Flink_Sql_Function——自定义各种函数
函数(Functions)
• Flink Table API 和 SQL 为用户提供了一组用于数据转换的内置函数
• SQL 中支持的很多函数,Table API 和 SQL 都已经做了实现
Ø 比较函数
• SQL:
- value1 = value2
- value1 > value2
• Table API: - ANY1 === ANY2
- ANY1 > ANY2
Ø 逻辑函数
• SQL: - boolean1 OR boolean2
- boolean IS FALSE
- NOT boolean
• Table API: - BOOLEAN1 || BOOLEAN2
- BOOLEAN.isFalse
- !BOOLEAN
Ø 算数函数
• SQL: - numeric1 + numeric2
- POWER(numeric1, numeric2)
• Table API: - NUMERIC1 + NUMERIC2
- NUMERIC1.power(NUMERIC2)


标量函数(Scalar Functions) 类似与map 进一个值返回一个值 。
• 用户定义的标量函数,可以将0、1或多个标量值,映射到新的标量值
• 为了定义标量函数,必须在 org.apache.flink.table.functions 中扩展基类
Scalar Function,并实现(一个或多个)求值(eval)方法
• 标量函数的行为由求值方法决定,求值方法必须公开声明并命名为 eval
class HashCode( factor: Int ) extends ScalarFunction {
def eval( s: String ): Int = {
s.hashCode * factor
}
}
package com.atguigu.sqlfunction
import com.atguigu.sourceandsink.SensorReading
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala._
import org.apache.flink.table.functions.ScalarFunction
import org.apache.flink.types.Row
object ScalaFunctionTest {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv)//默认blinkplanner
//读取数据
val inputStream: DataStream[String] = streamEnv.readTextFile(“in/sensor.txt”)
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val strings: Array[String] = data.split(",")
SensorReading(strings(0), strings(1).toLong, strings(2).toDouble)
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractorSensorReading {
override def extractTimestamp(element: SensorReading): Long = element.timestamp * 1000L
})
val sensorTable: Table = tableEnv.fromDataStream(dataStream,'id,'temperature,'timestamp.rowtime as 'ts)
//调用自定义函数 对id进行hash运算
//tableAPI
val hashCode = new HashCode(23)
val resultAPItable: Table = sensorTable.select('id,'ts,hashCode('id))
//sql调用
tableEnv.createTemporaryView(“sensor”,sensorTable)
tableEnv.registerFunction(“hashCode”,hashCode) //注册函数
val resultSqlTable: Table = tableEnv.sqlQuery(
“”"
select id,
ts,
hashCode(id)
from
sensor
“”".stripMargin)
resultSqlTable.toAppendStream[Row].print(“resultSqlTable”)
resultAPItable.toAppendStream[Row].print(“resultAPItable”)
streamEnv.execute()
}
}
//自定义标量函数
class HashCode(factor:Int) extends ScalarFunction{
//函数名必须为eval
def eval(s:String):Int={
s.hashCode*factor-10000
}
}
表函数(Table Functions) 返回任意数量的行 进入一行数据扩展成一个表 hive中的explode
一行对多行
• 用户定义的表函数,也可以将0、1或多个标量值作为输入参数;与标量函数不同
的是,它可以返回任意数量的行作为输出,而不是单个值
• 为了定义一个表函数,必须扩展 org.apache.flink.table.functions 中的基类
TableFunction 并实现(一个或多个)求值方法
• 表函数的行为由其求值方法决定,求值方法必须是 public 的,并命名为 eval
class Split(separator: String) extends TableFunction[(String, Int)]{
def eval(str: String): Unit = {
str.split(separator).foreach(
word => collect((word, word.length))
)
}}
package com.atguigu.sqlfunction
import com.atguigu.sourceandsink.SensorReading
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala._
import org.apache.flink.table.functions.{ScalarFunction, TableFunction}
import org.apache.flink.types.Row
object TableFunctionsTest {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv)//默认blinkplanner
//读取数据
val inputStream: DataStream[String] = streamEnv.readTextFile(“in/sensor.txt”)
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val strings: Array[String] = data.split(",")
SensorReading(strings(0), strings(1).toLong, strings(2).toDouble)
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractorSensorReading {
override def extractTimestamp(element: SensorReading): Long = element.timestamp * 1000L
})
val sensorTable: Table = tableEnv.fromDataStream(dataStream,'id,'temperature,'timestamp.rowtime as 'ts)
//调用自定义函数 对id进行hash运算
//tableAPI
val split = new Split("_")
val laterTable: Table = sensorTable.joinLateral(split('id) as ('word,'length))
val resultAPItable: Table = laterTable.select('id,'ts,'word,'length)
//sql调用
tableEnv.createTemporaryView(“sensor”,sensorTable)
tableEnv.registerFunction(“split”,split) //注册函数
val resultSqlTable: Table = tableEnv.sqlQuery(
“”"
select id,
ts,word,length
from
sensor,lateral table(split(id)) as splitid(word,length)
“”".stripMargin)
resultSqlTable.toAppendStream[Row].print(“resultSqlTable”)
resultAPItable.toAppendStream[Row].print(“resultAPItable”)
streamEnv.execute()
}
}
//自定义TableFunction
//将sernson_1打散 统计 输出为二元组
class Split(separator:String) extends TableFunction[(String,Int)]{
def eval(str:String): Unit ={
str.split(separator).foreach(
word=>collect((word,word.length))
)
}
}

package com.atguigu.sqlfunction
import com.atguigu.sourceandsink.SensorReading
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala._
import org.apache.flink.table.functions.{AggregateFunction, ScalarFunction, TableFunction}
import org.apache.flink.types.Row
object AggregateFunctionTest {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv)//默认blinkplanner
//读取数据
val inputStream: DataStream[String] = streamEnv.readTextFile(“in/sensor.txt”)
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val strings: Array[String] = data.split(",")
SensorReading(strings(0), strings(1).toLong, strings(2).toDouble)
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractorSensorReading {
override def extractTimestamp(element: SensorReading): Long = element.timestamp * 1000L
})
val sensorTable: Table = tableEnv.fromDataStream(dataStream,'id,'temperature,'timestamp.rowtime as 'ts)
//调用自定义函数 对id进行hash运算
//tableAPI
val avgTemp = new AvgTemp
val resultApiTable: Table = sensorTable
.groupBy('id)
.aggregate(avgTemp('temperature) as 'avgTemp)
.select('id, 'avgTemp)
//sql实现
tableEnv.createTemporaryView(“sensor”,sensorTable)
tableEnv.registerFunction(“avgTemp”,avgTemp)
val resultSqlTable: Table = tableEnv.sqlQuery(
“”"
select
id,avgTemp(temperature)
from
sensor
group by id
“”".stripMargin)
resultSqlTable.toRetractStream[Row].print(“resultSqlTable”)
resultApiTable.toRetractStream[Row].print(“resultApiTable”)
streamEnv.execute()
}
}
//自定义聚合函数
//求每个传感器的平均温度值 保存的状态为当前温度的和和个数
class AvgTemp extends AggregateFunction[Double,AvgTempAcc]{
//返回的结果
override def getValue(acc: AvgTempAcc): Double = {
acc.sum/acc.count
}
//初始化
override def createAccumulator(): AvgTempAcc = new AvgTempAcc
//还要实现一个具体的处理计算函数accumulate
//accumulator为
def accumulate(accumulator:AvgTempAcc,temp:Double)={
accumulator.sum+=temp
accumulator.count+=1
}
}
//定义一个类专门表示聚合的状态
class AvgTempAcc{
var sum=0.0
var count=0
}
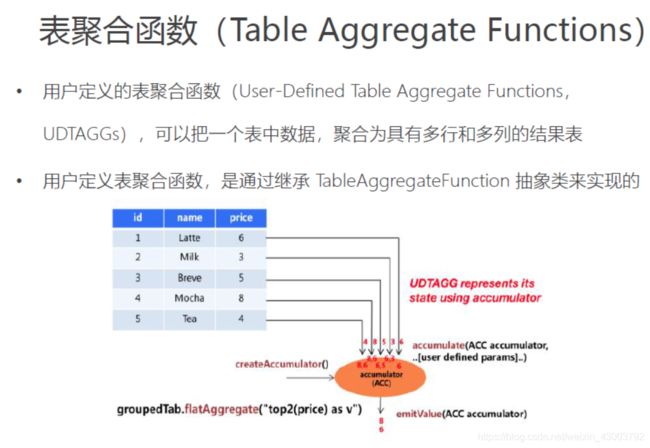
表聚合函数(Table Aggregate Functions) 多行对多行 top-N
• AggregationFunction 要求必须实现的方法:
– createAccumulator()
– accumulate()
– emitValue()
• TableAggregateFunction 的工作原理如下:
– 首先,它同样需要一个累加器(Accumulator),它是保存聚合中间结果的数据结
构。通过调用 createAccumulator() 方法可以创建空累加器。
– 随后,对每个输入行调用函数的 accumulate() 方法来更新累加器。
– 处理完所有行后,将调用函数的 emitValue() 方法来计算并返回最终结果。
**************实时更新最高的两个温度
package com.atguigu.sqlfunction
import com.atguigu.sourceandsink.SensorReading
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala._
import org.apache.flink.table.functions.{AggregateFunction, ScalarFunction, TableAggregateFunction, TableFunction}
import org.apache.flink.types.Row
import org.apache.flink.util.Collector
object TableAggregateFunctionTest {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv)//默认blinkplanner
//读取数据
val inputStream: DataStream[String] = streamEnv.readTextFile(“in/sensor.txt”)
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val strings: Array[String] = data.split(",")
SensorReading(strings(0), strings(1).toLong, strings(2).toDouble)
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractorSensorReading {
override def extractTimestamp(element: SensorReading): Long = element.timestamp * 1000L
})
val sensorTable: Table = tableEnv.fromDataStream(dataStream,'id,'temperature,'timestamp.rowtime as 'ts)
//调用自定义函数 对id进行hash运算
//tableAPI
val top2Temp = new Top2Temp
val resultApiTable: Table = sensorTable
.groupBy('id)
.flatAggregate(top2Temp('temperature) as ('temp,'rank))
.select('id, 'temp,'rank)
//sql实现
resultApiTable.toRetractStream[Row].print("resultApiTable")
streamEnv.execute()
}
}
//自定义表聚合函数 提取每个传感器所有温度值中最高的两个温度 输出(temp,rank)
class Top2Temp extends TableAggregateFunction[(Double,Int),Top2TempAcc] {
override def createAccumulator(): Top2TempAcc = {
new Top2TempAcc
}
//改变状态
def accumulate(acc:Top2TempAcc,temp:Double)={
//判断当前温度是否比当前温度值大
if(temp>acc.highestTemp){
acc.secondHighTemp = acc.highestTemp
acc.highestTemp = temp
}else if(temp > acc.secondHighTemp){
//如果在最高和第二高之间 替换第二高温度
acc.secondHighTemp = temp
}
}
def emitValue(acc:Top2TempAcc,out:Collector[(Double,Int)])={
out.collect(acc.highestTemp,1)
out.collect(acc.secondHighTemp,2)
}
}
//定义一个类用来表示表聚合函数的状态
class Top2TempAcc{
var highestTemp: Double = Double.MinValue
var secondHighTemp: Double = Double.MinValue
}