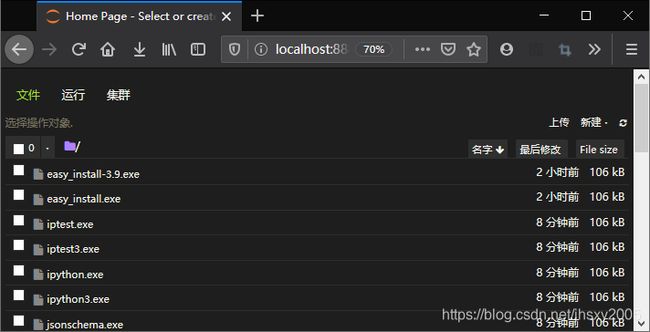 在命令栏中输入jupyter notebook,随即运行,并跳出一个本地网页,虽然我之前卸载了python,但是jupyter的设置看来还是在某处保留了下来,首先全新安装的jupyter是英文的,在系统设置中添加语言和中文,jupyter即变成了中文,jupyter默认是需要输入密码才能登陆的,因为我自己用,所以无需这样的安全设置,于是设置成直接登录进来。默认jupyter不是这个主题,这个主题是另外下载设置的。默认从哪里登录,会有对应的工作目录,例如这回在cmd下的目录下执行的jupyter,所以默认目录就是那个目录,而我一般使用是从快捷方式启动,那里可以设置工作目录。这一切内容都可以在CSDN内搜到,现在我重新创建一个快捷启动!
在命令栏中输入jupyter notebook,随即运行,并跳出一个本地网页,虽然我之前卸载了python,但是jupyter的设置看来还是在某处保留了下来,首先全新安装的jupyter是英文的,在系统设置中添加语言和中文,jupyter即变成了中文,jupyter默认是需要输入密码才能登陆的,因为我自己用,所以无需这样的安全设置,于是设置成直接登录进来。默认jupyter不是这个主题,这个主题是另外下载设置的。默认从哪里登录,会有对应的工作目录,例如这回在cmd下的目录下执行的jupyter,所以默认目录就是那个目录,而我一般使用是从快捷方式启动,那里可以设置工作目录。这一切内容都可以在CSDN内搜到,现在我重新创建一个快捷启动!
当在win+r中启动jupyter notebook时,他的工作目录是C:\Users\Jone,然后我固定运行程序到任务栏,接下来修改这个启动程序:

在目标中添加notebook命令,在起始位置设置为自己的源代码存放目录,这样点击这个快捷方式启动时,工作目录就是设置的这个了。
注意:之前发生过的问题,关于代码中的导入,他会先搜索同目录下是否有相关文件,再搜索全局路径,如果同目录下有象关子目录或是文件,但又不是真正需要的那个文件,就会运行错误!所以源代码目录下不要起名关键目录和文件名同名的行为。
那么之所以一定要插一段jupyter的介绍,就是因为他的方便性:
jupyter按tab无法补齐的解决(非Hinterland问题)
pip install jedi==0.17.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
 同样的交互特性,但是可以将代码保存,而且支持长代码,支持tab键补齐,支持符号补齐(但我最初学C时,没有任何扩展功能的编辑器,已经习惯同时输入两边符号,这让我很困扰,觉得多此一举)。网页界面很舒适,可以远程操作,支持ipython的魔法函数。jupyter本身就算是ipython的网络扩展。
同样的交互特性,但是可以将代码保存,而且支持长代码,支持tab键补齐,支持符号补齐(但我最初学C时,没有任何扩展功能的编辑器,已经习惯同时输入两边符号,这让我很困扰,觉得多此一举)。网页界面很舒适,可以远程操作,支持ipython的魔法函数。jupyter本身就算是ipython的网络扩展。
书中代码演示都来自于python交互命令行模式,我使用也建议大家使用的是jupyter。重回书本。
为什么使用PyScripter
新欢,书中提到了这个IDE,我试了之后,非常喜欢,尤其是他的Python解释器,虽然核心仍是系统上的python解释器,但是增加了好多这个IDE的补全,以及编辑功能,作为交互式会话窗口也很好使,虽然如此,但不要过于依赖,懒汉养成器,不利于学习的,但很利于应用!
推荐下Python的IDE:PyScripter,以及使用心得分享
实验
由于代码是立即执行的,交互命令行模式变成了实验这个语言的绝佳地方。
当你对一段Python代码的运行有任何疑问时,马上打开交互式命令行并实验代码,看看会发生什么。
加入阅读一个Python程序的代码并遇到了像’Spam!’*8这样一个不理解其含义的表达式。此时你可能会画上十分钟翻阅手册、书本或网页来尝试搞清楚这段代码做什么,或者你也可以直接交互式的运行它:
>>>'Spam!'*8
'Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!'
通过交互提示模式接收到的直接反馈,通常是搞清楚一段代码到底做什么的最快的方式。
这里他清楚地显示:这条语句重复字符串,在Python中,*表示数字相乘,但对于字符串来说,表示重复这段字符串几次。
同时交互式提示模式中,如果我们的语句存在错误,他会明显的提示具体是怎样的错误。
>>>X
---------------------------------------------------------------------------
NameError
Traceback (most recent call last)
<ipython-input-3-b5fec669aca1> in <module>
----> 1 X
NameError: name 'X' is not defined
这是调用变量的一个方式,但是之前并没有给这个变量赋值,也就是说并不存在这个变量,所以这里提示了对应的错误。
这样的错误并不会导致Python或计算机崩溃,相反你能得到有意义的出错信息,指出该错误以及出错的代码行,并且你可以继续自己的会话或脚本。
测试
除了充当学习语言的体验工具,交互式解释器也是测试已经写入到文件中的代码的好地方。你可以交互的导入模块文件,并且通过在交互提示模式中运指如飞的输入命令,从而在他们定义的工具上运行测试。
import os
os.getcwd()
#
'C:\\Users\\Jone\\Documents\\pydir'
书中这里介绍的比较艰涩,毕竟看过一本简略教材的我也没用过这个功能,他的意思是,使用import的功能,导入已经写好的python、C、Java等程序,在交互式命令中运行并查看结果,但我并不认为会如书中所提到的安全,内存上可能是安全的,但是如果涉及磁盘文件操作呢!当然自己写的代码的话,心里自然是有底的!
使用注意:交互命令行模式
交互命令行模式简单易用,但还是有一些需要注意的:
· 只能输入Python命令:不能输入系统命令,虽然Python有os.system等支持一些系统操作
· print语句仅在文件中才是必需的:交互解释器中自动打印表达式的结果,打印语句是可选的,不是必须的。但在文件中是需要写print的
· 在交互命令行模式下不需要缩进:这里指的是python交互式下的第一行,ipython没问题
>>> for i in range(10):
File "" , line 1
for i in range(10):
IndentationError: unexpected indent
缩进错误:意外缩进
但是在ipython和jupyter中是完全没问题的
for i in range(10):
print(i)
#
0
1
2
3
4
5
6
7
8
9
· 留意复合语句下的提示符变化
>>> for i in range(10):
... print(i)
...
0
1
2
3
4
5
6
7
8
9
语句中,…是复合语句,即接连上面的语句而没执行,所以看到…开头,就要知道
若想结束输入并执行,需要敲两次回车键,即用一个空行结束复合语句
· 交互式命令行模式,一次运行一条语句
语句,回车运行,下一条语句。这里将复合语句当作一条语句看待。
· 输入多行语句
在交互式命令行模式中,像for循环、if测试,用一个空行结束多行复合语句,也就是需要按两次回车键。
这意味着不能在交互命令行模式中复制并粘贴多行代码,除非这段代码的每条复合语句的后面都包含空行。
>>> for i in range(2):
... print(i)
... for a in range(2):
File "" , line 3
for a in range(2):
^
SyntaxError: invalid syntax
>>> print(a)
File "" , line 1
print(a)
IndentationError: unexpected indent
# 上面的情况,是两个紧挨的for复合语句
>>>
>>> for i in range(2):
... print(i)
...
... for a in range(2):
File "" , line 4
for a in range(2):
^
SyntaxError: invalid syntax
>>> print(a)
File "" , line 1
print(a)
IndentationError: unexpected indent
# 这里是两个for复合语句中隔了一行,但并不是空行,而是有个tab
>>> for i in range(2):
... print(i)
...
0
1
>>> for a in range(2):
... print(a)
# 这里是两个for复合语句中,有一个空行
在脚本文件(程序代码)中,复合语句后面是不需要空行的;只在交互命令行模式下,才需要该空行。
系统命令行和文件
尽管交互命令行对于实验和测试来说都很好,但是它也有一个很大的缺点:Python一旦执行了输入的程序之后,他们就消失了,输入的代码不会保存在一个文件中,为了能够重新运行,又不得不从头输入。即便是复制粘贴,也并不方便。
为了能够永久保存程序,需要在文件中写入代码,这样的文件通常叫做模块。模块是一个包含了Python语句的简单文本文件,一旦编写完成,可以让Python解释器多次运行这样的文件中的语句,并且可以以多种方式去运行。
模块文件常常作为Python写成的程序。一个程序是由一系列编写好的语句构成,保存在文件中,从而可以反复执行。
可以直接运行的模块文件往往也叫做脚本(一个顶层程序文件的非正是说法)。
有些人将“模块”这个说法应用于被另一个文件所导入的文件,而将“脚本”应用于一个程序的主文件。
对于许多程序员而言,一个系统shell命令行窗口加上一个文本编辑器窗口,就组成了他们所需的一个集成开发环境的主力部分。
第一段脚本
打开文本编辑器(vi,Notepad,IDLE),在命名为script1.py的新文本文件中输入如下Python语句,并把它保存在之前创立的工作代码目录。
这里不建议大家尝试使用其他的编辑器,例如vi,因为太耗时间、精力,linux的快捷方式、长城外的网络、语言的障碍,导致尝试著名的vim是一种时间消耗,不利于本书的学习,可以在课程结束后,需要写长代码时,再学。
这里我推荐IDLE,毕竟Python自带的,而且工具栏可以方便的运行。

这就是Python自带的IDLE。
如果你使用的是linux,我建议可以尝试一下gedit 搭建的python IDE。虽然windows下也有gedit,但是毕竟并非是原生的,没能搭建成功。
# A first Python script
import sys # 加载一个库的模块
print(sys.platform)
print(2**100) # 计算2的次方
x='Spam!'
print(x*8) # 重复一个字符串
这个文件是我们第一个正式Python脚本:
· 导入一个Python模块(附加工具的库),以获取系统平台的名称
· 运行3个print函数调用,以显示脚本的结果
· 运行一个名为x的变量,在创建的时候对其赋值,保存一个字符串对象
· 应用我们将从下一张开始学习的各种对象操作
这里的sys.platform只是一个字符串,他表示我们所工作的计算机的类型,它位于名为sys的标准Python模块中,我们必须导入以加载该模块
这里还添加了一些正式的Python注释,即#符号之后的文本,注释可以自称一行,也可以放置在代码行的右边。
我们已经把这段代码输入到一个文件中,而不是输入到交互命令行模式中。在这过程中,我们已经编写了一个功能完整的Python脚本。
使用命令行运行文件
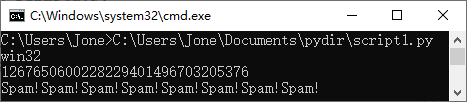
保存这个文本文件,可以在系统shell命令行中输入,从而要求Python来运行它:
% python script1.py
win32
1267650600228229401496703205376
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
如果PATH没有甚至的话,需要用完整的路径替换python
在windows中也可以直接在shell或者桌面运行script1.py,这里默认.py文件由python打开。
而在IDLE中,可以直接F5运行已编辑保存的当前窗口的代码。
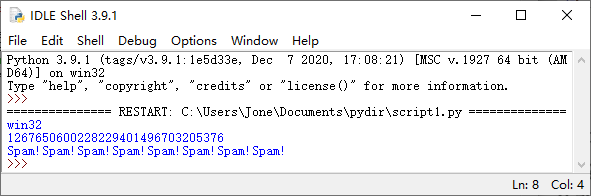 如果一切顺利进行,Python将会一条条的执行并打印出结果,如果输出失败或并非预料中的结果,就要检查是否输入错误、查看报错信息等,而有的时候是逻辑上的错误而非系统上的错误,可能会看不到报错信息。
如果一切顺利进行,Python将会一条条的执行并打印出结果,如果输出失败或并非预料中的结果,就要检查是否输入错误、查看报错信息等,而有的时候是逻辑上的错误而非系统上的错误,可能会看不到报错信息。
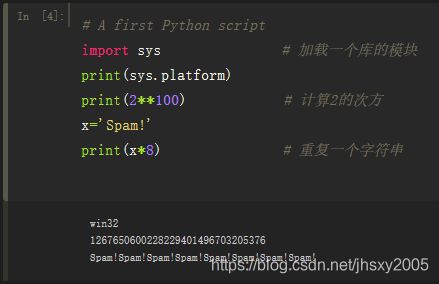 而在jupyter中,可以以这种模式运行,在一个代码块中,可以当作一个完整的程序编辑,编辑完成后可以立即运行。而且jupyter会自动保存,还能手动保存。
而在jupyter中,可以以这种模式运行,在一个代码块中,可以当作一个完整的程序编辑,编辑完成后可以立即运行。而且jupyter会自动保存,还能手动保存。
不同的命令行使用方式
我们可以输出结果保存到一个文件中
% python script1.py > saveit.txt
在windows中,是以ANSI格式保存的,即标准ASCII+当地国家标准编码,这也是为什么我们打开一些外国的文件,会有乱码,因为他们的字符存储信息都是当地的ANSI格式而非国际标准的Unicode编码。于是当我们无论尝试本地ANSI解码还是Unicode解码,显示的都是乱码(没有连贯意义的字符)。
在这个例子中,前面运行中的3个输出行都存储到了saveit.txt中,而不是打印出来。这同炒讲座流重定向(stream redirection),他用户文本的输入和输出,而且在Windows和类UNIX系统上都可以使用。这对测试来说是很棒的,因为你可以编写监视其他程序输出变化的程序。他几乎和Python不相关,因此,我们在这里略过有关shell重定向语法的细节。
而python也是有功能将print的输出直接写入文本中的,毕竟相对窗口和文本,其实都是打印的对象,只需要将print的对象切换为文本而非窗口,输出结果就会被打印到文本中。而python也有专门写入文本信息的参数。另外一个需要输出到文本由并非这两种情况的是help,这个类似于情况1,是将输出对像切换为文本。因为即便是将print切换为文本,而print也不过是将语句内的数据整合成一个字符串,那么将这个字符串直接用常规的写入的方法写入到文件中就是了。
除了上述的shell下运行脚本的方法(python和完整路径的python以及windows下直接运行.py)
% py -3 script1.py
win32
1267650600228229401496703205376
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
还可以使用py+指定版本号(可选)的方法运行,这里py写入到了windows/system下,目的只是为了启动在安装目录下的python,算是一个启动器。
补充,关于windows下,在管理器中直接运行.py,窗口通常会一闪而过,因为他执行完了,窗口就关闭了,一般会添加input()这样的有暂停效果的语句阻止窗口消失,不过是否就会比在shell中打开便利呢,毕竟shell可以直接输入或拖入.py运行。我通常是添加input()后双击.py运行的,尤其是某从动画到字符到文件,再播放这字符动画的时候。
使用注意:命令行和文件
从系统命令行开始运行程序文件是相当直接明了的启动选择,特别是自爱通过你之前的日常工作已熟悉命令行的使用。以及每个系统都有某种命令行和目录结构的概念。
· 注意Windows和IDLE上的自动扩展名。Windows系统的记事本会默认以.txt为后缀保存。而且资源管理器中默认是隐藏文件后缀名的。
而MS Word默认文件扩展名是.doc,更糟糕的是,他并非是纯文本格式,而是有自己的格式,以至于文件中会有未知的字符。
在Windows下保存文件时,永远要选择所有文件(不使用编辑器默认的后缀名)
或者使用对程序员更加友好的文本编辑器,例如IDLE。
· 在系统命令行模式下使用文件扩展名和目录路径,但是在导入时别使用它们。
在shell中,我们需要输入.py完整的路径和文件名,但是在之后的Python导入语句中,这些都不需要。Python是依靠模块搜索的路径定位文件的。
· 在文件中使用print语句
交互式命令行编程可以省去print语句,但是程序代码中是必需的。
UNIX风格可执行脚本:#!
UNIX脚本基础
在UNIX和LINUX中,文件后缀名对系统来说是没有意义的,而是根据文件内容的头部来确定文件类型,所以在这些系统中就有了头部是以#!开头的协定
· 他们的第一行是特定的。脚本的第一行往往以字符#!开始(常常叫做“hash bang”或“shebang”),其后紧跟着机器Python解释器的路径。hash bang的本意是跳转至,这里的意思就类似于Windows的shell中,python .py的意思
· 他们往往都拥有可执行的权限。脚本文件往往通过告诉操作系统,他们可以作为顶层顺序执行,而拥有可执行的权限。在UNIX系统上,往往以chmod +x file.py来实现这样的目的
Unix shell开头的#!
1:位于脚本文件最开始
2:#!告诉系统内核应有哪个shell来执行所指定的shell脚本。
3:如#! /bin/bash ,#!与shell文件名之间可以有空格,没有限定。
4:指定的shell可以带参数,如 #! /bin/bash -f,如果文件后只加“-”,表示没有参数:#! /bin/bash -,
注意点:
1:现在的系统没有对#!这一行的长度做一定的限定,各个系统之前不一致,最好不要大于63个字符。
2:在一些系统中,命令行部分,包括了完整的路径,不过有的系统却不是这样,命令行部分会原封不动的传给程序,因此脚本最好有完整的路径名。
3:别在shell文件名之后放空格,因其会原封不动的和脚本文件名连接在一起
#!/usr/local/bin/python
print('The Bright Side '+'of Life...') #+的意思是将两个字符串连起来
#
The Bright Side of Life...
在Windows中,第一行是没必要的,因为Windows是按照文件后缀名分辨文件类型的,根据注册信息绑定程序与文件的。
而在UNIX中,也不需要指定文件名后缀名,但为了我们的可读性,还是建议添加.py的
UNIX env 查找技巧
万一python解释器的位置不固定呢,就可以通过全局去查找,类似Windows的PATH,这就是env命令,env的意思是列出所有环境变量,于是可以写成:
#!/usr/bin/env python
...scrip goes here...
这样代码也更具有可移植性,只要UNIX中,python解释器在环境变量内,就可以被调用。
在系统中,书中称之为环境变量,我印象中称之为全局变量,网上一查,说法都有。但在程序代码内部,也有这两个名词,但是意义就不一样了!
Python 3.3 Windows启动器:Windows也有#!了
在Python 3.2及之前,这个符号在Windows中是没有含义的,但是在3.3之后,也有了含义,他指的是需要启动哪个版本的Python,例如当系统中同时安装了Python 2.X和3.X,或者更详细的版本。
而且要是想让程序同时能在Windows和UNIX中运行,还是需要这一行的。
当你从命令行运行带有py的程序脚本,以及点击Python文件图标时(在这种情况下py通过文件名关联隐式的运行),启动器的#!解析机制开始起作用。不同于UNIX,Windows下不必去给代码文件添加权限,因为文件时通过文件名关联得到类似的结果的。
% type robin3.py
#!/usr/bin/python3
print('Run','away!...')
% py robin3.py
Run away!...
% type robin2.py
#!python2
print 'Run','away more!...'
% py robin2.py
Run away more!...
% type /?
显示文本文件的内容。
% py robin2.py
Requested Python version (2) is not installed
% robin2.py
Requested Python version (2) is not installed
Requested Python version (3.5) is not installed
% python robin2.py
File "C:\Users\Jone\Documents\pydir\robin2.py", line 2
print 'Run','away more!...'
^
SyntaxError: Missing parentheses in call to 'print'. Did you mean print('Run','away more!...')?
嗯嗯,这里书中举例时以py作启动器的,而当以python直接运行的时候,是不会解释版本号的,所以这个机制是建立在py上的,而且单独运行.py的话,和py效果一样,于是.py文件时关联到py而非python。
#!/usr/bin/env python3.5
也可以这样写,虽然我只是在Windows上运行,但是我之前安装过deepin并尝试在上面安装python,里面是预安装了一个3.7版本的python,而在/usr/bin下有python和python3.7两个软件,python应该类似于Windows下的py,而python3.7才是真正的Python解释器。
这句代码,在Windows下,等价于
#!python3.5
而UNIX会直接去找python3.5这个文件
% py -3.1 script1.py
Python 3.1 not found!
Installed Pythons found by py Launcher for Windows
-3.9-64 *
而且py可以添加参数指定python版本
点击文件图标
如果你不是一位命令行狂热分子,一般你可以通过点击文件图标,使用开发GUI和运用其他随平台变化的架构,启动Python脚本,从而避免使用命令行。
图标点击基础知识
图标点击在绝大多数平台上以一种或另一种形式被支持
· Windows图标点击

这里的图标是指脚本文件的图标,即直接双击运行脚本文件。而脚本文件在windows中是根据注册表信息与py.exe绑定的,所以双击脚本文件等价于py *.py(3.3版本后,之前是与解释器直接绑定)。
· 非Windows图标点击
在非Windows系统中,也能够使用相似的技巧,但是图标、文件资源管理器导航方案以及许多方面都有少许不同。
MAC中,通过Finder调用PythonLauncher运行。
UNIX和Linux上,也在可能存在着管理器的GUI中注册.py的扩展名,或是其他工具,实现运行。
在Windows上点击图标

在Windows的资源管理器上,找到代码的目录:
· 源文件在Windows上有白色背景
· 字节码文件有黑色背景
字节码在pycharm下是自动生成的,但是直接运行python貌似并不生成字节码,于是我找了篇文章:
python下编译py成pyc和pyo
编译成pyc:python -m py_compile file.py
编译成pyo:python -O -m py_compile file.py
执行命令后,会在.py的同目录下生成一个__pycache__目录,生成对应的.cpython-39.pyc或.cpython-39.opt-1.pyc
Pyc和pyo是怎样一种存在?
pyc和pyo都是由.py文件生成的字节码文件。pyo相比pyc,少了断言和debug信息,在体积上小一些。还有,在python3.5之后已经不是.pyo文件,而是.opt-1.pyc形式。
回答中的运行耗时,.py 0.03s .pyc 0.29 .pyo 0.29 二进制文件0.02s
二进制文件我尝试打包失败,之前成功过一次,于是大家请不要尝试,之后会有学到的机会,这里避免浪费时间,请略过。
Windows上的输入技巧
在Windows上直接双击图标,窗口会一闪而过,因为程序结束了。
于是这里可以在代码末尾,增加一行
input()
这个语句会等待用户输入字符串,回车确认,这里的效果就回暂停并显示窗口内容,当敲击回车后,程序就会结束,窗口会关闭。
· Windows系统
· 通过点击文件图标运行脚本
· 脚本打印文本后退出
当满足以上三点,才需要这个技巧
若在命令后或者IDLE GUI中运行脚本,则不需要担心程序结束,窗口会关闭。
input的其他应用:
input('Press Enter to exit')
这里会打印出Press Enter to exit到窗口上,这类似于print的功能,一般提示你需要输入什么
nextinput=input()
这里是把输入的字符串赋值给nextinput这一个变量,而如果确定输入的是整数或其他非字符串类型,可以提前或之后对字符串进行处理,例如可以直接int(input()),也可以复杂的交给你个字符串处理流程去处理。
python spam.py < input.txt
在系统shell的层面上,支持输入流的重定向
spam.py
instr=input()
print(instr)
instr=input()
print(instr)
% spam.py < saveit.txt
usage: C:\Users\Jone\AppData\Local\Programs\Python\Python39\python.exe [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
这里的效果是将saveit.txt里面的字符串,一行一行的传入到代码中的input中,每次只能传入一行,下一次是下一行。而此时input()已经失去了暂停的功能,每个input将会依次的收到文本传过来的一行行的字符串,直至不再有input(),程序结束。或者文本中的行全部传递完毕,但仍然有input(),程序报错!如下:
% spam.py < hi.txt
hi
Traceback (most recent call last):
File "C:\Users\Jone\Documents\pydir\spam.py", line 3, in
instr=input()
EOFError: EOF when reading a line
之后章节,会更加复杂的使用input,例如,在交互循环中使用他。
其他图标点击的限制
如果代码中出错,即在input()之前,就回弹出错误代码并中止程序,窗口也是一闪而过的。
print(a)
input()
本书之后讨论异常的时候,会写一些代码截取错误,处理错误,从错误中恢复,这样他们就不会中止你的程序。try语句
print操作的时候,也可以将打印重定向到文件中,以便于之后的检查。
如此操作,错误和打印都不会显示到输出上。
正由于这些的限制,最好将点击图标看作是在程序调试之后,或已经配置为将其输出写入到一个文件,捕获和处理任何重大错误之后,启动运行程序的一种方法。
特别是初学的时候,建议通过系统命令行或IDLE运行程序,一边能够看到生成的错误信息,并在不编写额外代码的情况下,观察正常的输出结果。
模块导入和重载
我们将会子啊第五部分深入学习模块和较大的程序架构。导入同事也是一种启动程序的方法。这一节将会介绍足够多的模块基础知识。
导入和重载基础知识
每一个.py都是一个模块,不需要任何特殊的代码或语法来使文件成为模块。
其他文件可以通过导入一个模块读取这个模块定义的内容,导入操作从本质上来讲,就是载入另一个文件,并给予读取那个文件内容的权限。一个模块的内容通过其属性(会讲到)从而被外部世界使用。
这种基于模块的模型变成了Python程序架构背后的一个核心思想。更大的程序往往以多个模块文件的形式出现,并且从其他模块文件导入工具。
其中一个模块文件指定为主文件,或叫作顶层文件,或“脚本”。
就是那个启动后能够运行整个程序的文件,他照常逐行运行,在这一层之下,全部是模块导入模块。
导入文件中的代码,这个文件作为最后一步正在被加载,因此,导入文件是另一种运行文件的方法。
在一个交互对话中,运行之前创建的文件script1.py,通过简单的import来实现:
c:\code>python
Python 3.9.1 (tags/v3.9.1:1e5d33e, Dec 7 2020, 17:08:21) [MSC v.1927 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import script1
win32
1267650600228229401496703205376
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
>>> import script1
>>>
· 这里的路径时代码所在目录,Win10可以再任务栏固定图标并设置起始位置,之后只需要使用win+对应数字键即可打开
· 只有这个路径下才能导入其下的文件,定制PATH无效,补充,之后得知python内部有个sys.path,相当于python自己的环境变量。
python:永久添加路径到sys.path
· 导入只会运行一次,再同一个进程下,再次导入,即便修改了源代码,并不会被运行。这个再之后用到的自定义函数这种也是如此
这是有意设计的,导入是一个开销很大的操作,以至于每个文件、每个程序不能重复运行多于一次。导入需要找到文件,将其编译成字节码,并且运行代码。
>>> import threenames
Traceback (most recent call last):
File "" , line 1, in <module>
ModuleNotFoundError: No module named 'threenames'
>>> import sys
>>> sys.path.append("c:\code")
>>> import threenames
dead parrot sketch
 在环境变量中添加一个PYTHONPATH项
在环境变量中添加一个PYTHONPATH项
如果想要再Python的同一次会话中再次运行文件,需要调用imp标准模块中的reload函数。
>>> from imp import reload
<stdin>:1: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
>>> reload(script1)
win32
1267650600228229401496703205376
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
<module 'script1' from 'c:\\code\\script1.py'>
>>> reload(script1)
win32
256
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
<module 'script1' from 'c:\\code\\script1.py'>
>>> reload(script1)
win32
256
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
<module 'script1' from 'c:\\code\\script1.pyc'>
这里在从imp中导入reload的时候,出现了警告,但并不影响之后的运行,这里只要注意他是Warning的话,并不能说明运行错误,只是警告而已。之后仍可尝试运行该功能,看看实际是否影响。
这里使用reload(script1),再次运行这个文件中的代码,这里是从文件读取开始的,所以第二次是我修改2100为28,而显示的不同的结果。
reload(script1)
· script1被加载过
· script1的源文件还存在,如果不存在,同目录下有script1.pyc,同样可以运行,这里会从字节码而非源文件开始导入。
imreload.py
import script1
import script1
from imp import reload
reload(script1)
input()
win32
256
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
C:\code\imreload.py:3: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
from imp import reload
win32
256
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
这里我将这些代码写入文件执行,执行结果显示了提醒信息,带式并没有显示尖括号内部的信息。而提醒信息应该可以使用一个方法屏蔽掉。
1、在python或py后增加-W ignore参数
% python -W ignore imreload.py
win32
256
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
win32
256
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
2、在代码中增加如下
import warnings
warnings.filterwarnings("ignore")
注意改代码需要加载可能出现的警告之前,对在这代码之前的警告无效。
但这种写法会让程序在非法运行的边缘试探,所以尽可能地不用。
reload函数在模块对象的名称周围有圆括号,而import则不需要。是因为reload是一个被调用的函数,而import是一个语句。当你听见“函数”时,牢记需要圆括号来进行调用。
模块的宏观视角:属性
导入和重载提供了一种自然的程序启动选项,因为导入操作将会在最后一步执行文件。
从更宏观的角度来看,模块扮演了一个工具库的角色。
模块往往就是变量名的包,即命名空间,而在那个包中的变量名称为属性。属性简单你说就是绑定在特定的对象(如模块)上的变量名。
导入者得到了模块文件中在顶层所定义的所有变量名的访问权限。(这里的顶层应该指的是这个模块文件,例如如果一个模块文件还调用了其他模块文件才能是一个完整的程序的话,那么顶层就只是这一个模块文件。)
这些变量名通常被赋值给通过模块函数、类、变量等来导出的工具,这些工具往往用在其他文件或程序中。这里应该指的是模块的属性可以被调用者使用,属性包括模块内的函数、类、变量。还是说有别的意思?
一个模块文件的变量名可以通过两种Python语句读取:import 和 from,以及reload调用。
例:
myfile.py
title='The Meaning of Life'
当文件导入时,它的代码生成了模块的属性,也就是说,这个赋值语句创建了一个名为title的变量(对内)和模块属性(对外)。
从其他组件获得这个模块的title属性的方法:
1、import …
% python
>>> import myfile
>>> myfile.title
'The Meaning of Life'
使用import导入整个模块,可以使用object.attribute的方法,从任何object种取数任意的attribute。
2、from … import …
% python
>>> from myfile import title
>>> title
'The Meaning of Life'
通过from语句从模块文件中获取(复制出)变量名
from和import很相似,只不过增加了对载入组件的变量名的额外赋值。
from复制了模块的属性,并成为接收者的直接变量。能够直接用title(变量)引用导入的字符串,而不是myfile.title(属性引用)
>>> from myfile import title as t
>>> t
'The Meaning of Life'
如果不想使用模块种的变量名称,可以使用as自定义变量名。
无论import还是from,模块的语句都会执行,并导入到组件(对应这里是交互命令行模式),获得在文件顶层赋值的变量名的访问权。
但如果开始在模块中定义对象,例如函数和类时,这个概念将会更加有用:这样一些对象就成了可重用的软件组件,可以通过变量名被一个或多个客户端模块读取。
函数:处理数据的方法。类:定义数据的结构以及方法
往往一个模块不只有一个属性。
threenames.py
a='dead'
b='parrot'
c='sketch'
print(a,b,c)
这里给三个变量赋值,因此对外界生成三个属性。
% threenames.py
dead parrot sketch
% python
>>> import threenames
dead parrot sketch
>>> threenames.b,threenames.c
('parrot', 'sketch')
>>> from threenames import a,b,c
>>> b,c
('parrot', 'sketch')
(‘parrot’, ‘sketch’)是元组的结构,因为在之前输入的是b,c,他自动组成为一个元组的值,之后会介绍到。
而关于import和from的更多细节,之后也会学到,这里无须探究太多。而在代码中,插入不能带.py,而在shell中,必须带.py
>>> dir(threenames)
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'b', 'c']
使用dir()函数,可以获取所有threenames的,__x__等属性是Python预定义的内置变量名,对于解释起来说有特定的意义。通过代码复制而定义的变量:a、b、c,在dir结果的最后显示
>>> help(threenames)
Help on module threenames:
NAME
threenames
DATA
a = 'dead'
b = 'parrot'
c = 'sketch'
FILE
c:\code\threenames.py
而使用help(),可以看到更详细的细节,而那些没有定义的预定义会被略过。
help(dir)
Help on built-in function dir in module builtins:
dir(…)
dir([object]) -> list of strings
If called without an argument, return the names in the current scope.
Else, return an alphabetized list of names comprising (some of) the attributes
of the given object, and of attributes reachable from it.
If the object supplies a method named __dir__, it will be used; otherwise
the default dir() logic is used and returns:
for a module object: the module’s attributes.
for a class object: its attributes, and recursively the attributes
of its bases.
for any other object: its attributes, its class’s attributes, and
recursively the attributes of its class’s base classes.
dir:总之和通常认识的dir差不多,一般cmd的dir是列出目录中所有的文件。而这里的dir是列出模块中所有能使用的东西。
模块和命名空间
模块导入是一种运行代码文件的方法,同样是Python程序最大的程序结构,也是这门语言的首要关键概念。
Python程序往往由多个模块文件构成,通过import语句连接在一起。每个模块文件是一个变量包(一个命名空间)。
一个模块不能看到其他文件中定义的变量名,除非他显式的导入了那个文件。
因此,模块文件在代码文件中起到了最小化命名冲突的作用,因为每个文件都是一个独立完备的命名空间。
之后我们会深入谈到这个话题,包括类和函数定义的局部作用域。
使用注意:import和reload
这里介绍import和reload,只是描述程序的一种运行方式,但是这种其实很少用到。reload运行的时候,需要注意的有很多。
而我们要运行一个程序,大可以使用shell或IDLE、或直接双击图标。
使用sys.modules查看当前所有模块
>>> import sys
>>> sys.modules
{'__future__': <module '__future__' from 'C:\\Users\\Jone\\AppData\\Local\\Programs\\Python\\Python39\\lib\\__future__.py'>,
'__main__': <module '__main__'>,
'__oldmain__': <module '__main__' from 'C:\\Users\\Jone\\AppData\\Roaming\\PyScripter\\remserver.py'>,
'_abc': <module '_abc' (built-in)>,
....
'winreg': <module 'winreg' (built-in)>,
'zipimport': <module 'zipimport' (frozen)>,
'zlib': <module 'zlib' (built-in)>}
>>>
使用exec运行模块文件
>>> exec(open('c:\code\script1.py').read())
win32
256
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
exec是将括号内的字符串以Python代码运行的意思,例如:
>>> exec('a="ABC"') # 即a="ABC"
>>> a
'ABC'
>>> exec(open('script1.py').read())
win32
256
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
>>> exec(open('script1.py').read()) #此时已经修改了代码2**8改为2**10
win32
1024
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
>>>
因为exec是读取文件里面的内容当作python来运行,所以每次运行括号内的内容,都是打开文件读取内容,这里script1只是单纯的文本文件,.py的后缀对exec来说并没意义!
exec常用来处理字符串生成的命令,例如生成变量a1、a2、a3直到某个不确定的数,就可以用一段程序生成字符’a1’、‘a2’…,当触发结束条件后,结束生成。exec就可以在其之下执行这些字符串,即生成并赋值’a1’、‘a2’…
aa=ord('a')
for i in range(26):
exec("%s=%i"%(chr(aa+i),i+1))
exec("print('%s:%i')"%(chr(aa+i),i+1))
#
a:1
b:2
c:3
d:4
e:5
f:6
g:7
h:8
j:10
j:10
k:11
l:12
m:13
n:14
o:15
p:16
q:17
r:18
s:19
t:20
u:21
v:22
w:23
x:24
y:25
z:26
Python循环语句里一系列结果赋值给一系列变量,exec 函数
Python动态地声明变量赋值
IDLE用户界面
到目前为止,我们看到了如何通过交互命令行模式、系统命令行、UNIX风格脚本、图标点击、模块导入和exec调用来运行Python代码。如果你希望找到更可视的方法,IDLE提供了做Python开发的用户图形界面(GUI),而且他是Python系统的一个标准并免费的部分。他往往被认为是一个集成开发环境(IDE),因为他在一个单独的界面中绑定了很多不同的开发任务。
简而言之,IDLE是一个能够编辑、运行、浏览和调试Python程序的桌面GUI,所有能够在一个单独的界面实现。他在绝大多数Python平台上可移植的运行,包括微软Windows、X Windows(用于Linux、UNIX以及类UNIX平台)以及Mac OS(无论是Classic还是OS X)。
X Windows的理解与使用
对于很多人来说,IDLE代表了一种简单易用的命令行输入的替代方案,一种比点击图标出问题的可能性更小的替代方案,并且是初学者开始编辑和运行代码的一种伟大方式。
IDLE启动细节
技术上讲,IDLE是一个Python程序,它使用标准库的tkinter GUI工具箱来构建其窗口。这使得IDLE是可以指的,但是他还意味着你需要在Python中获得tkinter来支持使用IDLE。
这里以我用的Win10为例,其他系统不在阐述。
 他并非是个.exe文件,而是:
他并非是个.exe文件,而是:
C:\Users\Jone\AppData\Local\Programs\Python\Python39\pythonw.exe “C:\Users\Jone\AppData\Local\Programs\Python\Python39\Lib\idlelib\idle.pyw”
一个Python程序,而pythonw是以无命令行窗口显示的方式运行Python程序。
大家可以win+r,看一下效果:
C:\Users\Jone\AppData\Local\Programs\Python\Python39\pythonw.exe C:\code\script1.py
而且Python 3.9 Module Docs (64-bit)也是一个Python程序:
C:\Users\Jone\AppData\Local\Programs\Python\Python39\python.exe -m pydoc -b
Start the Python 3.9 documentation server.
算是动态的获取PYTHONPATH下的文件的帮助信息
Server ready at http://localhost:51333/
Server commands: [b]rowser, [q]uit
server> ----------------------------------------
Exception occurred during processing of request from ('127.0.0.1', 51348)
Traceback (most recent call last):
File "C:\Users\Jone\AppData\Local\Programs\Python\Python39\lib\socketserver.py", line 316, in _handle_request_noblock
self.process_request(request, client_address)
File "C:\Users\Jone\AppData\Local\Programs\Python\Python39\lib\socketserver.py", line 347, in process_request
self.finish_request(request, client_address)
File "C:\Users\Jone\AppData\Local\Programs\Python\Python39\lib\socketserver.py", line 360, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "C:\Users\Jone\AppData\Local\Programs\Python\Python39\lib\socketserver.py", line 720, in __init__
self.handle()
File "C:\Users\Jone\AppData\Local\Programs\Python\Python39\lib\http\server.py", line 427, in handle
self.handle_one_request()
File "C:\Users\Jone\AppData\Local\Programs\Python\Python39\lib\http\server.py", line 415, in handle_one_request
method()
File "C:\Users\Jone\AppData\Local\Programs\Python\Python39\lib\pydoc.py", line 2360, in do_GET
self.wfile.write(self.urlhandler(
File "C:\Users\Jone\AppData\Local\Programs\Python\Python39\lib\socketserver.py", line 799, in write
self._sock.sendall(b)
ConnectionAbortedError: [WinError 10053] 你的主机中的软件中止了一个已建立的连接。
----------------------------------------
win32
1024
Spam!Spam!Spam!Spam!Spam!Spam!Spam!Spam!
----------------------------------------
直接点击开始菜单里的IDLE,即可启动应用。
其他启动方法:
% python -m idlelib.idle
他的意思是搜索PYTHONPATH路径下的idlelib库中的idle Python程序。
IDLE基础用法
 这是启动后的界面,一个Shell,支持语法高亮、tab补全、复合语句换行缩进等操作。
这是启动后的界面,一个Shell,支持语法高亮、tab补全、复合语句换行缩进等操作。
File可以新建、打开Python代码文件


F5可以直接运行保存后的代码在Shell中。
IDLE功能特性
· 命令行历史
· 语法高亮
· 自动缩进或不缩进
· 输入字符时,Tab键单词补全
· 函数调用时,输入(时,气球弹窗提示
· 对象. Tab,对象属性列表
· 不局限于win10的输入法,win10下,部分输入法只能在桌面模式输入,无法在shell中输入,而在IDLE下就没有问题


高级IDLE工具

图形化调试器:Shell - Debug - Debugger


 对象浏览器
对象浏览器

右键错误信息,跳转到错误行
使用注意:IDLE
IDLE时免费、简单易用、可移植并自动支持绝大多数的平台的。但与一些更高级的商业化IDE相比,他同样有一些局限性,而对于一些人来说,他显得过于沉重。
· 当保存文件时,你必须显式的添加.py
· 通过在文本编辑窗口选择Run - Run模块运行脚本,而不是通过交互式的导入和重载。IDLE不只是个优秀的Shell,还是一个编辑器
· 你只需要重载交互的测试的模块。当只是测试一个非顶层的模块时,可以使用import/reload来代替Run-Run Module,这一应该指的是类似于之前提过的,使用Python测试软件,不过这里是测试他自己。
· 你可以对IDLE进行定制。可以设置字体、颜色、快捷键等。
· IDLE中没有清屏选项,但是可以添加插件实现清屏
IDLE清屏方法

· tkinter GUI和线程程序有可能不适用于IDLE
因为IDLE是一个Python/tkinter程序,如果使用它运行特定类型的高级Python/tkinter程序,有可能会没有响应。如果使用IDLE编辑GUI程序,没有问题,如果要启动运行他们的话。最好用图标点击或系统命令行。
· 如果发生了连接错误,试一下通过单进程模式启动IDLE
虽然在最新的Python版本中,这个问题表面上已经消失了,但仍要指导下。
由于IDLE要求在其独立的用户和GUI进程间通信,有时候特惠在特定的平台上发生启动错误,如果遇到这类连接错误,可以通过系统命令行使IDLE运行在单一进程的模式下进行启动,从而避免通信问题。
python -m idlelib.idle -n
· 谨慎使用IDLE的一些可用的特性
IDLE给使用者带来了很大的便利,例如不需要总是运行import获得顶层文件的变量名?会自动把运行的代码的目录添加到PYTHONPATH中等。而这些在IDLE以外不一定存在。
其他IDE
IDLE是一个不错的值得学习的首选开发工具。尽管如此,还是介绍一些其他的IDE,与IDLE相比,更加强大和健全:
· Eclipse和PyDev… 我不喜欢,安装、汉化困难,学校教Java的时候用的就是他
· Komodo 貌似现在免费了,但貌似没汉化
· NetBeans IDE Python版 也可以用开开发Jython,安装较为复杂
PythonWin、Wing、Visual Studio、PyCharm、PyScripter、Pyshield、Spyder
jupyter:学习用,方便快捷,顺畅
PyCharm:社区版免费,付费版增强了网页开发的功能
VSC、Atom,都比较臃肿,anaconda更是什么都包含的大



PyCharm vs Spyder:两个Python IDE的快速比较
Spyder,pip安装,pip install -i https://pypi.tuna.tsinghua.edu.cn/simple spyder
纯正的Python程序,内存占用较大,右下角的窗口既是ipython交互式界面,又是输出界面。相对于Jupyter来说,优点是存储的文件是一个完整的python项目,而不是笔记片段。

runfile('C:/code/exec1.py', wdir='C:/code')
其他IDE要么因为上网不易,很难下载到,要么因为语言,行为劝退。本想用gedit,却又有兼容性的问题。

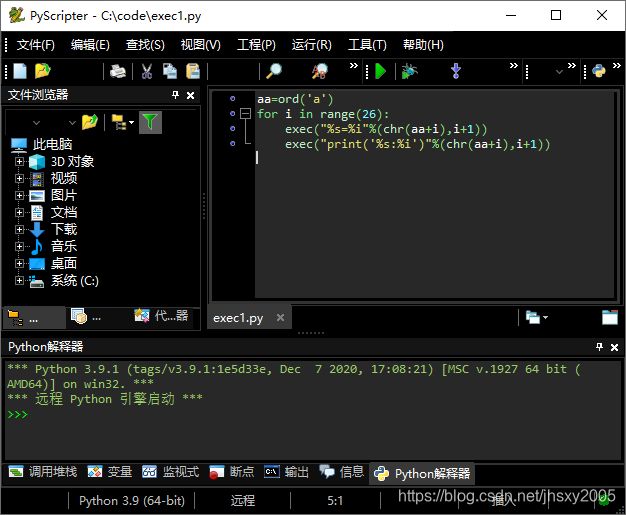 刚才终于安装成功一个PyScripter,小巧简洁,可以使用迅雷下载提速
刚才终于安装成功一个PyScripter,小巧简洁,可以使用迅雷下载提速
https://sourceforge.net/projects/pyscripter/postdownload
国内下载的是旧版,好在通过链接找到了国外,虽然仍然是挂在网速死掉的github上,但是还提供了一个软件站的下载链接,救活了。界面也很简洁。
总的来说,这次遇到的两个都很不错的样子,都是专一的Python IDE,一个是原生Python程序,一个很简洁,日后用用看。
推荐
如果你喜欢一个简洁但扩展功能好的Shell,推荐PyScripter
如果你喜欢一个%%timeit跑分稳定的IPython,内存分析(注),推荐Spyder
如果你喜欢Web操作,局域网内跨机器操作,推荐jupyter
如果你喜欢一上来就是专业操作环境,推荐PyCharm Community
如果你是MS当,就VSC
如果你是开源党,就Atom
如果你是大佬,就VIM
注:写了一个程序,能显示出类型的内存情况,但只限于第一层,于是必要情况还是用HxD查看,PyScripter的运行代码是重新开启一个python进程,用HxD看,每次都要重新加载进程,但是Spyder直接运行参数runfile,在当前的进程下运行代码,于是使用HxD查看方便。另外IPython可以使用%run,python shell可以使用os.system(‘python file.py’)等
其他启动选项
软件测试学习 之 Python 在不同场景中执行.py文件
嵌入式调用
在一些特定的领域,Python代码也许会在一个封闭的系统中运行。在这样的情况下,我们说Python程序被嵌入在其他程序中运行。
Python代码可以保存到一个文本文件中,存储在数据库中,从一个HTML页面获取,从XML文件解析等。
但从执行的角度来看,另一个系统(而不是你)会告诉Python去运行你创建的代码。
这样的嵌入式执行模式,一般用来支持终端用户定制的。例如一个游戏程序,也许允许用户进行游戏定制(及时在策略点存取Python代码)。用户可以提供或修改Python代码来定制这种系统。由于Python代码时解释性的,不必重新编译整个系统以融入修改。
在这种模式下,当使用Jython系统的时候,运行你的代码的外围系统可能是使用C、C++或者甚至Java编写的。
例:在C程序中通过调用Python运行时API中(Python在机器上编译时,创建的由库输出的一系列服务)的函数来创建并运行Python代码字符串:
#include C代码段中,用C语言编写的程序通过连接Python解释器的库,嵌入了Python解释器,并传递给Python解释器一行Python赋值语句字符串去运行。C程序也可以通过其他的Python API工具获取Python的对象,并处理或执行他们。
冻结二进制可执行文件
冻结二进制的可执行性是集成了程序的字节码以及Python解释器为一个单个的可执行程序的包。通过这种方式,Python程序可以向其他启动的任何可执行程序一样被启动。尽管这个选择对于产品的发售相当适合,但它并不是一个在程序开发阶段十一时用的选择。一般是在发售前进行封装(在开发完成之后)。
文本编辑器启动方式
尽管不是全套的IDE GUI,大多数程序员友好型文本编辑器都支持Python程序的编辑甚至运行等功能。这样的支持也许是内置的,或者可通过网络获取。
其他启动方式
例如jupyter,他的前端是一个Web页面,通过页面和服务器的交互,从而执行Python代码,但这个代码是否能够称之为程序,还只是个随笔,我之前虽然一直在用jupyter,但是还不知道更进一步的功能,只能说是ipython的扩展,但如果想把一个页面的片段整合成一个Python程序,也不难。
未来的可能
VR、小P小P
应该选用哪种方式
如果你刚开始学习Python,应该使用IDLE界面做开发,它提供了友好的GUI环境,并能够隐藏一些底层配置细节,为编写脚本,他还提供了一个与平台无关的文本编辑器,而且他是Python系统中的一个标准且免费的部分。
如果你是一个有经验的程序员,也许会和老王一样,一个编辑器,一个解释器就够了!
也许会有你自己的主观的选择!简单、丰富、多样、专一、方便、稳定、快捷?我试过好几个IDE,每个都有自己的特性,出去功能和扩展不说,剩下的就是喜好,有的编辑器编辑功能很舒服,但说不定调试运行就很拗!
调试Python代码
· 什么也不做,看报错信息
· 插入print语句,能比报错信息获取更多的信息,但是后期删掉或注释掉也比较麻烦
· 使用IDE GUI调试器,大多数开发工具都有调试器,IDLE也有,但并不常用
· 使用pdb命令行调试器
为了实现最终控制,Python附带了一个名为pdb的源代码调试器,可以作为Python的标准库中的一个模块使用。子啊pdb中,我们输入命令一行一行的步进执行,显示变量,设置和清楚断点,继续执行到一个断点或错误,等等。
你可以通过导入交互式的启动pdb,或者作为一个顶层脚本启动。不管采用哪种方式,由于我们可以输入命令来控制会话,他都提供强大的调试工具。他好包含了一个postmortem函数(pdb.pm()),可以在异常发生后执行他,从而获取发生错误时的信息。或使用Python的-m命令参数将pdb作为脚本运行
甚至jupyter都有方法跟踪调试,但并不方便。所以调试器是否顺手,也是选择心仪IDE的一个条件。
还有一个叫做PySnooper的神器,但是需要模块化,他将其下的模块所有变量信息输出,方便之后分析。
· 使用Python的-i命令行参数。
python -i m.py
这样无论m.py是成功运行完成还是出错停止,他都在python的交互式界面,测试可以查看他的变量信息。
c:\code>python -i exec1.py
a:1
b:2
c:3
d:4
e:5
f:6
g:7
h:8
j:10
j:10
k:11
l:12
m:13
n:14
o:15
p:16
q:17
r:18
s:19
t:20
u:21
v:22
w:23
x:24
y:25
z:26
>>> a
1
· 其他选项
如果有更具体的调试需求,你可以在开源领域找到其他工具,包括支持多线程程、嵌入式代码和进程附件的工具。例如Winpdb系统是一个独立的调试器,具有高级的调试支持、跨平台的GUI和控制台界面
当我们开始飙血较大的脚本,这些选项将变得更加重要。然而,关于调试最好的消息可能是在Python中检测出并报告错误,而不是默默的传递错误或最终导致系统崩溃,实际上错误本身是一种良好的机制,称为异常,我们可以捕获并处理他们。之后会讲到。
当然犯错并不好玩,尤其是面对一堆不可直视的数据时(一个十六简直计算器和仔细钻研成对的内存转储输出),有了Python的调试器支持,所犯的错误不会像没有调试器的情况下那样令人痛苦不堪。
本章小结
启动Python程序的一般方法:
交互的输入运行代码:python、ipython、jupyter、spyder
通过系统命令行运行保存在文件中的代码:py、python
文件图标点击:文件后缀名关联
模块导入:import m,reload(m)(from imp import reload)
exec调用:exec(open(’.py’).read())
IDLE这样的IDE GUI
本章习题
如何开始一个交互式解释器的会话
· 开始菜单 - Python目录 - Python
· 开始菜单 - Python目录 - IDLE (默认是加强版的交互式会话窗口)
· win+r 或者 cmd 直接运行 py 或者 python
· 若没有将python目录加入path,则需要完整python路径
在哪里输入系统命令行来启动一个脚本文件
· 系统shell,windows的cmd,linux的xterm等
运行保存在一个脚本文件中的代码的多种方法
· 在系统 shell中使用python加载或者直接运行
· 在系统界面双击图标运行
· 在python shell中当作模块,用import以及reload运行
· 在python shell中当作文本,用exec读入运行
· 在其他的IDE或者友好的编辑器中运行,例如在IDLE中,Run运行
· 注意UNIX的#!模式,兼容Windows
· 将字节码和解释器打包成冻结二进制可执行文件运行
· 在嵌入式模式下,被C、C++、Java载入运行
在Windows下点击图标运行的缺点
· 程序结束,窗口会关闭,可以在代码末尾增加一行input()
· 程序出错,窗口会关闭
以上问题如何解决
可以重设置输出为文本,但是毕竟是繁杂而多余,所以除非确定程序没问题,一般编程时还是在shell中输出
为什么你需要重载模块
一般,模块被python程序导入时,只会在那时运行一次,如果不想关闭python程序,而想更新这段代码或者想再次执行这段代码,就需要重载模块。
另:即便此时没有了.py,有对应的.pyc,就会载入对应的.pyc
以上常用在python shell的交互式编程中,而IDE编程,则会全部重新运行
IDLE的缺点
· 无法顺利运行tkinter GUI的程序
· 可能无法顺利运行多进程程序
· IDLE会自动导入当前代码的路径至pythonpath,而一般实际操作时不会有这项功能
命名空间与模块文件的关系
命名空间既是变量名有效的空间,如在一个模块中,变量名在其内部赋值后有效,在其他地方无效。
而当模块被其他模块加载时,加载它的模块就能使用被加载模块的变量名,即属性。 而如何去使用和加载的方式有关。
而因为命名空间的存在,一个程序的多个模块的内部变量命名不会有冲突。
命名空间就是变量(变量名)的封装。他在Python中以一个带有属性的对象的形式出现。
每一个模块文件自动成为一个命名空间。命名空间可以避免在Python程序中的命名冲突,文件必须显式的导入其他文件才能使用这些文件的变量名。
第一部分练习题
1、交互
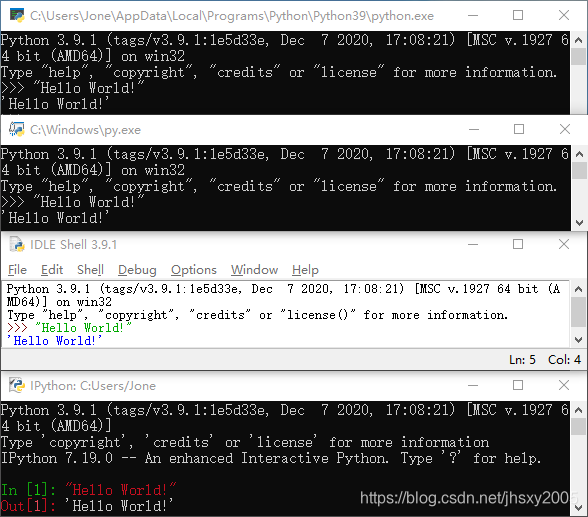
使用系统命令行、IDLE、或者其他工作方法,开始Python交互命令行,并输入表达式"Hello World!"


 2、程序
2、程序
使用你选择的文本编辑器,写一个简单的包含了单个打印"Hello module world!"语句的模块文件,并将其保存为module1.py。通过使用任何你喜欢的启动选项来运行这个文件。
· IDLE 内存32.4MB,语言英文,运行IDLE Shell
·
| IDE | 启动 | 内存 | 磁盘 | 语言 | 运行 | 备注 |
|---|---|---|---|---|---|---|
| IDLE | 快 3s | 32MB | Python预装 | 英文 | 交互Shell | 与紫光输入法略冲突,运行需要先保存 |
| PyCharm社区版 | 相当慢 35s | 662MB | 838MB | 中文插件 | 内置窗口显示python调用.py | 双击Shift不能改,启动很吃cpu |
| PyScripter | 比较快 4s+2s | 60.9MB | 26.1MB | 多国 | 调用Python控制台 | 多风格,好用,控制台支持自动补全选项,预设文件:注释、main |
| Spyder | 较慢 13s | 296MB | pip安装文件包100MB+ | 多国 | 调用IPyrhon控制台 | 原生Python程序,预设文件:code、注释,输入默认不会使用括号补全,对于从TC开始学的我来说,很友好 |
总体来说,PyScripter和Spyder的风格比较像,专门的Python IDE,布局简单,配置灵活,但两者因为实现方式的不同,启动速度、内存占用差异大。大家可以尝试后根据自己的喜好,机器的情况,选择。
PyCharm社区版是免费的,专业版增加了对web、html、js、sql的扩展。体积庞大,但作为完善的商业IDE,被世人认可。
VSC,ATOM都是多语言的编辑器,配置比较复杂,体积也庞大,如果是多语言编程者,可以试一下。
因为目前章节简单,我自己可能会选择PyScripter,简单快捷。日后会遇到调试相关,届时再对比一下。
 3、模块
3、模块
这里书上说,接上题,移动/删除.py,再次导入会怎样:
· 这次几个IDE都没有生成字节码,所以删除源代码之后,reload的话,直接报错,文件不存在,但源文件恢复位置后,再reload,是正常运行的。
· 以前运行PyCharm倒是会自动编译字节码来着,另外现在的字节码命名是*.cpython-39.pyc这样的,而python解释器是不会认为这个与*.py的关联性。
再者,python是搜索pythonpath的路径,而不包括其路径下的子目录。
而PyScript的python调用和ipython,他们导入模块的时候也是不会生成字节码的。
但基本上在顶层模块import目标模块,运行顶层模块时,会自动生成目标模块的字节码。
但因路径原因和文件名的原因,除非手动解决这两个问题,不然目标源码文件消失后,生成的字节码并没有任何的效果,reload也会显示文件不存在。
那么这里编译成字节码的目的只有一个,他不是为了目标模块源代码文件消失后仍能运行,而是为了在下次运行代码时而不再编译源代码,虽然它仍然保留了即便只有字节码也能运行的特色,但我并没有查到生成字节码文件名可以不用带cpython版本信息的。
4、脚本
顶层代码的首行的#!
在UNIX下是指对应解释器的位置,让后让解释器解释这个脚本。
而在Windows也有了对于#!的意义,即指定python的运行版本,这一行由写入了system下的py.exe启动器执行。
而UNIX下,python也只是一个启动器,真正的python解释器时类似于python3.9这样命名的!
5、错误和调试
>>> 1/0
Traceback (most recent call last):
File "" , line 1, in <module>
ZeroDivisionError: division by zero
当输入一个语句,Python会检查他的语法正确性,如果在语法上存在错误,会进行异常处理逻辑,打印出错误信息。而异常总是和Python中的调试概念密切相关的,Python关于异常的默认错误信息总是会为你的错误处理提供尽可能多的支持。而异常还可以自定义,例如自定义何种情况是异常,而不只是Python默认的那些异常。
6、中断
>>> L=[1,2] #L1
>>> id(L)
2223525440000
>>> L.append(L) #L2
>>> id(L)
2223525440000
>>> L
[1, 2, [...]]
>>> len(L)
3
>>> L=L+L #L3
>>> L
[1, 2, [1, 2, [...]], 1, 2, [1, 2, [...]]]
>>> len(L)
6
>>> id(L)
2223525504512
>>> id(L[2])
2223525440000
>>> id(L[0])
2223517362480
>>> id(L[2][0])
2223517362480
>>> L.append(L) #L4
>>> L
[1, 2, [1, 2, [...]], 1, 2, [1, 2, [...]], [...]]
道理我懂,但是不知道Python这样显示的解释具体是怎样的。
嗯,[…]的意思是,他是外一层,L3的时候,出现了它的外一层不是外一层的外一层,所以它只能在第三层写作[…]表示第三层是第二层,而第一层则是第二层的混合层,所以第二层无法写作第一层的[…]
而书中提到在1.5版之前的Python,可能是并不这样处理,以至于程序会无尽运行,所以需要按终端组合键来中止当前运行的程序。
那么在这里写一个必定会不断运行的程序,尝试Python的中断组合键!
while 1:
print("Help!")
书中写的中断组合键是
但是这个在Windows的Shell cmd中是无效的,大概是因为cmd为了符合用户的习惯,设定了Ctrl+C/V 是复制/粘贴,于是只能使用其他键实现
Windows上,运行VIM,他的复制粘贴快捷键是和UNIX一样的,也就是说UNIX上确实是Ctrl+C
7、文档
在你继续感受标准库中可用的工具和文档集的结构之前,至少花15分钟浏览一下Python库和语言手册,一旦你熟悉了,将会容易的找到你所需要的东西。