【深度学习】机器翻译的前世今生
我们都知道谷歌翻译,这个网站可以像变魔术一样在100 种不同的人类语言之间进行翻译。它甚至可以在我们的手机和智能手表上使用:
谷歌翻译背后的技术被称为机器翻译。它的出现改变了世界交流方式。
事实证明,在过去几年中,深度学习完全改写了传统的机器翻译方法。对语言翻译几乎一无所知的深度学习研究人员正在拼凑相对简单的机器学习解决方案,这些解决方案正在击败世界上最好的专家构建的语言翻译系统。
这一突破背后的技术被称为sequence to sequence模型。这是一种非常强大的技术,可用于解决多种问题。在我们了解它的工作原理之后,我们还将了解如何使用完全相同的算法来编写 AI 聊天机器人和图片描述系统。
让计算机翻译
那么我们如何对计算机编程来翻译人类语言呢?
最简单的方法是用目标语言的翻译词替换句子中的每个词。这是一个将西班牙语逐字翻译成英语的简单示例:

这很容易实现,因为只需要构造一个字典数据结构来查找每个单词的翻译。但是结果很糟糕,因为它忽略了语法和上下文。
因此,接下来您可能要做的就是开始添加特定于语言的规则以改进结果。例如,您可以将常见的双词短语翻译为一个组。你可能会交换名词和形容词的顺序,因为它们在西班牙语中的出现顺序通常与它们在英语中的出现顺序相反:
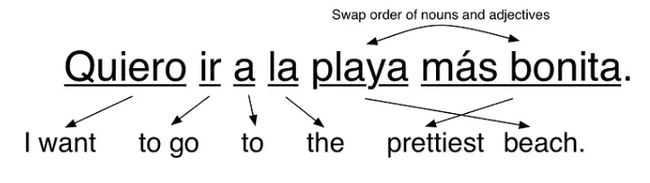
成功了!如果我们不断添加更多规则,直到我们能够处理语法的每一部分,我们的程序应该能够翻译任何句子,对吧?
这就是最早的机器翻译系统的工作方式。语言学家想出了复杂的规则,并将它们一一编入程序。
不幸的是,这只适用于像天气预报这种简单、结构清晰的语言。当面对真实世界的语言时它就变得不再可靠。
因为人类语言并不遵循一套固定的规则。人类语言充满了特殊情况、区域差异,并且完全违反规则。例如,西方国家说英语的方式更多地受到数百年前入侵者的影响,而不是坐下来定义语法规则的人。
应用统计方法让计算机翻译得更好
在基于规则的系统失败后,使用基于概率和统计的模型而不是语法规则开发了新的翻译方法。
构建基于统计的翻译系统需要大量训练数据,其中将完全相同的文本翻译成至少两种语言。这种双重翻译的文本称为平行语料库。就像 1800 年代科学家使用罗塞塔石碑从希腊语中找出埃及象形文字一样,计算机可以使用平行语料库来猜测如何将文本从一种语言转换为另一种语言。
幸运的是,在很多奇怪地方已经有很多双重翻译的文本。例如,欧洲议会将议事录翻译成 21 种语言。因此,研究人员经常使用这些数据来帮助构建翻译系统。

概率思维
这种方式不会只生成一种精确的翻译。相反,他们会生成数千种可能的翻译,然后根据每个翻译的正确可能性对这些翻译进行排名。并通过它与训练数据的相似程度来估计它有多“正确”。它是这样工作的:
第 1 步:将原始句子分成块
首先,我们将句子分解成简单的块,每个块都可以轻松翻译:

第 2 步:为每个块找到所有可能的翻译
接下来,我们将通过查找人类在我们的训练数据中翻译这些相同词块的所有方式来翻译这些词块中的每一个。
重要的是要注意,我们不仅仅是在简单的翻译词典中查找这些块。相反,我们正在看到真实的人如何在现实世界的句子中翻译这些相同的词块。这有助于我们了解它们在不同情况下的所有不同使用方式:
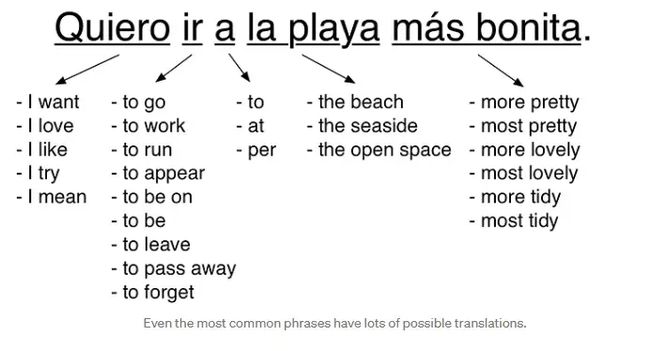
其中一些可能的翻译比其他翻译更频繁地使用。根据每个翻译在我们的训练数据中出现的频率,我们可以给它打分。
例如,某人说“Quiero”的意思是“我想要”比意思是“我尝试”要常见得多。因此,我们可以使用训练数据中“Quiero”被翻译成“I want”的频率来赋予该翻译比频率较低的翻译更高的权重。
第 3 步:生成所有可能的句子并找到最有可能的句子
接下来,我们将使用这些块的每一种可能组合来生成一堆可能的句子。
仅从我们在步骤 2 中列出的块翻译,我们已经可以通过以不同方式组合块来生成近 2,500 种不同的句子变体。这里有些例子:

但在现实世界的系统中,会有更多可能的组块组合,因为我们还将尝试不同的单词顺序和不同的句子组块方式:

现在需要扫描所有这些生成的句子,以找到听起来“最合理”的句子。
为此,我们将每个生成的句子与数以百万计的英文书籍和新闻故事中的真实句子进行比较。我们能得到的英文文本越多越好。
一种可能的翻译是:
I try | to leave | per | the most lovely | open space.
但是没有人用英语写过这样的句子,它与我们数据集中的任何句子都不会非常相似。因此会给这个可能的翻译一个低概率分数。
再看看这个可能的翻译:
I want | to go | to | the prettiest | beach.
这句话会和我们训练集中的某个句子相似,所以它会得到很高的概率分数。
在尝试了所有可能的句子之后,我们将选择具有最可能的块翻译的句子,同时也与真实的英语句子总体上最相似。
我们的最终翻译是“I want to go to the prettiest beach”。不错!
统计机器翻译是一个巨大的里程碑
如果您为统计机器翻译系统提供足够的训练数据,它们的性能要比基于规则的系统好得多。Franz Josef Och 改进了这些想法,并在 2000 年代初期使用它们构建了 Google 翻译。机器翻译终于面世了。
在早期,每个人都惊讶于基于概率的“愚蠢”翻译方法比语言学家设计的基于规则的系统效果更好。这导致了 80 年代研究人员之间的一个(有点刻薄的)说法:
每次我解雇一名语言学家,我的准确性都会提高。
统计机器翻译的局限性
统计机器翻译系统运行良好,但构建和维护起来很复杂。您要翻译的每一对新语言都需要专家调整和调整新的多步骤翻译管道。
由于构建这些不同的管道需要大量工作,因此必须做出权衡。如果你要求谷歌将格鲁吉亚语翻译成泰莱古语,它必须在内部将其翻译成英语作为中间步骤,因为没有足够多的格鲁吉亚语到泰莱古语的翻译来证明在该语言对上投入大量资金是合理的。与您要求更常见的法语到英语选择相比,它可能会使用不太先进的翻译管道进行翻译。
如果我们可以让计算机为我们完成所有烦人的开发工作,那不是很酷吗?
让计算机翻译得更好——没有那些昂贵的人
机器翻译的圣杯是一个黑匣子系统,它可以自己学习如何翻译——仅仅通过查看训练数据。使用统计机器翻译,仍然需要人工来构建和调整多步骤统计模型。
2014年,KyungHyun Cho的团队取得了突破。他们找到了一种应用深度学习来构建这个黑匣子系统的方法。他们的深度学习模型采用平行语料库,并使用它来学习如何在没有任何人工干预的情况下在这两种语言之间进行翻译。
两个伟大的想法使这成为可能——递归神经网络和编码。通过巧妙地结合这两种思想,我们可以构建一个自学习翻译系统。
循环神经网络
常规(非循环)神经网络是一种通用机器学习算法,它接受数字列表并计算结果(基于先前的训练)。神经网络可以用作解决许多问题的黑匣子。例如,我们可以使用神经网络根据房屋的属性计算房屋的近似值:

但与大多数机器学习算法一样,神经网络是无状态的。您传入一个数字列表,然后神经网络计算出一个结果。如果您再次传入相同的数字,它将始终计算出相同的结果。它没有过去计算的记忆。换句话说,2 + 2 总是等于 4。
循环神经网络(或简称 RNN)是神经网络的略微调整版本,其中神经网络的先前状态是下一次计算的输入之一。这意味着以前的计算改变了以后计算的结果!
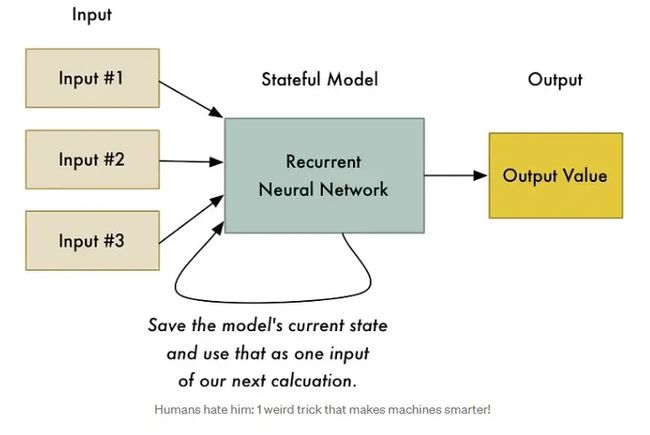
我们到底为什么要这样做?无论我们上次计算什么,2 + 2 不应该总是等于 4 吗?
这个技巧允许神经网络学习一系列数据中的模式。例如,您可以使用它根据前几个词预测句子中下一个最有可能的词:
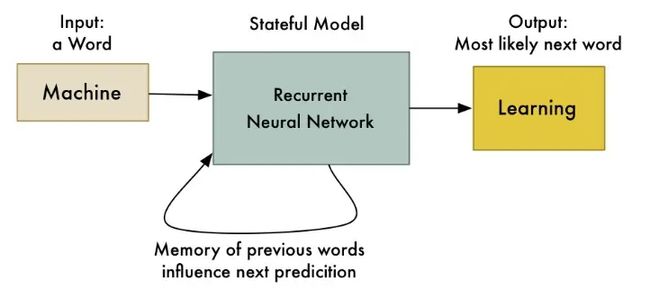
每当您想学习数据模式时,RNN 都非常有用。由于人类语言只是一种庞大而复杂的模式,因此 RNN 越来越多地用于自然语言处理的许多领域。
编码
我们需要审查的另一个想法是编码。我们之前讨论了作为人脸识别一部分的编码。为了解释编码,让我们稍微绕一下我们如何用计算机区分两个不同的人。
当你试图用计算机区分两张脸时,你会从每张脸上收集不同的测量值,并使用这些测量值来比较面孔。例如,我们可能会测量每只耳朵的大小或两只眼睛之间的间距,然后比较两张照片中的这些测量值,看看他们是否是同一个人。
将一张脸变成一个测量列表的想法是编码的一个例子。我们正在获取原始数据(一张人脸图片)并将其转换为表示它的测量值列表(编码)。
但是我们不必拿出一个特定的面部特征列表来衡量自己。相反,我们可以使用神经网络从面部生成测量值。在确定哪些测量最能区分两个相似的人方面,计算机可以比我们做得更好:

这是我们的编码。它让我们用简单的东西(128 个数字)来表示非常复杂的东西(一张脸的图片)。现在比较两张不同的脸要容易得多,因为我们只需要比较每张脸的这 128 个数字,而不是比较完整的图像。
你猜怎么了?我们可以用句子做同样的事情!我们可以想出一种编码,将每个可能的不同句子表示为一系列唯一的数字:

为了生成这种编码,我们会将句子输入 RNN,一次输入一个单词。处理完最后一个单词后的最终结果将是代表整个句子的值:

太好了,现在我们有办法将整个句子表示为一组唯一的数字!我们不知道编码中每个数字的含义,但这并不重要。只要每个句子都由它自己的一组数字唯一标识,我们就不需要确切地知道这些数字是如何生成的。
让我们翻译吧!
好的,所以我们知道如何使用 RNN 将一个句子编码成一组唯一的数字。这对我们有什么帮助?这就是事情变得非常酷的地方!
如果我们采用两个 RNN 并将它们端到端连接起来会怎样?第一个 RNN 可以生成表示句子的编码。然后第二个 RNN 可以采用该编码并反向执行相同的逻辑以再次解码原始句子:
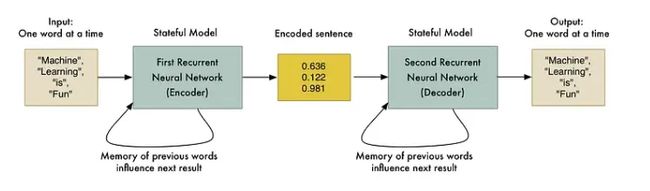
当然,能够对原始句子进行编码然后再次解码并不是很有用。但是,如果(这是个好主意!)我们可以训练第二个 RNN 将句子解码为西班牙语而不是英语怎么办?我们可以使用我们的平行语料库训练数据来训练它来做到这一点:

就像那样,我们有一种通用的方法可以将一系列英语单词转换为等效的西班牙语单词序列!
这是一个强大的想法:
- 这种方法主要受限于你拥有的训练数据量和你可以投入的计算机能力。机器学习研究人员两年前才发明这个,但它的性能已经和耗时 20 年开发的统计机器翻译系统一样好。
- 这并不取决于了解有关人类语言的任何规则。该算法自己计算出这些规则。这意味着您不需要专家来调整翻译流程的每一步。计算机会为你做这些。
- 这种方法几乎适用于任何类型的序列到序列问题!事实证明,许多有趣的问题都是序列到序列的问题。继续阅读您可以做的其他很酷的事情!
请注意,我们忽略了使这项工作与实际数据一起工作所需的一些事情。例如,您需要做一些额外的工作来处理不同长度的输入和输出句子(请参阅分桶和填充)。正确翻译生僻词也存在问题。
构建您自己的序列到序列翻译系统
如果您想构建自己的语言翻译系统,TensorFlow 中包含一个可在英语和法语之间进行翻译的工作演示。但是,这不适合胆小者或预算有限的人。这项技术仍然很新,而且非常耗费资源。即使你有一台配备高端显卡的快速计算机,也可能需要大约一个月的连续处理时间来训练你自己的语言翻译系统。
此外,序列到序列的语言翻译技术进步如此之快,以至于很难跟上。最近的许多改进(如添加注意力机制或跟踪上下文)正在显着改善结果,但这些发展太新了,甚至还没有维基百科页面。如果你想对序列到序列学习做任何严肃的事情,你需要跟上新的发展。
序列到序列模型的荒谬力量
那么我们还能用序列到序列模型做些什么呢?
大约一年前,谷歌的研究人员表明您可以使用序列到序列模型来构建人工智能机器人。这个想法是如此简单,以至于令人惊讶的是它的工作原理。
首先,他们获取了谷歌员工和谷歌技术支持团队之间的聊天记录。然后他们训练了一个序列到序列模型,其中员工的问题是输入句子,技术支持团队的回答是该句子的“翻译”。

当用户与机器人交互时,他们将使用该系统“翻译”用户的每条消息以获得机器人的响应。
最终结果是一个可以(有时)回答真正的技术支持问题的半智能机器人。这是他们论文中用户和机器人之间的示例对话的一部分:

他们还尝试构建一个基于数百万电影字幕的聊天机器人。这个想法是利用电影角色之间的对话来训练机器人像人一样说话。输入的句子是一个字符说的一行对话,“翻译”是下一个字符的回应:
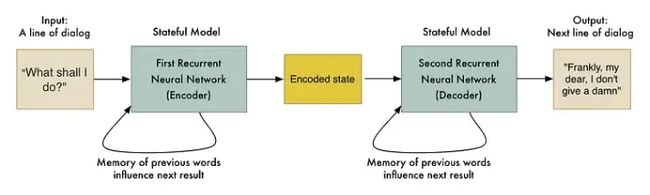
这产生了非常有趣的结果。机器人不仅像人一样交谈,而且还显示出一点点智慧:

这只是可能性的开始。我们不仅限于将一个句子转换为另一个句子。也可以制作一个可以将图像转换为文本的图像到序列模型!
Google 的另一个团队通过用卷积神经网络替换第一个 RNN 来做到这一点(就像我们在第 3 部分中了解到的那样)。这允许输入是图片而不是句子。其余的工作方式基本相同:

就这样,我们可以把图片变成文字(只要我们有很多很多的训练数据)!
Andrej Karpathy 扩展了这些想法,构建了一个能够通过分别处理图像的多个区域来非常详细地描述图像的系统:

这使得构建图像搜索引擎成为可能,这些引擎能够找到与奇怪的特定搜索查询匹配的图像:
甚至还有研究人员在研究相反的问题,即根据文本描述生成整张图片!
仅从这些示例中,您就可以开始想象各种可能性。到目前为止,从语音识别到计算机视觉的方方面面都有序列到序列的应用。我敢打赌明年会有更多。