基于机器学习的脑电病理学诊断
机器学习(Machine learning, ML)方法有可能实现临床脑电(Electroencephalography, EEG)分析的自动化。它们可以分为基于特征的方法(使用手工制作的特征)和端到端的方法(使用学习的特征)。以往对EEG病理解码的研究通常分析了有限数量的特征、解码器或两者兼而有之。对于I)更详细的基于特征的EEG分析,以及II)两种方法的深入比较,我们首先开发了一个全面的基于特征的框架,然后将该框架与最先进的端到端方法进行比较。为此,我们将提出的基于特征的框架和深度神经网络(包括EEG优化的时间卷积网络(temporal convolutional network, TCN))应用于病理性和非病理性EEG分类。为了进行强有力的比较,我们选择了天普大学医院(Temple University Hospital, TUH)的异常EEG语料库(2.0.0版),其中包含大约3000个EEG记录。结果表明,所提出的基于特征的解码框架可以达到与现有深度神经网络相同的精度。我们发现这两种方法的准确率都在81%到86%的范围内。此外,可视化和分析表明,这两种方法使用了相似的数据方面,例如,在颞叶电极位置处的delta和theta波段功率。我们认为,由于临床标签之间的不完全一致性,目前的二值EEG病理解码器的准确率可能达到90%左右,并且这种解码器已经在临床上有用,例如在临床EEG专家很少的领域。我们提出的基于特征的框架是开源的,从而为EEG机器学习研究提供了一个新的工具。本文发表在Neuroimage杂志。
关键词:机器学习 深度学习 脑电图 EEG 诊断病理学特征 黎曼几何 卷积神经网络
1.引言
利用机器学习方法进行EEG自动分析,特别是在基于EEG的临床诊断领域,引起了人们极大的兴趣。例如,它构成了检测和预测癫痫发作的基础,目的是警告患者即将发生的癫痫发作或控制大脑刺激以防止或停止癫痫发作活动。此外,机器学习允许基于EEG的睡眠分期过程的自动化,以及特定疾病和障碍的神经诊断,如阿尔茨海默病(Alzheimer’s disease, AD)、抑郁症(depression)、创伤性脑损伤(traumatic brain injuries),中风(strokes),意识障碍(disorders of consciousness),或一般EEG病理学。
有几个事实激发了人们对临床EEG自动诊断的兴趣。首先,临床EEG的评估往往是一个费时费力的过程。其次,它需要多年的训练来评估临床EEG记录中的病理变化。此外,即使是训练有素的EEG专家,诊断的准确性也受到许多限制。这在很大程度上取决于个人训练和经验、随时间变化的评级一致性、主观上经常定义的频带的不同滤波器设置中的时间限制以及潜在变化的阈值标准不明确,例如,与背景EEG相关的低振幅。因此,在评估EEG的评分者之间的信度是中等程度,即Grant等人(2014)发现神经学家将EEG记录归类为包括癫痫发作,减慢和正常活动在内的这七个类别之一时,Fleiss卡帕值为0.44(这个分数是用来评估多名评估员对于一系列观测样本的评估的一致性。Fleiss Kappa分越高,说明分歧越小,大家做出的判断都差不多,反之分数越低,分歧越大。维基百科上的分数和对应解释,一般0.8以上被认为基本完美的同意,0.6-0.8被认为大量的同意,以此类推。)。在将EEG记录分类为病理性或正常的更一般的任务中,Houfek和Ellingson等人(1959)以及Rose等人(1973)报告了基于两位神经学家的86%和88%的评分者间一致性。EEG自动诊断算法的发展可以为临床医生筛查EEG提供支持。它们不仅可以减少临床医生的工作量,而且可以更早地发现和治疗疾病,从而加强对患者的护理。此外,它们可以为无法到专门中心就诊的患者提供高质量的EEG解释和分类。
我们将EEG的机器学习大致分为两种方法:基于特征的方法和端到端的方法。基于特征的解码方法在不同的EEG解码任务中有着悠久的成功应用历史。在这种方法中,采用典型的手工和先验选择的特征来代表数据。例如,研究人员可以优先选择使用特定频段的频谱功率作为特征,如果他们假设这些频段对手头的解码任务有所帮助的话。然后可以手工进行精确的频带选择,例如在用于运动解码的共空间模式(common spatial patterns, CSP)算法中,或者它们可以通过自动特征选择来确定,例如通过滤波器组CSP (filter bank CSP, FBCSP)算法中的递归频带消除。这个过程依赖于研究人员的专业知识。如果先验特征决策是次优的,它会降低结果分析的质量。相反,由于其性质明确,分类决策的可解释性经常被认为是基于特征的解码的优势。
相反,端到端解码的方法接受原始或最低限度预处理的数据作为输入(端到端学习是一种解决问题的思路,与之对应的是多步骤解决问题,也就是将一个问题拆分为多个步骤分步解决,而端到端是由输入端的数据直接得到输出端的结果。其实也就是说,端到端将分步解决的中间步骤连接整合在一起,成为一个黑盒子,我能看看到的只是输入的数据和输出的结果,就是从数据的端,到了结果的端)。到目前为止,端到端深度学习吸引了人们的注意力,主要是因为它在其他研究领域的成功,如计算机视觉和语音识别。然而,它最近也通过将人工神经网络的深度学习成功应用于EEG分析而获得了势头。根据设计,网络自己学习特征,并允许特征提取和分类的联合优化。这一过程可以导致更好的解决方案或发现意想不到的信息特征,并且不需要手工制作,至少不需要提取特征。端到端模型在学习特性方面享有“黑箱”的美誉;理解他们所学的东西是深度学习领域的一个挑战,也是一个持续不断的主题。另一个常见的问题是,机器学习应用的复杂性只是从传统方法中的特征工程领域转移到网络工程领域,因为可能需要根据给定任务的要求手工制作网络。
在文献中,传统的基于特征和端到端的EEG机器学习分析缺乏系统的比较,尽管它们在广泛的应用中具有重要意义。特别是,尚无研究将基于大范围的时间、频率和连接特征的EEG病理解码的准确性与基于大量EEG数据集的成熟的端到端方法进行比较,以进行稳健的比较。过去对深度学习结果的比较通常只考虑其他深度学习结果,或者(更确切地说)对简单的有限特征集的基线进行比较(使用阈值、线性判别分析或线性回归)。这可能导致方法之间的不公平比较。此外,它会造成一种方法优于另一种方法的印象。实际上,在特定应用中,深度学习可能无法产生优于基于特征的解码的改进。最近,Rajkomar等人(2018)证明,在从电子健康记录预测医疗事件方面,逻辑回归可以与深度神经网络竞争。据我们所知,目前还没有研究将不同的深度神经网络结构与基于特征的方法进行比较,特别是使用多个领域的大量特征来解码EEG。然而,我们预计基于特征的方法和端到端方法之间的大规模比较对于超越当前技术水平的EEG机器学习技术的进步至关重要。在这两个重要领域中,以一种相互了解的方式开发方法,对于先进的基于特征的和新颖的端到端EEG方法都可能是卓有成效的。
在本文中,我们比较了使用深度神经网络的端到端解码和使用大量特征的基于特征的解码。我们使用天普大学医院(TUH)的异常EEG语料库设计了一项综合研究,大约有3000个记录,每个记录至少持续15分钟。这是TUH EEG语料库的一个子集,是迄今为止最大的公开可用的EEG记录集。对于基于特征的病理解码,我们使用随机森林(random forest, RF)、支持向量机(support vector machine, SVM)、黎曼几何(Riemannian geometry, RG)和自动sklearn分类器(auto-sklearn calssifier, ASC)——一个自动化的机器学习工具包。对于端到端的病理解码,我们使用三种类型的卷积神经网络(ConvNets,在其他出版物中也叫CNN),它们在不同的EEG解码任务中有成功应用的历史。这些是4层ConvNet架构(brain decode deep 4, BD-deep 4),已成功应用于运动解码、速度解码、病理解码。重要的是,我们使用Brain decode (BD,Available for download at https://github.com/TNTLFreiburg/braindecode.)——以前为EEG开发和评估的深度学习工具箱。此外,我们使用了一种通过神经架构搜索为EEG解码优化的TCN(时间卷积网络)。我们称之为BD-TCN。
据我们所知,目前有6个已发表的EEG病理解码结果,其中5个使用了TUH异常EEG语料库(表1)。然而,只有一份刊物使用了手工制作的特征,并通过CNN和多层感知器(multi layer perceptron, MLP)进行了分类。所有其他的论文都把这种基于特征的解码结果作为基准。尽管Amin等人(2019)和Alhussein等人(2019)报告了EEG解码病理学的最高准确性,但我们将其排除在直接比较之外。这些论文提到了预训练模型和额外的“10000个正常EEG记录”,这似乎是TUH异常EEG数据集的一个扩展,没有详细说明。在机器学习中,更多数据的影响通常大于更精细算法的影响。因此,直接与获得大量训练数据的刊物进行比较是不公平的。
本文结构如下。在第二节中,我们介绍了TUH异常EEG语料库,我们的研究基于此。然后,我们详细讨论了这两种方法的特点和深度学习流程,并解释了我们是如何评估和比较这两种方法的。本节最后讨论了我们用来帮助解释结果的分析方法。在第3节中,我们介绍并讨论了我们的结果,包括两个流程的广泛比较。我们在第4节进行了一般性讨论,并在第5节给出简要的展望和结论。
表 1 利用TUH异常EEG语料库进行病理解码的相关工作。所有方法都依赖于ConvNet架构。只有年代最久的刊物使用手工制作的特征。标有*的刊物使用了预训练模型和附加训练数据。标有+的刊物没有使用TUH异常EEG语料库。
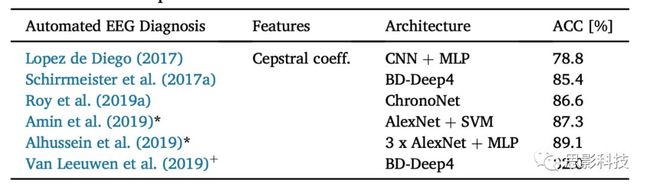
表 2 TUH异常EEG语料库(2.0.0版)中的记录数和患者数。对于某些患者,存在几种记录。对于发展组(development set)中的其他患者,存在正常和异常记录。患者在发展和最终评估集方面没有重叠。

2. 材料和方法
2.1. 数据
我们的研究基于TUH异常EEG语料库。该语料库包括从2329名独特患者获得的至少15 min持续时间的2993个记录,并由开发和单独的最终评估集组成(表2)。它包含各种年龄范围(7天-96岁)的男性和女性患者的记录,因此包括婴儿、儿童、青少年、成人和老年患者。在数据集中的患者中诊断的病理包括(但不限于)癫痫、中风、抑郁症和阿尔茨海默病,然而,仅提供二进制标签。该数据集包括医生报告,该报告提供了关于每个EEG记录的附加信息,例如主要EEG发现、患者正在进行的药物治疗和病史。在数据集的描述中,TUH报告的评分者间信度为97-100%。在文献中,所报道的分数通常要低得多。几乎完美的评分可能是由事先知道诊断的医学生对调查结果进行审查的结果。
2.2. 特征和端到端流程中的常见预处理
通常,在两种情况下,至少对原始EEG数据进行最小化的预处理,这依赖于手工特征提取和基于端到端的方法。我们将下面描述的预处理步骤应用于两种场景,以标准化输入数据的分布,从而稳定深度网络学习过程(深度学习应用程序中的常见做法),并稳定特征提取。但是,后者需要第2.4节中描述的附加步骤。重要的是,我们的一般预处理没有预先选择任何EEG特征。就像我们之前使用深层ConvNets进行的EEG病理学解码一样,包括以下预处理步骤:
首先,根据国际10–20的位置选择了21个电极位置的子集(图1),因为这些电极位置都出现在数据集里所有单独的记录中。
然后,丢弃了每个记录的前60秒,因为我们在此期间观察到了大量的记录伪迹,这可能是由于电极帽的重新排列或找到了舒适的就座位置造成的。此外,每次记录最多使用20分钟,以避免过长记录的大量特征生成和重采样时间。在之前的工作中,EEG记录被下采样到100 Hz,并以±800 μV来拒绝非生理极端值,并确保与这些先前研究的可比性。虽然Roy等人(2019a)在250 Hz下进行了实验,但我们选择使用100 Hz,以更好地与其他方法进行比较,并避免运动伪迹。然而,这可能会使我们在与Roy等人的直接比较中处于劣势。

图 1 TUH异常EEG语料库(2.0.0版)中包含的所有记录中常见的国际10–20放置的21个EEG通道子集的地形图。
2.3. 深度神经网络端到端解码
2.3.1. 神经网络体系结构
我们使用了包括ConvNets和TCN(时间卷积网络)在内的不同神经网络体系结构来从EEG记录中解码病理。首先,我们使用了Schirrmeister等人(2017b)先前介绍的称为BD-Deep4的四层ConvNet架构。BD-Deep4架构[图2]具有初始分离卷积(首先是时间的,然后是空间的)。随后,它具有由卷积和最大池化组成,并使用指数线性单元作为激活函数。它是一种相当通用的体系结构,已被证明可以很好地推广到多种EEG解码任务,例如运动(图像)解码,速度解码和病理学解码。我们应用了BD-Deep4,没有对其架构做任何进一步的调整。

图 2 Schirrmeister等人(2017b)介绍的四层BD-Deep4。初始分离卷积之后是几个卷积和最大池化
接下来,我们使用了Chrabąszcz(2018)在硕士论文中评估的TCN架构[图3]。最初由Bai等人(2018年)提出,作为递归神经网络(recurrent neural networks, RNN)的替代物。在他们的工作中,Bai等人(2018)证明了TCN在通常用于基准RNN的不同数据集的序列建模任务中始终优于RNNs。这是目前研究中最复杂、最深入的结构。Chrabąszcz (2018)的优化产生了由时间卷积组成的五个级别的组块,每个具有55个通道以及最大池化。我们称这种优化的架构为TCN(时间卷积网络)大脑解码(BD-TCN)。

图3 Bai等人(2018)介绍的TCN的总体架构和Chrabąszcz(2018)在硕士论文中探索的搜索基础,以找到BD-TCN
此外,我们使用了由Schirrmeister等人(2017b)引入的另一种ConvNet架构,称为Braindeocde Shallow ConvNet(BD-Shallow)。如同在BD-Deep4网络中一样,网络[图4]具有初始分离卷积;然而,这是整个架构中唯一的卷积。众所周知的FBCSP算法启发了BD-Shallow架构,特别是平方和对数非线性。它是专门为提取EEG信号频带功率的对数而设计的。我们应用了BD-Shallow,作为BD-Deep,没有对其架构做任何进一步的调整。
图 4 BD-Shallow体系结构,最初由Schirrmeister等人(2017b)引入,灵感来自FBCSP((filter bank CSP, FBCSP))算法
此外,我们使用了另一个名为EEGNet的ConvNet架构的重新实现,该架构最初是由Lawhern等人(2018)引入的。我们称这种重新实现为Braindecode Eegenet(BD-Eegenet)。同样,该架构具有一个单独的初始卷积。此外,该架构由于其参数数量少而引人注目。
2.3.2. 神经网络训练
按照Schirmeister等人(2017b)所述,用大小相等、最大重叠的裁剪对网络进行了裁剪训练。神经网络的感受野会自动决定裁剪的大小。所有网络一次暴露于大约600个信号样本中,除了具有大约900个样本的感受野的TCN。与Schirrmeister等人(2017a)的原始论文不同,本研究使用优化器AdamW代替Adam来最小化分类交叉熵损失函数。AdamW解耦了权重衰减的更新和损耗函数的优化,这允许更好的泛化。使用余弦退火来安排梯度和权重衰减更新的学习率,没有执行学习率的重新启动。
2.4. 基于特征的解码
2.4.1. 特征提取前的附加预处理
经过两个流程(pipeline)共同的一般预处理,在基于特征的流程(pipeline)中应用了几个附加步骤。在连通性特征提取的特殊情况下,首先将整个信号滤波到时域中选定的频率范围,以避免在信号段的起点和终点产生滤波伪像。将每个记录分成大小相等、不重叠的信号段,每段6s,最大限度地与端到端流程相当,在端到端流程(pipeline)中,结构的感受野决定段的大小。我们舍弃了±800 μV的值以稳定特征生成。
2.4.2. 特征提取
我们提出的基于特征的解码概念与文献中的概念有显著差异。我们计算了6个领域的50种特征类型,8633个特征[见表3],文献中通常使用小得多的特征集。例如,Hosseinifard等人(2013年)专门从theta、alpha和beta频带提取总功率来解码抑郁症。类似地,Lopez de Diego等人(2017)提取了起源于语音识别领域的单个特征类型(倒频谱系数-倒频谱分析是一种二次分析技术,是对功率谱的对数值进行傅立叶逆变换的结果)来解码EEG病理。Cai等人(2016)的工作就是一个具有大量特征类型的研究例子。他们提取了16种特征类型,包括振幅、时间和连通性测量来检测轻度抑郁。然而,在我们目前的研究中,我们策划了一个更大的特征集,其特征类型的数量是原来的两倍以上[表3]。
表 3 所有实现的特征按特征域排序。特征域、是连续小波变换/离散小波变换、傅立叶变换、患者信息、RG、连通性和时间。用*标记的特征是用PyEEG计算的。标记为的特征是使用PyWavelets计算的。
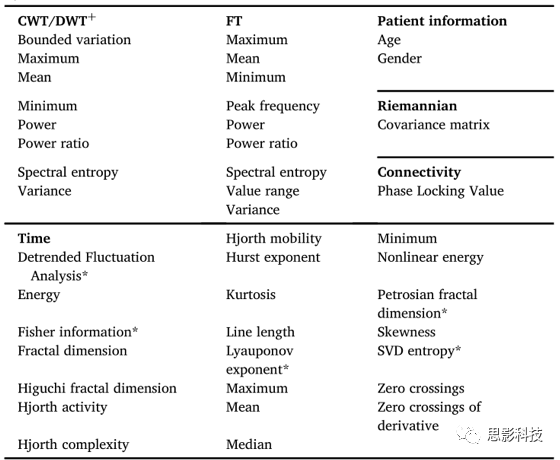
我们计算了描述EEG信号的时间、频率和连接结构的大量特征,这些特征都被用来表征EEG。我们基于离散傅里叶变换(Fourier Transform, FT)、连续和离散小波变换(Continuous and Discrete Wavelet Transform, CWT和DWT)以及基于希尔伯特变换的电极间连通性特征生成了每个分段的特征[表3]。此外,我们从欧洲数据格式中分析了患者的年龄和性别,记录头文件作为可选的附加特征。
对于连续小波变换、离散小波变换和傅立叶变换特征计算,我们使用Blackman-Harris窗函数对时域进行加权,以增强频谱估计并减少泄漏的影响。在初步实验中,我们测试了不同的窗函数。尽管窗口函数的选择对解码精度只有很小的影响,但Blackman-Harris窗口产生了最好的结果。我们使用傅立叶变换和50%的频带重叠从0-2 Hz、2-4 Hz、4-8 Hz、8-13 Hz、13-18 Hz、18-24 Hz、24-30 Hz和30-50 Hz频带中提取频率特征。我们选择的频段与文献中常用的频段相匹配。此外,当使用频带重叠时,我们在初步实验中观察到了优异的结果。我们为连续小波变换选择了小波尺度,为离散小波变换选择了等级,以尽可能地匹配这些频段。
对于连通性特征计算,我们使用希尔伯特变换对频率滤波的时间段进行变换,以提取信号相位。
特征向量的维数为F = 8631,包括域CWT、DWT、FT、连通性和时间在内的所有特征值。
时间分辨特征
对于每个记录特征生成的特征矩阵为Mi∈RCi×F,其中I是记录的总数,Ci是分析的6-s分段的数量,i∈I,而F是特征向量的维数。对于时间分辨解码,我们将每个分段的每个特征向量视为一个独立的例子。这极大地增加了训练实例的数量,这在训练阶段可能是有益的。然而,这也导致了更高的内存消耗和更高的学习时间。
聚合特征
对于聚合解码,我们计算所有时间-分段特征矩阵Mi∈RCi×F。因此,我们使用中值作为聚集函数,这样我们为每个记录获得了长度为F的单个特征向量。在以前的实验[Gemein (2017)]中,中值被证明是解码准确性方面的最佳聚合函数,尽管该选择只有很小的影响。聚合极大地减小了特征矩阵的大小,从而允许更快的学习和预测。然而,它的缺点是丢弃所有时间分辨的信息,因为它将一个记录的所有分段的特征折叠成单个特征向量。最终聚合特征矩阵的形状是Maggregate∈RI×F。
降维
我们在初步实验中专门使用主成分分析(principal component analysis, PCA)来降低特征维数。PCA的应用一直导致解码精度的降低。
协方差矩阵
对于基于黎曼几何的解码(与欧氏空间类似,在黎曼空间可以定义距离、面积、角度等概念,但这些概念与人的直觉往往相冲突。比如,人的直觉认为两点的距离是直线距离,这与欧氏空间相同,但在黎曼空间中,两点的距离是沿着流形的最短距离。这里往往用测地距离这个更一般性的概念来描述空间中两点的距离。在这些概念的基础上构建的一套数学工具被称为黎曼几何),我们对于每个分段计算了协方差特征矩阵∑i∈RCi×E*E。其中E是电极的数量。我们独立地测试了欧几里德和几何方法来聚合分段的协方差矩阵,这样我们获得了每个记录和聚合类型的长度为E*(E+1)/2的特征向量。最终协方差特征矩阵的形状是Mriemann∈RI×E*(E+1)/2。
2.4.3. . 基于特征的分类器
在特征生成之后,我们使用特征矩阵作为几个基于特征的机器学习模型的输入。我们使用了文献中常用的SVM与径向基函数(radial basis function, RBF)核。此外,我们使用了一个RF(随机森林)分类器,通过设计,它对过拟合是鲁棒的,因此是一个可靠的基准模型。此外,我们还应用了自动化的机器学习工具包ASC(Available for download at https://github.com/automl/auto-sklearn.),因为它有可能由于自动集成选择和超参数优化而产生更好的结果。最后,我们评估了基于黎曼几何的解码,该解码在Python包pyRiemann中实现,使用了具有径向基函数核的SVM,因为它最近在几个BCI解码任务中获得了最先进的结果。所有正在研究的模型都依赖于scikit-learn实现。
2.5. 性能评估
我们对发展组的记录进行了5折交叉验证(cross-validation, CV),这样每个记录都被精确地预测了一次。在拆分过程中,我们没有打乱数据;相反,我们使用按时间顺序排列的拆分。在CV期间,我们优化了基于特征的模型的超参数。
对于最终评估,我们在保留的最终评估集上评估我们的模型。我们在完整的发展集上训练模型,并在最终的评估集中预测示例。我们重复了五次最终评估,以管理由某些模型初始化引起的统计差异。
我们将发展和最终评估集示例的准确度分数报告为ACC,分别作为CV折和最终评估重复的平均值。
此外,我们还比较了基于最终评估预测的自助(bootstrap)精度分布的模型性能。对于每个模型,我们抽取相同的10000个自助样本,其中每个样本由100个随机选择的最终评估预测组成。然后,我们计算自举精度并绘制结果分布。
此外,我们使用了一个统计秩测试来验证预测标签在最终评估模型性能的优越性(H1)。我们在p-value<0.05时拒绝了零假设(H0:性能没有差异)。
2.6. 分析
手工制作的特征
因为我们实现了大量的特征[表3],我们对它们在决策过程中的重要性很感兴趣。RF通过数据拆分的“纯度”来估计特征的重要性。原则上,数据分割越纯,在森林的树中考虑特征越早,其重要性就越高。我们为第2.4节中描述的所有计算出的特征分配了文本标签,并使用RF将它们映射到CV中平均特征重要性。我们根据频带和电极位置的文本标签选择特征子集。然后,我们创建了特定频率范围内平均特征重要性的拓扑图。此外,我们计算了发展集上特征的斯皮尔曼相关性,并可视化了相关性图,因为显著的相关性可能是解释基于特征的分析的限制因素。
学习的特征
我们进行了输入信号扰动,以确定用于识别EEG中病理的信息频率范围和电极位置。我们计算原始和随机扰动输入信号的网络预测,并将振幅变化与预测的变化相关联。给定例子的标签,我们可以确定在给定频率范围内通过扰动增加(或减少)信号幅度是否有助于更多的病理(或非病理)预测。同样,我们绘制了拓扑图来表示与病理类别最相关的频率范围和电极位置。
2.7. 集合
在集合中,许多模型预测被组合在一起,以提供对单模型性能的改进。在模型产生不相关误差的假设下,一个组合可能导致错误的单模型决策的否决。我们计算了所有模型对CV预测的斯皮尔曼相关性,并可视化了得到的相关性图。请注意,ASC被排除在本次调查之外,因为它不提供内部的CV预测。对于集合,预测是加权的。单个模型预测的权重为“1”是一种特殊情况,相当于多数投票。我们首先基于非重叠标签错误的最高比率构建了三个模型的集合。然后,我们基于从单个模型预测中计算的标签的多数票来计算集合标签。另外,作为一种自动替代方案,我们研究了基于Caruana等人(2004)介绍的auto-sklearn(Available for download at https://github.com/automl/auto-sklearn.)的整体选择技术,自动选择模型进行整合,并根据验证集计算最佳权重。我们基于CV和单个模型的最终评估预测评估了两个集合的性能。
3.结果
3.1. 数据描述统计
我们在图5中呈现了TUH异常EEG语料库(2.0.0版)的发展集和最终评估集内的年龄分布直方图。年龄分布,尤其是女性患者的年龄分布,在发展和最终评估组之间存在差异。此外,病理性和非病理性病例也因性别和子集而异。相反,男性和女性患者的比例非常接近。可以观察到,标记为病理性的记录随着年龄的增加而出现得更频繁,这与直觉相吻合。
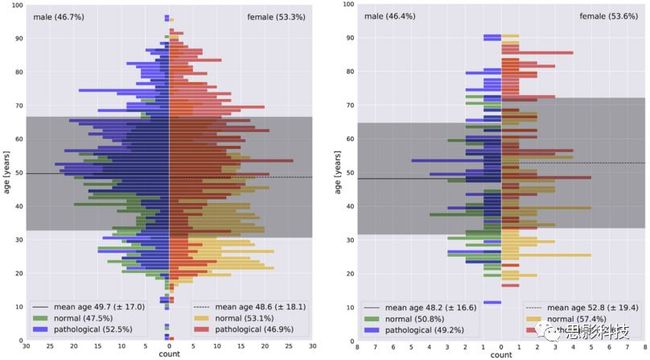
图5 TUH异常EEG语料库(2.0.0版)的发展(左)和最终评估(右)子集。直方图被构建为年龄金字塔,细分为男性和女性患者。不同的颜色编码表示病理性和非病理性EEG记录。
这些观察在两个方面很重要。首先,病理与年龄的相关性可能导致这样一种情况,即经过训练的模型使用患者年龄作为病理的替代。为了进一步研究患者年龄在EEG病理解码中的作用,我们将年龄作为一个特征纳入单独的分析(3.6)。相反,发展和最终评估集之间的系统差异会降低通用性,从而带来挑战。然而,病理与年龄的相关性以及发展和最终评估数据之间的变化都可能发生在实际应用场景中。因此,我们将TUH数据集的这些特性视为具有生态学意义和方法学意义的方面。然而,当解释在该数据集上获得的结果时,必须考虑它们。
3.2. 基于聚合特征的解码
我们在图6的右半部分给出了基于特征的聚合解码结果。基于黎曼几何的解码达到了近86%的准确率。有趣的是,解码准确率从CV中的81%提高到最终评估中的86%,这可能表明CV中的训练数据拟合不足。使用传统方法和基于特征的自动方法,我们获得了超过84%的准确率。

图 6 CV期间和最终评估中所有模型的解码精度。在Braindecode (BD-TCN)中实现的TCN表现性能最佳。基于RG的解码达到了类似于BD-TCN的精度。BD-Deep4和BD-Shallow转换网络、RF和ASC处于同一水平,而BD-Eegenet的解码精度略低。SVM表现最差。
此外,我们观察到,所有基于特征的模型的假阴性率都高于假阳性率;也就是说,它们更倾向于将病理性示例归类为非病理性而非相反(图7,底部一行)。这与Lopez de Diego(2017年)、Schirrmeister等人(2017年a)和Van Leeuwen等人(2019年)报道的结果一致。由于模型显示出较低的灵敏度[图7],它们未能识别一些患者的EEG病理。特别是对于医学筛查方法,这是不可取的,因为这些人仍然没有得到诊断。因此,性能改进是更可取的方法[见第5节]。
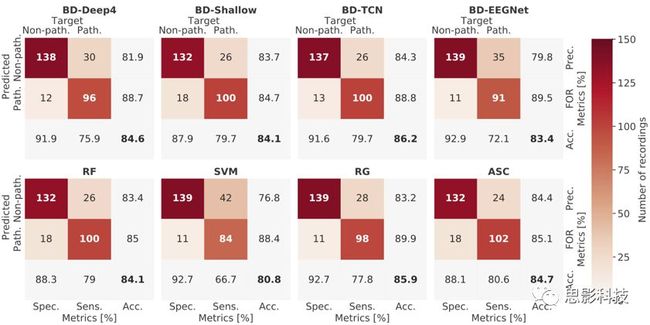
图 7 在独立的最终评估运行中平均的所有模型的混淆矩阵显示在左上角2×2个子矩阵。特异性(Spec.)、灵敏度(Sens.)、精度(Prec.),误漏率(FOR),准确率(Acc.)都表示出来了。所有模型都确定了更多的假阴性(病理样本预测为非病理)。
据我们所知,基于TUH异常EEG语料库,二进值病理学解码只有一个先前发布的基于特征的结果。使用倒频谱系数和CNN + MLP架构进行分类,可实现78.8%的准确性。因此,使用RG将基于特征的基准提高了7%以上,使用RF和ASC则将基准提高了5%以上。
基于黎曼几何的分类优于所有其他基于特征的模型,并达到85.87%的准确性。我们观察到用适当的自然空间度量(几何而不是欧几里得均值)处理协方差矩阵会产生更好的性能,这是可以预期的。
考虑到21个电极的协方差矩阵只有231个非冗余项,因此基于黎曼几何的解码的性能非常出色。协方差矩阵以及我们汇总的高维特征向量不包含详细的时程信息,并且在两种情况下,我们均对提取特征的分段的数量进行了平均。但是,结果表明,协方差矩阵中包含足够的信息,甚至优于使用手工特征的所有其他测试模型。类似地,如Sabbagh等人(2019)也使用了基于黎曼几何的解码,并发现了不错的结果。
ASC的应用有效地减少了建立和优化运作良好模型所需的时间和专家知识,并且其最终目标是使机器学习适用于非专家。我们可以确认,给定我们的一组特征,ASC在分类EEG病理学方面取得了竞争性结果,而无需用户交互。由ASC自动选择的集合包括AdaBoost,集合强度为78%(66%、8%和4%),梯度增强为18%,线性判别分析为4%。
3.3. 端到端解码性能
我们在图6的左半部分展示了深度神经网络的端到端解码结果。BD-TCN获得的总体最佳解码结果为86.16%的准确性。该精度非常接近以前使用ChronoNet报告的86.57%的精度。BD-TCN之后是BD-Deep4和BD-Shallow,准确率分别为84.57%和84.13%。 BD-EEGNet的解码准确率为83.41%。有趣的是,Heilmeyer等(2018)还发现,在跨不同任务和数据集的大规模基准测试中,将BD-Deep4与BD-EEGNet进行比较的准确性没有统计学上的显著差异。总体而言,这些网络在CV和最终评估中没有表现出比基于特征的方法那么多的性能差异。对于网络,基于特征的方法的差异在-0.6%到+ 0.4%的范围内,在-1.21%到+ 4.61%的范围内。同样,与基于特征的方法一样,我们观察到了更多的假阴性(图7,顶行)。因此,我们的观察结果表明,将CV与最终评估结果进行比较时,我们研究中使用的端到端方法可能更稳定。
我们还跟踪了所有应用网络的学习曲线(图8)。BD-Deep4和BD-Shallow的损失和误分类曲线在开始时是不规则的;但是,在分段20之后,它们变得更平滑。BD-EEGNet总体上显示出平滑的曲线,但是具有最高的损失和错误分类率。BD-TCN曲线表明训练对测试损失的最大差异。
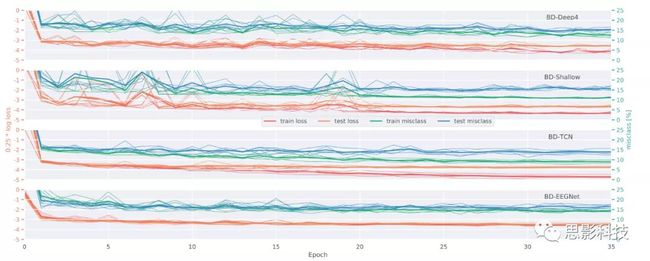
图 8 被调查网络体系结构的学习曲线。平滑趋势可以在epoch-20附近观察到,这可能是余弦退火的影响。BD-TCN实现了最低的误分类率。BD-Eegenet曲线是欠拟合的标志。
我们的结果表明,对于给定的任务,在解码精度方面,BD-TCN模型与ChronoNet是有竞争力的,ChronoNet是一种组合的ConvNet/RNN体系结构。BD-TCN优于所有其他网络,这可能是其通过神经架构搜索进行设计和优化的结果。所有其他模型最初都是为其他解码任务开发和优化的。它们在本研究中的表现突出了它们的普遍适用性。呈现的学习曲线显示出惊人的差异,我们假设它们是所研究的网络体系结构的特征。特别是对于BD-Deep4和BD-Shallow而言,在epoch-20附近曲线的平滑化可能是余弦退火更新学习速率的影响。在所有模型中,除了BD-EEGNet,我们都可以观察到训练损失和测试损失之间的明显差异。我们假设BD-EEGNet由于其参数数量相对较少而无法更好地拟合训练数据;它的学习曲线确实表明存在欠拟合的迹象。相反,过拟合无法观察到,这可能归因于正则化技术,即dropout或权重衰减。
3.4. 基于特征和端到端解码性能的比较
我们使用不同的模型和方法观察了相同范围内的解码精度,例如ChronoNet(86.57%),BD-TCN(86.16%),BD-Deep4(84.57%),ASC(84.71%),RF(84.06%),和RG(85.87%)。为了进一步研究性能,我们在图9中显示了自助法的精度分布。它们几乎是一致的,其中SVM是一个例外。但是,我们没有发现统计证据表明所研究的模型之一的性能优于其他模型。
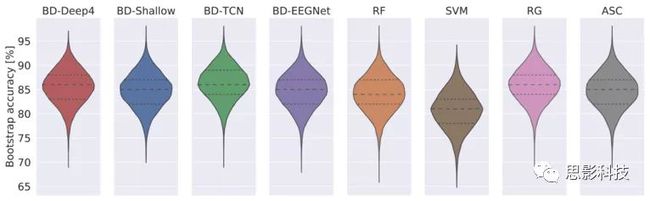
图 9 调查中所有模型的自助法精度分布。除了SVM,所有的分布都几乎全等。为了更深入地分析模型性能,我们提供了基于图10中的年龄和性别信息创建的子集的准确性,除了少数例外,例如对于30岁以下的男性患者,SVM模型在所有子集上都显示出非常相似的表现。总体而言,年轻女性患者的记录可以最高精度地解码,而老年女性患者似乎是最难解码的亚组。中年人是最一致的。

图10 不同子集的平均最终评估准确率性能概述。列显示不同的年龄类别,行显示性别。以前的文献[表1]已经表明,深度学习通常在使用TUH异常EEG语料库,解码病理学方面表现更好。这是因为只有一个使用手工特征的公开结果。这一基准似乎不是特别强,这使得深度学习方法显得更优越。然而,在这里,我们确定了基于特征和神经网络方法的类似解码精度。
3.5. 学习和手工制作的特征的重要性
通过使用BD-Deep4进行的扰动分析,我们确定了当振幅增加时与颞叶电极位置T3和T4上病理类别的预测之间的相关性(图11)。这种效应在delta和theta频率范围内尤为突出。相反,在枕部电极O1和O2处相关性的降低是alpha频率范围内最显着的影响。
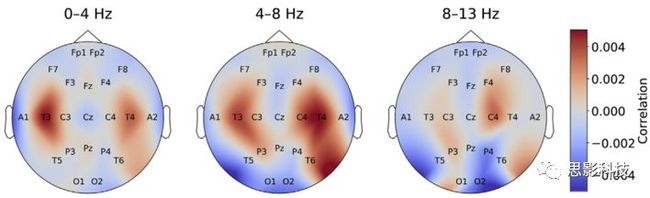
图 11 BD-Deep4网络的输入信号扰动显示,在颞叶电极位置(T3,T4)较高的活性是病理学的指示,特别是在低频范围(0-4 Hz和4–8 Hz)。在alpha频率范围内,枕部电极位置(O1,O2)与病理分级呈负相关。
为了与扰动分析进行比较,我们使用RF对特征重要性进行分析,给出了在相同频率范围内提取的重要手工特征(图12)。在颞叶电极T4处的delta和theta频率范围内提取的特征信息最丰富,这与扰动结果是一致的。然而,在电极T3处提取的特征不被认为是提供信息的。在alpha频率范围内,大多数信息特征是在枕部电极O1和O2处提取的。同样,这与扰动结果是一致的。
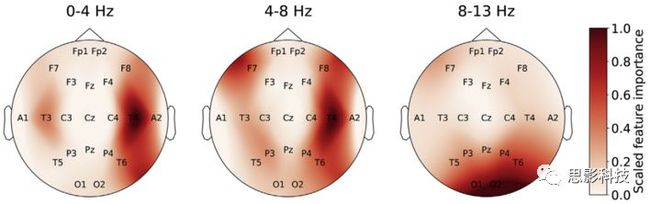
图 12 RF特征重要性分析表明,在0-4 Hz和4-8 Hz提取的特征在颞叶电极T4是最有用的。在8–13 Hz频段,枕部电极(O1,O2)具有最高的重要性值。
为了与扰动和特征重要性分析进行比较,我们展示了基于黎曼几何的解码流程(pipeline)中使用的类协方差矩阵的差异矩阵的值的可视化(图13)。可以观察到,在颞叶电极T3和T4处提取的方差最能指示病理。这与扰动分析是一致的。此外,如在扰动分析中一样,电极O1和O2(以及Fp1和Fp2)的差异指示正常的大脑活动。特征重要性分析强调了这两种观察结果。
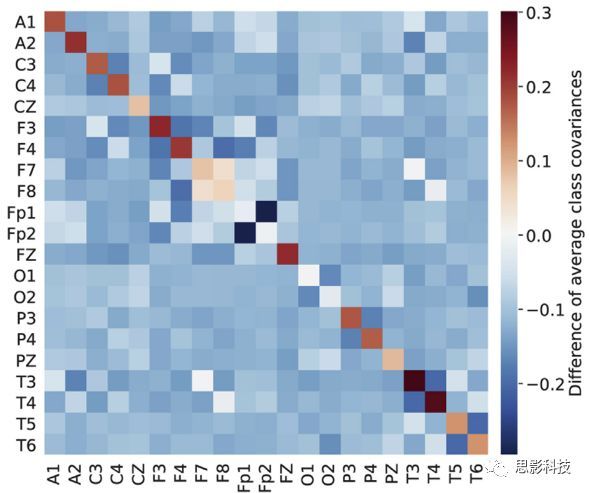
图13 映射到正切空间的平均协方差矩阵的差异(病理性-非病理性)。最能指示病理活动的值是在电极T3和T4提取的方差。只有O1、O2、Fp1和Fp2的差异表示正常活动。
为了进一步分析特征重要性和扰动结果的不同模式,我们计算了从delta,theta和alpha范围提取的特征的相关性[图14]。该图显示出很强的相关性,尤其是在theta和alpha波段。实际上,不管特征域、频带和电极记录位置如何,我们实际上观察到所有特征之间都有很强的相关性[图S2]。

图14 0-4、4-8和8–13 Hz频段的特征相关分析。对于每个电极(行),最高度相关的电极用白色十字标记。
3.6. 基于时间分辨特征的解码
受端到端流程(pipeline)中使用的分段解码(cropped-decoding)设置的启发,我们为基于特征的模型实现了时间分辨(非聚合)解码。然而,这并没有导致CV期间解码精度的提高,这就是为什么我们不再进一步研究此设置的原因。考虑到数据量的急剧增加,应该使用时间分辨解码来实现改进,如果不是在这里,则适用于不同的任务或数据集。对于给定的数据,这些改进实际上可以忽略不计。因为该任务涉及将EEG记录分类为病理性还是非病理性,所以在大时间尺度上演变的信号中可能没有信息。因为TUH异常EEG语料库(2.0.0版)并非癫痫发作或事件数据集,所以我们假设如果大脑活动中存在反映静态功能障碍(例如与结构性脑部异常有关)的连续变化,则它将被一致地指示。这也是我们的聚合解码方法的关键假设之一,该方法的性能与ConvNets一样[3.1]。如果此假设不成立,则聚合(尤其是使用中位数作为聚合函数)将导致由病理引起的效应变平滑。信号在较大的时间范围内变化的不同数据集中,时间分辨解码可以产生更好的解码性能。但是,必须考虑基于时间分辨特征的解码带来的挑战。在我们的研究中,与聚合解码相比,数据量增加了大约200倍。
3.7. 患者特定信息对解码准确性的影响
我们针对解码准确性调查了患者年龄和性别的影响,因为这些对于分类可能有用。因此,我们将患者的年龄和性别添加到我们的特征向量中,并作为BD-TCN的其他网络通道。在CV期间,分类准确率仅略有提高,例如,通过增加年龄和性别,RF CV准确率增加了0.15%(从83.1%增加到83.25%)。有趣的是,这与最近的刊物是一致的,在该刊物中,作者试图结合神经网络和患者的年龄信息来改善EEG对病理学的解码。他们还发现只有微小的,不显著的改善(ROC曲线下的+0.07面积)。
3.8. 集合解码性能
我们在表4中介绍了两种集成方法的结果。BD-Deep4,RF和RG模型的组合具有最高的不重叠CV标签错误率(336个错误,比率为44.56%),这就是为什么我们选择了他们进行多数投票。基于auto-sklearn的自动集合选择了SVM之外的所有模型,并基于CV预测计算出最佳权重[图4]。尽管auto-sklearn集合可实现总体最佳CV准确率(86.23%),但无论是基于多数投票的集合(85.51%)还是自动集合选择(85.14%)都没有在最终评估中产生优于最佳单模型性能(BD-TCN:86.16%)的改进。基于多数投票的准确率从CV到最终评估都有所提高,这可能是欠拟合的迹象,而基于于auto-sklearn的准确率有所下降,这可能是过拟合的迹象。表 4 两个集合的模型、权值和性能的集合调查结果。一个基于多数投票,一个由auto-sklearn自动选择。与最佳单模型性能相比,这两个集合都没有提高。

4.讨论
4.1. 深度端到端与基于特征的解码精度
我们目前研究的一个主要发现,连同Van Leeuwen等(2019)和Roy等(2019a)的结果,是EEG病理解码准确率在81-86%的狭窄范围内,我们比较了以下范围:
l分析策略:包括深度端到端、基于特征、自动化机器学习、基于RG;
l网络原型:包括ConvNet、TCN和RNN;
l网络架构:包括BD-Deep4、BD-TCN、BD-EEGNet、BD-Shallow和ChronoNet;
l基于特征的分类器和集成:包括RF、SVM和ASC;
l数据集:包括天普大学医院异常EEG语料库(2.0.0版)和Van Leeuwen等人(2019)使用的数据集。
重要的是,该范围也大大低于一个完美的分类得分(100%)。数十年的EEG研究表明,EEG诊断中的评估者间可靠性只有中等水平,最终导致标签噪声。关于标签噪声,在诊断EEG记录时,我们将专家错误称为病理性或非病理性,这会产生许多相互关联的后果:降低解码性能,增加所需数据量以实现可接受的解码性能,并增加模型复杂度以适当拟合数据。此外,标签噪声使相关特征的识别变得复杂。在Engemann等人的论文中也讨论了标签噪声在EEG解码中的作用。重要的是,在我们的设置中,较低的评分者间一致性和由此产生的标签噪声对理论上可实现的解码精度施加了限制,因为我们需要在单独的最终评估集中针对噪声标签进行评估。此外,我们没有获得任何独立于评分者的基本事实。有趣的是,据报道,在将EEG分为病理性和非病理性的二元分类中,评估者之间的一致性为86-88%,尽管这些分数仅基于两名神经科医师的EEG评分(可以基于TUH异常EEG语料库设计不同于病理解码的替代解码任务,例如解码患者性别或年龄)。考虑到这些数字,这里和之前Schirrmeister等(2017a)、Roy等(2019a)和Van Leeuwen等(2019)观察到的EEG病理解码准确率可能接近标签噪声施加的理论最佳值,约为86%。这个提出的假设可以在将来进行验证。但是,这将花费大量的精力。这将需要本研究中使用的大量数据集以及多个EEG专家的独立评级。大量的EEG数据正在医疗中心的档案中等待使用。更多的数据可能会带来积极影响,因为机器学习中的更多数据通常比更复杂的分类算法更有利。此外,通过大量神经病学家和/或癫痫病学家将EEG记录标记为病理性或非病理性将是改善标记质量的重要开端。然后,可以在每次记录的基础上将来自集合的评分者间的一致性分数包含在数据集中,使得它们可以被包含在详细的分析中。第一个是当前数据集的评分者间可靠性高于文献中通常报道的数字。第二个是,迄今为止研究的所有方法都没有提取或使用医生用来确定诊断的某些特征和信息。在第一种情况下,问题出现了,为什么端到端和基于特征的流程都不能更好地拟合和预测数据。在第二种情况下,出现的问题是医生使用了什么额外的信息来源,以及如何将其包括在内以提高绩效。这两个案例都会带来新的有趣的研究问题。在假设不正确且理论上最佳的EEG病理学解码精度较高的情况下,我们看到两个可能的非排他性原因。第一个是当前数据集的评估者间可靠性高于文献中通常报道的数字。第二个是,迄今为止研究的所有方法都没有提取或使用医生用来确定诊断的某些特征和信息。在第一种情况下,出现了一个问题,为什么端到端或基于特征的流程都无法更好地拟合和预测数据。在第二种情况下,出现的问题是医生使用了什么额外的信息来源,以及如何将其包括在内以提高性能。这两种情况都会带来新的有趣的研究问题。
4.2. 学习与手工制作的特征
基于我们的特征可视化,我们确定从颞电极位置在theta和delta范围中提取的特征被认为是有用的。癫痫病是统计学上最常见的大脑疾病之一,并且颞叶癫痫是最突出的癫痫,这可能是该区域在所有解码流程(pipeline)中确定病理学很重要的原因。请注意,尽管我们知道癫痫病是数据集中包括的一种病理,但我们既不知道确切的发作次数,也不知道其中有多少人患有颞叶癫痫。有趣的是,基于特征重要性分析,只有在电极T4处提取的特征在theta波段中才被认为是重要的。这与网络扰动结果和协方差矩阵可视化形成强烈对,在该范围内两个半球被认为具有同等的信息价值。给定决策树的机制,我们假设决策树在决策过程的早期选择了theta波段中T4处提取的特征,因为它们具有参考价值。然后,不选择在T3处提取的相同频带中的特征,因为它们不提供附加信息。因此,我们假设这些特征是高度相关的。我们的特征相关性分析揭示了在不同电极位置处提取的特征的几种强相关性,实际上,在T3处提取的特征与4-8 Hz频段中T4处提取的特征最相关(相关系数约为0.9)。通过我们的分析比较,我们确定了特征重要性的可视化由于强大的特征相关性而产生误导。通常,易于解释被认为是基于特征的方法相对于端到端方法的优势。但是,我们确定这种可解释性也存在局限性。Altmann等人(2010)也描述了具有RF特征相关性的陷阱。
4.3. 当前EEG病理学解码器的临床实用性
日常医疗应用通常需要比当前最先进的EEG病理解码更高的精度才能被接受。然而,当前范围内的精度解码流程(pipeline)可能是有价值的。例如,他们可以让无法进入专业中心的患者获得EEG诊断。这包括发展中国家的广大地区,那里很少有专门的中心和神经学专家。世界卫生组织(2019)称,全世界约有5000万人患有癫痫,其中绝大多数生活在发展中国家。在这些国家,除了疾病或紊乱之外,患者还经常遭受社会耻辱,因为在解决这些疾病和障碍方面缺乏诊断和经验。在我们看来,虽然诊断准确率约为86%,但自动诊断比根本不诊断要好。流程(pipeline)可用作预筛选方法,在检测到病理活动的情况下,可建议前往专业中心。
4.4. EEG解码评估的一般含义
我们对不同网络和分类器的统计相似的解码精度的发现对其他刊物也有启示。基于深度端到端学习的EEG解码论文经常将其结果与仅(而不是)简单的基于特征的方法进行比较,或仅将其结果与其他深度端对端学习结果进行比较。例如,对于基于TUH异常EEG语料库的病理学解码任务,与Lopez de Diego(2017)的结果相比,所有基于深度端到端学习的刊物都是如此。这给人的印象是,深度神经网络的性能大大优于基于特征的方法。然而,在这项研究中,我们证明了使用一种复杂的基于特征的方法,可以实现类似于深度端到端方法的解码结果。更准确地说,实际上没有统计证据表明所研究的网络的性能要比基于特征的方法更好。在不同于EEG解码的医学应用中,例如功能磁共振成像(magnetic resonance imaging, MRI)解码,已经进行了类似的观察。例如,He等人(2020)使用岭回归和包括ConvNets在内的不同原型的神经网络对传统机器学习方法进行了比较。他们在解码众多行为和人口统计指标时也发现了类似的模型性能。因此,我们再次强调,与强基准进行公平比较对于评估解码结果的质量至关重要。这不仅适用于EEG病理解码任务,而且通常也适用于一般的EEG解码任务。
4.5 解码流程(pipelines)的潜在改进
尽管我们为这项研究实现了许多不同领域的特征,但是该收集工作尚未完成。一个人可能实现的特征数不胜数,例如,在连通性领域,可以研究互相关,互相干,互信息,Ω复杂度,s估计量和全局场同步的使用。我们已经尝试增加患者的性别和年龄以改善分类。在临床诊断中,医生可以访问更多信息,例如病史和正在进行的药物治疗。如何将这些信息纳入决策过程是一个公开的挑战。
在本研究中提出的高维特征空间中,重新思考降维方法是很自然的。小的特征维数是有利的,因为它可以缩短学习时间并使解释更容易。尽管我们使用PCA进行的初步特征选择导致解码性能下降,但还有其他几种方法需要研究,包括独立成分分析(independent component analysis, ICA)或张量分解。此外,还可以尝试在提取特征和分类之前,通过应用源重建方法来提高信号质量。我们已经观察到,从颞叶电极位置提取的特征对于EEG病理学的解码非常有用。更精确的信号定位也可以提高分类精度。
在特征的实现中,有许多其他的基于特征的分类器可用。ASC自动选择了我们自己没有选择的模型,即AdaBoost和梯度Boost。但是,两个分类器通常都由决策树实现,决策树也构成了RF的基础。在其他分类器的应用中值得进一步研究。一个具体的例子是当执行基于时间分辨特征的解码时,本研究选择的模型还不能从数据的急剧增加中获益。
5.结论和展望
本研究目的不是暗示个别论文本质上是错误的,而是指出研究界可能从这些论文的综合结果可能会引起研究界的误解,并解决这些误解。具体地说,在先前关于TUH异常EEG语料库的文献中,没有强有力的尝试来改进基于特征的解码。基于特征的方法的唯一可用结果是Lopez de Diego(2017)的初始结果。
为了避免EEG病理解码中标签噪声的后果,我们建议解码1)患者的性别,以更好地评估基于特征和端到端流程(pipeline)的潜力,以及2)患者的年龄,以使用按时间顺序的年龄与预测的大脑年龄的差距作为病理指征的替代来源。在文献中,这一差距及其基于核磁共振扫描的估计被称为大脑年龄。
基于我们目前的研究,我们看到了自动化EEG诊断的美好前景。一个运行良好的流程(pipeline),实现上述改进选项,可能有助于解释EEG记录。它不仅可以为无法进入专业中心的患者提供EEG诊断,还可以在与人类专家团队相同的水平上实现早期病理检测,从而在一定程度上减轻神经疾病的全球负担。
如需原文及补充材料请添加思影科技微信:siyingyxf或18983979082获取,如对思影课程及服务感兴趣也可加此微信号咨询。觉得对您的研究有帮助,请给个转发支持以及右下角点击一下在看,是对思影科技莫大的支持,感谢!