python-模拟登陆多种方法总结
python-模拟登陆
目录
python-模拟登陆
1.1、urllib
1.2.requests
三、selenium模拟登陆
3.1.常见的函数使用
3.2.html中的定位元素
1.find_element_by_id--定位id属性
四.socket模拟登陆
socket拓展:
环境:python3
一、已知cookie模拟登陆
测试网站:http://zxjf.ecjtu.edu.cn/
1.1、urllib
登陆一个网站,然后burpsuite抓包获取cookie,模拟登陆代码如下:
限制:比如测试的网站cooki是一个会话,当会话结束时,之前的cookie便过期了,此时再次模拟登陆将会失败。
#urllib.request:用于处理从 urls 接收的数据
from urllib import request
import json
#登录后才能访问的网站
url = 'http://zxjf.ecjtu.edu.cn/Student/index.aspx'
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie = r'ASP.NET_SessionId=jm4iqsy1aten3qdkxm5vcl4r'
##将url和请求数据处理为一个Request对象,供urlopen调用
req = request.Request(url)
#设置cookie
req.add_header('cookie', cookie)
#设置请求头
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36')
#用于实现对目标url的访问。
resp = request.urlopen(req)
#read()方法通过utf-8编码读取返回数据内容
print(resp.read().decode('utf-8'))
#print(resp.info()) #获取头部信息,包括Content-Type、Server、X-AspNet-Version、X-Powered-By、Cache-Control等常见字段信息
1.2.requests
#request获取
import requests
#登录后才能访问的网页
url = 'http://zxjf.ecjtu.edu.cn/Student/index.aspx'
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie = r'ASP.NET_SessionId=jm4iqsy1aten3qdkxm5vcl4r'
#把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
#在发送get请求时带上请求头和cookies
resp = requests.get(url, headers = headers, cookies = cookies)
print(resp.content.decode('utf-8')) #返回响应包的整个响应包
二、python模拟登录获取cookie和post获取cookie
先放一个大致的框架,后面的终极代码我们再看
模拟post请求获取返回包中的cookie
from urllib import request
import urllib.parse
import requests
#登录后才能访问的网站
url = 'http://jsnu.fuyunweb.com/manage/admin/pt_login.aspx'
data = {
"action":"login",
"uid":"用户名",
"pass":"密码"
}
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
resp = requests.post(url=url,data=data,headers=headers)
print(resp.status_code)#输出请求状态码
print(resp.url)#输出请求url
print(resp.text)#输出请求返回的内容
print(resp.headers)#输出响应包的请求头信息
print("set-cookie:" + resp.headers['Set-Cookie'])#输出cookie信息
返回的内容如下,
200
http://jsnu.fuyunweb.com/manage/admin/pt_login.aspx
success<$$$$>/manage/admin/admin_pt_main.aspx<$$$$>/manage/admin/admin_pt_order_mydbgd.aspx
#一下为输出的cookie信息
set-cookie:userinfo=; expires=Sat, 12-Dec-2020 04:23:18 GMT; path=/, userinfo=userid=ZTxan6d5Aja4AMMDe5yu&uid=pCRUyMSkr5XlOxie3ganHRdIJ7fQDe5yuDe5yu&pass=837A6C7DDD08D1629D0F1394190687EE&schoolid=7YTECdKVMaQDe5yu&cookid=bca6d466-da54-4f76-a41a-e03093d2867e; domain=jsnu.fuyunweb.com; expires=Sat, 02-Jan-2021 04:23:18 GMT; path=/; HttpOnly
cookie模拟登录:利用cookiejar获取cookie,然后利用获取的cookie再次去请求需要访问的访问的网页。代码如下:
#方法二:模拟post请求,获取cookie包,然后进行登录
#cookiejar获取并处理cookie参数。
from urllib import request
import urllib.parse
from http import cookiejar
import requests
#登录后才能访问的网站
auth_url = 'http://jsnu.fuyunweb.com/manage/admin/pt_login.aspx'
post_url = 'http://jsnu.fuyunweb.com/manage/admin/admin_pt_main.aspx'
data = {
"action":"login",
"uid":"用户名",
"pass":"密码"
}
post_data=urllib.parse.urlencode(data).encode(encoding='UTF8')
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
# 声明一个CookieJar对象实例来保存cookie
cookie = cookiejar.CookieJar()
# 利用urllib.request库的HTTPCookieProcessor对象来创建cookie处理器,也就CookieHandler
handler=request.HTTPCookieProcessor(cookie)
# 通过CookieHandler创建opener
opener = request.build_opener(handler)
# 获取cookie
req = request.Request(auth_url,post_data,headers)
resp=opener.open(req)
print(resp.info()['set-cookie'])
# 自动带着cookie信息访问登录后的页面
resp2=opener.open(post_url)
print(resp2.info()) #返回响应包中响应头顶的信息,不包活html页面的内容
#显示登录的页面结果
print(resp2.read())
对于info()和read()的返回结果我们通过输出结果来加深一下印象。
实际的响应包如下:
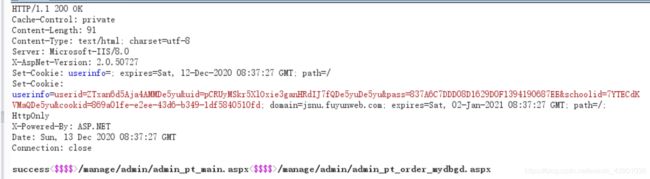
两个函数的的响应包分别来看一下:
- info():
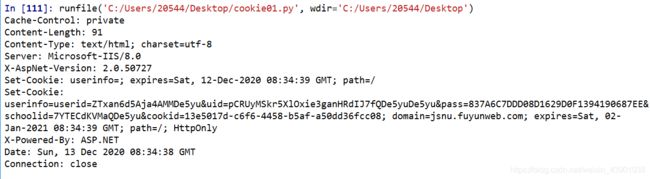
- read()

三、selenium模拟登陆
Selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
3.1.常见的函数使用
selenium.webdriver支持各种浏览器,包括谷歌、火狐、IE等浏览器,这里主要使用谷歌,不同浏览器操作区别不太。常用的几个函数包如下
from selenium import webdriver #基础模块应用,用来创建浏览器对象,操作浏览器
from selenium.common.exceptions import TimeoutException #异常处理
from selenium.webdriver.support.ui import WebDriverWait # 设置等待浏览器加载
3.2.html中的定位元素
html中的元素定位上面都准备好了之后,只要熟悉了html的定位就可以很好的进行模拟登陆了。元素查找分为以下几类:
(1)find_element_by_name------通过它的name属性单位到这个元素
(2)find_element_by_id--------通过它的id属性单位到这个元素。
(3)find_element_by_xpath-----如果一个元素它既没有id、name、class属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用xpath解决
(4)find_element_by_link_text--通过link超链接属性定位
(5)find_element_by_partial_link_text-有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了
(6)find_element_by_tag_name---每个元素都有tag(标签)属性
(7)find_element_by_class_name-通过它的class属性定位到这个元素
(8)find_element_by_css_selector
1.find_element_by_id--定位id属性
以百度搜索 框为例,id属性由浏览器-->F12寻找搜索框的id属性得来。如下:
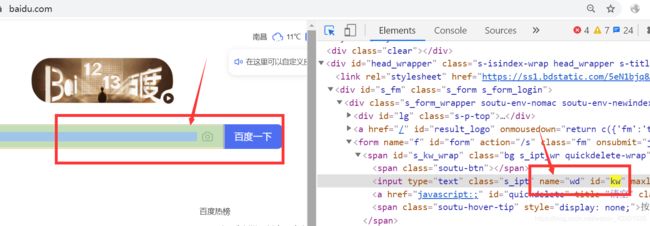
其他类似的属性:

link属性按钮比如hao123

from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
# 通过id属性定位百度搜索框,并输入“python”
driver.find_element_by_id("kw").send_keys("python")
# 通过name属性定位百度搜索框,并输入“python”--->可能会产生报错,主要是由于name属性不唯一
dirver.find_element_by_name("wd").send_keys("python")
# 通过class属性定位百度搜索框,并输入“python”
driver.find_element_by_class_name("s_ipt").send_keys("python")
# 从上面定位到的元素属性中,可以看到每个元素都有tag(标签)属性,如搜索框的标签属性,就是最前面的input-->直接运行是会报错的
driver.find_element_by_tag_name("input").send_keys("python")
# 通过link(超链接)属性定位hao123按钮,并点击
driver.find_element_by_link_text("hao123").click()
# 有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了
#partial_link是一种模糊匹配的方式,对于超长字符中的一段进行匹配
driver.find_element_by_partial_link_text("ao123").click()
# 通过xpath语法进行定位
driver.find_element_by_xpath('//*[@id="kw"]').send_keys("python")
find_element_by_xpath()------以上定位方式都是通过元素的某个属性来定位的,如果一个元素它既没有id、name、class属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用xpath解决
使用方法:chrome应用商店下载xpath helper插件,该插件在安装后,打开某个网页 拷贝目标页面元素的XPATH,如下图所示。copy的结果为:
//*[@id="kw"]/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/input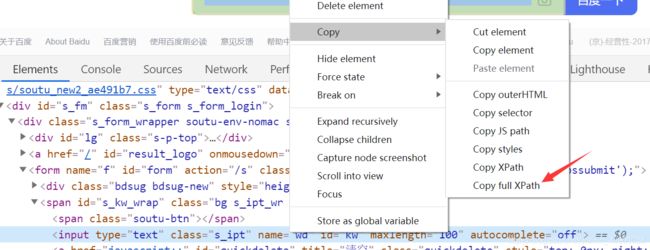
selenium模拟登陆的代码如下:
find_element_by_css_selector中的元素我 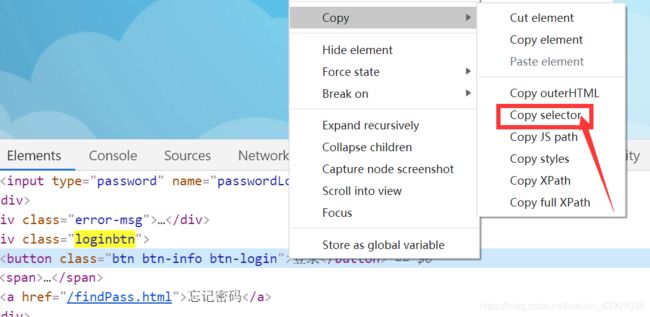 们可以在chrome中右边copy selector选择得出,具体如下图所示:
们可以在chrome中右边copy selector选择得出,具体如下图所示:
们可以在chrome中右边copy selector选择得出,具体如下图所示:
#方式三:selenium模拟登录
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('http://jsnu.fuyunweb.com/login2.html')
sleep(2)
driver.find_element_by_name("user").send_keys("用户名")
driver.find_element_by_name("passwordLogin").send_keys("密码")
sleep(2)
# find_element_by_css_selector中的元素在chrome中可以通过右键copy selector 进行选择
driver.find_element_by_css_selector("body > div.login2.log > div > div.loginbtn > button").click()#登录点击模拟
自动输入用户名和密码进行登录
四.socket模拟登陆
什么是Socket?
Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。
# 方式四:socket编程
import socket
from urllib.parse import urlparse
url = urlparse('http://XXX/login2.html')#登录界面
host = url.netloc #获取url中的host
path = url.path #获取url后面的路径
#data为抓到的响应包
data = '''
POST /manage/admin/pt_login.aspx HTTP/1.1
Host: jsnu.fuyunweb.com
Content-Length: 40
Accept: */*
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Origin: http://XXX
Referer: http:/XXX/login2.html
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: ASP.NET_SessionId=2fwb5pydk0htjy45nanudauf; userinfo=userid=ZTxan6d5Aja4AMMDe5yu&uid=pCRUyMSkr5XlOxie3ganHRdIJ7fQDe5yuDe5yu&pass=837A6C7DDD08D1629D0F1394190687EE&schoolid=7YTECdKVMaQDe5yu&cookid=9f729e29-a4d2-4b39-8bbc-068e2c7ab644
Connection: close
action=login&uid=用户名&pass=密码
'''
# 建立socke连接,如果是https请求需要使用ssl,例如:ssl.wrap_socket(socket.socket())
# ssl是专门用来处理https的模块,我们使用该模块的wrap_socket函数生成一个SSLSocket对象,使用前需要使用import进行导入
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host,80)) #建立连接
sock.send(data.format(path, host).encode("utf-8")) #发送数据
#recv_data = sock.recv(8192) #可以直接获取响应包的数据,以下循环纯属是用来对响应包格式进行一个规范的没有什么意义
recv_data = b""
while True:
d = sock.recv(1024)
if d:
recv_data += d
else:
break
recv_data = recv_data.decode("utf-8")
print(recv_data)
sock.close()
输出结果如下:
HTTP/1.1 200 OK
Cache-Control: private
Content-Length: 91
Content-Type: text/html; charset=utf-8
Server: Microsoft-IIS/8.0
X-AspNet-Version: 2.0.50727
Set-Cookie: userinfo=; expires=Sat, 12-Dec-2020 07:55:03 GMT; path=/
Set-Cookie: userinfo=userid=ZTxan6d5Aja4AMMDe5yu&uid=pCRUyMSkr5XlOxie3ganHRdIJ7fQDe5yuDe5yu&pass=837A6C7DDD08D1629D0F1394190687EE&schoolid=7YTECdKVMaQDe5yu&cookid=be8bf64b-430a-400c-b735-bd11ce65c6cc; domain=jsnu.fuyunweb.com; expires=Sat, 02-Jan-2021 07:55:03 GMT; path=/; HttpOnly
X-Powered-By: ASP.NET
Date: Sun, 13 Dec 2020 07:55:02 GMT
Connection: close
success<[ DISCUZ_CODE_2 ]gt;/manage/admin/admin_pt_main.aspx<[ DISCUZ_CODE_2 ]gt;/manage/admin/admin_pt_order_mydbgd.aspx
socket拓展:
一些来自于链接:https://www.cnblogs.com/limengda/p/10785719.html
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
socket又称为套接字,可以将其分为多种:
1.基于文件类型的套接字:AF_UNIX unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信2.基于网络类型的套接字:AF_INET/6 还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现,所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我么只使用AF_INET
一个生活中的场景。你要打电话给一个朋友,先拨号,朋友听到电话铃声后提起电话,这时你和你的朋友就建立起了连接,就可以讲话了。等交流结束,挂断电话结束此次交谈。 生活中的场景就解释了这工作原理。
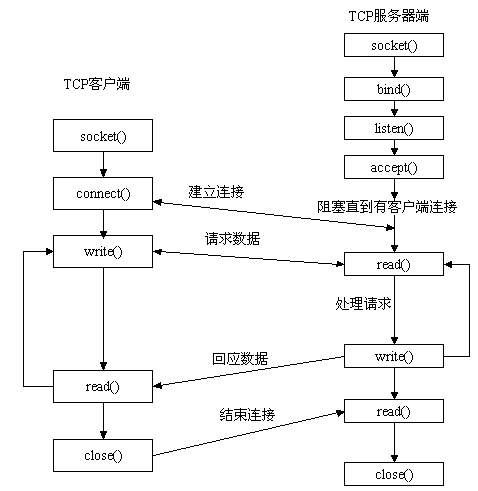
服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。
客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
# 获取tcp/ip套接字
tcpSock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 获取udp/ip套接字
udpSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 由于 socket 模块中有太多的属性。我们在这里破例使用了'from module import *'语句。使用 'from socket import *',我们就把 socket 模块里的所有属性都带到我们的命名空间里了,这样能 大幅减短我们的代码。
# 例如tcpSock = socket(AF_INET, SOCK_STREAM)
'''
# 涉及到的参数
AF_UNIX : 文件类型的套接字
AF_INET/6 :网络类型的套接字
SOCK_STREAM:提供面向连接的稳定数据传输,即TCP协议
SOCK_DGRAM :是基于UDP的,专门用于局域网
protocal : 协议默认为0填写的就是tcp协议
'''
# 服务端套接字函数
s.bind() 绑定(主机,端口号)到套接字
s.listen() 开始TCP监听,半连接池可以指定等待数量
s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
# 客户端套接字函数
s.connect() 主动初始化TCP服务器连接
s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
# 公共用途的套接字函数
s.recv() 接收TCP数据
s.send() 发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
s.sendall() 发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
s.recvfrom() 接收UDP数据
s.sendto() 发送UDP数据
s.getpeername() 连接到当前套接字的远端的地址
s.getsockname() 当前套接字的地址
s.getsockopt() 返回指定套接字的参数
s.setsockopt() 设置指定套接字的参数
s.close() 关闭套接字
# 面向锁的套接字方法
s.setblocking() 设置套接字的阻塞与非阻塞模式
s.settimeout() 设置阻塞套接字操作的超时时间
s.gettimeout() 得到阻塞套接字操作的超时时间
# 面向文件的套接字的函数
s.fileno() 套接字的文件描述符
s.makefile() 创建一个与该套接字相关的文件
PS:一些用户名和密码比较涉及隐私,就码掉了,调用函数这自行添加啊!
后记:
洗漱完了,想着模拟登陆的今天恰好写了一点,所以就想着先把日记搬过来再睡吧!此刻,日记结束,睡觉!晚安!今天看见一句话,不是很懂,但还是记录一下吧,语句如下:你的时间有限,所以不要浪费时间去过别人的生活。