计算机视觉未来走向:视频理解等5大趋势详解

作者:廖康,北京交通大学信息科学研究所
校对:梦佳
智源导读:近年来,深度学习在各种计算机视觉任务上都取得了重大的突破,其中一个重要因素就是其强大的非线性表示能力,能够理解图像更深层次的信息。本文针对CV+Deep Learning未来的走向进行了展望,其中包括CV与Learning之间的关系、CV面向不同场景以及Learning面向不同场景等多方面的延展。(本文系智源社区成员投稿)
01
「Learning-based CV」to 「CV-based Learning」
得益于神经网络较强的学习能力,很多视觉任务都被丢入一个黑盒中,然而神经网络直接从像素上对场景进行感知是不够的。对于具体的任务,我们需要利用CV中的原理和技术点对其进行解剖和建模,然后再利用深度学习中的网络架构/工具进行相应的特征提取与任务决策。
这里举个例子,CV中有一个很具有挑战性的任务是3D from Monocular Vision,即从单目图像进行三维重建与感知。目前很多方案都是通过强监督学习方式直接对深度信息进行预测或者直接在2D图像上进行3D任务。
在计算机视觉中,我们知道,从三维世界坐标系到二维相机坐标系是经过了一个透视变换的,因此不同深度的物体才被投影到了同一个平面上(如图1所示)。如果利用这种变换关系去显示地指导神经网络学习或者利用可逆网络去学习这种变换关系,会更加贴合真实场景中的应用。如Marr Vision所描述的,对于一个图像/场景的感知需要经过"2D-2.5D-3D"的过程,然而在Learning-based CV中,诸如此类的视觉原理都被简单粗暴的2D Convolutional Kernel给卷掉了。因此,CV + Deep Learning整个体系的后续发展应该会从Learning-based CV转到CV-based Learning,对于不同的视觉任务融入相应的CV原理并建模Learning方式。

图1:Ideal Projection of a 3D Object on A 2D Image
02
「Clean CV」to「Wild CV」
目前热门的视觉任务如目标检测、语义分割、深度估计等都已被“卷er”们刷爆各大榜单,其中所用到的大多数数据集都是非常干净的。然而在真实场景中,常见的噪声如径向畸变、光照、运动模糊、雨雾等都会通过改变物体的纹理结构而改变其语义特征,因此造成算法的泛化性不强、换个数据集就崩的现象。一个很直接的解决方案是Image Restoration + CV Task,即在做具体CV任务之前直接还原一个干净的场景。但是有一点需要注意的是目前Image Restoration很多都是基于图像生成式,在去噪的过程中常常会引入新的图像信息,这种顾此失彼的操作对很多下游任务是不能接受的。
对人来说,我们的日常视觉任务很少经过Image Restoration这一步,而是直接在存在各种噪声的情况下进行感知与决策。其中一个最主要的原因是我们已经见过各种场景下的相同物体,即人通过视觉系统所提取到的特征对于噪声具备较好的不变性。相比之下,目前Clean CV所做的事情可能更多关注的是提取对具体任务有帮助的特征,而这种Feature Bias会影响算法的泛化功能。
03
「Single-Frame CV」to「Sequence CV」
Video Understanding是一个未来可期的方向,近些年兴起的“小视频”等新消遣方式大大增加了该方向的人才需求,一些大厂如阿里、腾讯等也在悄然布局。先抛开工业界需求不说,来聊一些具体的技术点。
视频相较于图像而言具有一个绝佳的优势——时序性。这一优势产生的前后帧相关性能够促使弱监督学习和自监督学习等得以更好地应用,人类也是在这样一个动态的世界里利用仅有的标签信息不断地学习与认知。同时,在Sequence CV中,Frame之间的“迁移学习”也是值得探索的,即如何利用少量前序帧中学习到的知识去启发大量的后序帧。对于视频的海量数据对显卡资源产生的负担,视频浓缩(Video Synopsis)等技术可能会带来新的突破。
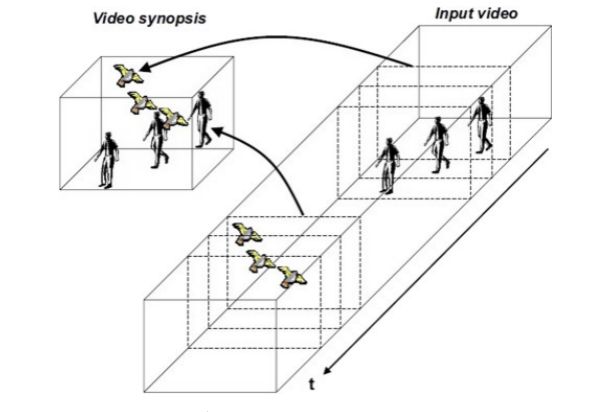
图2:Video Synopsis
04
「General Pre-training CV」to「Specific Pre-training CV」
众所周知,Pre-training on ImageNet在CV中是一个通用且有效的策略。但是,一些工作表明这种策略对不同CV任务的作用是不同的,原因大致有两点:Data Gap和Task Gap。首先在ImageNet数据集中,大多数图片都是无噪声的,并且场景较为单一,前景、背景易于剥离,这与其他不同的数据集存在数据上的差异;其次,ImageNet所面向的主要任务是图像分类,所以预载入模型中的参数大多与益于分类的特征相关,对于一些位置信息要求更加精细的任务却启发有限。
那么我们如何学习一个更好的Prior去启发后续视觉任务呢?再来联系一下人类的学习过程,对于不同的任务/课程,我们是有特定的Warm-up阶段。比如在学习乒乓球和篮球的过程中,对于乒乓球一开始我们需要练习的是简单的推挡和发球动作,而对于篮球,我们则是在一开始练习基础的运球和投篮动作,这两个Pre-training显然是不同的。回到CV中,对于不同任务比如深度估计和语义分割,也应该给予不同且更加精细的预学习课程:深度估计——三维成像先验,语义分割——场景类别先验等。
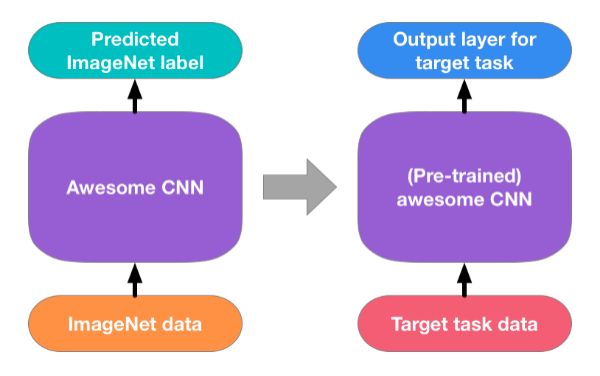
图3:Pre-training on ImageNet
05
「Learning-Implicit CV」to「Learning-Friendly CV」
如何评价一个任务是否易于网络学习,或者说这个任务是否对神经网络学习友好?很直观的一点就是去看图像特征与学习目标之间有无显示关联。例如在目标检测中,图像特征与Bounding Box之间的关联是肉眼可见的。而对于另一些任务,例如从一幅图像中直接预测对应拍摄相机的相机参数,那么图像特征与相机参数之间的关联就显得格外隐式了。此外,学习目标的同质性(Homogeneity)和异质性(Heterogeneity)也会影响神经网络的学习。如果对相机参数进一步细化的话,我们可以发现其中还包含了相机光心、焦距、畸变参数等不同的参数,这些参数之间的异质性以及相差甚远的取值范围会很容易导致回归的不平衡问题。
相比之下,Bounding Box中均为描述位置信息的顶点且取值范围相近,那么我们就可以说学习Bounding Box对神经网络是友好的。后续的Center-based目标检测又进一步优化了所学习的目标表示。从显示性与同质性这两点出发,我个人在学习相机参数这一个小点上提出了一个Learning-Friendly Representation(如下图所示),去代替传统的隐式和异质的相机参数,具体细节可参考论文A Deep Ordinal Distortion Estimation Approach for Distortion Rectification (IEEE TIP 2021)。除了相机参数,CV中还存在很多对神经网络并不是很友好的学习目标,相信后续工作会做好CV与神经网络之间的Trade-off,不会让神经网络太过为难。

图4:A Learning-friendly Representation for the Camera Intrinsic Parameters
综上,近年CV + Deep Learning虽在众多任务上得以革新,但二者相互作用的关系仍需要根据不同任务进行省视,而且面向Wild、Dynamic、Specific、Learning-Friendly等场景的进阶之路道阻且长。
作者简介:廖康,北京交通大学信息科学研究所2018级博士生,师从林春雨教授,读博期间主要从事图像生成、图像修复、3D视觉等研究,相关成果发表至IEEE Transactions on Image Processing (TIP), IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE Transactions on Intelligent Transportation Systems (TITS), IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)等会议及期刊。
扫码加入智源社区-计算机视觉群,参与更多 CV 研究和进展讨论
