【CV with Pytorch】第 6 章 :姿态估计
人体姿势估计 (HPE)是一项计算机视觉任务,它通过估计给定帧/视频中的主要关键点(例如眼睛、耳朵、手和腿)来检测人体姿势。图6-1显示了人体姿态估计的一个例子。

图 6-1 HPE示例
人体姿势检测有助于跟踪人体部位和关节。在人体中识别的一些关键点是手臂、腿、眼睛、耳朵、鼻子等,它们可以帮助我们跟踪运动。
HPE 主要广泛应用于机器人、理解人类活动和行为、运动分析等领域。
深度学习概念,尤其是 CNN 架构,专为 HPE 量身定制和设计。
有两种方法可以解决这个问题:
自上而下的方法
自下而上的方法
自上而下的方法
使用这种方法,首先通过在每个人周围绘制一个估计的边界框来识别人类。在第二步中,在特定人的每个边界框内识别人类关键点。这种方法的缺点是我们需要有一个单独的模型来进行人体识别,然后必须识别所有边界框内的关键点。这增加了计算时间和复杂性。该模型的优点是网络将识别框架中的所有人类。
自下而上的方法
使用这种方法,首先在给定的帧中识别所有人类关键点。第二阶段,将关键点连接起来形成类人骨架。这种方法的缺点是由于图像的尺度变化,它可能无法识别较小尺度的人。与自上而下的方法相比,这种方法的优点是减少了计算时间。
以下是当今使用的更常见的 HPE 模型:
OpenPose: 2019
HRNet: 2019
Higher HRNet: 2020
AlphaPose: 2018
Mask R-CNN: 2018
Dense pose: 2018
DeepCut: 2016
DeepPose: 2014
Pose Net: 2015
OpenPose
打开姿势是一种基于 VGG19 的实时、多人、多阶段姿态估计算法。该算法遵循自下而上的方法。输入图像被发送到 VGG-19 网络以提取特征图。提取的特征图被传递给多级 CNN。每个阶段包含两个并行运行的分支。
分支 1
该分支为要检测的关键点创建热图/置信度图。为所有关键点生成单独的热图。
分支 2
该分支创建部件亲和字段 (PAF)。PAF 可以识别关键点之间的连接。
两个分支的输出被映射以使用线积分识别正确的连接。L2损失是在预测结果(热图,PAF)和ground truth(热图,PAF)之间计算的。使用了两个 L2 损失函数——一个在每个分支的末尾。在训练期间,整体损失计算为这两个损失函数的总和。
第 1 阶段的输出被传递到第 2 阶段以改进结果。模型的深度随着阶段数的增加而增加。由于图像中可以有多个人,因此使用加权二分图来连接同一个人的各个部分。连接的对被合并以形成人体骨骼。该模型可以在单个图像上检测多达 135 个关键点。OpenPose的架构和流程图如图6-2和6-3所示。

图 6-2 OpenPose 架构
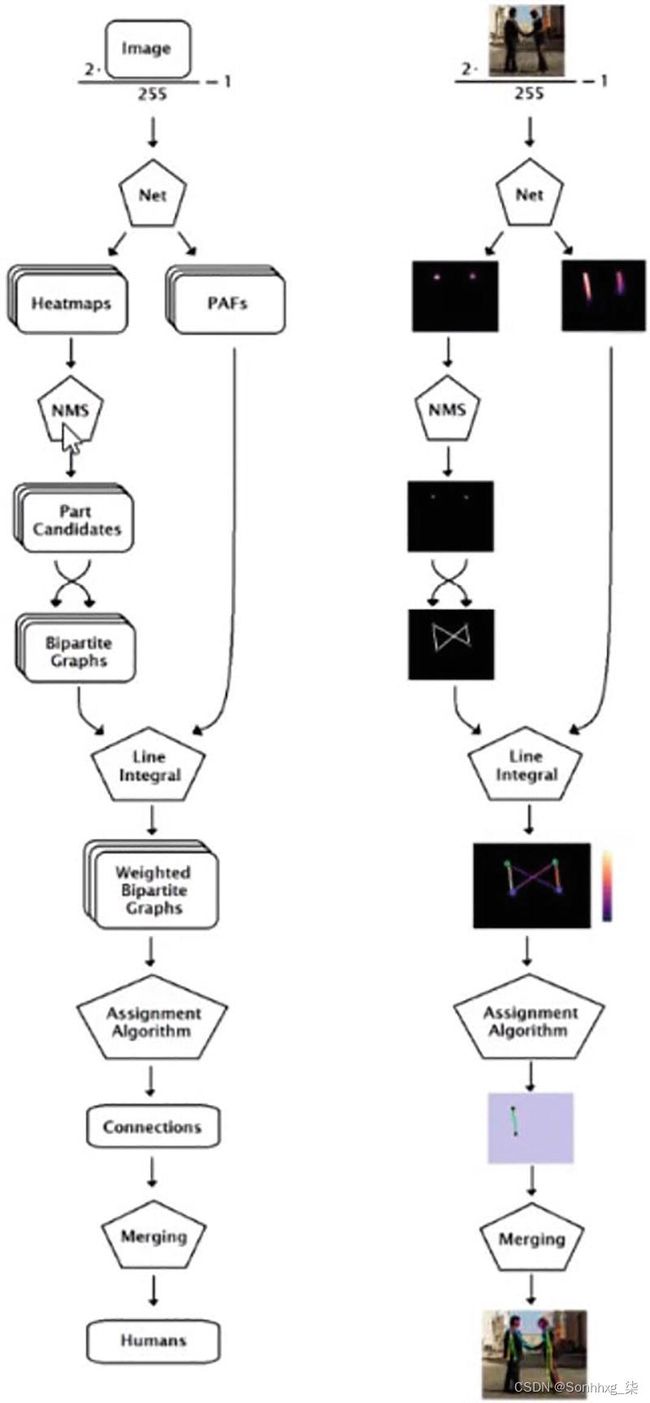
图 6-3 OpenPose流程图
图6-4显示了 OpenPose 运行时与其他模型的比较。默认 OpenPose 和最大精度 OpenPose 承诺更好的性能。

图 6-4 OpenPose 管道和运行时与其他模型的比较
HRNet(高分辨率网络)
这是一种自上而下的方法。它首先使用 Faster-RCNN 识别图像中的人,并在他们周围设置边界框。使用 HRNet 架构生成高质量的特征图。然后在每个边界框中识别关键点。
动机:
1.所有以前的模型(AlexNet、GoogleNet、ResNet 和 DenseNet)都是在图像分类卷积架构上开发的,使得输出分辨率低且对位置不敏感。使用空洞卷积可以在这些架构中增加低分辨率,但计算时间会增加。
2.上采样是这个问题的替代方法。U-net、SegNet、DeConvnet 和 Hourglass 模型使用上采样技术。在这种技术中,第 1 阶段的输入图像被转换为低分辨率以进行分类。在第 2 阶段,高分辨率图像将通过顺序连接的卷积从低分辨率图像中恢复。但是从 LR 完全恢复 HR 是不可能的,并且表示的位置敏感性很弱。
HRNet 是一种用于视觉识别的通用架构。它的架构不基于任何使用串联卷积的分类网络。在 HRNet 架构中,多分辨率卷积与使用上采样和下采样技术的重复融合并行连接。该网络自始至终维护 HR 表示。分辨率之间的反复融合加强了高分辨率和低分辨率的表示。使用称为“跨步卷积”的下采样技术将 HR 卷积转换为 LR 卷积。使用“双线性上采样”技术将 LR 卷积转换为 HR 卷积。HR 分支保留空间信息,LR 分支保留上下文信息。图6-5、6-6和_ _图 6-7显示了 HRNet 的详细架构。

图 6-5 HRNet 架构,第 1 部分
主要观察:
在分类中,卷积被串联放置。但在 HRNet 中,卷积是平行放置的。
对于上采样,使用双线性函数代替卷积(由于时间复杂度)。
跨步卷积用于对 HR 图像进行下采样(以避免信息丢失)。
阶段 2、3 和 4 中的块数为 1、4 和 3。这些数字没有得到很好的优化(根据作者的说法)。由于 HRNet 中的通道数量减少,参数和计算复杂度并不高于 ResNet。由于该架构是一个多分辨率网络,因此输出以所有分辨率(高、中和低)提供。对于 HPE,仅使用 HR 通道输出。对于语义分割和面部对齐,使用所有分辨率输出。
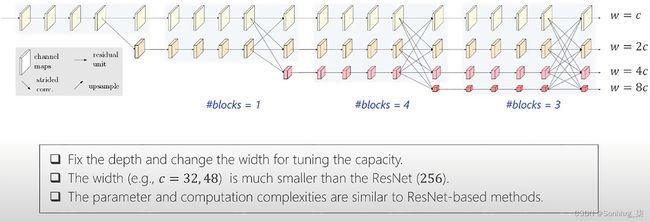
图 6-6 HRNet 架构,第 2 部分

图 6-7 HRNet 架构,第3部分
Higher HRNet
这是一种自下而上的方法,不同于原始的 HRNet 模型。以前的自下而上方法的主要问题是处理尺度变化(例如儿童或远处的人)。这个问题在Higher HRNet 模型中得到解决通过使用 HR 特征图(来自 HRNet)和 HR 热图(使用反卷积步骤)。
该网络是使用 HRNet 架构作为主干构建的。输入图像被传递到一个茎(包含两个卷积块,将分辨率降低到 ¼)。随后图像通过 HRNet 架构生成 HR 特征图。HR 特征图被馈送到反卷积块。这些反卷积块(来自 HRNet 的特征图和预测热图)作为输入,将生成两个 HR 热图,然后是四个残差块(batch norm + ReLU)以对特征图进行上采样。该模型使用高分辨率监督技术来训练模型。将地面实况关键点转换为所有分辨率热图以生成地面实况热图。预测的热图根据地面实况热图进行验证,以计算损失(均方误差)。数字图6-8显示了架构。

图 6-8 Higher HRNet架构
从理论研究来看,Higher HRNet 在解决计算时间(使用自下而上的方法)和尺度变化问题(使用多分辨率)方面显示出可喜的结果。
PoseNet
PoseNet是一个基于tensorflow.js构建的姿势估计器,可在移动设备上运行。它通过检测人体的眼睛、鼻子、嘴巴、手腕、肘部、臀部、膝盖等点来估计人体的姿势,通过将这些关键点连接起来形成姿势的骨骼状结构。
它适用于单个和多个人体姿势检测。
PoseNet 是如何工作的?
PoseNet 使用 ResNet 和 MobileNet 模型进行训练。ResNet 模型具有更高的准确性。但是它体积大,层数多,速度较慢。因此,最好使用 MobileNet 模型,因为它专为在移动设备上运行而设计。姿态估计分两个阶段进行:
输入的 RGB 图像被送入卷积神经网络。
单姿态或多姿态算法用于从模型输出中获取关键点(坐标)及其置信度分数。
PoseNet 模型的输出是一个姿势对象,其中包含每个检测到的人的关键点列表和置信度分数。图6-9显示了位姿与关键点置信度。

图 6-9 姿势与关键点置信度的图示
单人姿态估计
当输入图像或视频中只有一个人居中时就是这种情况。单姿态估计算法的输入如下:
输入图像元素:程序将为其预测姿势的输入图像元素。
图像比例因子:介于 0.2 和 1 之间的数字。默认情况下,它设置为 0.5。
水平翻转:默认情况下,此项设置为 false。如果必须水平/垂直翻转姿势,则必须将其设置为true。当视频默认水平翻转时,姿势会返回到正确的方向。
输出步幅:这应该是 32、16 或 8。默认情况下,它设置为 16。此变量影响神经网络的高度和宽度层。输出步幅的值越低,精度越高,但速度越慢,反之亦然。
单个姿势估计的输出是一个姿势,包含姿势置信度分数和 17 个关键点的数组。关键点由关键点位置(x 和 y 坐标)和关键点置信度得分组成。
图6-10、6-11、6-12展示了PoseNet的流程图。

图 6-10 PoseNet的流程图

图 6-11 PoseNet 流程图,第2部分

图 6-12 PoseNet 流程图,第 3 部分
多人姿态估计
该算法可以估计图像中的许多姿势/人。它比单姿态算法有点复杂并且稍微慢一些。但它的主要优点是,如果一张图片中有多个人,他们的关键点不太可能关联。因此,即使要求检测单个人的姿势,该算法也可能更可取。这些算法的输入如下:
输入图像元素
图像比例因子
水平翻转
输出步幅
最大姿势检测:最多可以检测五个姿势
姿势置信度阈值
非最大抑制 (NMS) 半径:这控制返回的姿势之间的最小距离。它的默认值为 20。
该算法的输出是一组姿势。每个姿势包含 17 个关键点以及每个关键点的分数。
PoseNet 的优缺点
考虑PoseNet的这些优点和缺点:
由于它是轻量级模型,因此可用于移动/边缘设备。
如果图片中不止一个人,单人姿势估计算法会将关键点与错误的人相关联。
姿态估计的应用
以下是姿态估计的常见应用:
人类活动识别
人体坠落检测
控制台的运动跟踪
训练机器人
执行的测试用例 零售店视频
案例 1:使用 1 小时的 1080p 分辨率视频测试 PoseNet 模型,fps 为 2。结果:
CPU 利用率:80-90%
内存:1.2 至1.5GB
每秒帧数:15
一小时视频的处理时间和数据库插入:20 到 25 分钟
案例 2:使用 720p 和 480p 分辨率视频测试 PoseNet 模型一小时,fps 为 2。结果:
对于 720p,一小时视频的处理时间和 DB 插入:8 到 10 分钟,16 fps
对于 480p,一小时视频的处理时间和 DB 插入:4 到 5 分钟,25 fps
执行
现在我们已经涵盖了一些理论方面和模型,让我们继续使用其中一种方法和预训练模型的实现部分。以下是使用 PyTorch 检测单个图像的人体姿势的分步指南。
我们将使用“ Keypoint-RCNN Using ResNet-50 Architecture with Feature pyramid Network”解决人体姿势和关键点检测。代码分为七个块以便于理解。以下是步骤:
1.确定要跟踪的人类关键点列表。
2.识别关键点之间可能的联系。
3.从 PyTorch 库加载预训练模型。
4.输入图像预处理和建模。
5.构建自定义函数来绘制输出(关键点和骨架)。
6.在输入图像上绘制输出。
首先,让我们导入所需的库:
# 导入库
import os
import numpy as np
# 用于导入关键点RCNN预训练模型和图像预处理
import torchvision
import torch
# 用于读取图像
import cv2
# 用于可视化
import matplotlib.pyplot as plt
# 挂载谷歌驱动器
# 将目录更改为包含图像文件夹的相应文件夹
from google.colab import drive
drive.mount('/content/drive')
%cd '/content/drive/MyDrive/Colab Notebooks/Bodypose'第 1 步:确定要跟踪的人体关键点列表
可以在图6-13中找到人类关键点列表。这些关键点是深度学习模型中的目标实体,将在步骤 3 中讨论。
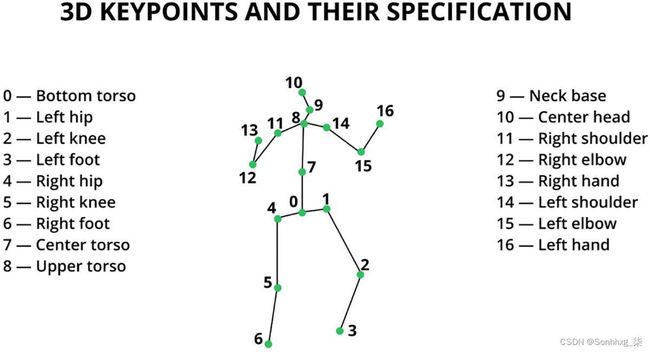
图 6-13 人类关键点的插图
图6-13显示了人体关键点的图示。
# 人类关键点列表 (count=17)
human_keypoints = ['nose','left_eye','right_eye','left_ear','right_ear','left_shoulder','right_shoulder','left_elbow',
'right_elbow','left_wrist','right_wrist','left_hip','right_hip','left_knee', 'right_knee', 'left_ankle','right_ankle']
print(human_keypoints)#输出
['nose', 'left_eye', 'right_eye', 'left_ear', 'right_ear', 'left_shoulder', 'right_shoulder', 'left_elbow', 'right_elbow', 'left_wrist', 'right_wrist', 'left_hip', 'right_hip', 'left_knee', 'right_knee', 'left_ankle', 'right_ankle']
第 2 步:确定关键点之间的可能连接
现在确定关键点之间可能的联系。例如,左耳与左眼相连。所有可能的连接都可以在以下代码片段中找到。
# 人类关键点之间可能的连接以形成一个结构
def possible_keypoint_connections(keypoints):
connections = [
[keypoints.index('right_eye'), keypoints.index('nose')],
[keypoints.index('right_eye'), keypoints.index('right_ear')],
[keypoints.index('left_eye'), keypoints.index('nose')],
[keypoints.index('left_eye'), keypoints.index('left_ear')],
[keypoints.index('right_shoulder'), keypoints.index('right_elbow')],
[keypoints.index('right_elbow'), keypoints.index('right_wrist')],
[keypoints.index('left_shoulder'), keypoints.index('left_elbow')],
[keypoints.index('left_elbow'), keypoints.index('left_wrist')],
[keypoints.index('right_hip'), keypoints.index('right_knee')],
[keypoints.index('right_knee'), keypoints.index('right_ankle')],
[keypoints.index('left_hip'), keypoints.index('left_knee')],
[keypoints.index('left_knee'), keypoints.index('left_ankle')],
[keypoints.index('right_shoulder'), keypoints.index('left_shoulder')],
[keypoints.index('right_hip'), keypoints.index('left_hip')],
[keypoints.index('right_shoulder'), keypoints.index('right_hip')],
[keypoints.index('left_shoulder'), keypoints.index('left_hip')]
]
return connections
connections = possible_keypoint_connections(human_keypoints)第 3 步:从 PyTorch 库加载预训练模型
在此博客中,我们使用具有 ResNet50 架构的PyTorch预训练模型keypoint-RCNN进行关键点检测。使用此参数加载模型:(pretrained= True)。
# 从预训练的 keypointrcnn_resnet50_fpn 类创建模型
pretrained_model = torchvision.models.detection.keypointrcnn_resnet50_fpn(pretrained=True)
# 调用 eval() 方法为推理模式准备模型。
pretrained_model.eval()#输出
Downloading: "https://download.pytorch.org/models/keypointrcnn_resnet50_fpn_coco-fc266e95.pth" to /root/.cache/torch/hub/checkpoints/keypointrcnn_resnet50_fpn_coco-fc266e95.pth
100%
226M/226M [00:04<00:00, 15.1MB/s]
KeypointRCNN(
(transform): GeneralizedRCNNTransform(
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
Resize(min_size=(640, 672, 704, 736, 768, 800), max_size=1333, mode='bilinear')
)
第 4 步:输入图像预处理和建模
原始图像在传递给模型之前需要归一化。使用TorchVision 的转换模块中的transforms.Compose()和transforms.ToTensor()类执行规范化。将输入图像放入当前工作目录的图像文件夹中。
# 导入transforms模块
from torchvision import transforms as T
# 使用opencv读取图像
img_path = "images/image1.JPG"
img = cv2.imread(img_path)
# 预处理输入图像
transform = T.Compose([T.ToTensor()])
img_tensor = transform(img)
# 前向传递模型
output = pretrained_model([img_tensor])[0]
print(output.keys())#输出
dict_keys(['boxes', 'labels', 'scores', 'keypoints', 'keypoints_scores'])
图6-14是我们用作输入的图像。

图 6-14 输入图像
第 5 步:构建自定义函数以绘制输出
构建自定义函数来绘制预测的关键点和身体骨架(通过连接关键点)。
# 绘制输入图像的关键点和骨架的函数
def plot_keypoints(img, all_keypoints, all_scores, confs, keypoint_threshold=2, conf_threshold=0.9):
# 从彩虹光谱中初始化一组颜色\
cmap = plt.get_cmap('rainbow')
# 创建图像的副本
img_copy = img.copy()
# 从光谱中选择一组 N 个颜色 ID
color_id = np.arange(1,255, 255//len(all_keypoints)).tolist()[::-1]
# 对检测到的每个人进行迭代
for person_id in range(len(all_keypoints)):
# 检查检测到的人的置信度分数
if confs[person_id]>conf_threshold:
# 抓取检测到的人的关键点位置
keypoints = all_keypoints[person_id, ...]
# 获取关键点的关键点分数
scores = all_scores[person_id, ...]
# 迭代每个关键点分数
for kp in range(len(scores)):
# 检查检测到的关键点的置信度分数
if scores[kp]>keypoint_threshold:
# 将关键点浮点数组转换为 python 整数列表
keypoint = tuple(map(int, keypoints[kp, :2].detach().numpy().tolist()))
# 在指定的 color-id 处选择颜色
color = tuple(np.asarray(cmap(color_id[person_id])[:-1])*255)
# 在关键点位置画一个圆圈
cv2.circle(img_copy, keypoint, 30, color, -1)
return img_copy
def plot_skeleton(img, all_keypoints, all_scores, confs, keypoint_threshold=2, conf_threshold=0.9):
# 从彩虹光谱中初始化一组颜色
cmap = plt.get_cmap('rainbow')
# 创建图像的副本
img_copy = img.copy()
# 检查是否检测到关键点
if len(output["keypoints"])>0:
# 从光谱中选择一组 N 个颜色 ID
colors = np.arange(1,255, 255//len(all_keypoints)).tolist()[::-1]
# iterate for every person detected
for person_id in range(len(all_keypoints)):
# 对检测到的每个人进行迭代
if confs[person_id]>conf_threshold:
# 检查检测到的人的置信度分数
keypoints = all_keypoints[person_id, ...]
# 迭代每个肢体
for conn_id in range(len(connections)):
# 选择肢体的起点
limb_loc1 = keypoints[connections[conn_id][0], :2].detach().numpy().astype(np.int32)
# 选择肢体的起点
limb_loc2 = keypoints[connections[conn_id][1], :2].detach().numpy().astype(np.int32)
# 将 limb-confidence 分数视为两个关键点分数中的最小关键点分数
limb_score = min(all_scores[person_id, connections[conn_id][0]], all_scores[person_id, connections[conn_id][1]])
# 检查 limb-score 是否大于阈值
if limb_score> keypoint_threshold:
# 选择特定颜色 ID 的颜色
color = tuple(np.asarray(cmap(colors[person_id])[:-1])*255)
# 为肢体画线
cv2.line(img_copy, tuple(limb_loc1), tuple(limb_loc2), color, 25)
return img_copy第 6 步:在输入图像上绘制输出
使用第 5 步中的自定义函数,将预测的关键点和骨架绘制到原始图像上。
#关键点
keypoints_img = plot_keypoints(img, output["keypoints"], output["keypoints_scores"], output["scores"],keypoint_threshold=2)
cv2.imwrite("output/keypoints-img.jpg", keypoints_img)
plt.figure(figsize=(8, 8))
plt.imshow(keypoints_img[:, :, ::-1])
plt.show()#输出
图6-15显示了带有关键点的图像。

图 6-15 带关键点的图像
#骨骼
skeleton_img = plot_skeleton(img,输出[“关键点”],输出[“keypoints_scores”],输出[“分数”],keypoint_threshold=2)
cv2.imwrite("output/skeleton-img.jpg", skeleton_img)
plt.figure(figsize=(8, 8))
plt.imshow(skeleton_img[:, :, ::-1])
plt.show()#plot
图6-16将图像显示为骨架。

图 6-16 图像作为骨架
以下是我们为不止一个人尝试过的其他图像的结果。您也可以在本书的 Git 链接上找到这些内容。
图 6-17 带关键点的图像
图 6-18 图像作为骨架
概括
本章探讨了开发姿势估计器模型的体系结构和代码演练。这在工业中被广泛使用。
您现在是否有信心构建一个充当“虚拟健身教练”的应用程序?考虑到有多少人想要家庭健身房,值得一试。在下一章中,我们将探讨如何对图像进行异常检测。