【目标检测】01-物体检测基础知识&模型评价指标-深度学习pytorch之物体检测实战-学习笔记
01-物体检测基础知识&模型评价指标
- 物体检测基础知识
-
- 机器学习
- 深度学习
-
- 深度学习发展历程
- 深度学习的核心因素
- 深度学习在计算机视觉中的应用
- 计算机视觉
-
- 计算机视觉任务
- 物体检测技术
-
- 发展历程
-
- RCNN之前
- RCNN之后
- 两阶算法
-
- 优点
- 缺点
- 典型算法
- 多阶算法
- 一阶算法
-
- 优点
- 缺点
- 典型算法
- Anchor
-
- 典型算法
- 无Anchor
- 算法评价指标
-
- IoU(Intersection over Union)
- mAP(mean Average Precision)
-
- mAP计算过程
-
- 1 先决条件-预测值与标签值
- 2 Score 排序
- 3 计算正确预测框个数TP和误检框FP
- 4 计算召回率Recall和准确率Precision
- 5 计算Average Precision
- 6 计算mean Average Precision
物体检测基础知识
机器学习
与传统的基于规则设计的算法不同,机器学习的关键在于从大量的数据中找出规律,自动地学习出算法所需的参数。
深度学习
深度学习是机器学习的技术分支之一,主要是通过搭建深层的人工神经网络(Artificial Neural Network)来进行知识的学习,输入数据
通常较为复杂、规模大、维度高。
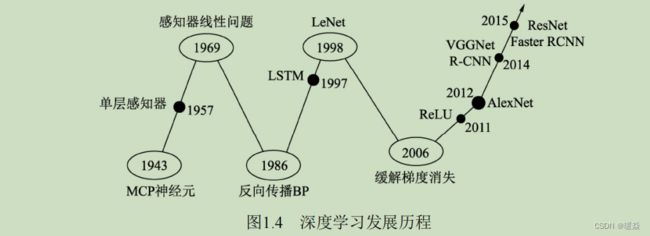
深度学习发展历程

深度学习的核心因素
模型
大数据
GPU
深度学习在计算机视觉中的应用

计算机视觉
计算机视觉则是研究如何使机器学会“看”的学科。
计算机视觉任务
图像分类
物体检测
图像分割
实例分割
物体检测技术
物体检测技术,通常是指在一张图像中检测出物体出现的位置及对应的类别。
要求检测器输出5个量:物体类别、xmin 、ymin 、xmax 与ymax 。当然,对于一个边框,检测器也可以输出中心点与宽高的形式,这两者是等价的。
发展历程
RCNN之前
深度学习做物体检测之前,传统算法对于物体的检测通常分为区域选取、特征提取与特征分类 3个阶段。
深度神经网络大量的参数可以提取出鲁棒性和语义性更好的特征,并且分类器性能也更优越。
RCNN之后
2014年的RCNN(Regions with CNN features)算是使用深度学习实现物体检测的经典之作。

在物体检测算法中,物体边框从无到有,边框变化的过程在一定程度上体现了检测是一阶的还是两阶的。
两阶算法
第一阶段专注于找出物体出现的位置,得到建议框,保证足够的准召率。
第二个阶段专注于对建议框分类,寻找更精确的位置。
优点
精度准更高。
缺点
速度较慢。
典型算法
Faster RCNN
多阶算法
例如:Cascade R-CNN
一阶算法
将二阶算法的两个阶段合二为一,在一个阶段里完成寻找物体出现位置与类别的预测。
优点
方法通常更为简单,依赖于特征融合、Focal Loss等优秀的网络经验,速度一般比两阶网络更快。
缺点
精度会有所损失
典型算法
典型算法如SSD、YOLO系列等。
Anchor
Anchor是一个划时代的思想,最早出现在Faster RCNN中。
Anchor思想的本质是一系列大小宽高不等的先验框,均匀地分布在特征图上,利用特征去预测这些Anchors的类别,以及与真实物体边框存在的偏移。
Anchor相当于给物体检测提供了一个梯子,使得检测器不至于直接从无到有地预测物体,精度往往较高。
典型算法
Faster RCNN和SSD
无Anchor
当然,还有一部分无锚框的算法,思路更为多样,有直接通过特征预测边框位置的方法,如YOLO v1等。
最近也出现了众多依靠关键点来检测物体的算法,如CornerNet和CenterNet等
算法评价指标
物体检测模型的输出是非结构化的,事先并无法得知输出物体的数量、位置、大小等,因此物体检测的评价算法较复杂。
IoU(Intersection over Union)
对于具体的某个物体来讲,可以从预测框与真实框的贴合程度来判断检测的质量,通常使用IoU(Intersection of Union)来量化贴合程
度。
使用两个边框的交集与并集的比值,就可以得到IoU。 I o U = A ∩ B A ∪ B IoU=\frac{A\cap B} {A\cup B} IoU=A∪BA∩B

显而易见,IoU的取值区间是[0,1],IoU值越大,表明两个框重合越好。
对于IoU而言,通常会选取一个阈值,如0.5,来确定预测框是正确的还是错误的。当两个框的IoU大于0.5时,认为是一个有效的
检测,否则属于无效的匹配。
mAP(mean Average Precision)
评测检测模型好坏。
通常使用mAP(mean Average Precision)这一指标来评价一个模型的好坏,这里的AP指的是一个类别的检测精度,mAP则是多
个类别的平均精度。
如图有两个杯子的标签,模型产生了两个预测框(虚线)。

mAP计算过程
1 先决条件-预测值与标签值
评测需要每张图片的预测值与标签值,对于某一个实例,二者包含的内容分别如下:
预测值(Dets):物体类别、边框位置的4个预测值、该物体的得分。
标签值(GTs):物体类别、边框位置的4个真值。
在预测值与标签值的基础上,AP的具体计算过程如图。

2 Score 排序
将所有的预测框按照得分从高到低进行排序(因为得分越高的边框其对于真实物体的概率往往越大),然后从高到低遍历预测框。
3 计算正确预测框个数TP和误检框FP
对于遍历中的某一个预测框,计算其与该图中同一类别的所有标签框GTs的IoU,并选取拥有最大IoU的GT作为当前预测框的匹配对象。
如果该IoU小于阈值,则将当前的预测框标记为误检框FP。
如果该IoU大于阈值,还要看对应的标签框GT是否被访问过。
如果前面已经有得分更高的预测框与该标签框对应了,即使现在的IoU大于阈值,也会被标记为FP。
如果没有被访问过,则将当前预测框Det标记为正确检测框TP,并将该GT标记为访问过,以防止后面还有预测框与其对应。
在遍历完所有的预测框后,会得到每一个预测框的属性,即TP或FP。
4 计算召回率Recall和准确率Precision
在遍历的过程中,可以通过当前TP的数量来计算模型的召回率(Recall,R),即当前检测出的标签框数量与所有标签框数量的比值 R = T P l e n ( G T s ) R=\frac{TP} {len(GTs)} R=len(GTs)TP。除了召回率,还有一个重要指标是准确率(Precision,P),即当前遍历过的预测框中,属于正确预测边框的比值, P = T P T P + F P P=\frac{TP} {TP+FP} P=TP+FPTP。
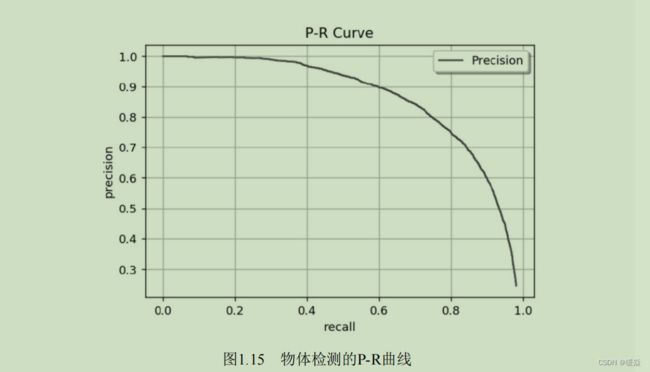
遍历到每一个预测框时,都可以生成一个对应的P与R,这两个值可以组成一个点(R,P),将所有的点绘制成曲线,即形成了P-R曲线。
即使有了P-R曲线,评价模型仍然不直观,如果直接取曲线上的点,在哪里选取都不合适,因为召回率高的时候准确率会很低,准确率高的时候往往召回率很低。
5 计算Average Precision
AP代表了曲线的面积,综合考量了不同召回率下的准确率,不会对P与R有任何偏好。严格意义上讲,还需要对曲线进行一定的修正,再进行AP计算。除了求面积的方式,还可以使用11个不同召回率对应的准确率求平均的方式求AP。
A P = ∫ 0 1 P d R AP=\int_{0}^{1}PdR AP=∫01PdR
6 计算mean Average Precision
每个类别的AP是相互独立的,将每个类别的AP进行平均,即可得到mAP。