毫末AI DAY的智驾弹药:上有「世界模型」,下有3000元方案
作者 | 张祥威
编辑 | 德新

「我们的感知能力可以说能做到识别万物了。」毫末智行在第九届毫末AI DAY上抛出这一豪言。
识别万物的底气,源于毫末的DriveGPT自动驾驶大模型引入了通用语义大模型,可以对交通参与者者、道路环境等做到全面感知。
今年是智驾获得公众接受度的关键节点。
而明年,随着技术门槛更高的「无图」城市NOA落地,头部智驾头部玩家大概率会迎来收获期。毫末在自动驾驶大模型上的诸多准备,正是为迎接大战。
不止有进化的大模型,毫末还带来三款高级辅助驾驶产品HP170、HP370、HP570,剑指无图城市NOH、记忆行车等大热功能。
当下,毫末智驾方案已经在山海炮HEV版、新摩卡Hi-4S等车型上搭载,明年一季度,搭载毫末城市NOH功能的魏牌蓝山将量产交付。
智驾大规模普及的时刻就要到来,毫末开始加快脚步。
与众多公司的科技日如特斯拉AI DAY、蔚来NIO DAY相比,这届毫末AI DAY的既有前沿技术进展的分享,又有极具竞争力的落地方案,有诸多看点。
一、克制的智驾方案
AI DAY上,毫末一口气推出三款智驾方案产品,共同点是「极致性价比」。
- HP170:算力5 TOPS,传感器方案标配1个前视相机、4个鱼眼相机、2个后角雷达、12个超声波雷达,支持选装1个前视雷达和2个前角雷达。
- HP370:算力32 TOPS,传感器方案标配2个前视相机、2个侧视相机、1个后视相机、4鱼眼相机、1个前雷达、2个后角雷达、12个超声波雷达,支持选装2个前角雷达。
- HP570:算力可选72 TOPS和100 TOPS两款芯片,传感器方案标配2个前视相机、4个侧视相机、1个后视相机、4个鱼眼相机、1个前雷达、12个超声波雷达,支持选配1颗激光雷达。

对比同行,这几套方案有以下特点:
首先,更低的芯片算力。
毫末采用基于5TOPS的芯片算力平台实现高速NOA,而实现城市NOA的方案,最高只需要要100TOPS的算力,比主流城市NOA智驾方案所需的算力都要低。
据HiEV了解,三套方案中的芯片分别为地平线征程3、TI的TDA4,以及高通Ride的SA8650芯片,这种高中低采用不同芯片方案的策略,也为量产搭载更多款车型提供了条件。
主流的智驾方案中,实现城市NOA通常需要两颗英伟达Oin X芯片,算力为508TOPS,少数玩家如智己、腾势,可以基于单颗英伟达Orin X芯片,算力为254TOPS。当然,更低算力的要属特斯拉的FSD,仅需144TOPS。
更低算力,意味着需要对算力有更极致地有效利用,同时要强化算法的能力。用更低的算力实现城市NOA,毫末的智驾技术水准和市场野心可见一斑。
其次,在传感器规模上也相对克制。
相较行业主流方案,毫末的智驾方案数量会更少一些。以搭载高阶智驾全享包的腾势N7作对比,这款车搭载33个传感器:
2个激光雷达、5个毫米波雷达、2个前视摄像头、4个环视摄像头、12个超声波雷达、4个侧视摄像头、1个后视摄像头、1个OMS摄像头、1个DMS摄像头、1个DVR摄像头。
毫末可以实现高阶智驾同等功能的HP570,传感器数量为24个,其缩减的部分是,方案中减少了毫米波雷达,而且激光雷达也并非标配。
最后,由于更低的算力的芯片,以及克制的传感器规模,还带来第三个特点,更低的BOM成本。

毫末智行董事长张凯认为,「让中阶智驾便宜好用,让高阶智驾好用更便宜,是毫末未来一年提交给中国智驾市场的答卷。」
毫末的三款智驾产品,最低为3000元级别,最高的高阶自动驾驶方案大概8000元级别,这与现在动辄上万的智驾选装包相比,无疑颇具杀伤力。
HiEV了解到,毫末的最新方案中,HP170已经定点,配合整车开发和上市的节奏,预计会在明年初上市;HP550预计在明年上半年蓝山的下一代车型搭载上市,支持记忆行车和记忆泊车;HP370 预计明年量产,而更新一代的HP570则会稍晚一些。
长线看,毫末的产品会全面平台化,提供高中低全系的智驾方案。
祭出成本更低的杀招,那么毫末的产品技术实力究竟如何呢?
二、可实现无图城市NOH,2024落地百城
一家公司的智驾能力,既体现在产品的上车规模和行驶里程,也体现在技术能够达到的广度和上限。
毫末的智驾方案HPilot产品已经搭载超过20款车型,用户辅助驾驶行驶里程突破8700万公里。由于起步不如蔚小理早,用户辅助驾驶行驶里程规模还不像对方那么庞大,但从搭载车型上,搭载车型规模是远超蔚小理的。

毫末的技术能力能力广度和上限,体现在可实现的功能上。
顾维灏说,毫末可以做到在城市道路中时速最高70公里在50米的距离下,就能检测到大概35cm高的小目标障碍物,可以做到100%的成功绕障或刹停。
下面一段视频,可见毫末智驾方案的技术能力。
面向L4的小魔驼,在城市开放道路进行无人驾驶时,也已经快于普通人骑自行车的速度。在行驶安全和通行效率上,均已达到商用状态。
与那些从基于高精地图转为去高精地图方案的玩家相比,毫末一早确立了重感知轻地图的技术路线。
基于高精地图的技术路线,开头容易,之后要在不同城市落地时,会面临泛化挑战。而重感知轻地图的好处是,开始难,但越走越快,能完成更快的城市落地。
毫末的高速无图NOH功能,可以实现高速、城市快速路上的无图NOH,短距离记忆泊车等功能,并获E-NCAP 5星AEB的高安全标准认证。
此外,毫末还可实现高速、城快,以及城市内的记忆行车,免教学记忆泊车、智能绕障等功能。高阶方案还支持无图记忆行车和泊车。
城市全场景无图NOH,则可实现全场景城市无图NOH、全场景辅助泊车、全场景智能绕障、跨层免教学记忆泊车等功能。
早期行业主打的智驾功能是高速NOA,之后是城市NOA,并在研发城市NOA时同步去掉高精地图,逐渐迈向今天的 去高精地图的“无图“阶段。
眼下能做到无图的,仅有小鹏、华为、蔚来等少数几家。谁具备无图能力,基本上便是智驾第一梯队成员。
毫末三款智驾产品的推出,意味着其智驾方案出手即高点,广度覆盖了当下热门功能,上限与头部玩持平,让自身站位来到第一梯队。按照计划,毫末的城市NOH落地目标是100城。
以上这些是毫末在乘用车NOH上的布局,会为明年智驾的普及大年做好准备。而之所以能在成立后短短几年做到无图等水平,离不开其核心,也是近几届AI DAY上常提到的自动驾驶大模型。
三、DriveGPT进化,可识别万物

自动驾驶其实是让汽车学习人类驾驶,这需要感知道路上的各类交通参与者,处理真实世界中无穷无尽的突发状况,最终顺利抵达目的地。
行业惯常做法,是在云端建立一个自动驾驶生成式大模型,然后通过剪枝、蒸馏的方式,把云端大模型的能力下放到车端,从而让汽车像人类司机一样开车。
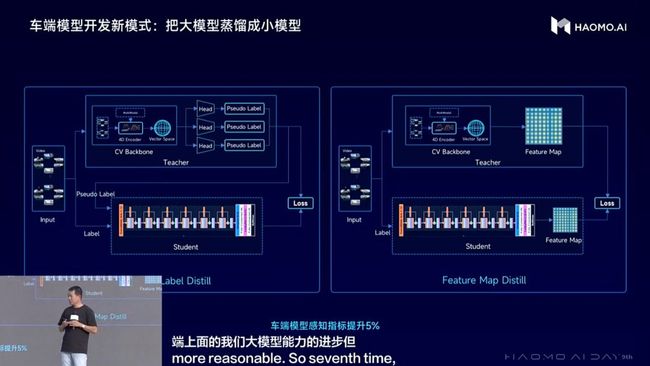
与人类大脑一样,自动驾驶生成式大模型也要不断进化。
今年的CVPR 2023,特斯拉和英国自动驾驶公司Wayve等均展示了自动驾驶大模型的新进展。
目前,特斯拉可以利用大模型生成连续视频,打造World Model即世界模型。
Wayve也在朝类似方向努力,其自动驾驶大模型GAIA-1,在通过持续扩展后已经拥有90亿个参数,可以生成驾驶场景视频,描述场景以及做出预测。
上月,Wayve还推出了视觉语言动作模型LINGO-1,可用于描述自动驾驶的行为和推理。
这些做法,直白地讲就是从原来仅学习文本,开始向看图、视频学习,从而与自动驾驶不断地更好融合。
根据毫末官方数据,目前团队已筛选出超过100亿帧互联网图片数据集,480万包含人驾行为的自动驾驶4D Clips。
毫末将自动驾驶分为三个时代,其中,自动驾驶3.0时代需要1亿公里。目前,用户辅助驾驶行驶里程已经达到8700多万公里,预计到年底可达到这一目标。
随着数据规模的增加,也为了更好地进入3.0时代,自动驾驶大模型需要不断进化。
感知模型中引入图文多模态大模型,以完成4D向量空间到语义空间的对齐,做到可以具备「万物识别」的能力,毫末将其称之为自动驾驶语义感知大模型。
基于自动驾驶语义感知大模型,毫末还会通过构建驾驶语言来描述驾驶环境和驾驶意图,再结合导航引导信息和自车历史动作,借助LLM大语言模型做出驾驶决策。
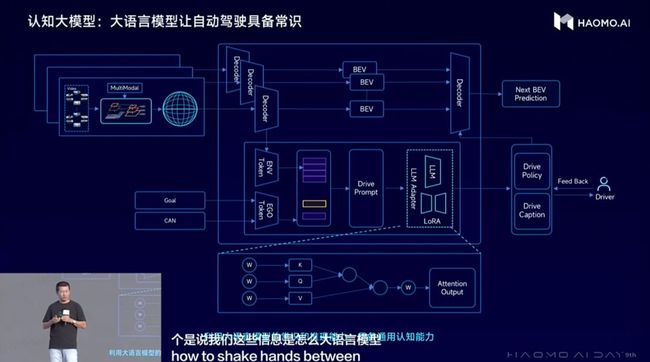
方向上,毫末正在沿着与特斯拉、Wayve同样的方向,让自动驾驶大模型拥有更多的学习进化途径,这相当于在建立自己的世界模型。
这一过程中,大模型的进化发生在多个方面:
早期,Transformer是用于自然语言处理(NLP)的大模型,主要应用于文本。之后Vision Transformer 又称ViT出现,主要用于图像。
直到后来,又出现Swin transformer,一种由微软提出的视觉领域的Transformer大模型。
在ViT图像大模型的基础上,Swin transformer进一步对图片进行图像分割,可以用于处理多视觉任务,更好地完成CV领域的目标检测和语义分割任务。
过去两年,毫末的视觉大模型的进化,与行业趋势一致,其CV Backbone先是从CNN模型全面切换到ViT,并又在今年全面升级到Swin transformer。
训练大模型方面,行业早期主要基于人工标注的单帧图片有监督,后来结合4D自动标注,再进一步升级到基于自动标注的4D Clip的有监督训练,到今天基于大规模数据的自监督学习训练,从而可以轻松吃下上百亿帧图片。
在毫末最新的模型中,已经可以采用视频生成的方式,通过预测生成视频下一帧的方式来构建4D表征空间,使CV Backbone学到三维的几何结构、图片纹理、时序信息等全面的物理世界信息。
以上这些动作,主要解决了大模型领域的数据采集和标注效率低、泛化能力差等问题,解决的其他问题还包括:
- 怎么做到高效、低成本地从上百亿的数据中,筛选出几万个有效数据;
- 怎么做到从闭集到开集,可以标注任意物体;
- 如何高效的场景迁移;
- 怎样让驾驶行为具备可解释性等等。
毫末将自动驾驶分为三个时代,其中,自动驾驶3.0时代需要1亿公里。目前,用户辅助驾驶行驶里程已经达到8700多万公里,预计到年底可达到这一目标。
总体上,这届AI DAY为毫末迈过自动驾驶3.0时代提供了更多弹药支持,从云端到车端做了充分准备。上有愈发聪明的自动驾驶大模型,下有性价比十足的智驾方案,毫末已经做好了明年智驾的卡位。