【数据分析进阶】DCIC竞赛-task5&6 订单调度分析
【数据分析进阶】DCIC竞赛-task5&6 订单调度分析
- task5 订单调度分析
-
- 经纬度转换相关知识
- 经纬度编码
- 订单调度分析
- 思考
- task 06 分析报告撰写
-
- 分析报告撰写
- 报告撰写建议
- 学习资源
task5 订单调度分析
经纬度转换相关知识
-
简单的城市名转换成经纬度:
https://www.cnblogs.com/zle1992/p/7209932.html -
批量获取经纬度:
https://www.cnblogs.com/reboot777/p/7124010.html -
用Python计算北京地铁的两站间最短换乘路线:
http://blog.csdn.net/myjiayan/article/details/45954679 -
使用爬虫获取获取所有的 站点名
http://blog.csdn.net/wenwu_both/article/details/70168760 -
高德地图地理编码服务
http://blog.csdn.net/u013250416/article/details/71178156
https://www.cnblogs.com/xautxuqiang/p/6241561.html
-
滴滴订单系统介绍
https://zhuanlan.zhihu.com/p/152013415
geohash原理介绍
- https://www.cnblogs.com/LBSer/p/3310455.html
- https://www.cnblogs.com/feiquan/p/11380461.html
geohash用一个字符串表示经度和纬度两个坐标。某些情况下无法在两列上同时应用索引 (例如MySQL 4之前的版本,Google App Engine的数据层等),利用geohash,只需在一列上应用索引即可。
其次,geohash表示的并不是一个点,而是一个矩形区域。比如编码wx4g0ec19,它表示的是一个矩形区域。 使用者可以发布地址编码,既能表明自己位于北海公园附近,又不至于暴露自己的精确坐标,有助于隐私保护。
热力图展示中,用于geohash点聚合功能,可以提高大量点前端渲染的性能
地址聚类中,通过geohash计算,进行地址归类
地址信息缓存时,通过geohash为key,来索引缓存信息
#geohash中precision的值设置的越大精确度越高,代表的区域越小
taxiorder2019.apply(lambda x: geohash.encode(x['GETON_LATITUDE'], x['GETON_LONGITUDE'], precision=5), axis=1)

【注意】在cmd中直接pip install geohash虽然能安装上,但是在jupyter中无法调用
可以使用pip install geohash2安装上然后import geohash2 as geohash
经纬度编码
文件读取、压缩及预处理
import pandas as pd
import numpy as np
import glob
INPUT_PATH='./input/taxiOrder/'
MAX_ROWS=None #文件读取行数
#读取出租车订单数据文件并进行压缩处理
taxiorder2019=pd.read_csv(INPUT_PATH+'taxiOrder20190531.csv',nrows=MAX_ROWS,
dtype = {
'GETON_LONGITUDE': np.float32,
'GETON_LATITUDE': np.float32,
'GETOFF_LONGITUDE': np.float32,
'GETOFF_LATITUDE': np.float32,
'PASS_MILE': np.float16,
'NOPASS_MILE': np.float16,
'WAITING_TIME': np.float16
})
#对时间类别属性进行转化
taxiorder2019['GETON_DATE']=pd.to_datetime(taxiorder2019['GETON_DATE'])
taxiorder2019['GETOFF_DATE']=pd.to_datetime(taxiorder2019['GETOFF_DATE'])
#属性列重命名
taxiorder2019 = taxiorder2019.rename(columns={'CAR_NO':'CARNO'})
#重新设置索引
taxiorder2019.sort_values(by=['CARNO','GETON_DATE'],inplace=True)
taxiorder2019.reset_index(inplace=True,drop=True)
下面对经纬度进行编码
import geohash2 as geohash
#对所有的经纬度实现了编码,percision编码的精确程度,设置的约精细hash范围越小,对每行进行操作所以设置axis=1
taxiorder2019.apply(lambda x: geohash.encode(x['GETON_LATITUDE'], x['GETON_LONGITUDE'], precision=5), axis=1)
结果是对数据中的所有经纬度都进行了编码
taxiorder2019['geohash'] = taxiorder2019.apply(lambda x: geohash.encode(x['GETON_LATITUDE'], x['GETON_LONGITUDE'], precision=8), axis=1)
taxiorder2019['geohash'].value_counts().head(10)
通过value_counts查看下出现最多的位置,第一为经纬度为空的异常值,从第二个开始才是正常的

#其中7zzzzzzz为异常点,可以提出掉,下面来统计热门的经纬度中心
#通过下面这个步骤统计出了排前十的(去掉异常后)的位置
for idx in taxiorder2019['geohash'].value_counts().iloc[1:11].index:
print(idx)
df=taxiorder2019[taxiorder2019['geohash']==idx]
#因为geohash对应的是一个区域,suoy
print(idx, df['GETON_LONGITUDE'].mean(), df['GETON_LATITUDE'].mean())

订单调度分析
分析哪些地方平均等待时间最长
#统计5000个热门的区域,value_counts.index返回了最热门5000区域的geohash的编码
legal_hash=taxiorder2019['geohash'].value_counts().iloc[:5000].index
#使用isin判断是否在5000个热门区域中,统计出来前50000个区域中的平均等待时间
taxiorder2019[taxiorder2019['geohash'].isin(legal_hash)].groupby(['geohash'])['WAITING_TIME'].mean().value_counts()

导入网约车数据进行统计
wycorder2019=pd.read_csv('./input/wycOrder/wycOrder20190531.csv')
#查看网约车等待时间存在着大量缺失,所以重新利用上车时间-预计上车时间来计算等待时间
wycorder2019.info()

#对时间进行处理
wycorder2019['DEP_TIME']=pd.to_datetime(wycorder2019['DEP_TIME'])
wycorder2019['BOOK_DEP_TIME']=pd.to_datetime(wycorder2019['BOOK_DEP_TIME'])
#计算等待时间
wycorder2019['WAITING_TIME'] = (wycorder2019['DEP_TIME']-wycorder2019['BOOK_DEP_TIME']).dt.seconds
#经纬度编码
wycorder2019['geohash'] = wycorder2019.apply(lambda x: geohash.encode(x['DEP_LATITUDE'], x['DEP_LONGITUDE'], precision=8), axis=1)
wycorder2019[wycorder2019['geohash'].isin(legal_hash)].groupby(['geohash'])['WAITING_TIME'].mean().sort_values()
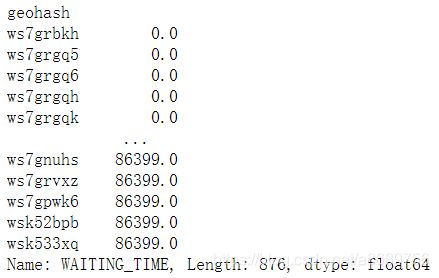
出租车筛选出的数据是1635个,而网约车在出租车的legal_hash中筛选得到的数据是876个,所以可以判定网约车与巡游车达不到车的位置区域存在部分重叠,但还是会有交叉的情况
- 比如打不到网约车,也打不到出租车;
- 比如打不到网约车,但能达到出租车;
思考
1.有没有其他对地理位置坐聚合的方法
2.如何定量衡量一个区域达不到车的情况
task 06 分析报告撰写
分析报告撰写
数据分析报告要有一个清晰的架构,层次分明能降低阅读成本,有助于信息的传达。虽然不同类型的分析报告有其适用的呈现方式,但总的来说作为议论文的一种,大部分的分析报告还是适用总-分-(总) 的结构。
本次DCIC2020详细分析报告要求为:以PDF形式提交,所有素材包括但不限于文字、图片、视频、网站等均需为中文,网站/视频素材可在方案里指明网站或视频链接地址。所提交方案要求设计架构完整、逻辑清晰,确保技术可行和可落地,内容可包括但不限于:
- 作品摘要:对作品做整体介绍。
- 问题需求:分析赛题问题的特征、场景、痛点,清楚说明所解决的问题和受众。
- 数据应用:清楚列举使用到的数据清单、数据分析细节以及安全保障等。
- 算法分析:阐述算法整体架构、重点描述任务数据清洗、特征构建、信息挖掘、关系关联、过程可视化、算法应用融合等各阶段的主要技术、方法、流程和关键实现代码。
- 结果及结果分析:说明算法的使用方法,基于算法模型及赛题数据输出的模型分析结果集、评测成绩,以及针对结果的分析说明等。
- 应用成果:详细说明作品的预期应用成果。
- 作品价值:说明作品的潜在社会效益和经济效益,指出方案的独特价值和亮点。
- 实施建议:结合赛题分析结果,提出可行性实施建议等。
参考文献:列举参考的文章、书目等。
参考样例:2020年Q1滴滴出行城市交通出行报告
报告撰写建议
在赛题分析报告中,不能只是侧重分析,措施建议类、策略性的篇幅比例建议不低于30%,数据模型算法挖掘、数据分析结果不低于50%。
围绕赛题要求写,统计分析、结果对比和建议举措;
图要清晰美观,标注详细;
表要直接间接,数据竟可能正确;
学习资源
分析报告模板
数据分析规范总结
动画交互效果实现:寻找相关工具