Kubernetes学习笔记
第一章 Kubernets与docker
Docker是一种轻量级的容器化平台,可以将应用程序及其依赖项打包到一个可移植的容器中,并在任何环境中运行。Docker可以帮助开发人员快速构建、测试和部署应用程序,并且能够提供更高的效率和可靠性。Docker的主要优点是打包和隔离应用程序,使其易于移植和部署。
Kubernetes则是一个开源的容器编排平台,可以自动化管理容器的部署、伸缩、负载均衡、故障恢复等操作。与Docker相比,Kubernetes更加关注管理和编排容器集群中的多个容器,可以根据应用负载和资源需求来调整容器数量和配置。Kubernetes的主要优点是实现了容器的自动化管理和扩展,从而降低了维护成本和系统故障的风险。
区别如下:
- kubernetes是一个开源的容器集群管理系统,是一套自动化部署工具;而Docker是一个开源的应用容器引擎,是一种容器化技术。
- docker是容器层面的。docker目前主要包含了dockerd和containerd两个组件。其中containerd才是真正干活的。
- k8s是容器编排层面的,可以对接不同的容器层。也就是说,k8s可以对接docker,也可以对接更简洁的containerd,或者其它。
有两种看待Docker的方式。第一种方法涉及将Docker容器视为真正的轻量级虚拟机。第二种方法是将Docker视为软件打包和交付平台。后一种方法被证明对人类开发人员更有帮助,并导致该技术得到广泛采用。
第二章 Docker版本
- 老旧版本:docker/docker.io/docker-engine/lxc-docker
RHEL/CentOS软件源中的Docker包名为docker;Ubuntu软件源中的Docker包名为docker.io;而很古老的Docker源中Docker也曾叫做lxc-docker。这些都是非常老旧的Docker版本,基本不会更新到最新的版本。
另外,17.04以后,包名从docker-engine改为docker-ce,因此从现在开始安装,应该都使用docker-ce这个包。 - 主流版本:docker-CE/docker-EE
docker-ce是社区版本是完全免费的;从1.XX版本升级到17.XX版本上的风险是非常小的;docker-ce还区分两个版本edge和stable版本;
edge版本是每个月发布一次,喜欢尝新的用户可以下载此版本,因此对于安全和错误只能当月获取与修复;stable版本是每个季度更新一次,也就是说是稳定版本。
docker-ee版本是由公司支持,可在经过认证的操作系统和云提供商中使用,并可运行来自Docker Store的、经过认证的容器和插件;对于企业则提供了一下收费的高级特性。
第三章 Kubernetes原理
Kubernetes简称k8s,是支持云原生部署的一个平台,起源于谷歌。谷歌早在十几年之前就对其应用,通过容器方式进行部署。
k8s本质上就是用来简化微服务的开发和部署的,关注点包括自愈和自动伸缩、调度和发布、调用链监控、配置管理、Metrics监控、日志监控、弹性和容错、API管理、服务安全等,k8s将这些微服务的公共关注点以组件形式封装打包到k8s发这个大平台中,让开发人员在开发微服务时专注于业务逻辑的实现,而不需要去特别关心微服务底层的这些公共关注点,大大简化了微服务应用的开发和部署,提高了开发效率。
3.1.功能介绍
K8s是用来对docker容器进行管理和编排的工具,其是一个基于docker构建的调度服务,提供资源调度、均衡容灾、服务注册、动态扩容等功能套件,其作用如下所示:
① 数据卷:pod中容器之间数据共享,可以使用数据卷
② 应用程序健康检查:容器内服务可能发生异常导致服务不可用,可以使用健康检查策略保证应用的健壮性
③ 复制应用程序实例:控制器维护着pod的副本数量,保证一个pod或者一组同类的pod数量始终可用
④ 弹性伸缩:根据设定的指标(CPU利用率等)动态的自动缩放pod数
⑤ 负载均衡:一组pod副本分配一个私有的集群IP地址,负载均衡转发请求到后端容器,在集群内布,其他pod可通过这个Cluster IP访问集群
⑥ 滚动更新:更新服务不中断,一次更新一个pod,而不是同时删除整个服务
⑦ 服务编排:通过文件描述部署服务,使的程序部署更高效
⑧ 资源监控:Node节点组件集成cAdvisor资源收集工具,可通过Heapster汇总整个集群节点资源数据,然后存储到InfluxDB时序数据库,再由Grafana展示
⑨ 提供认证和授权:支持属性访问控制、角色访问控制等认证授权策略
3.2.整体架构
Kubernetes最初源于谷歌内部的Borg,提供了面向应用的容器集群部署和管理系统,比如Pod、Service、Labels和单Pod单IP等。Kubernetes的整体架构跟Borg非常像,整个架构有apiserver、controller-manager、scheduler、etcd、kubelet、kube-proxy、network-plugin等相关组件完成,整体架构如下:

3.2.1.Master
K8s中的Master是集群控制节点,负责整个集群的管理和控制。
API Server:提供了HTTP Rest接口的关键服务进程,是K8S里所有资源的增删改查等操作的唯一入口,也是集群控制的入口进程;
controller-manager:K8S里所有资源对象的自动化控制中心,集群内各种资源Controller的核心管理者,针对每一种资源都有相应的Controller,保证其下管理的每个Controller所对应的资源始终处于期望状态;
scheduler:负责资源调度(Pod调度)的进程,通过API Server的Watch接口监听新建Pod副本信息,并通过调度算法为该Pod选择一个最合适的Node;
etcd:K8S里的所有资源对象以及状态的数据都被保存在etcd中。
3.2.2.Worker
Worker是K8S集群中的工作负载节点,每个Worker都会被Master分配一些工作负载,当某个Worker宕机时,其上的工作负载会被Master自动转移到其他节点上
kubelet:负责Pod对应的容器的创建、启停等任务,同时与master节点上的API server节点进行交互,接受指令执行操作;
kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件,负责对Pod进行寻址和负载均衡;
Pod:k8s中特有的一个概念,可以理解为对容器的包装,是k8s的基本调度单位,实际的容器时运行在Pod中的,一个节点可以启动一个或多个Pod;
Docker Engine:Docker引擎,负责本机的容器创建和管理工作
在默认情况下Kubelet会向Master注册自己,一旦Node被纳入集群管理范围,kubelet进程就会定时向Master汇报自身的信息(例如机器的CPU和内存情况以及有哪些Pod在运行等),这样Master就可以获知每个Node的资源使用情况,并实现高效均衡的资源调度策略。而某个Node在超过指定时间不上报信息时,会被Master判定为失败,Node的状态被标记为不可用,随后Master会触发工作负载转移的自动流程
Controller Runtime:下载镜像和运行容器的组件,负责镜像管理以及Pod和容器的真正运行(CRI)。
3.3.核心概念
3.3.1.概念介绍
3.3.1.1.集群Cluster
集群有多个节点组成且可以按需添加节点(物理机/虚拟机),每一个节点都包含一定数量的CPU和内存RAM。

3.3.1.2.容器Container
k8s本身是一个容器调度平台,从宿主机操作系统来看,容器就是一个一个的进程。从容器内部来看容器就是一个操作系统,它有着自己的网络、CPU、文件系统等资源。

3.3.1.3.Pod
k8s也不是直接调度容器的,而是将其封装成了一个个POD,POD才是k8s的基本调度单位。每个POD中可以运行一个或多个容器,共享POD的文件系统、IP和网络等资源,每一个POD只有一个IP。
Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume。在K8S里,一个Pod里的容器与另外主机上的Pod容器能够直接通信。
3.3.1.4.Pod控制器Controller-Manager
Controller-Manager由kube-controller-manager和cloud-controller-manager组成,是Kubernetes的大脑,它通过apiserver监控整个集群的状态,并确保集群处于预期的工作状态。cloud-controller-manager在Kubernetes启用Cloud Provider的时候才需要,用来配合云服务提供商的控制
3.3.1.5.服务service
POD 在k8s中是不固定的,可能会挂起或者重启,且挂起重启都是不可预期的,那么这就会导致服务的IP也随着不停的变化,给用户的寻址造成一定的困难。而service就是用来解决这个问题的,它屏蔽了应用的IP寻址和负载均衡,消费方可直接通过服务名来访问目标服务,寻址和负载均衡均由service底层进行。
3.3.1.6.存储ConfigMap/Secret
微服务在上线时需要设置一些可变配置,环境不同则配置值不同,有些配置如数据库的连接字符串在启动时就应该配好,有些配置则可以在运行中动态调整。为了实现针对不同环境灵活实现动态配置,微服务就需要ConfigMap的支持。
k8s平台内置支持微服务的配置(ConfigMap),开发人员将配置填写在ConfigMap中,k8s再将ConfigMap中的配置以环境变量的形式注入POD,这样POD中的应用就可以访问这些配置。
Secret是一种特殊的ConfigMap,提供更加安全的存储和访问配置机制。
3.3.1.7.总结
| 概念 | 作用 |
|---|---|
| Cluster | 超大计算抽象,由节点组成 |
| Container | 应用居住和运行在容器中 |
| Pod | Kubernetes基本调度单位 |
| Controller-Manager | 监控集群状态,控制Pod运行方式 |
| Service | 应用Pods的访问点,屏蔽IP寻址和负载均衡 |
| ConfigMap/Secrets | 应用配置,secret敏感数据配置 |
3.3.2.详细介绍
3.3.2.1.Pod
每个Pod都有一个根容器的Pause容器,还包含一个或多个紧密相关的用户业务容器

3.3.2.1.1.分类
Pod是kubernetes的最小管理单元,在kubernetes中,按照pod的创建方式可以将其分为两类:
自主式pod:kubernetes直接创建出来的Pod,这种pod删除后就没有了,也不会重建
控制器创建的pod:kubernetes通过控制器创建的pod,这种pod删除了之后还会自动重建
3.3.2.1.2.生命周期
Pod生命周期包含Pending、Running、Compeleted、Failed、Unknown五个状态。
| 状态 | 说明 |
|---|---|
| Pending | API Server已经创建了该Pod,但Pod中的一个或多个容器的镜像还没有创建,包括镜像下载过程 |
| Running | Pod内所有容器已创建,且至少一个容器处于运行、正在启动或正在重启状态 |
| Compeleted | Pod内所有容器均成功执行退出,且不会再重启 |
| Failed | Pod内所有容器均已退出,但至少一个容器退出失败 |
| Unknown | 由于某种原因无法获取Pod状态,例如网络通信不畅等 |
3.3.2.1.3.重启策略
Pod重启策略有Always、OnFailure、Never,Always为默认值。
| 项目 | Value |
|---|---|
| Always | 当容器失效时,由kubelet自动重启该容器 |
| OnFailure | 当容器终止运行且退出码不为0时,由kubelet自动重启该容器 |
| Never | 不论容器运行状态如何,kubelet都不会重启该容器 |
3.3.2.1.4.资源分配
每个Pod都可以对其能使用的服务器上的计算资源设置限额,Kubernetes中可以设置限额的计算资源有CPU与Memory两种,CPU的资源单位为CPU数量,是一个绝对值而非相对值。Memory配额也是一个绝对值,它的单位是内存字节数。
Kubernetes中,一个计算资源进行配额限定需要设定以下两个参数:
- Requests,该资源最小申请数量,系统必须满足要求
- Limits,该资源最大允许使用的量,不能突破,当容器试图使用超过这个量的资源时,可能会被Kubernetes“杀死”并重启
3.3.2.1.5.完整Yaml定义
完整定义如下:
apiVersion: v1 // 版本
kind: pod // 类型,此处为Pod类型
metadata: // 元数据
name: string // 元数据,是pod的名称
namespace: string // 元数据,pod的命名空间,如果不填写默认是default
labels: // 元数据,pod的标签列表,可写多个label
- name: string // 元数据,标签的名称
annotations: // 元数据,自定义注解列表
- name: string // 元数据,自定义注解名称
spec: // pod中容器的详细定义
containers: // pod中容器的列表
- name: string // 容器的名称
image: string // 容器中的镜像
imagePullPolicy: Always | Never | IfNotPresent // 获取镜像的策略: 默认为Always(拉取镜像库镜像,即每次都尝试重新下载镜像)、Never(仅使用本地镜像)、IfNotPresent(本地有镜像就不拉取镜像库镜像,如果没有就拉取镜像库镜像)
command: [string] // 容器的启动命令列表(不配置则使用镜像内部的命令)
args: [string] // 启动命令参数列表
workingDir: string // 容器的工作目录
volumeMounts: // 挂载到容器内部的存储卷配置
- name: string // 引用pod定义的共享存储卷的名称,需使用volumes[]部分定义的共享存储卷名称
mountPath: string // 存储卷在容器内部Mount的绝对路径
readOnly: boolean // 是否为只读模式,默认为读写模式
ports: // 容器需要暴露的端口号列表
- name: string // 端口的名称
containerPort: int // 容器要暴露的端口
hostPort: int // 容器所在主机监听的端口(容器暴露端口映射到宿主机的端口,设置host port时同一台宿主机将不能启动该容器的第二份版本)
protocol: string // 端口协议,支持TCP和UDP,默认值为TCP
env: // 容器运行前设置的环境变量列表
- name: string // 环境变量的名称
value: string // 环境变量的值
resources: // 资源限制和资源请求设置
limits: // 资源限制,容器的最大可用资源数量
cpu: string // CPU限制,单位为core数
memory: string // 内存限制,单位可以为MiB、GiB等
requests: // 资源请求设置
cpu: string // CPU请求,单位为core数,容器启动的初始可用数量
memory: string // 内存请求,单位可以为MiB、GiB等,容器启动的初始可用数量
livenessProbe: // pod内各容器健康检查的设置
exec: // 对pod内各容器健康检查的设置,exec方式
command: [string] // exec方式需要指定的命令或者脚本
httpGet: // 对pod内各容器健康检查的设置,使用httpGet方式,需指定path、port
path: string // 指定的路径
port: number // 指定的端口
host: string // 指定的主机
scheme: string
httpHeaders:
- name: string
value: string
tcpSocket: // 对pod内各容器健康检查的设置,tcpSocket方式
port: number
initialDelaySeconds: 0 // 容器启动完成后首次探测的时间,单位为s
timeoutSeconds: 0 // 对容器健康检查的探测等待响应的超时时间设置,单位为s,默认值为1s。若超过该超时时间设置,则将认为该容器不健康,会重启该容器
periodSeconds: 0 // 对容器健康检查的定期探测时间设置,单位为s,默认10s探测一次
successThreshold: 0
failureThreshold: 0
securityContest:
privileged: false
restartPolicy: Always | Never | OnFailure // 重启策略,默认为always
nodeSelector: object // 节点选择,表示将该Pod调度到包含这些label的node上,以key:value的方式指定
imagePullSecrets: // pull镜像时使用的secret名称,以name:secretkey格式指定
- name: string
hostNetwork: false // 是否使用主机网络模式,弃用docker网桥,默认为否
volumes: // 在该pod上定义的共享存储卷列表
- name: string // 共享存储卷的名称,在一个pod中每个存储卷定义一个名称
emptyDir: {} // 类型为emptyDir的存储卷,表示与pod同生命周期的一个临时目录,其值为一个空对象:emptyDir: {}
hostPath: // 类型为hostPath的存储卷,表示pod容器挂载的宿主机目录,通过volumes[].hostPath.path指定
path: string // pod容器挂载的宿主机目录
secret: // 类型为secret的存储卷,表示挂载集群预定义的secret对象到容器内部
secretName: string
items:
- key: string
path: string
configMap: // 类型为configMap的存储卷,表示挂载集群预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
3.3.2.1.6.创建pod流程
① 用户提交创建Pod的请求,可以通过API Server的REST API,或Kubectl命令行工具;
② apiserver响应命令,通过一系列认证授权,把pod数据存储到etcd,创建deployment资源并初始化(期望状态);
③ controller-manager通过list-watch机制,监测发现新的deployment,将该资源加入到内部工作队列,发现该资源没有关联的pod和replicaset,启用deployment controller创建replicaset资源,再启用replicaset controller创建pod;
④ 创建完成后,将deployment、replicaset、pod资源更新存储到etcd;
⑤ scheduler通过list-watch机制,监测发现新的pod,经过主机过滤、主机打分规则,将pod绑定(binding)到合适的主机;
过滤主机:调度器用一组规则过滤掉不符合要求的主机,比如Pod指定了所需要的资源,那么就要过滤掉资源不够的主机
主机打分:对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等
⑥ 将绑定结果存储到 etcd;
⑦ kubelet每隔20s(可以自定义)向apiserver通过NodeName获取自身Node上所要运行的pod清单,通过与自己的内部缓存进行比较,新增加pod;
⑧ kubelet调用Docker API创建并启动pod;
⑨ kube-proxy为新创建的pod注册动态DNS到CoreOS。给pod的service添加iptables/ipvs规则,用于服务发现和负载均衡;
⑩ controller-manager通过control loop(控制循环)将当前pod状态与用户所期望的状态做对比,如果当前状态与用户期望状态不同,则controller会将pod修改为用户期望状态,实在不行会将此pod删掉,然后重新创建pod。

3.3.2.2.Pod控制器Controller-manager
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod。
- ReplicationController:比较原始的pod控制器,已经被废弃,由ReplicaSet替代
- ReplicaSet:保证副本数量一直维持在期望值,并支持pod数量扩缩容,镜像版本升级
- Deployment:通过控制ReplicaSet来控制Pod,并支持滚动升级、回退版本
- Horizontal Pod Autoscaler:可以根据集群负载自动水平调整Pod的数量,实现削峰填谷
- DaemonSet:在集群中的指定Node上运行且仅运行一个副本,一般用于守护进程类任务
- Job:创建出来的pod只要完成任务就立即退出,不需要重启或重建,用于执行一次性任务
- Cronjob:创建的Pod负责周期性任务控制,不需要持续后台运行
- StatefulSet:管理有状态应用
3.3.2.2.1.ReplicaSet(RS)
ReplicaSet的主要作用是保证一定数量的pod正常运行,它会持续监听这些Pod的运行状态,一旦Pod发生故障,就会重启或重建。同时它还支持对pod数量的扩缩容和镜像版本的升降级。
ReplicaSet和ReplicationController都是副本控制器,其中:
- 相同点:基础功能基本相同
- 不同点:标签选择器的功能不同。Replica Sets支持基于集合的Label selector,RC只支持基于等式的Label Selector
replicas:指定副本数量,是当前rs创建出来的pod的数量,默认为1
selector:选择器,它的作用是建立pod控制器和pod之间的关联关系,采用的Label Selector机制(在pod模板上定义label,在控制器上定义选择器,就可以表明当前控制器能管理哪些pod了)
3.3.2.2.2.Deployment(Deploy)
为了更好的解决服务编排的问题,kubernetes在V1.2版本开始,引入了Deployment控制器。值得一提的是,这种控制器并不直接管理pod,而是通过管理ReplicaSet来简洁管理Pod,即:Deployment管理ReplicaSet,ReplicaSet管理Pod。所以Deployment比ReplicaSet功能更加强大。


Deployment主要功能:
- 支持ReplicaSet的所有功能
- 支持发布的停止、继续
- 支持滚动升级和回滚版本
deployment支持两种更新策略:重建更新和滚动更新,可以通过strategy指定策略类型。
重建更新:在创建出新的Pod之前会先杀掉所有已存在的Pod
spec:
strategy:
type: Recreate
滚动更新:就是杀死一部分Pod,就启动一部分Pod,在更新过程中,存在两个版本Pod
spec:
strategy:
type: RollingUpdate
maxUnavailable: 用来指定在升级过程中不可用Pod的最大数量,默认为25%。
maxSurge: 用来指定在升级过程中可以超过期望的Pod的最大数量,默认为25%。
3.3.2.2.3.Horizontal Pod Autoscaler(HPA)
手工执行kubectl scale命令实现Pod扩容或缩容,但是这显然不符合Kubernetes的定位目标–自动化、智能化。Kubernetes期望可以实现通过监测Pod的使用情况,实现pod数量的自动调整,于是就产生了Horizontal Pod Autoscaler(HPA)这种控制器。
HPA可以获取每个Pod利用率,然后和HPA中定义的指标进行对比,同时计算出需要伸缩的具体值,最后实现Pod的数量的调整。其实HPA与之前的Deployment一样,也属于一种Kubernetes资源对象,它通过追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,这是HPA的实现原理。

需要安装metrics-server用来收集集群中的资源使用情况。
3.3.2.2.4.DaemonSet(DS)
DaemonSet类型的控制器可以保证在集群中的每一台(或指定)节点上都运行一个副本。一般适用于日志收集、节点监控等场景。也就是说,如果一个Pod提供的功能是节点级别的(每个节点都需要且只需要一个),那么这类Pod就适合使用DaemonSet类型的控制器创建。
DaemonSet控制器的特点:
- 每当向集群中添加一个节点时,指定的Pod副本也将添加到该节点上
- 当节点从集群中移除时,Pod也就被回收了

3.3.2.2.5.Job
主要用于负责批量处理(一次要处理指定数量任务)短暂的一次性(每个任务仅运行一次就结束)任务。Job特点如下:
- 当Job创建的pod执行成功结束时,Job将记录成功结束的pod数量
- 当成功结束的pod达到指定的数量时,Job将完成执行

关于重启策略设置的说明:
如果指定为OnFailure,则job会在pod出现故障时重启容器,而不是创建pod,failed次数不变;
如果指定为Never,则job会在pod出现故障时创建新的pod,并且故障pod不会消失,也不会重启,failed次数加1;
如果指定为Always的话,就意味着一直重启,意味着job任务会重复去执行了,当然不对,所以不能设置为Always。
3.3.2.2.6.CronJob(CJ)
CronJob控制器以Job控制器资源为其管控对象,并借助它管理pod资源对象,Job控制器定义的作业任务在其控制器资源创建之后便会立即执行,但CronJob可以以类似于Linux操作系统的周期性任务作业计划的方式控制其运行时间点及重复运行的方式。也就是说,CronJob可以在特定的时间点(反复的)去运行job任务。

schedule: cron表达式,用于指定任务的执行时间
*/1 * * * *
<分钟> <小时> <日> <月份> <星期>
分钟 值从 0 到 59.
小时 值从 0 到 23.
日 值从 1 到 31.
月 值从 1 到 12.
星期 值从 0 到 6, 0 代表星期日
多个时间可以用逗号隔开;范围可以用连字符给出;*可以作为通配符;/表示每
concurrencyPolicy:
Allow: 允许Jobs并发运行(默认)
Forbid: 禁止并发运行,如果上一次运行尚未完成,则跳过下一次运行
Replace: 替换,取消当前正在运行的作业并用新作业替换它
3.3.2.2.7.StatefulSet
对k8s来说,不能使用Deployment部署有状态的服务。通常情况下,Deployment被用来部署无状态服务。
无状态服务(Stateless Service):该服务运行的实例不会在本地存储需要持久化的数据,并且多个实例对于同一个请求响应的结果是完全一致的,比如WordPress实例,我们是不是可以同时启动多个实例,但是我们访问任意一个实例得到的结果都是一样的吧?因为他唯一需要持久化的数据是存储在MySQL数据库中的,所以我们可以说WordPress这个应用是无状态服务,但是MySQL数据库就不是了,因为他需要把数据持久化到本地。同时,在无状态服务集群中,如果把某一个服务抽离出去,一段时间后再加入回集群网络,对集群服务无任何影响,因为它们不需要做交互,不需要数据同步等等;
有状态服务(Stateful Service):就和上面的概念是对立的了,该服务运行的实例需要在本地存储持久化数据,比如上面的MySQL数据库,你现在运行在节点A,那么他的数据就存储在节点A上面的,如果这个时候你把该服务迁移到节点B去的话,那么就没有之前的数据了,因为他需要去对应的数据目录里面恢复数据,而此时没有任何数据。在有状态服务集群中,如果把某一个服务抽离出来,一段时间后再加入回集群网络,此后集群网络会无法使用。
StatefulSet类似于ReplicaSet,但是它可以处理Pod的启动顺序,为保留每个Pod的状态设置唯一标识,同时具有以下功能:
- 稳定的、唯一的网络标识符
- 稳定的、持久化的存储
- 有序的、优雅的部署和缩放
- 有序的、优雅的删除和终止
- 有序的、自动滚动更新
3.3.2.2.7.1.部署模型
StatefulSet的部署模型和Deployment的很相似。
借助PVC(与存储有关)文件系统来存储的实时数据,因此下图就是一个有状态服务的部署。在pod宕机之后重新建立pod时,StatefulSet通过保证hostname不发生变化来保证数据不丢失。因此pod就可以通过hostname来关联(找到)之前存储的数据。

3.3.2.2.7.2.流程
首先,StatefulSet的控制器直接管理的是Pod,而StatefulSet区分这些实例的方式,就是通过在Pod的名字里面加上事先约定好的编号。
其次,Kubernetes通过Headless Service,为这些有编号的Pod,在DNS服务器中生成带有同样编号的DNS记录。只要StatefulSet能够保证这些Pod名字里的编号不变,那么Service中DNS记录也就不会变。
最后,StatefulSet还为每一个Pod分配并创建一个同样编号的PVC。这样就可以保证每个Pod都拥有一个独立的Volume。在这种情况下,即使Pod被删除,它所对应的PVC和PV依然会留下来,所以当这个Pod被重新创建出来之后,Kubernetes会为它找到同样编号的PVC,挂载这个PVC对应的Volume,从而获取到以前保存在Volume中的数据。
其实StatefulSet就是一种特殊的Deployment,只不过它的每个Pod都被编号了。正是由于这种机制,使得具有主从关系的创建成为可能。
3.3.2.2.7.3.访问StatefulSet
Headless Service会为StatefulSet生成相应的DNS我们通过这个来访问
组成方式:{KaTeX parse error: Expected 'EOF', got '}' at position 9: pod-name}̲.{service-name}.{$namespace}.svc.cluster.local
3.3.2.2.7.4.附:Headless Service
Service是Kubernetes项目中用来将一组Pod暴露给外界访问的一种机制,比如一个Deployment有3个Pod,那么我就可以定义一个Service,然后用户只要能访问到这个Service,就能访问到某个具体的Pod。但是,这个Service是怎么被访问到的呢?
第一种方式,以Service的VIP(Virtual IP,即:虚拟IP)方式。比如:当我访问192.168.0.1这个Service的IP地址时,它就是一个VIP。在实际中,它会把请求转发到Service代理的具体Pod上。
第二种方式,就是以Service的DNS方式。在这里又分为两种处理方法:第一种是Normal Service。这种情况下,当访问DNS记录时,解析到的是Service的VIP。第二种是Headless Service。这种情况下,访问DNS记录时,解析到的就是某一个Pod的IP地址。
可以看到,Headless Service不需要分配一个VIP,而是可以直接以DNS记录的方式解析出被代理Pod的IP地址。这样设计可以使Kubernetes项目为Pod分配唯一“可解析身份”。而有了这个身份之后,只要知道了一个Pod的名字以及它对应的Service的名字,就可以非常确定地通过这条DNS记录访问到Pod的IP地址。
3.3.2.3.Service
Service是Kubernetes的核心概念之一,创建一个Service可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上。
Service能够提供负载均衡的能力,但是在使用上有以下限制:只提供4层负载均衡能力,而没有7层功能。
3.3.2.3.1.类型
① ClusterIp
默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP。

示例如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: stabel
template:
metadata:
labels:
app: myapp
release: stabel
env: test
spec:
containers:
- name: myapp
image: wangyanglinux/myapp:v2
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
② Headless Service
是一种特殊的Cluster IP,不需要负载均衡以及单独的Service IP,而是通过coredns访问域名实现服务的访问。
域名格式:服务名称.命名空间.集群名称.
例如:myapp-headless.default.svc.cluster.local.
apiVserion: v1
kind: Service
metadata:
name: myapp-headless
namespace: default
spec:
selector:
app: myapp
clusterIP: "None"
ports:
- port: 80
targetPort: 80
③ NodePort
在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过NodePort来访问该服务。
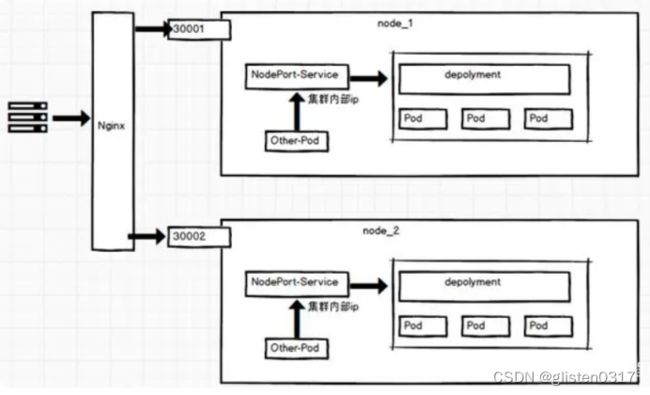
示例如下:
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: NodePort
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80
④ LoadBalancer
在NodePort的基础上,借助Cloud Provider创建一个外部负载均衡器,并将请求转发到NodePort。

⑤ ExternalName
把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有Kubernetes 1.7或更高版本的kube-dns才支持。
这种类型的Service通过返回CNAME和它的值,可以将服务映射到ExternalName字段的内容(例如:hub.atguigu.com);ExternalName Service是Service的特例,它没有selector,也没有定义任何的端口和Endpoint,相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
kind: Service
apiVsersion: v1
metadata:
name: my-service-1
namespace: default
spec:
type: ExternalName
externalName: hub.atguigu.com
3.3.2.3.2.过程描述
客户端访问节点时通过iptables实现的
iptables规则是通过kube-proxy写入的
apiserver通过监控kube-proxy去进行对服务和端点的监控
kube-proxy通过pod的标签(lables)去判断这个断点信息是否写入到Endpoints里

3.3.2.3.3.代理模式
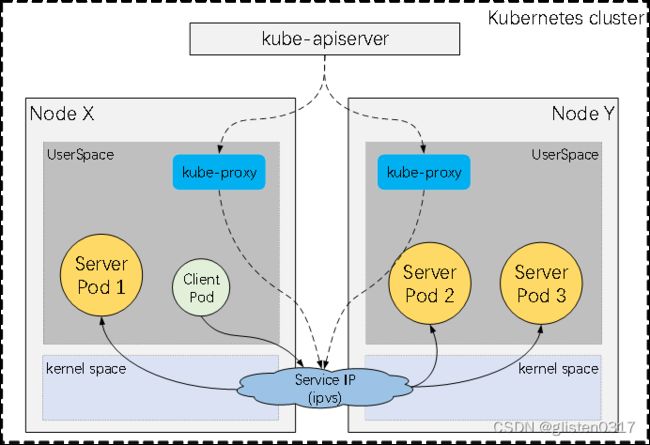
在Kubernetes集群中,每个Node运行一个kube-proxy进程。kube-proxy负责为Service实现了一种VIP的形式,而不是ExternalName的形式。在Kubernetes v1.0版本,代理完全在UserSpace。在Kubernetes v1.1版本,新增了iptables代理,但并不是默认的运行模式。从Kubernetes v1.2起,默认就是iptables代理。在Kubernetes v1.8.0-beta.0中,添加了ipvs代理。在Kubernetes 1.14版本开始默认使用ipvs代理。
在Kubernetes v1.0版本,Service是4层(TCP/UDP over IP)概念。在Kubernetes v1.1版本,新增了Ingress API(beta版),用来表示7层(HTTP)服务。(注:Ingress并非是Service的一种类型)
7层没有采用DNS,是因为DNS会在很多的客户端里进行缓存,很多服务在访问DNS进行域名解析完成、得到地址后不会对DNS的解析进行清除缓存的操作,所以一旦有他的地址信息后,不管访问几次还是原来的地址信息,导致负载均衡无效。
① UserSpace代理模式
Client Pod → Service IP(iptables) → kube-proxy → Server Pod
kube-apiserver → kube-proxy → Service IP(iptables)

② iptables代理模式
Client Pod → Service IP(iptables) → Server Pod
kube-apiserver → kube-proxy → Service IP(iptables)

③ ipvs代理模式
Client Pod → Service IP(ipvs) → Server Pod
kube-apiserver → kube-proxy → Service IP(ipvs)
ipvs代理模式中kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs与netfilter的hook功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
rr:轮询调度
lc:最小连接数
dh:目标哈希
sh:源哈希
sed:最短期望延迟
nq:不排队调度
3.3.2.4.存储ConfigMap/Secret
3.3.2.4.1.ConfigMap
Configmap是k8s中的资源对象,用于保存非机密性的配置的,数据可以用key/value键值对的形式保存,也可通过文件的形式保存。
我们在部署服务的时候,每个服务都有自己的配置文件,如果一台服务器上部署多个服务:nginx、tomcat、apache 等,那么这些配置都存在这个节点上,假如一台服务器不能满足线上高并发的要求,需要对服务器扩容,扩容之后的服务器还是需要部署多个服务:nginx、tomcat、apache,新增加的服务器上还是要管理这些服务的配置,如果有一个服务出现问题,需要修改配置文件,每台物理节点上的配置都需要修改,这种方式肯定满足不了线上大批量的配置变更要求。所以,k8s中引入了Configmap资源对象,可以当成volume挂载到pod中,实现统一的配置管理。
- Configmap是k8s中的资源,相当于配置文件,可以有一个或者多个Configmap;
- Configmap可以做成Volume,k8s pod启动之后,通过volume形式映射到容器内部指定目录上;
- 容器中应用程序按照原有方式读取容器特定目录上的配置文件;
- 在容器看来,配置文件就像是打包在容器内部特定目录,整个过程对应用没有任何侵入。
3.3.2.4.1.1.编写ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
[mysqld]
log-bin
log_bin_trust_function_creators=1
lower_case_table_names=1
slave.cnf: |
[mysqld]
super-read-only
log_bin_trust_function_creators=1
3.3.2.4.1.2.使用ConfigMap
① 通过环境变量引入:使用configMapKeyRef
创建一个存储mysql配置的configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
log: "1"
lower: "1"
创建pod,引用Configmap中的内容
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: busybox
command: [ "/bin/sh", "-c", "sleep 3600" ]
env:
- name: log_bin # 定义环境变量log_bin
valueFrom:
configMapKeyRef:
name: mysql # 指定configmap的名字
key: log # 指定configmap中的key
- name: lower # 定义环境变量lower
valueFrom:
configMapKeyRef:
name: mysql
key: lower
restartPolicy: Never
② 通过环境变量引入:使用envfrom
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod-envfrom
spec:
containers:
- name: mysql
image: busybox
command: [ "/bin/sh", "-c", "sleep 3600" ]
envFrom:
- configMapRef:
name: mysql # 指定configmap的名字
restartPolicy: Never
③ 把configmap做成volume,挂载到pod
创建一个mysql的配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
log: "1"
lower: "1"
my.cnf: |
[mysqld]
Welcome=hello
创建pod,将configmap做成volume并挂载
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod-volume
spec:
containers:
- name: mysql
image: busybox
command: [ "/bin/sh","-c","sleep 3600" ]
volumeMounts:
- name: mysql-config
mountPath: /tmp/config
volumes:
- name: mysql-config
configMap:
name: mysql
restartPolicy: Never
3.3.2.4.2.Secret
Secret解决了密码、token、秘钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者Pod Spec中。Secret可以以Volume或者环境变量的方式使用。
Secret类型:
- Service Account:用于被serviceaccount引用。serviceaccout创建时Kubernetes会默认创建对应的secret。Pod如果使用了serviceaccount,对应的secret会自动挂载到Pod的/run/secrets/kubernetes.io/serviceaccount目录中;
- Opaque:base64编码格式的Secret,用来存储密码、秘钥等。可以通过base64 --decode解码,获得原始数据,因此安全性弱;
- kubernetes.io/dockerconfigjson:用来存储私有docker registry的认证信息。
3.3.2.4.2.1.通过环境变量引入Secret
把mysql的root用户的password创建成secret
kubectl create secret generic mysql-password --from-literal=password=xxxxx
kubectl describe secret mysql-password # 查看secret详信息
创建pod,引用secret
apiVersion: v1
kind: Pod
metadata:
name: pod-secret
labels:
app: myapp
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
env:
- name: MYSQL_ROOT_PASSWORD # 它是Pod启动成功后,Pod中容器的环境变量名
valueFrom:
secretKeyRef:
name: mysql-password # 这是secret的对象名
key: password # 它是secret中的key名
进入pod查看环境变量MYSQL_ROOT_PASSWORD的值为xxxxx
3.3.2.4.2.2.通过volume挂载Secret
手动加密,基于base64加密
echo -n 'admin' | base64
YWRtaW4=
echo -n 'xuegod123456f' | base64
eHVlZ29kMTIzNDU2Zg==
解码
echo eHVlZ29kMTIzNDU2Zg== | base64 -d
创建secret文件
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: eHVlZ29kMTIzNDU2Zg==
将Secret挂载到Volume中
apiVersion: v1
kind: Pod
metadata:
name: pod-secret-volume
spec:
containers:
- name: myapp
image: registry.cn-beijing.aliyuncs.com/google_registry/myapp:v1
volumeMounts:
- name: secret-volume
mountPath: /etc/secret
readOnly: true
volumes:
- name: secret-volume
secret:
secretName: mysecret
进入pod可以看到/etc/secret下有password和username两个文件,查看内容和我们创建的secret内容吻合。
3.3.2.4.2.3.私有镜像仓库secret
创建
kubectl create secret docker-registry registry-pull-secret --docker-server=192.168.1.62 --docker-username=admin --docker-password=Harbor12345
# docker-registry 为secret参数,指定创建的secret用于docker仓库的认证
# registry-pull-secret 为创建的secret名称
# --docker-server=192.168.1.62 指定私有仓库地址
# --docker-username=admin 指定私有仓库用户名
# --docker-password=Harbor12345 指定私有仓库密码
使用
/etc/docker/daemon.json添加如下内容:
"insecure-registries":["192.168.1.62","harbor"]
重启docker使配置生效
systemctl daemon-reload && systemctl restart docker && systemctl status docker
登录到私有仓库,输入账号、密码。(前提是私有仓库已搭建好,并创建了项目、上传了镜像)
docker login 192.168.1.62
创建pod,使用仓库中的镜像,并指定拉取镜像时用的secret。
apiVersion: v1
kind: Pod
metadata:
name: pod-secret
spec:
containers:
- name: myapp
image: 192.168.1.62/test/myapp:v1 # 指定私有仓库中的镜像
imagePullPolicy: IfNotPresent
volumes:
- name: secret-volume
secret:
secretName: mysecret
imagePullSecrets: # 指定拉取镜像用到的secret
- name: registry-pull-secret
3.4.部署方式
kubernetes有多种部署方式,目前主流的方式有kubeadm、minikube、二进制包三种。
(1)minikube:一个用于快速搭建单节点的kubernetes工具
(2)kubeadm:一个用于快速搭建kubernetes集群的工具
(3)二进制包:从官网上下载每个组件的二进制包依次安装,此方式对于理解kubernetes组件更加有效
3.5.接口
K8S的设计初衷就是支持可插拔架构,解决PaaS平台不好用、不能用、需要定制化等问题,K8S集成了插件、附加组件、服务和接口来扩展平台的核心功能。附加组件被定义为与环境的其他部分无缝集成的组件,提供类似本机的特性,并扩展集群管理员可用的组件,扩展还可以用于添加自定义软硬件的支持;服务和接口提供了看似繁琐和冗余的设计(比如我们常见的PV、PVC、SC),实际上为开发人员提供了更多的可扩展性。在本文中,我们将更多地关注K8S提供三个特定功能的接口插件:运行时插件、存储插件和网络插件。更具体地说,我们将讨论容器网络接口(CNI)、容器运行时接口(CRI)和容器存储接口(CSI)如何扩展K8S的核心功能,以及它对定制服务的支持。

- CRI(Container Runtime Interface):容器运行时接口,提供计算资源
- CNI(Container Network Interface):容器网络接口,提供网络资源
- CSI(Container Storage Interface):容器存储接口,提供存储资源
3.5.1.容器运行时接口CRI
CRI中定义了容器和镜像的服务的接口,因为容器运行时与镜像的生命周期是彼此隔离的,因此需要定义两个服务。该接口使用Protocol Buffer,基于gRPC,在kubernetes v1.7+版本中是在pkg/kubelet/apis/cri/v1alpha1/runtime的api.proto中定义的。
初期,K8S并没有实现CRI功能,docker运行时代码跟kubelet代码耦合在一起,再加上后期其它容器运行时的加入给kubelet的维护人员带来了巨大负担。解决方式也很简单,把kubelet对容器的调用之间再抽象出一层接口即可,这就是CRI。CRI接口设计的一个重要原则是只关注接口本身,而不关心具体实现,kubelet就只需要跟这个接口打交道。而作为具体的容器项目,比如Docker、rkt、containerd、kata container它们就只需要自己提供一个该接口的实现,然后对kubelet暴露出gRPC服务即可。简单来说,CRI主要作用就是实现了kubelet和容器运行时之间的解耦。

kubelet是客户端,CRI代理(shim)是服务端;
Protocol Buffers API包含两个gRPC服务:ImageService和RuntimeService;
ImageService提供从仓库拉取镜像、查看和移除镜像功能;
RuntimeService负责Pod和容器的生命周期管理,以及与容器的交互(exec/attach/port-forward)。rkt和Docker运行时可以使用一个Socket同时提供两个服务,在kubelet中可以用–container-runtime-endpoint和–image-service-endpoint参数设置这个Socket。
3.5.2.容器网络接口CNI
k8s对Pods之间如何进行组网通信提出了要求,k8s对集群的网络有以下要求:
- 所有的Pods之间可以在不使用NAT网络地址转换的情况下相互通信
- 所有的Nodes之间可以在不使用NAT网络地址转换的情况下相互通信
- 每个Pod自己看到的自己的ip和其他Pod看到的一致
k8s网络模型设计基础原则:每个Pod都拥有一个独立的IP地址,而且假定所有Pod都在一个可以直接连通的、扁平的网络空间中。所以不管它们是否运行在同一个Node(宿主机)中,都要求它们可以直接通过对方的IP进行访问。设计这个原则的原因是,用户不需要额外考虑如何建立Pod之间的连接,也不需要考虑将容器端口映射到主机端口等问题。
由于Kubemetes的网络模型假设Pod之间访问时使用的是对方Pod的实际地址,所以一个Pod内部的应用程序看到的自己的IP地址和端口与集群内其他Pod看到的一样。它们都是Pod实际分配的IP地址(从dockerO上分配的)。将IP地址和端口在Pod内部和外部都保持一致,我们可以不使用NAT来进行转换,地址空间也自然是平的。
鉴于上面这些要求,我们需要解决四个不同的网络问题: - Docker容器和Docker容器之间的网络
- Pod与Pod之间的网络
- Pod与Service之间的网络
- Internet与Service之间的网络
3.5.2.1.docker网络基础
Docker使用到的与Linux网络有关的主要技术包括:网络命名空间(network namespace)、Veth设备对、网桥(bridge)。
3.5.2.1.1.网络命名空间Network Namespace
network namespace是namespace隔离中的一种,主要提供关于网络资源的隔离,包括网络设备、网络协议栈、ip路由表、iptables等等。**通过对网络资源的隔离,就能在一个宿主机上虚拟出多个不同的网络环境,给外部用户一种透明的感觉,用户仿佛在与一个独立的网络实体进行通信。**Docker正是利用了网络的命名空间特性,实现了不同容器之间的网络隔离。
由于网络命名空间代表的是一个独立的协议栈,所以它们之间是相互隔离的,彼此无法通信,在协议栈内部都看不到对方。为了让不同网络命名空间彼此通信,通常的做法是创建一个Veth设备对,一端放在新的namespace中(通常命名为eth0),另一端放在原先的namespace中连接物理网络设备,再通过把多个设备接入网桥或者进行路由转发,来实现通信的目的。
所有的网络设备(物理的或虚拟接口、桥等在内核里都叫做Net Device),且都只能属于一个命名空间。
3.5.2.1.2.Veth设备对
Veth设备即Virtual Ethernet Device(虚拟以太网设备),引入Veth设备对是为了在不同的网络命名空间之间通信。Veth设备对的重要作用就是打通互相看不到的协议栈之间的壁垒,它就像一条管子,一端连接着这个网络命名空间的协议栈,一端连接着另一个网络命名空间的协议栈。所以如果两个命名空间之间通信,就必须有一个Veth设备对。利用它可以直接将两个网络命名空间连接起来。由于要连接两个网络命名空间,所以Veth设备都是成对出现的,很像一对网卡。
3.5.2.1.3.网桥
网桥是一个二层的虚拟网络设备,简单的理解,相当于现实世界的交换机,把若干个网络接口“连接”起来,以使得网络接口之间的报文能够相互转发。网桥能够解析收发的报文,读取目标MAC地址信息,根据已经记录的MAC表,来决定向哪个目标网络接口进行转发。
Linux网桥的实现
Linux内核是通过一个虚拟的网桥设备(Net Device)来实现桥接的。这个虚拟设备可以绑定若干个以太网接口设备,从而将它们桥接起来。如下图所示,这种Net Device网桥和普通的设备不同,最明显的一个特性是它还可以有一个IP地址。

上图中,网桥设备br0绑定了eth0和eth1。对于网络协议栈的上层来说,只看得到br0就行。因为桥接是在数据链路层实现的,上层不需要关心桥接的细节,所以协议栈上层需要发送的报文被送到br0,网桥设备来判断报文该被转发到eth0还是eth1,或者两者皆转发;反过来,从eth0或从eth1接收到的报文被提交给网桥,在这里会判断报文应该被转发、丢弃还是被提交到协议栈上层。
3.5.2.2.容器和容器之间的网络
在k8s中每个Pod中管理着一组Docker容器,这些Docker容器共享同一个网络命名空间。Pod中的每个Docker容器拥有与Pod相同的IP和port地址空间,并且由于他们在同一个网络命名空间,他们之间可以通过localhost相互访问。什么机制让同一个Pod内的多个docker容器相互通信?其实是使用Docker的一种网络模型:–net=container。
container模式指定新创建的Docker容器和已经存在的一个容器共享一个网络命名空间,而不是和宿主机共享。新创建的Docker容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。每个Pod容器有有一个pause容器其有独立的网络命名空间,在Pod内启动Docker容器时候使用–net=container就可以让当前Docker容器加入到Pod容器拥有的网络命名空间(pause容器)。

3.5.2.3.Pod与Pod之间的网络
k8s中,每个Pod拥有一个ip地址,不同的Pod之间可以直接使用该ip与彼此进行通讯;在同一个Node上,从Pod的视角看,它存在于自己的网络命名空间中,并且需要与该Node上的其他网络命名空间上的Pod进行通信。

那么是如何做到的?这多亏了使用linux虚拟以太网设备或者说是由两个虚拟接口组成的veth对使不同的网络命名空间链接起来,这些虚拟接口分布在多个网络命名空间上(这里是指多个Pod上)。
为了让多个Pod的网络命名空间链接起来,我们可以让veth对的一端链接到root网络命名空间(宿主机的),另一端链接到Pod的网络命名空间。
每对Veth就像一根接插电缆,连接两侧并允许流量在它们之间流动;这种veth对可以推广到同一个Node上任意多的Pod上,如上图这里展示使用veth对链接每个Pod到虚拟机的root网络命名空间。
网桥实现了ARP协议用来根据给定的ip地址找到对应机器的数据链路层的mac地址,一开始转发表为空,当一个数据帧被网桥接受后,网桥会广播该帧到所有的链接设备(除了发送方设备),并且把响应这个广播的设备记录到转发表;随后发往相同ip地址的流量会直接从转发表查找正确的mac地址,然后转发包到对应的设备。

3.5.2.3.1.同一个Node中的Pod之间的一次通信
鉴于每个Pod有自己独立的网络命名空间,我们使用虚拟以太网设备把多个Pod的命名空间链接到了root命名空间,并且使用网桥让多个Pod之间进行通信。

通过网桥这里把veth0和veth1组成为一个以太网,他们直接是可以直接通信的,另外这里通过veth对让pod1的eth0和veth0、pod2的eth0和veth1关联起来,从而让pod1和pod2相互通信。
pod1通过自己默认的以太网设备eth0发送一个数据包,eth0把数据传递给veth0,数据包到达网桥后,网桥通过转发表把数据传递给veth1,然后虚拟设备veth1直接把包传递给pod2网络命名空间中的虚拟设备eth0。
3.5.2.3.2.不同Node中的Pod之间通信
k8s网络模型需要每个pod必须通过ip地址可以进行访问,每个pod的ip地址总是对网络中的其他pod可见,并且每个pod看待自己的ip与别的pod看待的是一样的。
k8s中每个集群中的每个Node都会被分配了一个CIDR块(无类别域间路由选择,把网络前缀都相同的连续地址组成的地址组称为CIDR地址块)用来给该Node上的Pod分配IP地址。(保证pod的ip不会冲突),另外还需要把pod的ip与所在的nodeip关联起来。

如上图Node1(vm1)上的Pod1与Node2(vm2)上Pod4之间进行交互。
首先pod1通过自己的以太网设备eth0把数据包发送到关联到root命名空间的veth0上,然后数据包被Node1上的网桥设备cbr0接受到,网桥查找转发表发现找不到pod4的Mac地址,则会把包转发到默认路由(root命名空间的eth0设备),然后数据包经过eth0就离开了Node1,被发送到网络。
数据包到达Node2后,首先会被root命名空间的eth0设备,然后通过网桥cbr0把数据路由到虚拟设备veth1,最终数据表会被流转到与veth1配对的另外一端(pod4的eth0)
每个Node都知道如何把数据包转发到其内部运行的Pod,当一个数据包到达Node后,其内部数据流就和Node内Pod之间的流转类似了。
对于如何来配置网络,k8s在网络这块自身并没有实现网络规划的具体逻辑,而是制定了一套CNI(Container Network Interface)接口规范,开放给社区来实现。
例如AWS,亚马逊为k8s维护了一个容器网络插件,使用CNI插件来让亚马逊VPC环境中的Node与Node直接进行交互;CoreOS的Flannel是k8s中实现CNI规范较为出名的一种实现。
3.5.2.4.Pod与Service之间的网络
Pod之间通过他们自己的ip地址进行通信,但是pod的ip地址是不持久的,当集群中pod的规模缩减或者pod故障或者node故障重启后,新的pod的ip就可能与之前的不一样的。所以k8s中衍生出来Service来解决这个问题。
k8s中Service管理了一系列的Pods,每个Service有一个虚拟的ip,要访问service管理的Pod上的服务只需要访问你这个虚拟ip就可以了,这个虚拟ip是固定的,当service下的pod规模改变、故障重启、node重启时候,对使用service的用户来说是无感知的,因为他们使用的service的ip没有变。
当数据包到达Service虚拟ip后,数据包会被通过k8s给该servcie自动创建的负载均衡器路由到背后的pod容器。
3.5.2.4.1.netfilter
为了实现负载均衡,k8s依赖linux内建的网络框架netfilter。Netfilter是Linux提供的内核态框架,允许使用者自定义处理接口实现各种与网络相关的操作。Netfilter为包过滤,网络地址转换和端口转换提供各种功能和操作,以及提供禁止数据包到达计算机网络内敏感位置的功能。
3.5.2.4.2.iptables
iptables是运行在用户态的用户程序,其基于表来管理规则,用于定义使用netfilter框架操作和转换数据包的规则。
在k8s中,iptables规则由kube-proxy控制器配置,该控制器监视K8s API服务器的更改。当对Service或Pod的虚拟IP地址进行修改时,iptables规则也会更新以便让service能够正确的把数据包路由到后端Pod。
iptables规则监视发往Service虚拟IP的流量,并且在匹配时,从可用Pod集合中选择随机Pod IP地址,iptables规则将数据包的目标IP地址从Service的虚拟IP更改为选定的Pod的ip。总的来说iptables已在机器上完成负载平衡,并将指向Servcie的虚拟IP的流量转移到实际的pod的IP。
在从service到pod的路径上,IP地址来自目标Pod。在这种情况下,iptables再次重写IP头以将Pod IP替换为Service的IP,以便Pod认为它一直与Service的虚拟IP通信。
3.5.2.4.3.IPVS
k8s的最新版本(1.11)包括了用于集群内负载平衡的第二个选项:IPVS。IPVS(IP Virtual Server)也构建在netfilter之上,并实现传输层负载平衡(属于Linux内核的一部分)。IPVS包含在LVS(Linux虚拟服务器)中,它在主机上运行,并在真实服务器集群前充当负载均衡器。IPVS可以将对基于TCP和UDP的服务的请求定向到真实服务器,并使真实服务器的服务在单个IP地址上显示为虚拟服务。这使得IPVS非常适合Kubernetes服务。
声明Kubernetes服务时,您可以指定是否要使用iptables或IPVS完成群集内负载平衡。IPVS专门用于负载平衡,并使用更高效的数据结构(哈希表),与iptables相比,允许几乎无限的规模。在创建IPVS负载时,会发生以下事情:在Node上创建虚拟IPVS接口,将Service的IP地址绑定到虚拟IPVS接口,并为每个Service额IP地址创建IPVS服务器。将来,期望IPVS成为集群内负载平衡的默认方法。
3.5.2.4.4.Pod到Service的一个包的流转
当从一个Pod发送数据包到Service时候,数据包先从Pod1所在的虚拟设备eth0离开pod1,并通过veth对的另外一端veth0传递给网桥cbr0,网桥找不到service对应ip的mac地址,所以把包转发给默认路由,也就是root命名空间的eth0;
在root命名空间的设备eth0接受到数据包前,数据包会经过iptables进行过滤,iptables接受数据包后会使用kube-proxy在Node上安装的规则来响应Service或Pod的事件,将数据包的目的地址从Service的IP重写为Service后端特定的Pod IP(本例子中是pod4)
现在数据包的目的ip就不再是service的ip地址了,而是pod4的ip地址;
iptables利用Linux内核的conntrack来记住所做的Pod选择,以便将来的流量路由到同一个Pod(禁止任何扩展事件)。从本质上讲,iptables直接在Node上进行了集群内负载均衡,然后流量使用我们已经检查过的Pod-to-Pod路由流到Pod。

3.5.2.4.5.Service到Pod的一个包的流转
收到此数据包的Pod将会回发包到源Pod,回包的源IP识别为自己的IP(比如这里为Pod4的ip),将目标IP设置为最初发送数据包的Pod(这里为pod1的ip);
数据包进入目标Pod(这里为Pod1)所在节点后,数据包流经iptables,它使用conntrack记住它之前做出的选择,并将数据包的源IP重写为Service的IP。 从这里开始,数据包通过网桥流向与Pod1的命名空间配对的虚拟以太网设备,并流向我们之前看到的Pod1的以太网设备。
3.5.2.5.Internet与Service之间的网络
3.5.2.5.1.k8s流量到Internet
数据包源自Pod1的网络命名空间,并通过veth对连接到root命名空间。
一旦root命名空间,数据包就会从网桥cbr0流传到到默认设备eth0,因为数据包上的目的IP与连接到网桥的任何网段都不匹配,在到达root命名空间的以太网设备eth0之前,iptables会修改数据包。
在这种情况下,数据包的源IP地址是Pod1的ip地址,如果我们将源保持为Pod1,则Internet网关将拒绝它,因为网关NAT仅了解连接到vm的IP地址。解决方案是让iptables执行源NAT - 更改数据包源 - 以便数据包看起来来自VM而不是Pod。
有了正确的源IP,数据包现在可以离开VM,并到达Internet网关。 Internet网关将执行另一个NAT,将源IP从VM内部IP重写为Internet IP。最后,数据包将到达公共互联网。在回来数据包的路上,数据包遵循相同的路径,任何源IP都会与发送时候做相同的修改操作,以便系统的每一层都接收它理解的IP地址:Node,以及Pod命名空间中中的Pod IP。

3.5.2.5.2.Internet到k8s
3.5.2.5.2.1.NodePort(四层)
如果您需要将一个Service公开到集群外部,但又不想使用负载均衡器,则可以使用NodePort。NodePort将Service公开到所有节点的IP地址上,并将随机端口映射到目标端口。如果您只需要将一个Service公开到外部,并且您有一个静态IP地址或DNS名称来访问它,则NodePort可能是一个不错的选择。
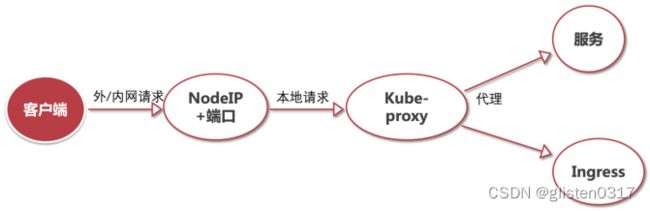
3.5.2.5.2.2.LoadBalancer(四层)
如果您需要将一个Service公开到外部,并且需要一个负载均衡器来处理流量,则可以使用LoadBalancer。LoadBalancer可以将流量负载均衡到多个Pod之间,从而提高应用程序的可用性和可伸缩性。如果您正在运行在公共云环境中,例如AWS、Azure或GCP,那么您可以使用云提供商的负载均衡器服务,否则您可以使用Kubernetes自带的负载均衡器。

3.5.2.5.2.3.Ingress(七层)
如果需要在同一IP地址和端口上公开多个服务,并根据请求路径或主机名进行路由,则可以使用Ingress。Ingress是Kubernetes中的一个抽象层,它可以将多个Service公开到同一个IP地址和端口上,并根据请求路径或主机名进行路由,非常适合用于Web应用程序。

3.5.2.6.CNI网络接口
3.5.2.6.1.接口与解决方案
上面完成了关于整个网络情况的描述,对于Pod之间的网络实现上,为了能更好的适应更多不同的技术方案,k8s设计了一个网络接口,即CNI(Container Network Interface),该接口提供的是一个标准,而非解决方案,主要是为了解决跨主机Pod之间的网络互通问题。具体实现方案上,主要有以下两种:
- 基于隧道:最常见的隧道方案是flannel vxlan模式、calico的ipip模式,优势就是对物理网络环境没有特殊要求,只要宿主机IP层可以路由互通即可;劣势就是性能差,封包和解包耗费CPU性能、额外的封装导致带宽浪费,大约有30%左右的带宽损耗;
- 基于路由:常见的路由方案包括了flannel的host-gw模式、calico的bgp模式,优势就是没有封包和解包过程,完全基于两端宿主机的路由表进行转发;劣势就是要求宿主机处于同一个2层网络下,也就是连在一台交换机上,这样才能基于MAC通讯,而不需要在IP上动封包/解包的手脚,路由表膨胀导致性能降低,因为宿主机上每个容器需要在本机添加一条路由规则,而不同宿主机之间需要广播自己的网段路由规则。
3.5.2.6.2.Flannel
Flannel的功能简单的来讲就是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得同属一个内网且不重复的IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。Flannel实质上是一种覆盖网络(overlay network),也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持udp、vxlan、host-gw、aws-vpc、gce和alloc路由等数据转发方式,常用的的三种转发模式。
hostgw:这种方式就是直接路由(性能最高,要求集群节点在同一个网段)
vxlan:是flannel推荐的方式。需要通信的网络设备能够支持vxlan协议(性能较好)
udp:该方式与vxlan很类似,它对ip层网络进行包装。通常用于调试环境或者不支持vxlan协议网络环境中(性能最差)
优点:
- Flannel相对容易安装和配置;
- 支持多个Kubernetes发行版;
- 使集群中的不同Node主机创建的Docker容器都具有全集群唯一的虚拟IP地址;
- Flannel可以使用Kubernetes集群的现有etcd集群来使用API存储其状态信息,因此不需要专用的数据存储;
- 默认路由使用的方法是使用VXLAN,因为VXLAN性能更良好并且需要的手动干预更少。
缺点: - 不支持pod之间的网络隔离,Flannel设计思想是将所有的pod都放在一个大的二层网络中,所以pod之间没有隔离策略;
- 由于使用二层技术,vlan隔离和tunnel隧道则消耗更多的资源并对物理环境有要求,随着网络规模的增大,整体会变得越加复杂在较大的k8s集群规模下不适用。
3.5.2.6.3.Calico
calico是基于BGP路由实现的容器集群网络方案,Calico是一个纯三层的协议,使用虚拟路由代替虚拟交换。与Flannel不同的是Calico不使用隧道或NAT来实现转发,而是巧妙的把所有二三层流量转换成三层流量,并通过host上路由配置完成跨Host转发。基础的calico使用体验可能和flannel host-gw是基本一样的。Calico在每个计算节点都利用Linux Kernel实现了一个高效的虚拟路由器vRouter来负责数据转发。每个vRouter都通过BGP1协议把在本节点上运行的容器的路由信息向整个Calico网络广播,并自动设置到达其他节点的路由转发规则。Calico保证所有容器之间的数据流量都是通过IP路由的方式完成互联互通的。Calico节点组网时可以直接利用网络结构,不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率。支持两种网络IPIP、BGP。
优点:
- 二层网络通讯需要依赖广播消息机制,广播消息的开销与host的数量呈指数级增长,Calico使用的三层路由方法,完全抑制了二层广播,减少了资源开销;
- 不同之处在于flannel方案下路由都是通过代码逻辑进行配置。calico会在每个节点建立bgp peer,bgp peer彼此之间会进行路由的共享和学习,所以自动生成并维护了路由。在k8s集群大规模的情况下集群间的网络保持通畅;
- Calico较少的依赖性使它能适配所有VM、Container、混合环境场景;
- 支持network-policy,自定义ingress(进栈)egress(出栈)规则。
缺点: - 通过路由规则可以看出,路由规模和pod分布有关,如果pod离散分布在host集群中,会产生较多的路由项;
- 1台Host上可能虚拟化十几或几十个容器实例,过多的iptables规则造成复杂性和不可调试性,同时也存在性能损耗;
- 网关路由问题,当对端网络不为二层可达时,需要通过三层路由机时,需要网关支持自定义路由配置,即pod的目的地址为本网段的网关地址,再由网关进行跨三层转发;
- 简单使用和flannel无异,深层的使用需要有较高的学习成本。
3.5.3.容器存储接口CSI
3.5.3.1.PV/PVC/StorageClass
PV全称叫做Persistent Volume,持久化存储卷。它是用来描述或者说用来定义一个存储卷的。PV有2个重要的参数accessModes和persistentVolumeReclaimPolicy。
- accessModes:支持三种类型ReadWriteMany多路读写,卷能被集群多个节点挂载并读写ReadWriteOnce单路读写,卷只能被单一集群节点挂载读写ReadOnlyMany多路只读,卷能被多个集群节点挂载且只能读。
- persistentVolumeReclaimPolicy:也有三种策略,这个策略是当与之关联的PVC被删除以后,这个PV中的数据如何被处理;Retain当删除与之绑定的PVC时候,这个PV被标记为released(PVC与PV解绑但还没有执行回收策略)且之前的数据依然保存在该PV上,但是该PV不可用,需要手动来处理这些数据并删除该PV;Delete当删除与之绑定的PVC时候
PVC是用来描述希望使用什么样的或者说是满足什么条件的存储,它的全称是Persistent Volume Claim,也就是持久化存储声明。开发人员使用这个来描述该容器需要一个什么存储。比如下面使用NFS的PVC:PV是已有存储,PVC是需要的存储,两者要形成配对需要下面2个条件:
PV和PVC中的spec关键字段要匹配,比如存储(storage)大小;
PV和PVC中的storageClassName字段必须一致。
storageclass:PV是运维人员来创建的,用户操作PVC,可是大规模集群中可能会有很多PV,如果这些PV都需要运维手动来处理这也是一件很繁琐的事情,所以就有了动态供给(Dynamic Provisioning)概念。而手动创建的PV都是静态供给方式(Static Provisioning)是。而动态供给的关键就是StorageClass,它的作用就是创建PV模板。
创建StorageClass里面需要定义PV属性比如存储类型、大小等;另外创建这种PV需要用到存储插件。最终效果是,用户提交PVC,里面指定存储类型,如果符合我们定义的StorageClass,则会为其自动创建PV并进行绑定。
3.5.3.2.CSI接口
CSI是将任意块和文件存储系统公开给Kubernetes等容器编排系统(COs)上的容器化工作负载的标准。使用CSI第三方存储提供商可以编写和部署插件,在Kubernetes中公开新的存储系统,而无需接触Kubernetes的核心代码。
K8S的V1.13版本已经支持了GA版本的CSI组件。
在pod创建过程中,通过指定创建外部卷存储,PVC通过storageclass的动态供给生成对应绑定的PV,PV的创建与绑定由CSI来进行。这时候CSI就可以自己定义如何加载一个卷,如何挂载一个卷。

3.6.常用指令
3.6.1.查看指令
获取节点和服务版本信息
kubectl get nodes
获取节点和服务版本信息,并查看附加信息
kubectl get nodes -o wide
获取pod信息,默认是default名称空间
kubectl get pod
获取pod信息,默认是default名称空间,并查看附加信息【如:pod的IP运行所在节点】
kubectl get pod -o wide
获取指定名称空间的pod
kubectl get pod -n kube-system
获取指定名称空间中的指定pod
kubectl get pod -n kube-system podName
获取所有名称空间的pod
kubectl get pod -A
查看pod的详细信息,以yaml格式或json格式显示
kubectl get pods -o yaml
kubectl get pods -o json
查看pod的标签信息
kubectl get pod -A --show-labels
根据Selector(label query)来查询pod
kubectl get pod -A --selector="k8s-app=kube-dns"
查看运行pod的环境变量
kubectl exec podName env
查看指定pod的日志
kubectl logs -f --tail 500 -n kube-system kube-apiserver-k8s-master
查看所有名称空间的service信息
kubectl get svc -A
查看指定名称空间的service信息
kubectl get svc -n kube-system
查看componentstatuses信息
kubectl get cs
查看所有configmaps信息
kubectl get cm -A
查看所有serviceaccounts信息
kubectl get sa -A
查看所有daemonsets信息
kubectl get ds -A
查看所有deployments信息
kubectl get deploy -A
查看所有replicasets信息
kubectl get rs -A
查看所有statefulsets信息
kubectl get sts -A
查看所有jobs信息
kubectl get jobs -A
查看所有ingresses信息
kubectl get ing -A
查看有哪些名称空间
kubectl get ns
查看pod的描述信息
kubectl describe pod podName
kubectl describe pod -n kube-system kube-apiserver-k8s-master
查看指定名称空间中指定deploy的描述信息
kubectl describe deploy -n kube-system coredns
查看node或pod的资源使用情况,需要heapster 或metrics-server支持
kubectl top node
kubectl top pod
查看集群信息
kubectl cluster-info 或 kubectl cluster-info dump
查看各组件信息【172.16.1.110为master机器】
kubectl -s https://172.16.1.110:6443 get componentstatuses
3.6.2.操作指令
创建资源
kubectl create -f xxx.yaml
应用资源
kubectl apply -f xxx.yaml
应用资源,该目录下的所有.yaml,.yml,或.json文件都会被使用
kubectl apply -f <directory>
创建test名称空间
kubectl create namespace test
删除资源
kubectl delete -f xxx.yaml
kubectl delete -f <directory>
删除指定的pod
kubectl delete pod podName
删除指定名称空间的指定pod
kubectl delete pod -n test podName
删除其他资源
kubectl delete svc svcName
kubectl delete deploy deployName
kubectl delete ns nsName
强制删除
kubectl delete pod podName -n nsName --grace-period=0 --force
kubectl delete pod podName -n nsName --grace-period=1
kubectl delete pod podName -n nsName --now
编辑资源
kubectl edit pod podName
3.6.3.进阶指令
kubectl exec:进入pod启动的容器
kubectl exec -it podName -n nsName /bin/sh
kubectl exec -it podName -n nsName /bin/bash
kubectl label:添加label值
# 为指定节点添加标签
kubectl label nodes k8s-node01 zone=north
# 为指定节点删除标签
kubectl label nodes k8s-node01 zone-
# 为指定pod添加标签
kubectl label pod podName -n nsName role-name=test
# 修改lable标签值
kubectl label pod podName -n nsName role-name=dev --overwrite
# 删除lable标签
kubectl label pod podName -n nsName role-name-
kubectl滚动升级:通过 kubectl apply -f myapp-deployment-v1.yaml启动deploy
# 通过配置文件滚动升级
kubectl apply -f myapp-deployment-v2.yaml
# 通过命令滚动升级
kubectl set image deploy/myapp-deployment myapp="registry.cn-beijing.aliyuncs.com/google_registry/myapp:v3"
# pod回滚到前一个版本
kubectl rollout undo deploy/myapp-deployment 或者 kubectl rollout undo deploy myapp-deployment
# 回滚到指定历史版本
kubectl rollout undo deploy/myapp-deployment --to-revision=2
kubectl scale:动态伸缩
kubectl scale deploy myapp-deployment --replicas=5
# 动态伸缩【根据资源类型和名称伸缩,其他配置「如:镜像版本不同」不生效】
kubectl scale --replicas=8 -f myapp-deployment-v2.yaml
第四章 资源规划
4.1.资源配置
| 主机名 | FQDN | IP | 服务器配置 | 操作系统 |
|---|---|---|---|---|
| master01 | master01.k8s.local | 192.168.111.1/24 | 8c、8G、500GB | CentOS 7.7.1908 |
| master02 | master02.k8s.local | 192.168.111.2/24 | 8c、8G、500GB | CentOS 7.7.1908 |
| master03 | master03.k8s.local | 192.168.111.3/24 | 8c、8G、500GB | CentOS 7.7.1908 |
| worker01 | worker01.k8s.local | 192.168.111.11/24 | 8c、4G、500GB | CentOS 7.7.1908 |
| worker02 | worker02.k8s.local | 192.168.111.12/24 | 8c、4G、500GB | CentOS 7.7.1908 |
| harbor01 | harbor01.k8s.local | 192.168.111.20/24 | 8c、4G、500GB | CentOS 7.7.1908 |
4.2.组件规划
| 组件 | 版本 | master01 | master02 | master03 | worker01 | worker02 | harbor01 | |
| ansible | 2.9.27 | ★ | ||||||
| docker | docker-ce | 23.0.5 | ★ | ★ | ★ | ★ | ★ | ★ |
| docker-compose | 2.16.0 | ★ | ||||||
| harbor | 2.7.2 | ★ | ||||||
| KeepAlived | 1.3.5 | ★ | ★ | |||||
| HAProxy | 1.5.18 | ★ | ★ | |||||
| kubernetes | kube-apiserver | 1.23.5 | ★ | ★ | ★ | |||
| kube-proxy | 1.23.5 | ★ | ★ | ★ | ★ | ★ | ||
| kube-scheduler | 1.23.5 | ★ | ★ | ★ | ||||
| kube-controller-manager | 1.23.5 | ★ | ★ | ★ | ||||
| etcd | 3.5.1 | ★ | ★ | ★ | ||||
| coredns | 1.8.6 | ★ | ||||||
| calico | calico-kube-controllers | 3.23.5 | ★ | |||||
| calico-node | ★ | ★ | ★ | ★ | ★ | |||
第五章 基础环境准备
5.1.SSH免密登录
在master01、master02、master03上生成公钥,配置免密登录到其他节点
ssh-keygen -t rsa -f ~/.ssh/id_rsa -C username_root
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 [email protected]
5.2.ansbile配置
在外网服务器上,下载ansible及相关依赖包
yum install -y epel-release
yumdownloader --resolve --destdir /opt/ansible/ ansible
上传至master01上,并进行安装
rpm -ivh /opt/ansible/*
安装完成后查询版本
[root@localhost ~]# ansible --version
ansible 2.9.27
config file = /etc/ansible/ansible.cfg
configured module search path = [u'/root/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python2.7/site-packages/ansible
executable location = /usr/bin/ansible
python version = 2.7.5 (default, Aug 7 2019, 00:51:29) [GCC 4.8.5 20150623 (Red Hat 4.8.5-39)]
配置ansible和rhel-system-roles,创建配置文件
mkdir /root/ansible
cd /root/ansible
cp /etc/ansible/ansible.cfg /root/ansible/
修改配置文件,/root/ansible/ansible.cfg
[defaults]
inventory = /root/ansible/inventory
ask_pass = false
remote_user = root
配置inventory文件,/root/ansible/inventory
[k8s:children]
master
worker
harbor
[master]
192.168.111.1 hostname=master01
192.168.111.2 hostname=master02
192.168.111.3 hostname=master03
[worker]
192.168.111.11 hostname=worker01
192.168.111.12 hostname=worker02
[harbor]
192.168.111.20 hostname=harbor01
测试
[root@master01 ansible]# ansible all -m ping
192.168.111.3 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
192.168.111.12 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
192.168.111.11 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
192.168.111.1 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
192.168.111.2 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
192.168.111.20 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
5.3.修改主机名
创建playbook,/root/ansible/hostname.yml
---
- name: modify hostname
hosts: all
tasks:
- name: modify hostname permanently
raw: "echo {{ hostname | quote }} > /etc/hostname"
- name: modify hostname temporarily
shell: hostname {{ hostname | quote }}
执行并确认
[root@master01 ansible]# ansible-playbook hostname.yml
PLAY [modify hostname] ****************************************************************************************************************************************
TASK [Gathering Facts] ****************************************************************************************************************************************
ok: [192.168.111.11]
ok: [192.168.111.12]
ok: [192.168.111.1]
ok: [192.168.111.2]
ok: [192.168.111.3]
ok: [192.168.111.20]
TASK [modify hostname permanently] ****************************************************************************************************************************
changed: [192.168.111.2]
changed: [192.168.111.1]
changed: [192.168.111.11]
changed: [192.168.111.3]
changed: [192.168.111.12]
changed: [192.168.111.20]
TASK [modify hostname temporarily] ****************************************************************************************************************************
changed: [192.168.111.3]
changed: [192.168.111.11]
changed: [192.168.111.1]
changed: [192.168.111.2]
changed: [192.168.111.12]
changed: [192.168.111.20]
PLAY RECAP ****************************************************************************************************************************************************
192.168.111.1 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.111.11 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.111.12 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.111.2 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.111.20 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.111.3 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
[root@master01 ansible]# ansible all -m shell -a 'hostname'
192.168.111.3 | CHANGED | rc=0 >>
master03
192.168.111.11 | CHANGED | rc=0 >>
worker01
192.168.111.1 | CHANGED | rc=0 >>
master01
192.168.111.2 | CHANGED | rc=0 >>
master02
192.168.111.12 | CHANGED | rc=0 >>
worker02
192.168.111.20 | CHANGED | rc=0 >>
harbor01
5.4.修改hosts列表
在master01上修改主机列表,/etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.111.1 master01.k8s.local master01
192.168.111.2 master02.k8s.local master02
192.168.111.3 master03.k8s.local master03
192.168.111.11 worker01.k8s.local worker01
192.168.111.12 worker02.k8s.local worker02
192.168.111.20 harbor01.k8s.local harbor01
分发至其他节点
ansible all -m template -a 'src=/etc/hosts dest=/etc/hosts'
5.5.关闭firewall和SELinux
关闭firewall
ansible all -m service -a 'name=firewalld state=stopped enabled=no'
确认状态
[root@master01 ansible]# ansible all -m shell -a 'systemctl status firewalld | grep Active'
192.168.111.11 | CHANGED | rc=0 >>
Active: inactive (dead)
192.168.111.12 | CHANGED | rc=0 >>
Active: inactive (dead)
192.168.111.1 | CHANGED | rc=0 >>
Active: inactive (dead)
192.168.111.3 | CHANGED | rc=0 >>
Active: inactive (dead)
192.168.111.2 | CHANGED | rc=0 >>
Active: inactive (dead)
192.168.111.20 | CHANGED | rc=0 >>
Active: inactive (dead)
关闭SELinux
ansible all -m selinux -a 'policy=targeted state=disabled'
确认状态
[root@localhost ansible]# ansible all -m shell -a 'getenforce'
192.168.111.1 | CHANGED | rc=0 >>
Permissive
192.168.111.11 | CHANGED | rc=0 >>
Permissive
192.168.111.3 | CHANGED | rc=0 >>
Permissive
192.168.111.2 | CHANGED | rc=0 >>
Permissive
192.168.111.12 | CHANGED | rc=0 >>
Permissive
192.168.111.20 | CHANGED | rc=0 >>
Permissive
5.6.配置系统Yum源
【master01】配置CentOS镜像Yum源
mkdir /mnt/cdrom
mount /dev/cdrom /mnt/cdrom/
rm -f /etc/yum.repos.d/*
创建repo文件,/etc/yum.repos.d/local.repo
[centos]
name=centos
baseurl=file:///mnt/cdrom
gpgcheck=0
enabled=1
更新yum源
yum clean all
yum makecache fast
安装httpd服务
yum install -y httpd
systemctl enable --now httpd
配置http服务指向CentOS源
mkdir /var/www/html/centos
umount /mnt/cdrom/
mount /dev/cdrom /var/www/html/centos/
删除原有repo文件
ansible all -m shell -a 'rm -f /etc/yum.repos.d/*.repo'
配置所有节点的系统Yum源
ansible all -m yum_repository -a 'name="centos" description="centos" baseurl="http://master01.k8s.local/centos" enabled=yes gpgcheck=no'
ansible all -m shell -a 'yum clean all'
ansible all -m shell -a 'yum makecache fast'
ansible all -m shell -a 'yum update -y'
5.7.安装基础软件
安装vim等基础软件,/root/ansible/packages.yml
---
- hosts: all
tasks:
- name: install packages
yum:
name:
- pciutils
- bash-completion
- vim
- chrony
- net-tools
state: present
执行并确认
[root@master01 ansible]# ansible-playbook packages.yml
PLAY [all] ****************************************************************************************************************************************************
TASK [Gathering Facts] ****************************************************************************************************************************************
ok: [192.168.111.3]
ok: [192.168.111.1]
ok: [192.168.111.12]
ok: [192.168.111.11]
ok: [192.168.111.2]
ok: [192.168.111.20]
TASK [install packages] ***************************************************************************************************************************************
ok: [192.168.111.2]
ok: [192.168.111.11]
ok: [192.168.111.1]
ok: [192.168.111.12]
ok: [192.168.111.20]
changed: [192.168.111.3]
PLAY RECAP ****************************************************************************************************************************************************
192.168.111.1 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.111.11 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.111.12 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.111.2 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.111.20 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.111.3 : ok=2 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
5.8.NTP时钟
以master01为时钟源,其余节点从master01进行时钟同步
服务端(master01)
修改配置文件,/etc/chrony.conf
# 不指定外部NTP源
# 允许本网段其节点作为客户端访问
allow 192.168.111.0/24
# 如果时间服务可不用,则使用本地时间作为标准时间授权,层数为10
local stratum 10
重启服务
systemctl restart chronyd
客户端(mster02/worker01/worker02/harbor01)
在外网服务器上下载ansible system role的安装包
yumdownloader --resolve rhel-system-roles
将安装包上传至master01的/opt/ansible/下,并进行安装
[root@localhost ~]# rpm -ivh /opt/ansible/python-netaddr-0.7.5-9.el7.noarch.rpm
warning: /opt/ansible/python-netaddr-0.7.5-9.el7.noarch.rpm: Header V3 RSA/SHA256 Signature, key ID f4a80eb5: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:python-netaddr-0.7.5-9.el7 ################################# [100%]
[root@localhost ~]# rpm -ivh /opt/ansible/rhel-system-roles-1.7.3-4.el7_9.noarch.rpm
warning: /opt/ansible/rhel-system-roles-1.7.3-4.el7_9.noarch.rpm: Header V3 RSA/SHA256 Signature, key ID f4a80eb5: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:rhel-system-roles-1.7.3-4.el7_9 ################################# [100%]
安装ntp时钟,/root/ansible/timesync.yml
---
- hosts: 192.168.111.2,192.168.111.3,worker,harbor
vars:
timesync_ntp_servers:
- hostname: 192.168.111.1
iburst: yes
roles:
- rhel-system-roles.timesync
执行
ansible-playbook /root/ansible/timesync.yml
确认时钟同步情况
[root@master01 ansible]# ansible 192.168.111.2,192.168.111.3,worker,harbor -m shell -a 'chronyc sources -v'
192.168.111.12 | CHANGED | rc=0 >>
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* master01.k8s.local 10 6 377 46 +5212ns[ +19us] +/- 73us
192.168.111.3 | CHANGED | rc=0 >>
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* master01.k8s.local 10 6 17 30 -261ns[ -62us] +/- 966us
192.168.111.11 | CHANGED | rc=0 >>
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* master01.k8s.local 10 6 377 35 -17us[ -20us] +/- 130us
192.168.111.20 | CHANGED | rc=0 >>
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* master01.k8s.local 10 6 377 25 -4152ns[-7463ns] +/- 96us
192.168.111.2 | CHANGED | rc=0 >>
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* master01.k8s.local 10 6 377 27 -52us[ -50us] +/- 191us
5.9.关闭swap
临时关闭:
ansible all -m shell -a 'swapoff -a'
永久关闭:
ansible all -m shell -a 'sed -ri "s/.*swap.*/#&/" /etc/fstab'
5.10.启用ipvs转发
在kubernetes中service有两种代理模型,一种是基于iptables的,一种是基于ipvs的;ipvs转发性能更好。
在master01-03上开启ipvs转发
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
赋予执行权限并执行
chmod +x /etc/sysconfig/modules/ipvs.modules
/bin/bash /etc/sysconfig/modules/ipvs.modules
5.11.启用网桥过滤及内核转发
bridge-nf-call-iptables这个内核参数,表示bridge设备在二层转发时也去调用iptables配置的三层规则(包含conntrack),所以开启这个参数就能够解决Service同节点通信问题。
在master01上创建/etc/sysctl.d/k8s.conf,添加网桥过滤及内核转发配置
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
分发至其他节点
ansible all -m template -a 'src=/etc/sysctl.d/k8s.conf dest=/etc/sysctl.d/'
ansible all -m shell -a 'modprobe br_netfilter'
验证是否生效
[root@master01 ansible]# ansible all -m shell -a 'sysctl --system | grep -A3 k8s'
192.168.111.3 | CHANGED | rc=0 >>
* Applying /etc/sysctl.d/k8s.conf ...
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
192.168.111.1 | CHANGED | rc=0 >>
* Applying /etc/sysctl.d/k8s.conf ...
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
192.168.111.12 | CHANGED | rc=0 >>
* Applying /etc/sysctl.d/k8s.conf ...
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
192.168.111.11 | CHANGED | rc=0 >>
* Applying /etc/sysctl.d/k8s.conf ...
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
192.168.111.2 | CHANGED | rc=0 >>
* Applying /etc/sysctl.d/k8s.conf ...
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
192.168.111.20 | CHANGED | rc=0 >>
* Applying /etc/sysctl.d/k8s.conf ...
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
第六章 Docker安装
在master、worker、harbor上均需要安装
6.1.准备安装文件
在外网服务器上,下载安装docker-ce的相关rpm安装文件
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum makecache fast
yum install --downloadonly --downloaddir=/opt/docker-ce docker-ce docker-ce-cli
将下载好的安装文件上传到master01上的/opt/docker-ce中
6.2.制作repo文件
在master01上,创建repo的镜像源
cp -r /opt/docker-ce/ /var/www/html/
yum install createrepo -y
createrepo /var/www/html/docker-ce/
为所有节点创建repo文件
ansible all -m yum_repository -a 'name="docker-ce" description="docker-ce" baseurl="http://master01.k8s.local/docker-ce" enabled=yes gpgcheck=no'
ansible all -m shell -a 'yum clean all'
ansible all -m shell -a 'yum update -y'
6.3.安装docker
通过ansible的yum模块安装docker-ce和docker-ce-cli
ansible all -m yum -a 'name=docker-ce,docker-ce-cli state=present'
设置docker服务随机启动
ansible all -m service -a 'name=docker state=started enabled=yes'
ansible all -m shell -a 'systemctl status docker'
安装完成后查看版本
[root@master01 ansible]# ansible all -m shell -a 'docker version'
192.168.111.1 | CHANGED | rc=0 >>
Client: Docker Engine - Community
Version: 23.0.5
API version: 1.42
Go version: go1.19.8
Git commit: bc4487a
Built: Wed Apr 26 16:18:56 2023
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 23.0.5
API version: 1.42 (minimum version 1.12)
Go version: go1.19.8
Git commit: 94d3ad6
Built: Wed Apr 26 16:16:35 2023
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.6.20
GitCommit: 2806fc1057397dbaeefbea0e4e17bddfbd388f38
runc:
Version: 1.1.5
GitCommit: v1.1.5-0-gf19387a
docker-init:
Version: 0.19.0
GitCommit: de40ad0
192.168.111.3 | CHANGED | rc=0 >>
Client: Docker Engine - Community
Version: 23.0.5
API version: 1.42
Go version: go1.19.8
Git commit: bc4487a
Built: Wed Apr 26 16:18:56 2023
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 23.0.5
API version: 1.42 (minimum version 1.12)
Go version: go1.19.8
Git commit: 94d3ad6
Built: Wed Apr 26 16:16:35 2023
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.6.20
GitCommit: 2806fc1057397dbaeefbea0e4e17bddfbd388f38
runc:
Version: 1.1.5
GitCommit: v1.1.5-0-gf19387a
docker-init:
Version: 0.19.0
GitCommit: de40ad0
192.168.111.11 | CHANGED | rc=0 >>
Client: Docker Engine - Community
Version: 23.0.5
API version: 1.42
Go version: go1.19.8
Git commit: bc4487a
Built: Wed Apr 26 16:18:56 2023
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 23.0.5
API version: 1.42 (minimum version 1.12)
Go version: go1.19.8
Git commit: 94d3ad6
Built: Wed Apr 26 16:16:35 2023
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.6.20
GitCommit: 2806fc1057397dbaeefbea0e4e17bddfbd388f38
runc:
Version: 1.1.5
GitCommit: v1.1.5-0-gf19387a
docker-init:
Version: 0.19.0
GitCommit: de40ad0
192.168.111.2 | CHANGED | rc=0 >>
Client: Docker Engine - Community
Version: 23.0.5
API version: 1.42
Go version: go1.19.8
Git commit: bc4487a
Built: Wed Apr 26 16:18:56 2023
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 23.0.5
API version: 1.42 (minimum version 1.12)
Go version: go1.19.8
Git commit: 94d3ad6
Built: Wed Apr 26 16:16:35 2023
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.6.20
GitCommit: 2806fc1057397dbaeefbea0e4e17bddfbd388f38
runc:
Version: 1.1.5
GitCommit: v1.1.5-0-gf19387a
docker-init:
Version: 0.19.0
GitCommit: de40ad0
192.168.111.12 | CHANGED | rc=0 >>
Client: Docker Engine - Community
Version: 23.0.5
API version: 1.42
Go version: go1.19.8
Git commit: bc4487a
Built: Wed Apr 26 16:18:56 2023
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 23.0.5
API version: 1.42 (minimum version 1.12)
Go version: go1.19.8
Git commit: 94d3ad6
Built: Wed Apr 26 16:16:35 2023
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.6.20
GitCommit: 2806fc1057397dbaeefbea0e4e17bddfbd388f38
runc:
Version: 1.1.5
GitCommit: v1.1.5-0-gf19387a
docker-init:
Version: 0.19.0
GitCommit: de40ad0
192.168.111.20 | CHANGED | rc=0 >>
Client: Docker Engine - Community
Version: 23.0.5
API version: 1.42
Go version: go1.19.8
Git commit: bc4487a
Built: Wed Apr 26 16:18:56 2023
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 23.0.5
API version: 1.42 (minimum version 1.12)
Go version: go1.19.8
Git commit: 94d3ad6
Built: Wed Apr 26 16:16:35 2023
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.6.20
GitCommit: 2806fc1057397dbaeefbea0e4e17bddfbd388f38
runc:
Version: 1.1.5
GitCommit: v1.1.5-0-gf19387a
docker-init:
Version: 0.19.0
GitCommit: de40ad0
6.4.修改docker默认IP
docker默认分配IP为172.17.0.1/16,可能与实际生产环境IP冲突,因此需要根据实际情况对docker分配IP进行调整
[root@master01 ansible]# ansible all -m shell -a 'ifconfig docker0'
192.168.111.1 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:bd:49:a1:7f txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
192.168.111.3 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:0d:24:ee:3c txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
192.168.111.12 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:68:ae:0f:71 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
192.168.111.2 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:dc:e5:f5:cd txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
192.168.111.11 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:4a:68:55:68 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
192.168.111.20 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:69:ed:42:5d txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
docker安装后默认没有daemon.json这个配置文件,需要进行手动创建。配置文件的默认路径:/etc/docker/daemon.json
该文件作为Docker Engine的配置管理文件,里面几乎涵盖了所有docker命令行启动可以配置的参数。不管是在哪个平台以何种方式启动,Docker默认都会来这里读取配置。使用户可以统一管理不同系统下的docker daemon配置。
如果在daemon.json文件中进行配置,需要docker版本高于1.12.6(在这个版本上不生效,1.13.1以上是生效的)。
配置docker分配IP段为1.1.1.1/24
{
"bip": "1.1.1.1/24"
}
将daemon.json文件分发至其他节点上
ansible all -m template -a 'src=/etc/docker/daemon.json dest=/etc/docker/'
重启服务
ansible all -m systemd -a 'daemon_reload=yes'
ansible all -m service -a 'name=docker state=restarted'
查看IP确认
[root@master01 ansible]# ansible all -m shell -a 'ifconfig docker0'
192.168.111.3 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 1.1.1.1 netmask 255.255.255.0 broadcast 1.1.1.255
ether 02:42:0d:24:ee:3c txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
192.168.111.11 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 1.1.1.1 netmask 255.255.255.0 broadcast 1.1.1.255
ether 02:42:4a:68:55:68 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
192.168.111.2 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 1.1.1.1 netmask 255.255.255.0 broadcast 1.1.1.255
ether 02:42:dc:e5:f5:cd txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
192.168.111.1 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 1.1.1.1 netmask 255.255.255.0 broadcast 1.1.1.255
ether 02:42:bd:49:a1:7f txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
192.168.111.12 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 1.1.1.1 netmask 255.255.255.0 broadcast 1.1.1.255
ether 02:42:68:ae:0f:71 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
192.168.111.20 | CHANGED | rc=0 >>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 1.1.1.1 netmask 255.255.255.0 broadcast 1.1.1.255
ether 02:42:69:ed:42:5d txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
第七章 Harbor搭建
Docker-Compose是用来管理容器的,类似用户容器管家,我们有N多台容器或者应用需要启动的时候,如果手动去操作,是非常耗费时间的,如果有了Docker-Compose只需要一个配置文件就可以帮我们搞定,但是Docker-Compose只能管理当前主机上的Docker,不能去管理其他服务器上的服务。与k8s的区别如下:
- compose是docker推出的(swarm也是,级别同k8s),k8s是CNCF推出的
- compose只能在一台宿主机上编排容器,而k8s可以在很多台机器上编排容器
Docker-Compose由python实现,调用docker服务的API负责实现对docker容器集群的快速编排,即通过一个单独的yaml文件,来定义一组相关的容器来为一个项目服务。因此,harbor也是通过Docker-Compose来实现的。
过程:harbor下有install.sh脚本,里面会调用docker-compose,通过配置文件harbor.yml来实现对harbor的安装。
7.1.安装dockers-compose
docker-compose软件是一个可执行的二进制文件,在harbor01上将二进制文件上传至/usr/local/bin后赋予执行权限。
下载链接:
https://github.com/docker/compose/releases/download/v2.16.0/docker-compose-linux-x86_64
cp /opt/harbor/docker-compose-linux-x86_64 /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
查看版本
[root@harbor01 ~]# docker-compose --version
Docker Compose version v2.16.0
7.2.安装harbor
7.2.1.安装
下载harbor安装包,下载页面:
https://github.com/goharbor/harbor/releases/tag/v2.7.2
上传后解压
tar -xvf /opt/harbor/harbor-offline-installer-v2.7.2.tgz -C /opt/harbor/
修改yaml配置文件
cp /opt/harbor/harbor/harbor.yml.tmpl /opt/harbor/harbor/harbor.yml
修改内容如下:
# 修改hostname
hostname: harbor01.k8s.local
# 不使用http协议,注释掉http和port选项
#http:
# port: 80
# 启用https协议
https:
port: 443
# 证书位置
certificate: /opt/harbor/harbor/certs/harbor.crt
# 私钥位置
private_key: /opt/harbor/harbor/certs/harbor.key
# 页面密码
harbor_admin_password: lnyd@LNsy115
database:
# 数据库密码
password: root123
# 存储位置
data_volume: /data
创建数据存储目录
mkdir /data
创建证书和私钥对应的路径
mkdir /opt/harbor/harbor/certs
7.2.2.生成自签证书
- 生成证书颁发机构证书
生成CA证书私钥(ca.key)
[root@harbor01 harbor]# cd /opt/harbor/harbor/certs/
[root@harbor01 certs]# openssl genrsa -out ca.key 4096
Generating RSA private key, 4096 bit long modulus
.........++
....................................................................................................................++
e is 65537 (0x10001)
生成CA证书(ca.crt)
调整-subj选项中的值以反映组织信息,如果使用FQDN连接Harbor主机,则必须将其指定为通用名称(CN)属性。
openssl req -x509 -new -nodes -sha512 -days 3650 \
-subj "/C=CN/ST=Liaoning/L=Shenyang/O=kubernetes/OU=Personal/CN=harbor01.k8s.local" \
-key ca.key \
-out ca.crt
- 生成服务器证书
证书通常包含一个.crt文件和一个.key文件
生成私钥(harbor01.k8s.local.key)
[root@harbor01 certs]# openssl genrsa -out harbor01.k8s.local.key 4096
Generating RSA private key, 4096 bit long modulus
........................................................................................................................................++
.........................................................................................................++
e is 65537 (0x10001)
生成证书签名请求(harbor01.k8s.local.csr)
openssl req -sha512 -new \
-subj "/C=CN/ST=Liaoning/L=Shenyang/O=kubernetes/OU=Personal/CN=harbor01.k8s.local" \
-key harbor01.k8s.local.key \
-out harbor01.k8s.local.csr
生成一个x509 v3扩展文件(v3.ext)
无论使用FQDN还是IP地址连接到Harbor主机,都必须创建此文件,以便可以为Harbor主机生成符合主题备用名称(SAN)和x509 v3的证书扩展要求。替换DNS条目以反映域。
cat > v3.ext <<-EOF
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
extendedKeyUsage = serverAuth
subjectAltName = @alt_names
[alt_names]
DNS.1=harbor01.k8s.local
DNS.2=harbor01.k8s.local
DNS.3=harbor01.k8s.local
EOF
使用v3.ext文件生成Harbor服务器证书(harbor01.k8s.local.crt)
[root@harbor01 certs]# openssl x509 -req -sha512 -days 3650 \
> -extfile v3.ext \
> -CA ca.crt -CAkey ca.key -CAcreateserial \
> -in harbor01.k8s.local.csr \
> -out harbor01.k8s.local.crt
Signature ok
subject=/C=CN/ST=Liaoning/L=Shenyang/O=kubernetes/OU=Personal/CN=harbor01.k8s.local
Getting CA Private Key
7.2.3.配置daemon.json文件
在master01上配置镜像加速地址以及
{
"registry-mirrors": ["https://harbor01.k8s.local"],
"exec-opts": ["native.cgroupdriver=systemd"],
"bip": "1.1.1.1/24"
}
将daemon.json文件分发至其他节点上
ansible all -m template -a 'src=/etc/docker/daemon.json dest=/etc/docker/'
注:
① docker的cgroup驱动程序默认设置为system,默认情况下Kubernetes cgroup为systemd,因此需要更改Docker cgroup驱动。否则会在后面的kubeadm init时报错;
② Docker从1.3.X之后,与docker registry交互默认使用的是https,http服务则需要增加insecure-registries配置。
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp: lookup localhost on [::1]:53: read udp [::1]:41922->[::1]:53: read: connection refused.
配置完成后,需要重启docker服务
ansible all -m systemd -a 'daemon_reload=yes'
ansible all -m service -a 'name=docker state=restarted'
7.2.4.启动harbor
在/opt/harbor下启动harbor
[root@harbor01 ~]# cd /opt/harbor/harbor
[root@harbor01 harbor]# ./install.sh
[Step 0]: checking if docker is installed ...
Note: docker version: 23.0.5
[Step 1]: checking docker-compose is installed ...
Note: Docker Compose version v2.17.3
[Step 2]: loading Harbor images ...
17d981d1fd47: Loading layer [==================================================>] 37.78MB/37.78MB
066f24b65b06: Loading layer [==================================================>] 8.91MB/8.91MB
f5c5b2da3f78: Loading layer [==================================================>] 3.584kB/3.584kB
4cd07c2f1254: Loading layer [==================================================>] 2.56kB/2.56kB
90b02d6624a2: Loading layer [==================================================>] 87.15MB/87.15MB
b1c452c676c1: Loading layer [==================================================>] 5.632kB/5.632kB
a07864b2e153: Loading layer [==================================================>] 108kB/108kB
26a29846faca: Loading layer [==================================================>] 44.03kB/44.03kB
15c5d56364b4: Loading layer [==================================================>] 88.09MB/88.09MB
07cc9a12826b: Loading layer [==================================================>] 2.56kB/2.56kB
Loaded image: goharbor/harbor-core:v2.7.2
d381f65a97a8: Loading layer [==================================================>] 8.91MB/8.91MB
a5ba716047be: Loading layer [==================================================>] 25.63MB/25.63MB
8af720b31993: Loading layer [==================================================>] 4.608kB/4.608kB
cf85d4aafef0: Loading layer [==================================================>] 26.42MB/26.42MB
Loaded image: goharbor/harbor-exporter:v2.7.2
9090e472d914: Loading layer [==================================================>] 6.295MB/6.295MB
95706aae16e4: Loading layer [==================================================>] 4.096kB/4.096kB
1e59d3cfe0b1: Loading layer [==================================================>] 3.072kB/3.072kB
c15f397332af: Loading layer [==================================================>] 190.7MB/190.7MB
625812afd6af: Loading layer [==================================================>] 13.75MB/13.75MB
bc49c81af9a3: Loading layer [==================================================>] 205.2MB/205.2MB
Loaded image: goharbor/trivy-adapter-photon:v2.7.2
d632d8a25428: Loading layer [==================================================>] 91.15MB/91.15MB
cabcd0940bdc: Loading layer [==================================================>] 6.145MB/6.145MB
44ee4d8970ae: Loading layer [==================================================>] 1.249MB/1.249MB
2f6a0dd83f2a: Loading layer [==================================================>] 1.194MB/1.194MB
Loaded image: goharbor/harbor-portal:v2.7.2
1a216f8aa02a: Loading layer [==================================================>] 123.4MB/123.4MB
d089ab0054a9: Loading layer [==================================================>] 24.63MB/24.63MB
8f24b651395d: Loading layer [==================================================>] 5.12kB/5.12kB
f2d321b72ee5: Loading layer [==================================================>] 6.144kB/6.144kB
acee91b49dbe: Loading layer [==================================================>] 3.072kB/3.072kB
73f0a48672cf: Loading layer [==================================================>] 2.048kB/2.048kB
d1137d179e82: Loading layer [==================================================>] 2.56kB/2.56kB
93f0cd1915db: Loading layer [==================================================>] 2.56kB/2.56kB
9c825e10712c: Loading layer [==================================================>] 2.56kB/2.56kB
4cb9928e2724: Loading layer [==================================================>] 9.728kB/9.728kB
Loaded image: goharbor/harbor-db:v2.7.2
bef216058819: Loading layer [==================================================>] 5.767MB/5.767MB
8f27a70b8dba: Loading layer [==================================================>] 4.096kB/4.096kB
6b2d3322e8cd: Loading layer [==================================================>] 17.42MB/17.42MB
4bdfc014a9cd: Loading layer [==================================================>] 3.072kB/3.072kB
dc54a26bde1b: Loading layer [==================================================>] 30.78MB/30.78MB
f22d45960368: Loading layer [==================================================>] 48.99MB/48.99MB
Loaded image: goharbor/harbor-registryctl:v2.7.2
dfef2543aa70: Loading layer [==================================================>] 5.762MB/5.762MB
a68585f608e3: Loading layer [==================================================>] 8.999MB/8.999MB
295d31910dd4: Loading layer [==================================================>] 14.47MB/14.47MB
efd5b1579023: Loading layer [==================================================>] 29.29MB/29.29MB
7dfd2e3fc59e: Loading layer [==================================================>] 22.02kB/22.02kB
faa41d246ac8: Loading layer [==================================================>] 14.47MB/14.47MB
Loaded image: goharbor/notary-signer-photon:v2.7.2
17b21070628b: Loading layer [==================================================>] 5.767MB/5.767MB
65500e78d7c9: Loading layer [==================================================>] 91.76MB/91.76MB
42ee762ff7a8: Loading layer [==================================================>] 3.072kB/3.072kB
26fcbd0bc385: Loading layer [==================================================>] 4.096kB/4.096kB
dce96c29de1b: Loading layer [==================================================>] 92.56MB/92.56MB
Loaded image: goharbor/chartmuseum-photon:v2.7.2
5853ff7207cd: Loading layer [==================================================>] 44.11MB/44.11MB
93590529a39f: Loading layer [==================================================>] 65.93MB/65.93MB
45c0712d114a: Loading layer [==================================================>] 26.14MB/26.14MB
27d6fd7e5535: Loading layer [==================================================>] 65.54kB/65.54kB
b0c1525b1461: Loading layer [==================================================>] 2.56kB/2.56kB
b81d770e8744: Loading layer [==================================================>] 1.536kB/1.536kB
12bbb36d555f: Loading layer [==================================================>] 12.29kB/12.29kB
7a733d55d815: Loading layer [==================================================>] 2.621MB/2.621MB
e4007be64a14: Loading layer [==================================================>] 407kB/407kB
Loaded image: goharbor/prepare:v2.7.2
5bdb50147fe3: Loading layer [==================================================>] 8.909MB/8.909MB
7c7583a1eef8: Loading layer [==================================================>] 3.584kB/3.584kB
f5483be14faa: Loading layer [==================================================>] 2.56kB/2.56kB
9b67b6258fdf: Loading layer [==================================================>] 106.5MB/106.5MB
374df1d91d24: Loading layer [==================================================>] 107.3MB/107.3MB
Loaded image: goharbor/harbor-jobservice:v2.7.2
ec911fc21120: Loading layer [==================================================>] 91.15MB/91.15MB
Loaded image: goharbor/nginx-photon:v2.7.2
631cf08f9ff0: Loading layer [==================================================>] 5.767MB/5.767MB
db4216090ca5: Loading layer [==================================================>] 4.096kB/4.096kB
1f1103a3353e: Loading layer [==================================================>] 3.072kB/3.072kB
5e28d0ce371b: Loading layer [==================================================>] 17.42MB/17.42MB
bbbdbc284648: Loading layer [==================================================>] 18.21MB/18.21MB
Loaded image: goharbor/registry-photon:v2.7.2
3dc8df9174d5: Loading layer [==================================================>] 99.07MB/99.07MB
38e93b103e4f: Loading layer [==================================================>] 3.584kB/3.584kB
74b98ab194ce: Loading layer [==================================================>] 3.072kB/3.072kB
c203b688a2be: Loading layer [==================================================>] 2.56kB/2.56kB
525a15ff6933: Loading layer [==================================================>] 3.072kB/3.072kB
ea4e850eadfa: Loading layer [==================================================>] 3.584kB/3.584kB
5c345ac6af33: Loading layer [==================================================>] 20.48kB/20.48kB
Loaded image: goharbor/harbor-log:v2.7.2
1c464948f4c8: Loading layer [==================================================>] 91.99MB/91.99MB
e23b5317ef75: Loading layer [==================================================>] 3.072kB/3.072kB
ad8e1bb2e672: Loading layer [==================================================>] 59.9kB/59.9kB
2eade6174326: Loading layer [==================================================>] 61.95kB/61.95kB
Loaded image: goharbor/redis-photon:v2.7.2
dc782aa72031: Loading layer [==================================================>] 5.762MB/5.762MB
aead20724337: Loading layer [==================================================>] 8.999MB/8.999MB
22b6f665e30b: Loading layer [==================================================>] 15.88MB/15.88MB
4ded3a6c4ce0: Loading layer [==================================================>] 29.29MB/29.29MB
258a7b5fb17f: Loading layer [==================================================>] 22.02kB/22.02kB
be68b1b440c0: Loading layer [==================================================>] 15.88MB/15.88MB
Loaded image: goharbor/notary-server-photon:v2.7.2
[Step 3]: preparing environment ...
[Step 4]: preparing harbor configs ...
prepare base dir is set to /opt/harbor/harbor
Generated configuration file: /config/portal/nginx.conf
Generated configuration file: /config/log/logrotate.conf
Generated configuration file: /config/log/rsyslog_docker.conf
Generated configuration file: /config/nginx/nginx.conf
Generated configuration file: /config/core/env
Generated configuration file: /config/core/app.conf
Generated configuration file: /config/registry/config.yml
Generated configuration file: /config/registryctl/env
Generated configuration file: /config/registryctl/config.yml
Generated configuration file: /config/db/env
Generated configuration file: /config/jobservice/env
Generated configuration file: /config/jobservice/config.yml
Generated and saved secret to file: /data/secret/keys/secretkey
Successfully called func: create_root_cert
Generated configuration file: /compose_location/docker-compose.yml
Clean up the input dir
Note: stopping existing Harbor instance ...
[Step 5]: starting Harbor ...
[+] Running 10/10
✔ Network harbor_harbor Created 0.1s
✔ Container harbor-log Started 0.7s
✔ Container redis Started 1.2s
✔ Container harbor-db Started 1.4s
✔ Container registry Started 1.5s
✔ Container registryctl Started 1.5s
✔ Container harbor-portal Started 1.5s
✔ Container harbor-core Started 1.8s
✔ Container harbor-jobservice Started 2.4s
✔ Container nginx Started 2.4s
✔ ----Harbor has been installed and started successfully.----

7.3.向docker主机上添加harbor证书
转换harbor01.k8s.local.crt为harbor01.k8s.local.cert,供Docker使用;Docker守护程序将.crt文件解释为CA证书,并将.cert文件解释为客户端证书
在harbor01上,进行证书转换
cd /opt/harbor/harbor/certs/
openssl x509 -inform PEM -in harbor01.k8s.local.crt -out harbor01.k8s.local.cert
在master01上,直接登录harbor01,会提示证书问题的报错
[root@localhost ansible]# docker login https://harbor01.k8s.local -uadmin
Password:
Error response from daemon: Get "https://harbor01.k8s.local/v2/": x509: certificate signed by unknown authority
将harbor01上的服务器证书、密钥和CA文件复制到/etc/docker/certs.d/harbor01.k8s.local/目录下
ansible all -m file -a 'path=/etc/docker/certs.d/harbor01.k8s.local state=directory'
scp harbor01:/opt/harbor/harbor/certs/harbor01.k8s.local.cert /etc/docker/certs.d/harbor01.k8s.local/
scp harbor01:/opt/harbor/harbor/certs/harbor01.k8s.local.key /etc/docker/certs.d/harbor01.k8s.local/
scp harbor01:/opt/harbor/harbor/certs/ca.crt /etc/docker/certs.d/harbor01.k8s.local/
将harbor的证书复制到master01上,然后分发至所有其他节点上
ansible all -m template -a 'src=/etc/docker/certs.d/harbor01.k8s.local/harbor01.k8s.local.cert dest=/etc/docker/certs.d/harbor01.k8s.local/'
ansible all -m template -a 'src=/etc/docker/certs.d/harbor01.k8s.local/harbor01.k8s.local.key dest=/etc/docker/certs.d/harbor01.k8s.local/'
ansible all -m template -a 'src=/etc/docker/certs.d/harbor01.k8s.local/ca.crt dest=/etc/docker/certs.d/harbor01.k8s.local/'
ansible all -m systemd -a 'daemon_reload=yes'
ansible all -m service -a 'name=docker state=restarted'
重启docker后,需要重新启动harbor
cd /opt/harbor/harbor
./install.sh
登录到私有仓库上,显示“Login Succeeded”表示成功
[root@master01 ansible]# docker login https://harbor01.k8s.local -uadmin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
7.4.创建项目
访问https://192.168.111.20,用户名admin,密码lnyd@LNsy115

创建项目kubernetes,用于存放kubernetes集群组件的镜像

第八章 K8s环境安装
8.1.准备安装文件
在外网服务器上,配置kubernetes的yum源
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
下载相关安装包及依赖包
yum clean all
yum makecache fast
mkdir /opt/k8s
cd /opt/k8s/
yumdownloader --resolve kubelet-1.23.5 kubeadm-1.23.5 kubectl-1.23.5
8.2.制作repo文件
将下载好的rpm文件上传至master01的/opt/kubernetes下,并创建repo的镜像源
cp -r /opt/kubernetes/ /var/www/html/
createrepo /var/www/html/kubernetes/
为所有节点创建repo文件
ansible all -m yum_repository -a 'name="kubernetes" description="kubernetes" baseurl="http://master01.k8s.local/kubernetes" enabled=yes gpgcheck=no'
ansible all -m shell -a 'yum clean all'
ansible all -m shell -a 'yum update -y'
8.3.安装k8s环境
通过ansible的yum模块安装kubelet、kubeadm和kubectl
ansible master,worker -m yum -a 'name=kubelet,kubeadm,kubectl state=present'
查看版本
[root@master01 ansible]# kubelet --version
Kubernetes v1.23.5
[root@master01 ansible]# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.5", GitCommit:"c285e781331a3785a7f436042c65c5641ce8a9e9", GitTreeState:"clean", BuildDate:"2022-03-16T15:57:37Z", GoVersion:"go1.17.8", Compiler:"gc", Platform:"linux/amd64"}
[root@master01 ansible]# kubectl version
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.5", GitCommit:"c285e781331a3785a7f436042c65c5641ce8a9e9", GitTreeState:"clean", BuildDate:"2022-03-16T15:58:47Z", GoVersion:"go1.17.8", Compiler:"gc", Platform:"linux/amd64"}
The connection to the server localhost:8080 was refused - did you specify the right host or port?
第九章 K8s集群构建
9.1.集群初始化
集群初始化是首先形成一个master的集群,因此相关操作仅在master01上完成即可,当集群初始化完成后,将其他master和worker节点相继加入集群。
9.1.1.APIServer高可用配置
9.1.1.1.安装
在master02、master03上安装keepalived和HAProxy服务
yum install -y keepalived haproxy
9.1.1.2.配置HAProxy
备份配置文件
cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak20230508
修改配置文件
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend tcp_8443
bind *:8443
mode tcp
stats uri /haproxy?stats
default_backend tcp_8443
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend tcp_8443
mode tcp
balance roundrobin
server server1 master01.k8s.local:6443 check
server server2 master02.k8s.local:6443 check
server server3 master03.k8s.local:6443 check
将修改的配置文件分发至master节点上并启动HAProxy服务
systemctl enable --now haproxy
systemctl status haproxy
9.1.1.3.配置KeepAlived
备份配置文件
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak20230508
master02上修改配置文件
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
router_id master02.k8s.local
script_user root
enable_script_security
}
vrrp_script chk_ha_port {
script "/etc/keepalived/chk_ha.sh"
interval 2
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER
interface ens192
virtual_router_id 128
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress {
192.168.111.50
}
track_script {
chk_ha_port
}
}
master03上修改配置文件
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
router_id master03.k8s.local
script_user root
enable_script_security
}
vrrp_script chk_ha_port {
script "/etc/keepalived/chk_ha.sh"
interval 2
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BACKUP
interface ens192
virtual_router_id 128
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress {
192.168.111.50
}
track_script {
chk_ha_port
}
}
在master02和mater03上创建监测脚本,/etc/keepalived/chk_ha.sh
#!/bin/bash
counter=$(ps -C haproxy --no-heading | wc -l)
if [ "${counter}" = "0" ]; then
systemctl start haproxy
sleep 1
counter=$(ps -C haproxy --no-heading | wc -l)
if [ "${counter}" = "0" ]; then
systemctl stop keepalived
fi
fi
启动keepalived服务
systemctl enable --now keepalived
systemctl status keepalived
在master02和master03上分别查看ens192端口上的IP是否增加192.168.111.50
[root@master02 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:10:9a:be brd ff:ff:ff:ff:ff:ff
inet 192.168.111.2/24 brd 192.168.111.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 192.168.111.50/32 scope global ens192
valid_lft forever preferred_lft forever
inet6 fe80::c9dc:d704:71fd:c8bf/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:dc:e5:f5:cd brd ff:ff:ff:ff:ff:ff
inet 1.1.1.1/24 brd 1.1.1.255 scope global docker0
valid_lft forever preferred_lft forever
[root@master03 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:3b:9e:f4 brd ff:ff:ff:ff:ff:ff
inet 192.168.111.3/24 brd 192.168.111.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet6 fe80::605:23f1:e01c:b74/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:0d:24:ee:3c brd ff:ff:ff:ff:ff:ff
inet 1.1.1.1/24 brd 1.1.1.255 scope global docker0
valid_lft forever preferred_lft forever
9.1.2.harbor上安装k8s组件镜像
在harbor01上,查看k8s所需镜像
[root@master01 ~]# kubeadm config images list
W0508 16:50:52.428239 4391 common.go:167] WARNING: could not obtain a bind address for the API Server: no default routes found in "/proc/net/route" or "/proc/net/ipv6_route"; using: 0.0.0.0
W0508 16:50:52.440732 4391 version.go:103] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get "https://dl.k8s.io/release/stable-1.txt": dial tcp: lookup dl.k8s.io on [::1]:53: read udp [::1]:49538->[::1]:53: read: connection refused
W0508 16:50:52.440763 4391 version.go:104] falling back to the local client version: v1.23.5
k8s.gcr.io/kube-apiserver:v1.23.5
k8s.gcr.io/kube-controller-manager:v1.23.5
k8s.gcr.io/kube-scheduler:v1.23.5
k8s.gcr.io/kube-proxy:v1.23.5
k8s.gcr.io/pause:3.6
k8s.gcr.io/etcd:3.5.1-0
k8s.gcr.io/coredns/coredns:v1.8.6
在外网服务器上,拉群对应的组件镜像
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.5
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.5
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.5
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.5
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.1-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6
将拉取的镜像保存到外网服务器本地磁盘上
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.5 > /opt/images/kube-apiserver:v1.23.5.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.5 > /opt/images/kube-proxy:v1.23.5.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.5 > /opt/images/kube-controller-manager:v1.23.5.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.5 > /opt/images/kube-scheduler:v1.23.5.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.1-0 > /opt/images/etcd:3.5.1-0.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6 > /opt/images/coredns:v1.8.6.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6 > /opt/images/pause:3.6.tar
在harbor01上,创建存储组件镜像的目录
mkdir /opt/kube-images
上传并解压k8s的镜像文件,并将镜像加载到本地
cd /opt/kube-images
docker load -i coredns_v1.8.6.tar
docker load -i etcd_3.5.1-0.tar
docker load -i kube-apiserver_v1.23.5.tar
docker load -i kube-controller-manager_v1.23.5.tar
docker load -i kube-proxy_v1.23.5.tar
docker load -i kube-scheduler_v1.23.5.tar
docker load -i pause_3.6.tar
重新tag
[root@harbor01 ~]# docker images | grep "registry.cn-hangzhou.aliyuncs.com"
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver v1.23.5 3fc1d62d6587 13 months ago 135MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy v1.23.5 3c53fa8541f9 13 months ago 112MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler v1.23.5 884d49d6d8c9 13 months ago 53.5MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager v1.23.5 b0c9e5e4dbb1 13 months ago 125MB
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd 3.5.1-0 25f8c7f3da61 18 months ago 293MB
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns v1.8.6 a4ca41631cc7 19 months ago 46.8MB
registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.6 6270bb605e12 20 months ago 683kB
[root@harbor01 ~]# docker tag 3fc1d62d6587 harbor01.k8s.local/kubernetes/kube-apiserver:v1.23.5
[root@harbor01 ~]# docker tag 3c53fa8541f9 harbor01.k8s.local/kubernetes/kube-proxy:v1.23.5
[root@harbor01 ~]# docker tag 884d49d6d8c9 harbor01.k8s.local/kubernetes/kube-scheduler:v1.23.5
[root@harbor01 ~]# docker tag b0c9e5e4dbb1 harbor01.k8s.local/kubernetes/kube-controller-manager:v1.23.5
[root@harbor01 ~]# docker tag 25f8c7f3da61 harbor01.k8s.local/kubernetes/etcd:3.5.1-0
[root@harbor01 ~]# docker tag a4ca41631cc7 harbor01.k8s.local/kubernetes/coredns:v1.8.6
[root@harbor01 ~]# docker tag 6270bb605e12 harbor01.k8s.local/kubernetes/pause:3.6
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.5
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.5
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.5
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.5
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.5
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.5
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.5
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.5
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.1-0
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.1-0
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6
登录到harbor后,并推送镜像到harbor的kubernetes项目中
docker login https://harbor01.k8s.local -uadmin
生成推送指令
[root@harbor01 ~]# docker images | awk '{print "docker push "$1":"$2}' | grep "harbor01.k8s.local"
docker push harbor01.k8s.local/kubernetes/kube-apiserver:v1.23.5
docker push harbor01.k8s.local/kubernetes/kube-proxy:v1.23.5
docker push harbor01.k8s.local/kubernetes/kube-controller-manager:v1.23.5
docker push harbor01.k8s.local/kubernetes/kube-scheduler:v1.23.5
docker push harbor01.k8s.local/kubernetes/etcd:3.5.1-0
docker push harbor01.k8s.local/kubernetes/coredns:v1.8.6
docker push harbor01.k8s.local/kubernetes/pause:3.6
执行推送指令
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/kube-apiserver:v1.23.5
The push refers to repository [harbor01.k8s.local/kubernetes/kube-apiserver]
50098fdfecae: Pushed
83e216f0eb98: Pushed
5b1fa8e3e100: Pushed
v1.23.5: digest: sha256:d4fdffee6b4e70a6e3d5e0eeb42fce4e0f922a5cedf7e9a85da8d00bc02581c4 size: 949
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/kube-proxy:v1.23.5
The push refers to repository [harbor01.k8s.local/kubernetes/kube-proxy]
618b3e11ccba: Pushed
2b8347a02bc5: Pushed
194a408e97d8: Pushed
v1.23.5: digest: sha256:a1dc61984a02ec82b43dac2141688ac67c74526948702b0bc3fcdf1ca0adfcf6 size: 950
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/kube-controller-manager:v1.23.5
The push refers to repository [harbor01.k8s.local/kubernetes/kube-controller-manager]
a70573edad24: Pushed
83e216f0eb98: Mounted from kubernetes/kube-apiserver
5b1fa8e3e100: Mounted from kubernetes/kube-apiserver
v1.23.5: digest: sha256:0dfc4f1512064e909fa8474ac08c49a5699546b03a7c3e87166d7b77eed640b0 size: 949
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/kube-scheduler:v1.23.5
The push refers to repository [harbor01.k8s.local/kubernetes/kube-scheduler]
46576c5a6a97: Pushed
83e216f0eb98: Mounted from kubernetes/kube-controller-manager
5b1fa8e3e100: Mounted from kubernetes/kube-controller-manager
v1.23.5: digest: sha256:d9fc2cccd6a4b56637f01b7e967a965fa01acdf50327923addc4c801c51d3e5a size: 949
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/etcd:3.5.1-0
The push refers to repository [harbor01.k8s.local/kubernetes/etcd]
62ae031121b1: Pushed
664dd6f2834b: Pushed
d80003ff5706: Pushed
b6e8c573c18d: Pushed
6d75f23be3dd: Pushed
3.5.1-0: digest: sha256:05c1a3be66823dcaca55ebe17c3c9a60de7ceb948047da3e95308348325ddd5a size: 1372
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/coredns:v1.8.6
The push refers to repository [harbor01.k8s.local/kubernetes/coredns]
80e4a2390030: Pushed
256bc5c338a6: Pushed
v1.8.6: digest: sha256:8916c89e1538ea3941b58847e448a2c6d940c01b8e716b20423d2d8b189d3972 size: 739
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/pause:3.6
The push refers to repository [harbor01.k8s.local/kubernetes/pause]
1021ef88c797: Pushed
3.6: digest: sha256:74bf6fc6be13c4ec53a86a5acf9fdbc6787b176db0693659ad6ac89f115e182c size: 526
登录harbor查看镜像推送结果

9.1.3.kubeadm初始化
在master01上生成配置文件,并根据实际情况进行修改
kubeadm config print init-defaults > /root/init-defaults.conf
对于生成的配置文件,需要修改以下内容:
A.token:连接master使用的token,这里不用修改,后面会生成永久的token;
B.advertiseAddress:连接apiserver的地址,即master的local api地址,只能写IP;
C.name:node节点的名称,如果使用主机名,需要确保master节点可以解析该主机名;
D.controlPlaneEndpoint:master集群对外暴露的IP及端口,10.97.237.239:6443;
E.imageRepository:修改为harbor的kubernetes项目,harbor01.k8s.local/kubernetes;
F.kubernetesVersion:修改为与docker images中镜像的版本一致
G.podSubnet:新增pod地址段,172.16.0.0/24;
H.serviceSubnet:修改service地址段,172.16.1.0/24
文件完整内容如下:
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.111.1
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
imagePullPolicy: IfNotPresent
name: master01.k8s.local
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.111.50:8443"
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: harbor01.k8s.local/kubernetes
kind: ClusterConfiguration
kubernetesVersion: 1.23.5
networking:
dnsDomain: cluster.local
podSubnet: 172.16.0.0/24
serviceSubnet: 172.16.1.0/24
scheduler: {}
使用修改后的配置文件进行初始化
[root@master01 ~]# kubeadm init --config /root/init-defaults.conf
[init] Using Kubernetes version: v1.23.5
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 23.0.5. Latest validated version: 20.10
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master01.k8s.local] and IPs [172.16.1.1 192.168.111.1 192.168.111.50]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master01.k8s.local] and IPs [192.168.111.1 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master01.k8s.local] and IPs [192.168.111.1 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 7.021934 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.23" in namespace kube-system with the configuration for the kubelets in the cluster
NOTE: The "kubelet-config-1.23" naming of the kubelet ConfigMap is deprecated. Once the UnversionedKubeletConfigMap feature gate graduates to Beta the default name will become just "kubelet-config". Kubeadm upgrade will handle this transition transparently.
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master01.k8s.local as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master01.k8s.local as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: abcdef.0123456789abcdef
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 192.168.111.50:8443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.111.50:8443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc

创建相关文件夹
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
9.1.4.安装网络插件
此时查看coredns的状态异常,需要安装网络插件calico
[root@master01 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-767c6f8554-kk8hq 0/1 Pending 0 111s
kube-system coredns-767c6f8554-vbzxg 0/1 Pending 0 111s
kube-system etcd-master01.k8s.local 1/1 Running 0 2m4s
kube-system kube-apiserver-master01.k8s.local 1/1 Running 0 2m4s
kube-system kube-controller-manager-master01.k8s.local 1/1 Running 0 2m4s
kube-system kube-proxy-kp4sg 1/1 Running 0 112s
kube-system kube-scheduler-master01.k8s.local 1/1 Running 0 2m4s
查看/var/log/message,存在关于网络的报错,说明需要安装网络插件
May 7 14:23:39 master01 kubelet: E0507 14:23:39.472622 26251 kubelet.go:2347] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized"
在外网服务器上,通过https://docs.tigera.io/下载calico.yaml文件,查找对应的镜像地址
wget https://docs.projectcalico.org/v3.23/manifests/calico.yaml
下载对应calico对应的3个镜像,并保存到本地(docker.io下载太慢,使用dockerproxy镜像加速)
docker pull dockerproxy.com/calico/cni:v3.23.5
docker pull dockerproxy.com/calico/kube-controllers:v3.23.5
docker pull dockerproxy.com/calico/node:v3.23.5
docker save dockerproxy.com/calico/cni:v3.23.5 > /opt/calico/cni:v3.23.5.tar
docker save dockerproxy.com/calico/kube-controllers:v3.23.5 > /opt/calico/kube-controllers:v3.23.5.tar
docker save dockerproxy.com/calico/node:v3.23.5 > /opt/calico/node:v3.23.5.tar
在harbor01上,将calico镜像上传至/opt/calico/
mkdir /opt/calico
docker load -i /opt/calico/cni_v3.23.5.tar
docker load -i /opt/calico/kube-controllers_v3.23.5.tar
docker load -i /opt/calico/node_v3.23.5.tar
新建calico项目

重新tag并推送到私有harbor中
[root@harbor01 ~]# docker images | grep calico
dockerproxy.com/calico/kube-controllers v3.23.5 ea5536b1fa4a 6 months ago 127MB
dockerproxy.com/calico/cni v3.23.5 1c979d623de9 6 months ago 254MB
dockerproxy.com/calico/node v3.23.5 b6e6ee0788f2 6 months ago 207MB
[root@harbor01 ~]# docker tag ea5536b1fa4a harbor01.k8s.local/calico/kube-controllers:v3.23.5
[root@harbor01 ~]# docker tag 1c979d623de9 harbor01.k8s.local/calico/cni:v3.23.5
[root@harbor01 ~]# docker tag b6e6ee0788f2 harbor01.k8s.local/calico/node:v3.23.5
[root@harbor01 ~]# docker rmi dockerproxy.com/calico/kube-controllers:v3.23.5
Untagged: dockerproxy.com/calico/kube-controllers:v3.23.5
[root@harbor01 ~]# docker rmi dockerproxy.com/calico/cni:v3.23.5
Untagged: dockerproxy.com/calico/cni:v3.23.5
[root@harbor01 ~]# docker rmi dockerproxy.com/calico/node:v3.23.5
Untagged: dockerproxy.com/calico/node:v3.23.5
[root@harbor01 ~]# docker images | grep calico
harbor01.k8s.local/calico/kube-controllers v3.23.5 ea5536b1fa4a 6 months ago 127MB
harbor01.k8s.local/calico/cni v3.23.5 1c979d623de9 6 months ago 254MB
harbor01.k8s.local/calico/node v3.23.5 b6e6ee0788f2 6 months ago 207MB
将calico镜像推送至harbor中
docker login https://harbor01.k8s.local -uadmin
docker push harbor01.k8s.local/calico/cni:v3.23.5
docker push harbor01.k8s.local/calico/kube-controllers:v3.23.5
docker push harbor01.k8s.local/calico/node:v3.23.5

将calico.yml文件上传至master01的/root/下,并做如下修改:
修改拉取镜像地址改为私有仓库harbor
[root@master01 ~]# cat calico.yaml | grep image
image: docker.io/calico/cni:v3.23.5
image: docker.io/calico/cni:v3.23.5
image: docker.io/calico/node:v3.23.5
image: docker.io/calico/node:v3.23.5
image: docker.io/calico/kube-controllers:v3.23.5
[root@master01 ~]# sed -i 's/docker.io\/calico/harbor01.k8s.local\/calico/g' /root/calico.yaml
[root@master01 ~]# cat calico.yaml | grep image
image: harbor01.k8s.local/calico/cni:v3.23.5
image: harbor01.k8s.local/calico/cni:v3.23.5
image: harbor01.k8s.local/calico/node:v3.23.5
image: harbor01.k8s.local/calico/node:v3.23.5
image: harbor01.k8s.local/calico/kube-controllers:v3.23.5
calico中用环境变量CALICO_IPV4POOL_IPIP来标识是否开启IPinIP Mode. 如果该变量的值为Always那么就是开启IPIP,如果关闭需要设置为Never。
IPIP的calico-node启动后会拉起一个linux系统的tunnel虚拟网卡tunl0,并由二进制文件allocateip给它分配一个calico IPPool中的地址,log记录在本机的/var/log/calico/allocate-tunnel-addrs/目录下。tunl0是linux支持的隧道设备接口,当有这个接口时,出这个主机的IP包就会本封装成IPIP报文。
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Always"
# Enable or Disable VXLAN on the default IP pool.
- name: CALICO_IPV4POOL_VXLAN
value: "Never"
# Enable or Disable VXLAN on the default IPv6 IP pool.
- name: CALICO_IPV6POOL_VXLAN
value: "Never"
去掉CALICO_IPV4POOL_CIDR部分的注释,并将修改pod地址段
- name: CALICO_IPV4POOL_CIDR
value: "172.16.0.0/24"
安装calico插件前,首先检查master01的本机IP
[root@master01 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:d4:d0:64 brd ff:ff:ff:ff:ff:ff
inet 192.168.111.1/24 brd 192.168.111.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet6 fe80::e5b5:69ee:10cc:8f0d/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:bd:49:a1:7f brd ff:ff:ff:ff:ff:ff
inet 1.1.1.1/24 brd 1.1.1.255 scope global docker0
valid_lft forever preferred_lft forever
安装插件
kubectl apply -f /root/calico.yaml
kubectl get node -n kube-system
再次检查coredns的状态,变为正常
[root@master01 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6b86d5b6c7-65f4x 1/1 Running 0 118m
kube-system calico-node-pr6x6 1/1 Running 0 10m
kube-system coredns-767c6f8554-kk8hq 1/1 Running 0 3h35m
kube-system coredns-767c6f8554-vbzxg 1/1 Running 0 3h35m
kube-system etcd-master01.k8s.local 1/1 Running 0 3h36m
kube-system kube-apiserver-master01.k8s.local 1/1 Running 0 3h36m
kube-system kube-controller-manager-master01.k8s.local 1/1 Running 1 (83m ago) 3h36m
kube-system kube-proxy-kp4sg 1/1 Running 0 3h35m
kube-system kube-scheduler-master01.k8s.local 1/1 Running 1 (83m ago) 3h36m
再次检查master01的本机IP,增加了tunnel等网卡
[root@master01 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:d4:d0:64 brd ff:ff:ff:ff:ff:ff
inet 192.168.111.1/24 brd 192.168.111.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet6 fe80::e5b5:69ee:10cc:8f0d/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:bd:49:a1:7f brd ff:ff:ff:ff:ff:ff
inet 1.1.1.1/24 brd 1.1.1.255 scope global docker0
valid_lft forever preferred_lft forever
4: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 172.16.0.64/32 scope global tunl0
valid_lft forever preferred_lft forever
5: cali9ff1213e5d4@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
6: cali51f93af7f47@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
7: calid894eb53108@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
9.1.5.生成永久token
kubeadm init生成的token为临时,有效期默认为900秒,便于后续扩容node节点,需要生成永久不失效的token
[root@master01 ~]# kubeadm token create --ttl 0
vmz0fo.e1bqw0mj5bszm9bd
[root@master01 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
abcdef.0123456789abcdef 22h 2023-05-09T22:44:56Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
vmz0fo.e1bqw0mj5bszm9bd <forever> <never> authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
获取ca证书sha256编码hash值
[root@master01 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc
生成加入集群指令
kubeadm join 192.168.111.50:8443 --token vmz0fo.e1bqw0mj5bszm9bd \ --discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc
9.2.Master节点加入集群
9.2.1.将master01证书文件复制到master02、master03
在master01上,给master02和master03上创建相关目录
ansible 192.168.111.2,192.168.111.3 -m file -a 'path=/etc/kubernetes/pki/etcd/ state=directory'
将相关证书文件等复制到master02和master03上
scp /etc/kubernetes/pki/ca.* root@master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.* root@master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.* root@master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.* root@master02:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/admin.conf root@master02:/etc/kubernetes/
scp /etc/kubernetes/pki/ca.* root@master03:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.* root@master03:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.* root@master03:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.* root@master03:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/admin.conf root@master03:/etc/kubernetes/
9.2.2.master02、master03加入集群
其他master节点加入集群时,一定要添加–experimental-control-plane参数,否则会被认为是普通node节点。
kubeadm join 192.168.111.50:8443 --token vmz0fo.e1bqw0mj5bszm9bd \
--discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc \
--control-plane
执行结果如下:
[root@master02 ~]# kubeadm join 192.168.111.50:8443 --token vmz0fo.e1bqw0mj5bszm9bd \
> --discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc \
> --control-plane
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 23.0.5. Latest validated version: 20.10
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master02] and IPs [172.16.1.1 192.168.111.2 192.168.111.50]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master02] and IPs [192.168.111.2 127.0.0.1 ::1]
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master02] and IPs [192.168.111.2 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/admin.conf"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Creating static Pod manifest for "etcd"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
The 'update-status' phase is deprecated and will be removed in a future release. Currently it performs no operation
[mark-control-plane] Marking the node master02 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master02 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
创建相关文件夹
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
查看加入集群的状态
[root@master01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master01.k8s.local Ready control-plane,master 138m v1.23.5
master02 Ready control-plane,master 6m13s v1.23.5
master03 Ready control-plane,master 77s v1.23.5
9.3.Node节点加入集群
node在完成基础配置后,使用kubeadm join加入集群
kubeadm join 192.168.111.50:8443 --token vmz0fo.e1bqw0mj5bszm9bd \
--discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc
执行结果如下:
[root@worker01 ~]# kubeadm join 192.168.111.50:8443 --token vmz0fo.e1bqw0mj5bszm9bd \
> --discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 23.0.5. Latest validated version: 20.10
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
查看加入集群的状态
[root@master01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master01.k8s.local Ready control-plane,master 3h40m v1.23.5
master02 Ready control-plane,master 88m v1.23.5
master03 Ready control-plane,master 83m v1.23.5
worker01 Ready <none> 79m v1.23.5
worker02 Ready <none> 105s v1.23.5
9.4.常见报错
9.4.1.报错:初始化报错container runtime is not running
在进行kubeadm时报错
[root@master01 ~]# kubeadm init --config /root/init-defaults.conf
[init] Using Kubernetes version: v1.27.0
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="2023-05-04T21:06:19+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
解决:执行如下指令后重新初始化
[root@master01 ~]# rm -f /etc/containerd/config.toml
[root@master01 ~]# systemctl restart containerd
9.4.2.报错:calico-node状态为Init:CrashLoopBackOff
在启动calico后,查看pod状态,calico-pod为Init:CrashLoopBackOff,并不断尝试重启
[root@master01 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6b86d5b6c7-27n5d 0/1 Pending 0 14s
kube-system calico-node-wtcjv 0/1 Init:CrashLoopBackOff 1 (4s ago) 14s
kube-system coredns-767c6f8554-kk8hq 0/1 Pending 0 81m
kube-system coredns-767c6f8554-vbzxg 0/1 Pending 0 81m
kube-system etcd-master01.k8s.local 1/1 Running 0 81m
kube-system kube-apiserver-master01.k8s.local 1/1 Running 0 81m
kube-system kube-controller-manager-master01.k8s.local 1/1 Running 0 81m
kube-system kube-proxy-kp4sg 1/1 Running 0 81m
kube-system kube-scheduler-master01.k8s.local 1/1 Running 0 81m
因为pod未完成初始化,因此无法查看pod日志
[root@master01 ~]# kubectl logs calico-node-wtcjv -n kube-system
Error from server (BadRequest): container "calico-node" in pod "calico-node-wtcjv" is waiting to start: PodInitializing
需要使用kubectl describe查看pod的信息包括哪些容器,然后逐个容器查看
kubectl describe pod calico-node-wtcjv -n kube-system
从关于容器的信息中可以看出,calico-node-wtcjv中共需要创建3个容器,分别为upgrade-ipam、install-cni和mount-bpffs
Init Containers:
upgrade-ipam:
Container ID: docker://c3d8bcce819aa695433def817c05aeb3f1adb0262531292677621fcb66414aaa
Image: harbor01.k8s.local/calico/cni:v3.23.5
Image ID: docker-pullable://harbor01.k8s.local/calico/cni@sha256:9c5055a2b5bc0237ab160aee058135ca9f2a8f3c3eee313747a02edcec482f29
Port: <none>
Host Port: <none>
Command:
/opt/cni/bin/calico-ipam
-upgrade
State: Terminated
Reason: Completed
Exit Code: 0
Started: Tue, 09 May 2023 08:09:35 +0800
Finished: Tue, 09 May 2023 08:09:35 +0800
Ready: True
Restart Count: 0
Environment Variables from:
kubernetes-services-endpoint ConfigMap Optional: true
Environment:
KUBERNETES_NODE_NAME: (v1:spec.nodeName)
CALICO_NETWORKING_BACKEND: <set to the key 'calico_backend' of config map 'calico-config'> Optional: false
Mounts:
/host/opt/cni/bin from cni-bin-dir (rw)
/var/lib/cni/networks from host-local-net-dir (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dgr48 (ro)
install-cni:
Container ID: docker://39679af86542703bf1824d7a9e94e6347a26a62c9b11893ec75713bdce3a2317
Image: harbor01.k8s.local/calico/cni:v3.23.5
Image ID: docker-pullable://harbor01.k8s.local/calico/cni@sha256:9c5055a2b5bc0237ab160aee058135ca9f2a8f3c3eee313747a02edcec482f29
Port: <none>
Host Port: <none>
Command:
/opt/cni/bin/install
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
Started: Tue, 09 May 2023 08:15:09 +0800
Finished: Tue, 09 May 2023 08:15:10 +0800
Ready: False
Restart Count: 6
Environment Variables from:
kubernetes-services-endpoint ConfigMap Optional: true
Environment:
CNI_CONF_NAME: 10-calico.conflist
CNI_NETWORK_CONFIG: <set to the key 'cni_network_config' of config map 'calico-config'> Optional: false
KUBERNETES_NODE_NAME: (v1:spec.nodeName)
CNI_MTU: <set to the key 'veth_mtu' of config map 'calico-config'> Optional: false
SLEEP: false
Mounts:
/host/etc/cni/net.d from cni-net-dir (rw)
/host/opt/cni/bin from cni-bin-dir (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dgr48 (ro)
mount-bpffs:
Container ID:
Image: harbor01.k8s.local/calico/node:v3.23.5
Image ID:
Port: <none>
Host Port: <none>
Command:
calico-node
-init
-best-effort
State: Waiting
Reason: PodInitializing
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/nodeproc from nodeproc (ro)
/sys/fs from sys-fs (rw)
/var/run/calico from var-run-calico (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dgr48 (ro)
分别查看这3个容器的日志发现install-cni有报错
[root@master01 ~]# kubectl logs calico-node-wn2mc -n kube-system -c install-cni
time="2023-05-09T00:15:09Z" level=info msg="Running as a Kubernetes pod" source="install.go:140"
2023-05-09 00:15:09.958 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/bandwidth"
2023-05-09 00:15:09.958 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/bandwidth
2023-05-09 00:15:10.037 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/calico"
2023-05-09 00:15:10.037 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/calico
2023-05-09 00:15:10.104 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/calico-ipam"
2023-05-09 00:15:10.104 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/calico-ipam
2023-05-09 00:15:10.107 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/flannel"
2023-05-09 00:15:10.107 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/flannel
2023-05-09 00:15:10.110 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/host-local"
2023-05-09 00:15:10.110 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/host-local
2023-05-09 00:15:10.194 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/install"
2023-05-09 00:15:10.194 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/install
2023-05-09 00:15:10.200 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/loopback"
2023-05-09 00:15:10.200 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/loopback
2023-05-09 00:15:10.204 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/portmap"
2023-05-09 00:15:10.205 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/portmap
2023-05-09 00:15:10.209 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/tuning"
2023-05-09 00:15:10.209 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/tuning
2023-05-09 00:15:10.209 [INFO][1] cni-installer/<nil> <nil>: Wrote Calico CNI binaries to /host/opt/cni/bin
2023-05-09 00:15:10.238 [INFO][1] cni-installer/<nil> <nil>: CNI plugin version: v3.23.5
2023-05-09 00:15:10.238 [INFO][1] cni-installer/<nil> <nil>: /host/secondary-bin-dir is not writeable, skipping
W0509 00:15:10.238184 1 client_config.go:617] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
2023-05-09 00:15:10.239 [ERROR][1] cni-installer/<nil> <nil>: Unable to create token for CNI kubeconfig error=Post "https://172.16.1.1:443/api/v1/namespaces/kube-system/serviceaccounts/calico-node/token": dial tcp 172.16.1.1:443: connect: network is unreachable
2023-05-09 00:15:10.239 [FATAL][1] cni-installer/<nil> <nil>: Unable to create token for CNI kubeconfig error=Post "https://172.16.1.1:443/api/v1/namespaces/kube-system/serviceaccounts/calico-node/token": dial tcp 172.16.1.1:443: connect: network is unreachable
从日志报错中可以看出是网络不可达导致,网上查找资料确认为本地主机侧没有配置默认路由导致calico容器侧的ARP表异常显示incomplete。
[root@master01 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
1.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
192.168.111.0 0.0.0.0 255.255.255.0 U 100 0 0 ens192
[root@master01 ~]# route add -net 0.0.0.0/0 gw 192.168.111.1
[root@master01 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.111.1 0.0.0.0 UG 0 0 0 ens192
1.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
192.168.111.0 0.0.0.0 255.255.255.0 U 100 0 0 ens192
重新拉起calico-node后,状态正常
[root@master01 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6b86d5b6c7-65f4x 1/1 Running 0 66s
calico-node-qqpfj 0/1 Running 0 66s
coredns-767c6f8554-kk8hq 1/1 Running 0 98m
coredns-767c6f8554-vbzxg 1/1 Running 0 98m
etcd-master01.k8s.local 1/1 Running 0 98m
kube-apiserver-master01.k8s.local 1/1 Running 0 98m
kube-controller-manager-master01.k8s.local 1/1 Running 0 98m
kube-proxy-kp4sg 1/1 Running 0 98m
kube-scheduler-master01.k8s.local 1/1 Running 0 98m
9.4.3.报错:calico-node状态为CrashLoopBackOff
在启动calico后,查看pod状态,calico-pod为CrashLoopBackOff
[root@master01 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6b86d5b6c7-65f4x 1/1 Running 0 108m
calico-node-qqpfj 0/1 CrashLoopBackOff 33 (65s ago) 108m
coredns-767c6f8554-kk8hq 1/1 Running 0 3h25m
coredns-767c6f8554-vbzxg 1/1 Running 0 3h25m
etcd-master01.k8s.local 1/1 Running 0 3h25m
kube-apiserver-master01.k8s.local 1/1 Running 0 3h25m
kube-controller-manager-master01.k8s.local 1/1 Running 1 (73m ago) 3h25m
kube-proxy-kp4sg 1/1 Running 0 3h25m
kube-scheduler-master01.k8s.local 1/1 Running 1 (73m ago) 3h25m
查看日志
kubectl logs calico-node-pr6x6 -n kube-system
发现报错如下:
2023-05-09 02:09:17.561 [ERROR][84] felix/health.go 296: Health endpoint failed, trying to restart it... error=listen tcp: lookup localhost on [::1]:53: read udp [::1]:35661->[::1]:53: read: connection refused
bird: KRT: Received route 0.0.0.0/0 with strange next-hop 192.168.111.1
2023-05-09 02:09:18.563 [ERROR][84] felix/health.go 296: Health endpoint failed, trying to restart it... error=listen tcp: lookup localhost on [::1]:53: read udp [::1]:57748->[::1]:53: read: connection refused
2023-05-09 02:09:19.564 [ERROR][84] felix/health.go 296: Health endpoint failed, trying to restart it... error=listen tcp: lookup localhost on [::1]:53: read udp [::1]:43132->[::1]:53: read: connection refused
bird: KRT: Received route 0.0.0.0/0 with strange next-hop 192.168.111.1
2023-05-09 02:09:20.565 [ERROR][84] felix/health.go 296: Health endpoint failed, trying to restart it... error=listen tcp: lookup localhost on [::1]:53: read udp [::1]:53369->[::1]:53: read: connection refused
2023-05-09 02:09:21.567 [ERROR][84] felix/health.go 296: Health endpoint failed, trying to restart it... error=listen tcp: lookup localhost on [::1]:53: read udp [::1]:36117->[::1]:53: read: connection refused
确认原因为localhost未设置映射,需要在/etc/hosts中增加映射
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
第十章 容器回退
部署过程中,如遇问题可重新初始化k8s或彻底卸载k8s、docker重新部署。
10.1.node重新初始化
恢复主机状态
kubeadm reset -f
rm -rf /etc/kubernetes/*
rm -rf rm -rf $HOME/.kube/config
重启相关服务
systemctl daemon-reload
systemctl restart kubelet
systemctl restart docker
然后使用kubeadm join重新加入集群
10.2.master重新初始化
先恢复主机状态
kubeadm reset -f
删除之前生成的密钥等信息
rm -rf $HOME/.kube
然后再进行初始化
kubeadm init --config init-defaults.conf
10.3.卸载k8s
kubeadm reset -f
yum remove -y kubelet kubeadm kubectl
modprobe -r ipip
lsmod
rm -rf ~/.kube/
rm -rf /etc/kubernetes/
rm -rf /etc/systemd/system/kubelet.service.d
rm -rf /etc/systemd/system/kubelet.service
rm -rf /usr/bin/kube*
rm -rf /etc/cni
rm -rf /opt/cni
rm -rf /var/lib/etcd
rm -rf /var/etcd
ifconfig cni0 down
ip link delete cni0
ifconfig flannel.1 down
ip link delete flannel.1
rm -rf /var/lib/cni
rm -f /etc/cni/net.d/*
10.4.卸载docker
rpm -qa | grep docker
yum remove -y docker*
yum -y install bridge-utils
ifconfig docker0 down
brctl delbr docker0
rm -rf /var/lib/docker/*