LLM应用构建解析
一、背景介绍
在不断发展的人工智能领域,语言模型占据了重要位置。随着ChatGPT受到广泛认可,语言模型,尤其是大语言模型LLM,成为科技领域的重要话题。这些模型在大量的文本数据上进行训练,使他们能够掌握复杂的语言模式与语义内容的细微差别。凭借前所未有的语言处理能力,LLM能够生成高质量内容,完成复杂语言处理任务。
以LLM模型为核心的开发框架的出现为自然语言处理打开了一个充满可能性的世界,我们可以用其创建各种应用程序,包括聊天机器人和智能问答工具。
本文将重点关注三个方面:
1、LLM应用的技术架构
2、LLM应用开发框架
3、LLM应用构建实例
二、LLM应用技术架构
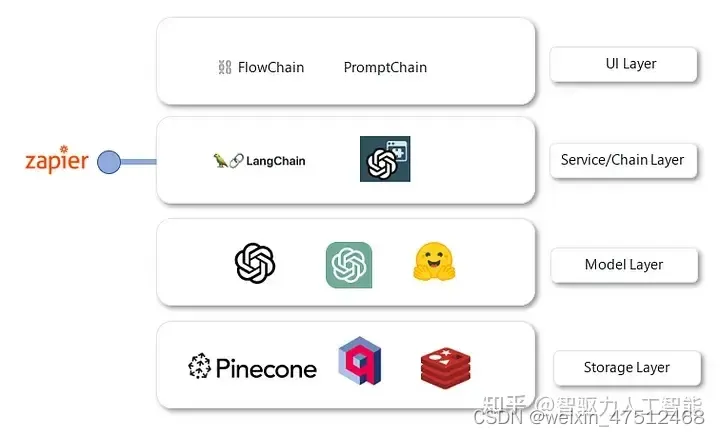
如上图,一个典型的LLM应用开发架构主要分为四层,详情如下。
(1)存储层:主要为向量数据库,用于存储文本、图像等编码后的特征向量,支持向量相似度查询与分析。例如,我们在做文本语义检索时,通过比较输入文本的特征向量与底库文本特征向量的相似性,从而检索目标文本,即利用了向量数据库中的相似度查询(余弦距离、欧式距离等)。
【代表性数据库】Pinecone向量数据库、Qdrant向量数据库等。
(2)模型层:选择需要调用的大语言模型,可以是OpenAI的GPT系列模型,Hugging Face中的开源LLM系列等。模型层提供最核心支撑,包括聊天接口、上下文QA问答接口、文本总结接口、文本翻译接口等。
【代表性模型】OpenAI的GPT-3.5/4,Anthropic的Claude,Google的PaLM,THU的ChatGLM等。
(3)服务层:将各种语言模型或外部资源整合,构建实用的LLM模型。Langchain是一个开源LLM应用框架,概念新颖,将LLM模型、向量数据库、交互层Prompt、外部知识、外部工具整合到一起,可自由构建LLM应用。
【代表性框架】:Langchain,AutoGPT,BabyAGI,Llama-Index等。
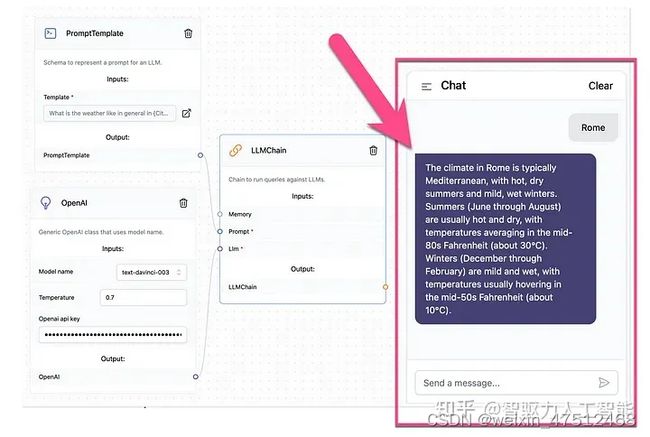
(4)交互层:用户通过UI与LLM应用交互,如langflow是langchain的GUI,通过拖放组件和聊天框架提供一种轻松的实验和原型流程方式。例如,我们想实现一个简单的聊天应用,我们输入“城市名字”,聊天机器人回复“该城市的天气情况”。我们只需要拖动三个组件:PromptTemplate、OpenAI、LLMChain。完成PromptTemplate、OpenAI、LLMChain的界面化简单配置即可生成应用。生成实例如下:
三、LLM应用开发框架
Langchain是一个大语言模型应用开发框架。它致力于将各种语言模型整合起来,并结合其他知识来源或外部能力,创建一个实用的应用程序。

如上图,langchain包含六部分组件,分别为:Models、Prompts、Indexes、Memory、Chains、Agents。
(1)Models(模型): 可选择不同的LLM与Embedding模型
大语言模型是Models的核心,同时也是Langchain的核心,这些模型包括OpenAI的GPT-3.5/4、谷歌的LaMDA/PaLM,Meta AI的LLaMA等。Text Embedding用于文本的向量化表示。例如,可调用OpenAI、Cohere、Hugging Face等Embedding标准接口,对文本向量化。
举个例子:
import os
from langchain.llms import OpenAI
openai_api_key = 'sk-F9O70vxxxxxlbkFJK55q8YgXb6s5dJ1A4LjA'
os.environ['OPENAI_API_KEY'] = openai_api_key
llm = OpenAI(model_name="gpt-3.5-turbo")
print(llm("讲个笑话,很冷的笑话"))
输出:
为什么鸟儿会成为游泳高手?因为它们有一只脚比另一只脚更长,所以游起泳来不费力!(笑)
以上是langchain调用OpenAI的gpt-3.5-turbo大语言模型的简单示例。
(2)Prompts(提示语): 管理LLM输入
当用户与大语言模型对话时,用户所说的内容即Prompt(提示语)。如果用户每次输入的Prompt中包含大量的重复内容,我们可以考虑生成一个Prompt模板,将通用的部分提取出来,用户输入输入部分作为变量。如下所示:
举个例子:
from langchain import PromptTemplate
name_template = """
我想让你成为一个起名字的专家。给我返回一个名字的名单. 名字寓意美好,简单易记,朗朗上口.
关于{name_description},好听的名字有哪些?
"""
# 创建一个prompt模板
prompt_template = PromptTemplate(input_variables=["name_description"], template=name_template)
description = "男孩名字"
print(prompt_template.format(name_description=description))
输出:
我想让你成为一个起名字的专家。给我返回一个名字的名单. 名字寓意美好,简单易记,朗朗上口.关于男孩名字,好听的名字有哪些?
以上为调用langchain的PromptTemplate的简单示例。Prompt模板十分有用,比如,我们想利用langchain构建专属客服助理,并且明确告诉其只回答知识库(产品介绍、购买流程等)里面的知识,其他无关的询问,只回答“我还没有学习到相关知识”。这时,可利用Prompt模板对llm进行约束。
(3)Indexes(索引):对文档结构化的方法
索引是指对文档进行结构化的方法,以便LLM能够更好的与之交互。该组件主要包括:Document Loaders(文档加载器)、Text Splitters(文本拆分器)、VectorStores(向量存储器)以及Retrievers(检索器)。

文本检索器:将特定格式的数据,转换为文本。输入可以是pdf、word、csv、images等。
文本拆分器:将长文本拆分成小的文本块,便于LLM模型处理。由于模型在处理数据时,对输入长度有限制,因此需要对长文本进行分块。不同语言模型对块的大小定义不同,比如OpenAI的GPT对分块的长度通过token大小来限制,比如GPT-3.5是4096,即这个分块所包含的Token数量不能超过4096。一般的分块方法:首先,对长文本进行断句,即分成一句一句话。然后,计算每句话包含的token数量,并从第一句话开始往后依次累加,直到达到指定的数量,组成为1个分块。依次重复上述操作。比如按照字母切分的Character,按照token切分的Tiktoken等。
向量存储器:存储提取的文本向量,包括Faiss、Milvus、Pinecone、Chroma等。
向量检索器:通过用户输入的文本,检索器负责从底库中检索出特定相关度的文档。度量准则包括余弦距离、欧式距离等。
(4)Chains(链条):将LLM与其他组件结合
Chain提供了一种将各种组件统一到应用程序中的方法。例如,可以创建一个Chain,它接受来自用户的输入,并通过PromptTemplate将其格式化,然后将格式化的输出传入到LLM模型中。通过多个Chain与其他部件结合,可生成复杂的链,完成复杂的任务。

LLM与其他组件结合,创建不同应用,一些例子如下:
- 将LLM与提示模板相结合
- 通过将第一个 LLM 的输出作为第二个 LLM 的输入来顺序组合多个 LLM
- LLM与外部数据结合,比如,通过langchain获取youtube视频链接,通过LLM视频问答
- LLM与长期记忆结合,比如聊天机器人
(5)Agents(智能体):访问其他工具
Agents是LLM与工具之间的接口,Agents用来确定任务与工具。一般的Agents执行任务过程如下:
- 首先,接收用户的输入,并转化为PromptTemplate
- 其次,Agents通过调用LLM输出action,并决定使用哪种工具执行action
- 最后,Agents调用工具完成action任务

Agents可以调用那些工具完成任务?
| 工具 | 描述 |
|---|---|
| 搜索 | 调用谷歌浏览器或其他浏览器搜索指定内容 |
| 终端 | 在终端中执行命令,输入应该是有效的命令,输出将是运行该命令的任何输出 |
| Wikipedia | 从维基百科生成结果 |
| Wolfram-Alpha | WA 搜索插件——可以回答复杂的数学、物理或任何查询,将搜索查询作为输入。 |
| Python REPL | 用于评估和执行 Python 命令的 Python shell。它以 python 代码作为输入并输出结果。输入的 python 代码可以从 LangChain 中的另一个工具生成 |
举个例子:
import os
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
openai_api_key = 'sk-F9xxxxxxx55q8YgXb6s5dJ1A4LjA'
os.environ['OPENAI_API_KEY'] = openai_api_key
llm = OpenAI(temperature=0)
tools = load_tools(["wikipedia","llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
print(agent.run("列举spaceX星舰在2022年后的发射记录?"))
输出:

如上图,agent通过调用wikipedia工具,对用户提出的问题回答。尽管gpt-3.5功能强大,但是其知识库截止到2021年9月,因此,agent调用wikipedia外部知识库对用户问题回答。回答过程如下:
- 根据用户输入的问题分析后,采取的Action为通过Wikipedia实现,并给出了Action的输入
- 根据分析得到了最相关的两页,并进行了总结
- 对最后的内容进一步提炼,得到最终答案
(6)Memory(记忆)
对于像聊天机器人这样的应用程序,它们需要记住以前的对话内容。但默认情况下,LLM对历史内容没有记忆功能。也就是说LLM的输出知针对用户当前的提问内容回答。为解决这个问题,Langchain提供了记忆组件,用来管理与维护历史对话内容。

langchain提供了不同的Memory组件完成内容记忆,下面列举四种:
ConversationBufferMemory:记住全部对话内容。这是最简单的内存记忆组件,它的功能是直接将用户和机器人之间的聊天内容记录在内存中。

ConversationBufferWindowMemory:记住最近k轮的聊天内容。与之前的ConversationBufferMemory组件的差别是它增加了一个窗口参数,它的作用是可以指定保存多轮对话的数量。

在该例子中设置了对话轮数k=2,即只能记住前两轮的内容,“我的名字”是在前3轮中的Answer中回答的,因此其没有对其进行记忆,所以无法回答出正确答案。
ConversationSummaryMemory:ConversationSummaryMemory它不会将用户和机器人之前的所有对话都存储在内存中。它只会存储一个用户和机器人之间的聊天内容的摘要,这样做的目的可能是为了节省内存开销和token的数量。


由上图可知,在第一轮对话完成后,Memory对第一轮对话的内容进行了总结,放到了摘要中。在第二轮对话中,LLM基于摘要与该轮的问题进行回答。
VectorStored-Backed Memory: 它是将所有之前的对话通过向量的方式存储到VectorDB(向量数据库)中,在每一轮新的对话中,会根据用户的输入信息,匹配向量数据库中最相似的K组对话。
四、LLM应用构建实例
1、本地文档知识问答助理(chat with pdf)
GPT几秒内读完了26页文档,并准确回答了我提出的问题。
需求描述:假设您有大量的本地文档数据。您希望通过问答的方式快速获取想要的知识或信息(例如,从公司产品资料中获取产品参数细节,从海量的公司资产资料中获取统计数据等),以便提高工作效率。
如果这个工作通过人力完成,需要做的工作:首先从大量资料中找到问题相关支撑材料;其次,对这些相关的支撑材料进行总结。
解决方案:langchain+llms
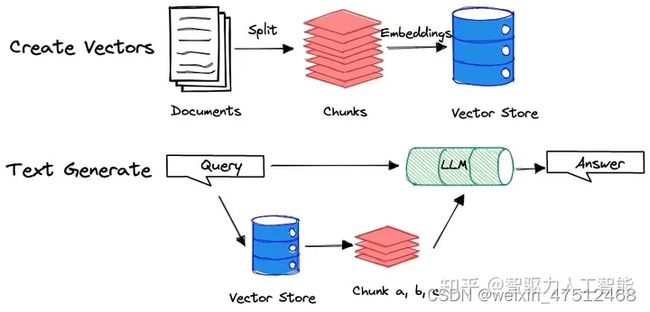
本地化知识专属问答助理构建过程可简单概括如下:
第一步:数据加载&预处理(将数据源转换为text,并做text split等预处理)
第二步:向量化(将处理完成的数据embedding处理)
第三步:召回(通过向量检索工具Faiss等对query相关文档召回)
第四步:阅读理解,总结答案(将context与query传给llms,总结答案)
(1)数据加载&预处理
import os
openai_api_key = 'sk-F9Oxxxxxx3BlbkFJK55q8YgXb6s5dJ1A4LjA'
os.environ['OPENAI_API_KEY'] = openai_api_key
from langchain.llms import OpenAI
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
from langchain import PromptTemplate
llm = OpenAI(model_name="gpt-3.5-turbo", temperature=0, openai_api_key=openai_api_key)
# data loader
loader = PyPDFLoader("data/ZT91.pdf")
doc = loader.load()
# text splitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=400)
docs = text_splitter.split_documents(doc)
加载pdf文件,对文本进行分块,这里每个分块的最大长度为3000个字符。这个最大长度根据llm的输入大小确定,比如gpt-3.5-turbo最大输入是4096个token。相邻块之间的重叠部分为400个字符,这样做的目的是每个片段保留一定的上文信息,后续处理任务利用重叠信息更好理解文本。
(2)向量化
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
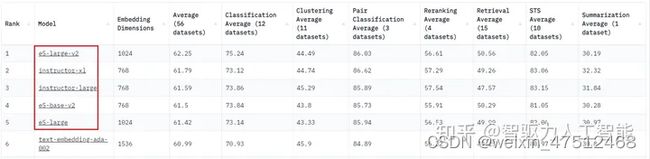
在这里调用的是OpenAIEmbeddings接口对文本进行向量化。在实际应用中,可以使用开源模型,如下所示(OpenAIEmbeddings用的是第6个)。同时,中文embedding效果优秀的模型有百度的ERNIE。
(3)召回
docsearch = FAISS.from_documents(docs, embeddings)
采用FAISS工具对输入文档构建FAISS索引,返回构建好的FAISS索引对象。创建FAISS索引包含的工作有:为索引分配内存空间;选择合适的索引类型与参数(比如Flat IVFFlat等);将文档向量添加到索引中。
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever(search_kwargs={"k": 5}),chain_type_kwargs={"prompt": PROMPT})
docsearch.as_retriever(search_kwargs={“k”: 5})表示返回前5个最相关的chunks,默认是4,可以修改
(4)阅读理解,总结答案
prompt_template = """请注意:请谨慎评估query与提示的Context信息的相关性,只根据本段输入文字信息的内容进行回答,如果query与提供的材料无关,请回答"对不起,我不知道",另外也不要回答无关答案:
Context: {context}
Question: {question}
Answer:"""
PROMPT = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
query = "实时画面无法查看,怎样解决?"
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever(search_kwargs={"k": 5}),chain_type_kwargs={"prompt": PROMPT})
qa.run(query)
输入:query+context
输出:answer
其中context为通过faiss retriever检索出的相关文档:retriever=docsearch.as_retriever(search_kwargs={“k”: 5}),query为用户输入的提问。
特别的,为了让gpt只回答文档中的内容,在prompt_template 增加了约束:“请注意:请谨慎评估query与提示的Context信息的相关性,只根据本段输入文字信息的内容进行回答,如果query与提供的材料无关,请回答"对不起,我不知道",另外也不要回答无关答案:”。即如果文档中没有用户提问相关内容,需要回答“不知道”,防止“答非所问”误导用户。
(5)效果验证
效果验证采用本公司的晓知精灵ZT91产品资料,一个26页的pdf文档,包含文字、表格、图片。验证中只对文本文字与表格文字处理。采用以上流程处理后,进行问答。
Question:请介绍如何快速接入设备?
Answer:
![]()
回答的答案正确。
Question:实时画面无法查看怎样解决?
Answer:

回答完整正确。
Question:告警数据的默认存储为几天?
Answer:

这个是表格中的数据,回答正确。
Question:晓知精灵的价格是多少?
Answer:

对于产品资料中没有答案的问题,其不会乱说。
【应用】:私域知识问答助理,智能客服,语义检索总结、辅助教学。
2、视频知识总结问答助理(chat with video)
GPT十几秒看完了8分钟视频,并准确回答了我提出的问题。
需求描述:youtube等视频网站上每天都会产生大量视频,虽然推荐系统按照我们的喜好进行了推荐,但观看大量有价值的视频依然面临挑战,如果我们能够快速了解视频内容,并得到我们关注的信息,将极大提高信息获取效率。
解决方案:langchain+transcript+llms
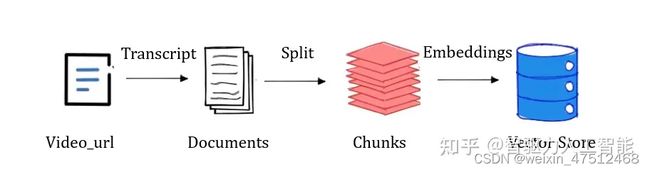
与pdf文档的处理方式不同,YoutubeLoader库从youtube视频链接中加载数据,并转换为文档。
# 加载 youtube 频道
loader = YoutubeLoader.from_youtube_url('https://www.youtube.com/watch?v=_rcnWQ0b2lM')
# 将数据转成 document
documents = loader.load()
其文档的获取过程是通过youtube-transcript-api获取的视频的字幕文件,这个字幕文件是youtube生成的。当用户将视频上传至youtube时,youtube会通过内置的语音识别算法将视频语音转换为文本。当加载youtube视频字幕文档后,接下来的处理工作与第一个例子类似。
原始视频:Elon Musk Unveils NEW Generation Robots. Tesla Investor Day 2023

下面是对视频内容的提问:
Question: “对视频中介绍的内容,逐条列举?”
Answer:

GPT对视频内容进行了总结,并列出了8条视频内容摘要,通过观看视频,给出的内容符合视频介绍。
【应用】:视频自动编目、视频检索问答。
3、表格知识总结问答助理(chat with csv)
GPT几分钟内容分析完了54万条数据,给出了我正确答案,完成了数据分析师1天的工作。
需求描述:假设您是一家零售商,您手头有客户的交易数据。您希望从数据中生成一些基本见解(例如按性别和年龄组划分的平均支出、每种类型的客户购买的产品、产品在哪个城市和商店的销售额最高,等等!),以便识别最佳客户。
这个问题陈述听起来像是数据分析师应该做的工作类型,而这正是它的本质。数据分析师将获取数据,编写一些 SQL 或 Python 或 R 代码,生成见解,数据分析师可能需要一天的时间来提供这些结果。
解决方案:langchain+llm+agents


(1) 按性别显示客户数量
我让gpt帮我显示表格中用户的数量,执行情况如下:
举例:
import os
from langchain.agents import create_csv_agent
from langchain.llms import OpenAI
openai_api_key = 'sk-F9O70vxxxxxxxBlbkFJK55q8YgXb6s5dJ1A4LjA'
os.environ['OPENAI_API_KEY'] = openai_api_key
agent = create_csv_agent(OpenAI(openai_api_key=openai_api_key,temperature=0),'train.csv',verbose=True)
agent.run("请按照性别对用户数量进行显示?")
输出:

经过验证,agent给出的答案完全正确。
(2) 年龄与消费金额之间相关性分析
我让gpt帮我分析下年龄与消费金额之间的相关性,执行情况如下:
举例:
agent.run("在这份表格中,年龄与消费金额是否存在相关性?")
输出:

agent进行了相关性分析,年龄与消费成正相关,但是相关性很弱。
(3) 产品销售量统计并画出柱状图
我让gpt帮我统计每种产品的销售总量,并画柱状图,执行情况如下:
举例:
agent.run("产品1总量,产品2总量,产品3总量分别是多少,将三个总量通过柱状图画出来并显示")
输出:
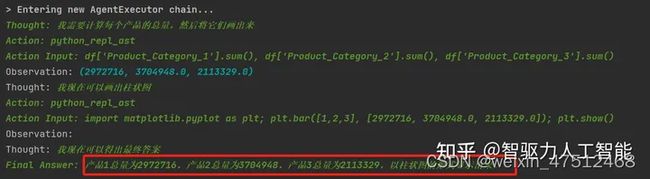

agent理解了我的指令,将产品1,产品2,产品3的总量进行了计算,并画出了柱状图。
【应用】:商业数据分析、市场调研分析、客户数据精准分析等。
总结:大语言模型的突破加速了人工智能的行业应用,未来不仅prompt engineering,且以llm为核心的application将不断涌现。在开发llm basic model的同时,利用llm引擎开发高质量的llm应用,不断释放应用价值与商业潜力。我们正处于人类与计算机交互方式的一场革命的开端,在短短几年内,我们使用的每个应用程序都可能将以某种方式由LLM 提供支持。
参考文献
【1】 ️ LangChain | ️ LangChain
【2】Build an LLM-powered application using LangChain
Edited by Lucas Shan