论文导读 | 图流的分割和摘要
前 言
本次论文导读介绍有关图流的分割和摘要问题的3篇文章。第1篇是partition的,第2篇是summarization的。

首先介绍第一篇文章。
文章一:图分割在分布式系统中有广泛的应用
文章的问题定义是用划分边的方式来分割图。如图所示,把图(图流)中的边分割到p个集合中(p预先给定)。我们的目标是,在最小化顶点重复(最小化所有集合中顶点总数)的同时,最大化 load balance(最大化最小集合的边数)。
以往的工作分为offline和stream两类,offline的工作不支持很大的、无法完整存入内存的图,stream的工作的效果不好。因此,本文希望能结合二者,对于很大的图,用 offline 算法来提高 stream 算法的分割质量。
具体来说,以往一个常用的stream算法是HDRF[2]。它用partition state 存储已经处理完的边的分割信息,用这个信息帮助后续的图流 分割。HDRF的冷启动是一个很大的问题,即在处理图流的开头时,还没有足够的边来给后续分割提供信息,因此开头一段的边分割几乎是随机做的。
本文提出的方法是,在图流的开头,把一批 edge 读入内存,运行 offline 分割算法来提高初始状态下partition state信息少的时候的准确性,而不是在读入第一条边的时候立刻决定怎么分割。
文章用了修改后的NE[1]算法作为offline算法。修改的主要内容是,在分割的同时,加上对partition state的设置,供后续图流分割使用。文中用到的partition state如图所示。

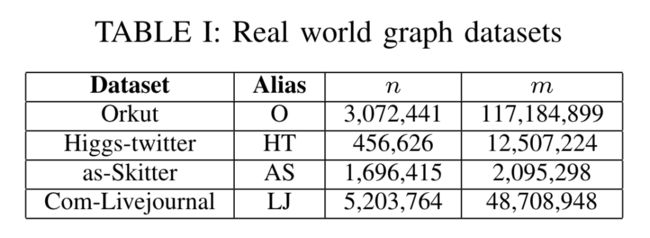
因此,本文在初始阶段使用NE,在后续阶段使用HDRF,大大提升了分割效果,同时分割速度也很高。本文在以下4个真实世界数据集上进行了实验。
文中比较了各种offline和stream方法的replication factor(RF)和load balance(LB)来衡量分割效果,公式如下图所示。

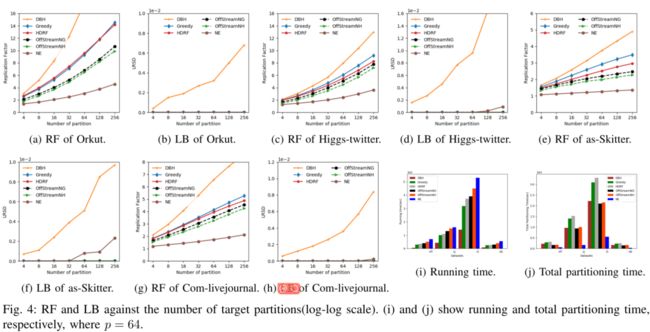
实验结果如下,可以看到,在stream算法中,本文的分割效果很好。
文章二:无损的图摘要
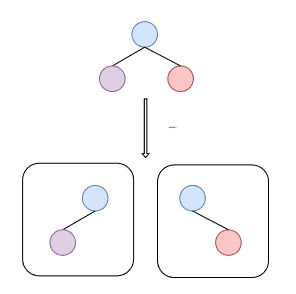
问题定义如下图所示,将一张图划分为多个超点,超点之间有连边代表两个超点间任意两点均连边。同时,还加上了edge correction 信息。还原原图时,在连上两个超点间任意两点的连边的基础上,进行edge correction,可以无损的得到原图。评价摘要质量的方式是希望压缩率尽可能高,也就是摘要图尽可能小。因为超点个数相对于边数目很小,可以忽略,因此我们的目标设置为最优化cost = |超点图的E|+|C+|+|C-|。

这篇文章是第一篇增量无损图摘要算法。文章基于如下观察:如下图所示,固定 vertex (为了更好的区分原图顶点和超点,我们在文中用vertex表示原图顶点,super node表示超点)划分,最优的 super node 间连边是显然的, 因此算法针对 vertex 划分即可。

维护vertex划分的方法是,每当新来一个增边或删边操作,我们都在 super node 之间移动 vertex,更改 vertex 划分。那么,余下的问题就变成了,移动哪些vertex,以及将其移动到哪个super node。本文使用采样方法来解决这两个问题。文章中展示了4个算法,来展示处理这两个问题需要考虑的因素。最后一个算法是文章提出的最终算法。
对于操作的边(u,v),u和v等价(本文针对无向图)。因此,下文只介绍 u 对应的部分。
第一个算法是greedy算法。它对两个问题是这么处理的:
1. 移动哪些 vertex:移动u。
2. 移动到哪个 super node:对每个 super node,计算把 u 移动到此 node 中之后的 cost,选最小 cost 的 node。
Greedy算法的问题是,每次只移动一个点,容易陷入局部最优。
第二个算法是MCMC算法。它对两个问题是这么处理的:
1. 移动哪些 vertex:移动u的所有邻居。
2. 移动到哪个 super node:对于每个u的邻居y,从所有 super node 中,按照预定义的随机分布,抽样一个super node。然后计算移动y后的 cost,根据移动、不移动两种情况的cost,得到“移动概率”。
MCMC算法的问题有两个。第一个问题是,邻居个数很多,这样做会带来高代价;第二个是,不容易遇到减小 cost 的好 super node 选择,移动概率往往很小。
总结前两个算法的问题,我们得到第三个算法Mosso-simple。它对两个问题是这么处理的:
1. 移动哪些 vertex:移动u的一部分邻居。具体方法如下图所示。
![]()
以1/deg(w)概率采样的原因是,高度数vertex的:连接性质往往独特,一般会形成 singleton super node(一个super node中只有它一个vertex),移动它结果一般不好。
2. 移动到哪个 super node:以概率 e(预定义e)在 N(u) 所在的 super nodes 中 等概率随机选择一个 super node,以概率1-e成立一个 singleton super node。如果移动后cost减小,则移动;反之不移动。
这个算法依然存在问题:第一个问题是,算法依然需要遍历u的所有邻居。邻居很多,因此只是获取邻居这一步,已经是性能瓶颈了。第二个问题是,等概率随机选择super node的情形下,Cost 减小的情形依然少。
因此,提出第四个算法Mosso来解决上面两个问题。首先,mosso使用如下图的算法来在不遍历u的所有邻居的前提下等概率采样u的邻居。

然后,引入粗聚类,来在super node的选取中进一步利用结构信息。如下图所示。粗聚类算法已经有很多文章研究了。本文实验中选用了min hashing算法。

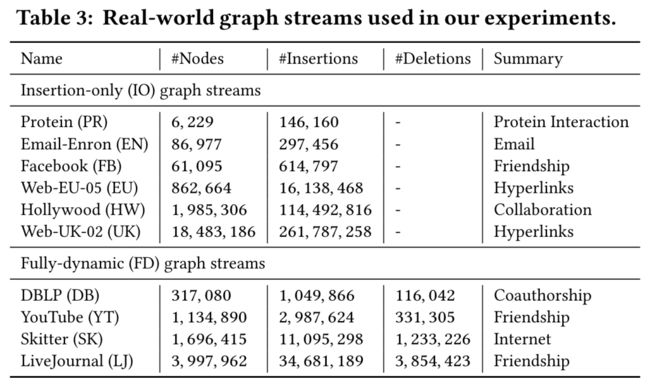
本文在以下数据集上进行了实验。
实验结果如下。可以看到,mosso比静态图上的算法快的多,同时也有不错的压缩率。


文章三:有损的图流摘要
针对的是图流大小不断增长的情景。以往工作中,GSS[3]利用一个固定大小的矩阵来存储图流摘要。对于图流大小不断增长的情景,naïve方法是将GSS连接成链,但这样会带来O(|E|)的时间复杂度。本文用树结构来组织GSS,在确保log级别的时间复杂度同时,节省空间。
本文的树结构如下图所示,是前缀树的结构,用指纹(每条边(s,d)都有对应的(footprint(s),footprint(d)),指纹是GSS中用于增加图摘要准确度的重要结构)的前缀来决定边应该存储在哪个子树中。当上层矩阵满了时,拓展下层矩阵。

与此同时,因为子矩阵中所有边的指纹前缀都相同,因此不需要存储指纹前缀。因此,第i层的矩阵中,每条边可以节省i bit的指纹。这个优化带来的空间节省如下图所示。

这个结构能够很好的节省空间和时间,但还有空间利用率波动的问题。如下图所示,每次新扩展一层,都会让空间利用率骤降。

因此,文章提出了进一步的优化来缓解这一点。首先,把4叉树改成2叉树,来让最坏情况下的空间利用率维持在1/2.第二个优化是,提出deputy tree的结构,如图所示。

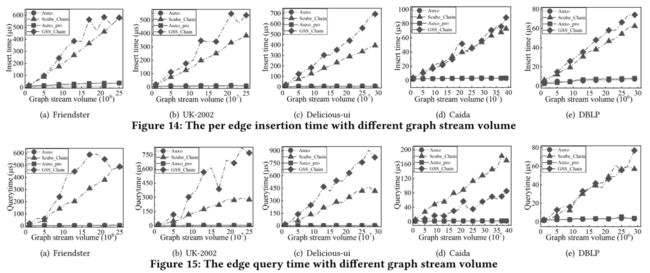
实验结果如下图所示。可以看到,Auxo的时间和空间效率都不错,同时准确性也较高。准确率用ARE表示,定义也在下方图中。



参考文献
[1] C. Zhang, F. Wei, Q. Liu, Z. G. Tang, and Z. Li, “Graph edge partitioning via neighborhood heuristic,” in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2017, pp. 605–614.
[2] F. Petroni, L. Querzoni, K. Daudjee, S. Kamali, and G. Iacoboni, “Hdrf: Stream-based partitioning for power-law graphs,” in Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. ACM, 2015, pp. 243–252.
[3] Xiangyang Gou, Lei Zou, Chenxingyu Zhao, and Tong Yang. 2019. Fast and Accurate Graph Stream Summarization. In Proceedings of the 35th IEEE International Conference on Data Engineering (ICDE ’19). IEEE, Macao, China, April 8-11, 2019, 1118–1129. https://doi.org/10.1109/ICDE.2019.00103