数据结构-堆和二叉树
目录
1.树的概念及结构
1.1 树的相关概念
1.2 树的概念
1.3 树的表示
1.4 树在实际中的应用(表示文件系统的目录树结构)
2.二叉树的概念及结构
2.1 概念
2.2 特殊的二叉树
2.3 二叉树的存储
3.堆的概念及结构
4.堆的实现
初始化堆
堆的插入
向上调整法
堆的删除
向下调整法
取堆顶的数据
堆的数据个数
堆的判空
堆的销毁
完整代码:
测试:
1.树的概念及结构
1.1 树的相关概念
下图就是一个树型结构,我们先来了解一下它的相关概念:
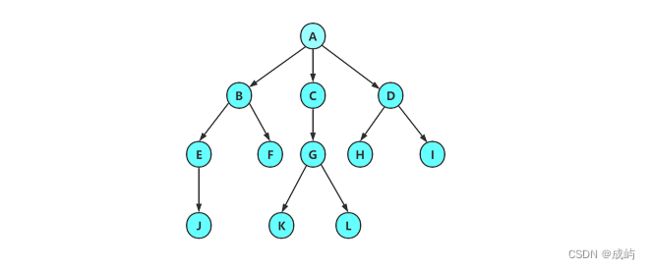
节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的为6
叶节点或终端节点:度为0的节点称为叶节点; 如上图:B、C、H、I...等节点为叶节点
非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G...等节点为分支节点
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林:由m(m>0)棵互不相交的树的集合称为森林
简单在图中标识一下:

1.2 树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
有一个特殊的结点,称为根结点,根节点没有前驱结点(即没有父节点)
除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继
因此,树是递归定义的。
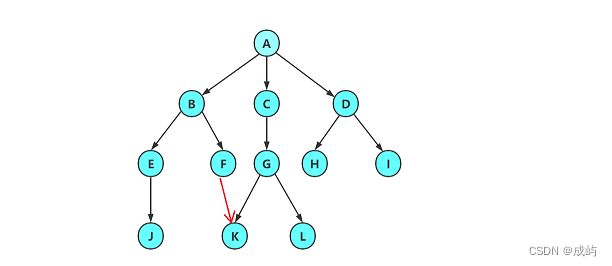
可以这样理解:一个树是由父节点和N颗子树构成的,
如下图所示,红圈内的就是子树:
而且每棵子树也能分为父节点和许多子树,所以说树可以递归定义。
但是注意,树型结构中,子树不能有交集,有交集就不能被称为树型结构。

1.3 树的表示
学了树的概念,我们来看看怎么表示树,一个树有很多子节点,但实际上在定义之前,我们并不知道到底有多少子节点,那树应该怎么定义呢?
实际中树有很多种表示方式如:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法
等。我们这里就简单的了解其中最常用的孩子兄弟表示法
struct TreNode
{
struct TreeNode* fristChild;//第一个孩子节点
struct TreeNode* pNextBrother;//指向下一个兄弟节点
int data;//节点中的数据域
};结构体中有两个指针,分别指向第一个孩子节点和它的下一个兄弟节点,那上文中的树型结构用孩子兄弟表示法表示如下:
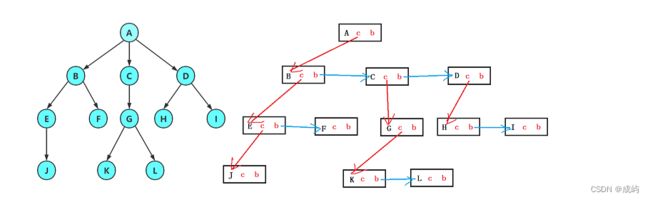
图中红线是父子节点之间的连线,蓝线是兄弟节点之间的连线,通过这种方式,只要找到第一个孩子,就能找到他的所有兄弟节点。例如:A中fristChild指针指向它的第一个孩子B,B中的fristChild指向它的第一个孩子C,pNextBrother指向他下一个兄弟节点......
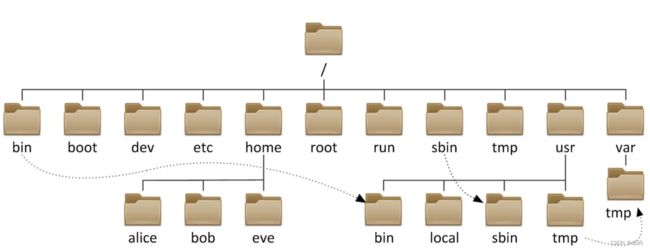
1.4 树在实际中的应用(表示文件系统的目录树结构)
2.二叉树的概念及结构
2.1 概念
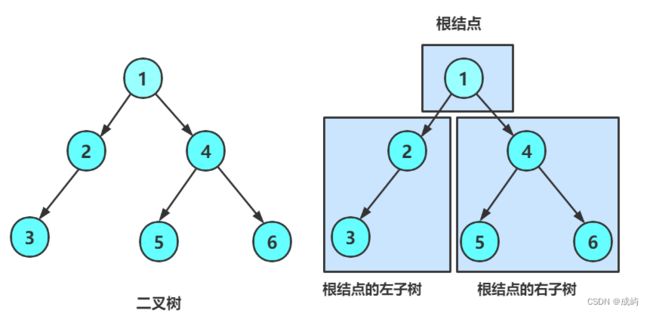
一棵二叉树是结点的一个有限集合,该集合:
由一个根节点加上两棵别称为左子树和右子树的二叉树组成
从上图可以看出:
1. 二叉树不存在度大于2的结点。2. 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
注意:对于任意的二叉树都是由以下几种情况复合而成的:

2.2 特殊的二叉树
我们已经知道了二叉树中每个父节点最多只能有2个子节点,下面来看两种特殊的二叉树:
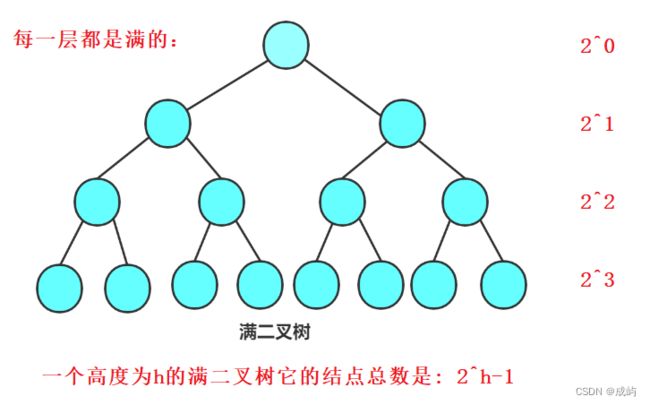
满二叉树:
一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。
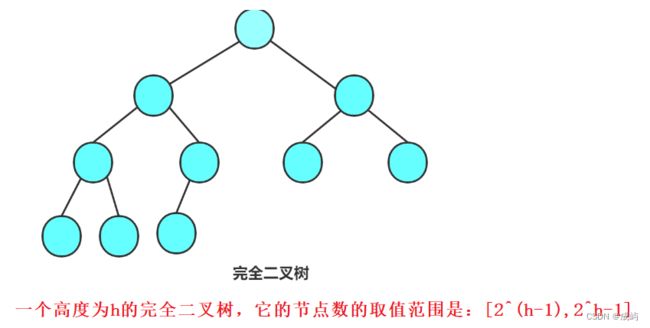
完全二叉树:
前h-1层是满的,最后一层可以不满,但是从左到右必须是连续的。
那二叉树在是怎么存储的呢?
2.3 二叉树的存储
我们可以把它的每一层数据按顺序存储到数组中,父节点和子节点之间下标有相应的关系。

由于满二叉树和完全二叉树它的最后一层前的每一层都是满的,所以适合用数组存储,但是如果不是完全二叉树就不适合用数组存储:

3.堆的概念及结构
概念:
堆必须要满足下面两个条件:
1. 完全二叉树。2. 大堆:树的任何一个父亲都大于等于孩子。
小堆:树的任何一个父亲都小于等于孩子。
下面看一道题目:
1.下列关键字序列为堆的是:()
A 100,60,70,50,32,65
B 60,70,65,50,32,100
C 65,100,70,32,50,60
D 70,65,100,32,50,60
E 32,50,100,70,65,60
F 50,100,70,65,60,32答案是A,我们画一下图就能很清楚地看出来了,它既满足完全二叉树,也满足大堆条件。

结构:
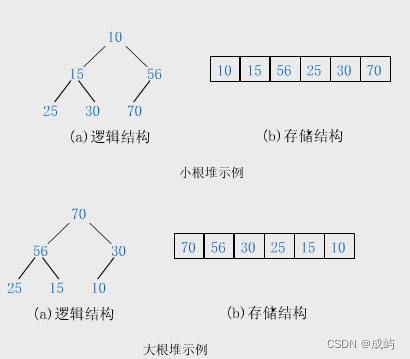
注意:有序的数组不代表它就是堆,因为堆只规定父亲和孩子的大小,但是没规定左孩子和右孩子的大小。
堆也有它的应用:
1、堆排序 2、topk 3、优先级队列。这些我们在后面的章节讲。
4.堆的实现
这里我们用数组来实现。
先定义一个结构体:
typedef int HeapDatatype;
typedef struct Heap
{
HeapDatatype* a;
int size;
int capacity;
}HP;初始化堆
void HeapInit(HP* php)
{
php->a = (HeapDatatype*)malloc(4*sizeof(HeapDatatype));
if (php->a == NULL)
{
perror("malloc fail\n");
return;
}
php->size = 0;
php->capacity = 4;
}堆的插入
void HeapPush(HP* php, HeapDatatype x)
{
if (php->size == php->capacity)
{
HeapDatatype* tmp = (HeapDatatype*)realloc(php->a, sizeof(HeapDatatype) * (php->capacity) * 2);
if (tmp == NULL)
{
perror("realloc fail\n");
return;
}
php->a = tmp;
php->capacity *= 2;
}
php->a[php->size] = x;
php->size++;
AdjustDwon(php->a, php->size-1);
}向上调整法
堆要么是大堆,树的任意一个父节点都大于等于子节点,要么是小堆,树的任意一个父亲都小于等于孩子,所以我们每插入一个数据都要和它的父亲进行比较,这里使用向上调整法:
假设我们要得小堆,那每当插入的孩子小于父亲时都要交换它们的位置,前文我们讲了,可以通过孩子的下标找到父亲,再把父亲的下标给孩子,直到孩子是根节点或者中途父亲就已经小于孩子,就停止循环(如果要得到大堆,当插入的孩子大于父亲时交换它们的位置)。
void AdjustUp(HeapDatatype*a,int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] > a[child])
{
HeapDatatype p = a[parent];
a[parent] = a[child];
a[child] = p;
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}堆的删除
删除有两种方法:
1. 直接删除根节点,然后把剩下的节点重新生成堆。
2. 删除堆顶元素,然后把最后一个元素放到堆顶,然后使用向下调整法,直到满足堆的性质。
第一种方法过于复杂,我们采用第二种方法。
void HeapPop(HP* php)
{
assert(php);
assert(!HeapEmpty(php));
swap(&php->a[0],&php->a[php->size-1]);
php->size--;
AdjustDown(php->a, php->size,0);
}向下调整法
具体步骤如下:
我们可以通过child=parent*2+1和child=parent*2+2得到父节点的左右子节点,然后从堆顶开始,将堆顶元素与其左右子节点中较小的那个进行比较,如果堆顶元素小于其子节点中的较小值,则将其与较小值交换位置,并继续向下比较,直到堆的性质被满足(如果要得到大堆就与较大的那个进行比较,如果堆顶元素大于子节点中的较大值,则将其和较大值交换位置)
代码如下:
void AdjustDown(HeapDatatype*a, int n,int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child] > a[child + 1])
{
child++;
}
if (a[parent] > a[child])
{
swap(&a[parent],&a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}函数swap()用来交换两个数的值:
swap(HeapDatatype* p1, HeapDatatype* p2)
{
HeapDatatype tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}取堆顶的数据
堆顶数据就是数组中下标为0的数据。
代码如下:
HeapDatatype HeapTop(HP* php)
{
assert(php);
assert(!HeapEmpty(php));
return php->a[0];
}堆的数据个数
int HeapSize(HP* php)
{
assert(php);
return php->size;
}堆的判空
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}堆的销毁
void HeapDestory(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->size = 0;
php->capacity = 0;
}完整代码:
test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"Heap.h"
int main()
{
HP hp;
HeapInit(&hp);
int arr[] = { 65,100,70,32,50,60 };
int i = 0;
for (i = 0; i < sizeof(arr) / sizeof(int); i++)
{
HeapPush(&hp, arr[i]);
}
while (!HeapEmpty(&hp))
{
HeapDatatype top = HeapTop(&hp);
printf("%d ", top);
HeapPop(&hp);
}
return 0;
}Heap.h
#pragma once
#include
#include
#include
#include
typedef int HeapDatatype;
typedef struct Heap
{
HeapDatatype* a;
int size;
int capacity;
}HP;
//堆的初始化
void HeapInit(HP* php);
//堆的销毁
void HeapDestory(HP* php);
//堆的插入
void HeapPush(HP* php,HeapDatatype x);
//堆的删除
void HeapPop(HP* php);
//取堆顶元素
HeapDatatype HeapTop(HP* php);
//堆中数据个数
int HeapSize(HP* php);
//堆的判空
bool HeapEmpty(HP* php);
//向上调整法
void AdjustUp(HeapDatatype* a, int child);
//向下调整法
void AdjustDown(HeapDatatype* a, int n, int parent); Heap.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"Heap.h"
//堆的初始化
void HeapInit(HP* php)
{
php->a = (HeapDatatype*)malloc(4*sizeof(HeapDatatype));
if (php->a == NULL)
{
perror("malloc fail\n");
return;
}
php->size = 0;
php->capacity = 4;
}
//堆的销毁
void HeapDestory(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->size = 0;
php->capacity = 0;
}
//交换两数值
swap(HeapDatatype* p1, HeapDatatype* p2)
{
HeapDatatype tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//向上调整法
void AdjustUp(HeapDatatype*a,int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] > a[child])
{
swap(&a[parent],&a[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//堆的插入
void HeapPush(HP* php, HeapDatatype x)
{
if (php->size == php->capacity)
{
HeapDatatype* tmp = (HeapDatatype*)realloc(php->a, sizeof(HeapDatatype) * (php->capacity) * 2);
if (tmp == NULL)
{
perror("realloc fail\n");
return;
}
php->a = tmp;
php->capacity *= 2;
}
php->a[php->size] = x;
php->size++;
AdjustUp(php->a, php->size-1);
}
//向下调整法
void AdjustDown(HeapDatatype*a, int n,int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child] > a[child + 1])
{
child++;
}
if (a[parent] > a[child])
{
swap(&a[parent],&a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//堆的判空
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
//堆的删除
void HeapPop(HP* php)
{
assert(php);
assert(!HeapEmpty(php));
swap(&php->a[0],&php->a[php->size-1]);
php->size--;
AdjustDown(php->a, php->size,0);
}
//取堆顶元素
HeapDatatype HeapTop(HP* php)
{
assert(php);
assert(!HeapEmpty(php));
return php->a[0];
}
//堆的数据个数
int HeapSize(HP* php)
{
assert(php);
return php->size;
}测试:
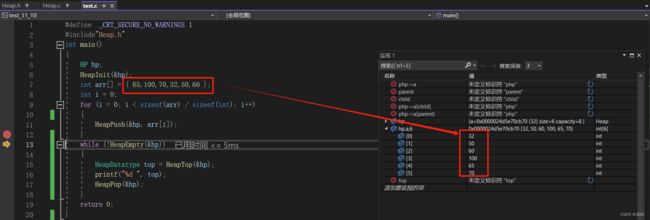
我们要得到的是小堆,通过调试可以看到,堆中的元素依次是 32 50 60 100 65 70
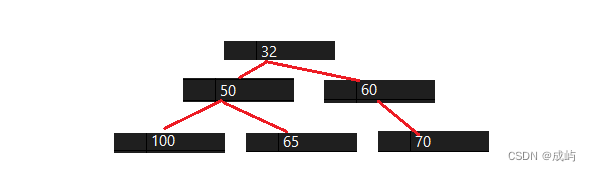
很明显,满足小堆的性质。
我们再来打印一下堆顶元素,
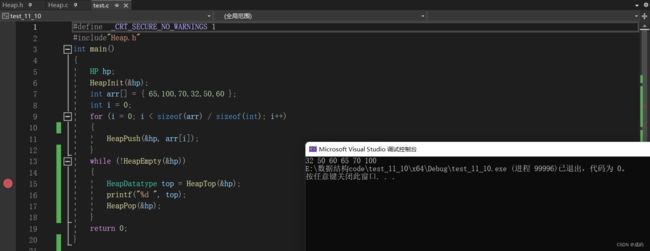
每次pop后再打印堆顶元素出来,数据是升序,那说明堆可以实现数据的排序,那我们用堆排序每次都要写一个堆出来吗,那岂不是太麻烦了?
下节我们再来详细讲解堆排序及相关问题,未完待续。。。