类人的系统泛化性完全可以通过组合元学习框架实现,NYU最新成果登上Nature

论文链接:Human-like systematic generalization through a meta-learning neural network | Nature
上世纪80年代,认知科学研究者Jerry Fodor和Zenon Pylyshyn合作发表了一篇论文《联结主义和认知架构》[1],在该文中,他们提出了一个著名的观点,"即人工神经网络缺乏理解已知概念并泛化到新组合上的能力,因此他们认为神经网络并不是一种合理的思维模型"。虽然在那之后的一段时间,神经网络产生了一定的发展,但是在泛化性方面的系统问题仍然被学术界诟病,直到今天。但是如果我们从人类认知能力的底层出发,就会发现,"人类语言和思维的力量源于系统的组合性",人类在探索新概念的过程就可以理解是对已知概念的有机组合。本文介绍一篇来自纽约大学和庞培法布拉大学合作完成的论文,目前已被Nature期刊录用。
在本文中,作者团队完整的证明了神经网络在优化其组合技能时可以实现类似人类的系统性,这有效的回应了Fodor和Pylyshyn在多年前提出的挑战。具体来说,本文提出了一种称为组合性元学习(meta-learning for compositionality,MLC)的方法,MLC可以通过动态的任务组合来指导模型训练。为了继续全面的评估,作者遵循指令学习范式设计了人类行为模拟实验,并且选择了7种不同的算法模型进行对比实验,实验结果表明,MLC能够同时实现类似人类泛化所需的系统性和灵活性,并且在多个泛化基准中提高了模型的综合性能,这有力的证明了:一个神经网络架构在进行概念组合方面的优化后,完全可以模仿人类的系统泛化能力。
01. 引言
人类在学习全新概念时可以很好的利用先前已经掌握的技能,例如一旦小孩学会了基础动作"跳跃",他就可以灵活的组合出"向后跳跃"、"连续跳跃"等其他新技能。而通常印象里,模仿人类神经元机制的神经网络却不具备这样的能力。但随着神经网络不断发展,甚至出现了以ChatGPT为代表的涌现大模型,这个问题能否得到解决呢。因此本文的研究团队重新审视了这一经典的系统性测试挑战,提出了MLC优化框架,并且提供了强有力的证据证明神经网络可以通过MLC实现类似人类的系统泛化,MLC可以通过一系列的小样本组合任务来引导模型泛化到新任务中(如下图所示)。
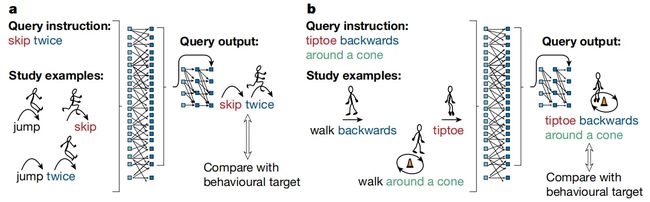
在MLC的训练阶段,只需要提供给神经网络一组已有的任务示例和一条查询指令,上图(a)中的任务示例为如何“跳(jump)”、“连跳两次(jump twice)”和“跳过(skip)”,随后在新的场景中给定一个新查询单词“连续跳过两次(skip twice)”,MLC可以在没有添加任何符号机制以及其他手工设计的情况下,自行组织已有概念泛化到新任务中,这提供了一种高层语义的指导方案来引导普通神经网络获得新能力。
02. 本文方法
下图展示了本文提出的MLC方法的整体框架,其核心部件使用标准的seq2seq transformer,整体架构由两个协同工作的神经网络构成,图中下半部分的编码器transformer用于处理查询输入和已有概念示例,上半部分的解码器用于生成输出序列。其中编码器和解码器都有3层,每层设置8个注意力头,输入和隐藏层的嵌入大小为128,整体框架的参数量为140万。
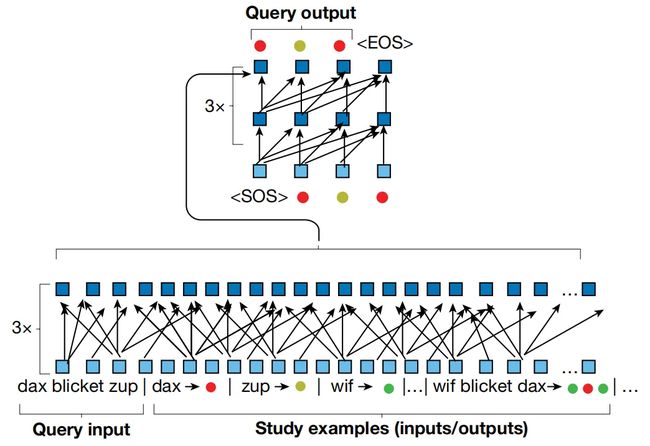
在模型训练阶段,MLC通过优化transformer网络来完成元学习过程,模型将支持示例和新指令联合起来作为输入在每个episode构成一个不同的seq2seq任务,由于模型的优化发生在动态变化的事件中(每个事件都有新的指令和查询示例),而不是在静态数据集上进行,因此模型必须从输入的文本中提取语义并且尝试对它们进行组合来完成新查询的任务,这一过程灵活地发生在现代Transformer神经网络中的可变长度输入和自注意力块中,这表明随着研究的进步,我们已经可以在神经网络架构本身的设计上应对Fodor和Pylyshyn的挑战。
03. 实验效果
本文的实验主要聚焦于MLC框架在一些极具挑战性的泛化任务中能否实现类似人类水平的系统泛化能力,如果不能实现,MLC也应该和人类在类似任务中发生失误的情况相同。具体来说,模型必须从几个例子中系统地学习和使用单词,可以清晰的捕捉其中输入/输出之间的结构化关系。当模型遇到一个未知任务时,MLC需要引导网络获得特殊的参数值,这些参数值能够准确支持模型完成当前的新任务。本文作者参考人类系统的泛化特性设计了多种实验,这些实验要求模型能够理解文本指令并生成行为响应,这些响应值随后可以直接输入到seq2seq工具包中对结果数据进行建模。具体的实验分为小样本学习任务和开放式指令任务等多种形式。
3.1 小样本学习任务
在该任务中,作者对25个参与者提供了包含14个学习指令(输入/输出对)的任务,任务要求为10个新的查询任务指令,任务的详细设计如下图所示,首先设置了四个原始单词,是从一个输入单词到一个输出符号的直接映射(例如,“dax”是红色圆圈,“wif”是绿色圆圈,“lug”是蓝色圆圈),其他几个单词是带有参数的功能术语,例如函数 1(图中的“fep”)将原始单词作为参数,并重复输出3次(“dax fep”就是是 RED RED RED)。 函数 2(图中的“blicket”)将前面的单词和后面的单词作为参数,以特定的交替序列生成它们的输出(“wif blicket dax”是绿色、红色、绿色)。通过这种原始单词和参数函数的组合,就可以设计出非常复杂的泛化新任务,并且对于这种任务,人类也需要在脑海中进行推理后才能完成。
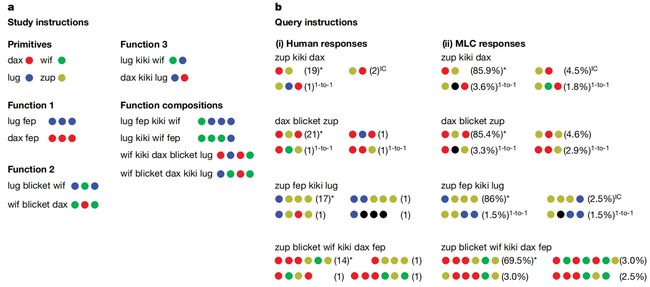
作者在上图(b)中展示了参与测试的25个人类受试者得到的结果,可以看到,在80.7%的情况下,人类受试者可以做出与代数标准完全匹配的答案,而MLC的表现非常接近人类,并且在处理较长序列的情况时,MLC可以实现77.8%的性能,由于MLC在训练阶段只接收过短序列,因此处理长序列是一种非常典型的泛化现象,但是MLC很好的实现了这一点。
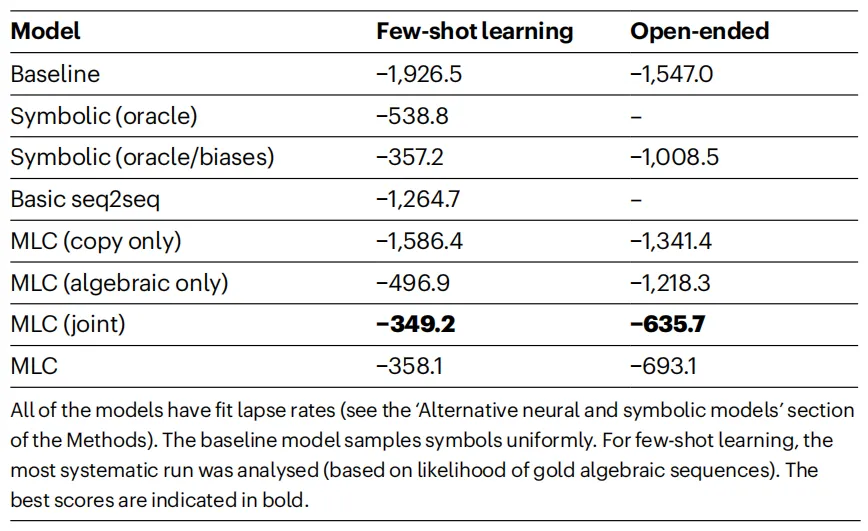
此外,作者还选取了包括概率符号模型(Symbolic oracle)、基础seq2seq等在内的其他神经网络作为对比baseline方法,对比效果如上表所示,可以看到,MLC模型及其变体在小样本学习任务和下节介绍的开放式指令任务中均取得了优越的性能,其中达到最佳性能的MLC(joint)变体是针对小样本学习任务和开放式指令任务进行联合优化的版本。
3.2 开放式指令任务
开放式指令任务可以很好的反映出任务本身具有的归纳偏差,作者对29个人类受试者提供了7个未知指令任务,任务详情如下图所示,受试者需要对输入指令之间的相互关系合理的猜测(用一系列彩色圆圈回答“fep fep”或“fep wif”),在实验过程中,防止受试者看到任何输入/输出示例,从而展示其归纳偏差。

其中大多数受试者(29 人中的 17 人,约占58.6%)的反应类似于图 3a、b(左)中的模式,这与任务固有的三种归纳偏差完全一致,而MLC模型在65.0%的样本中的响应与人类受试者完全相同,如图 3b(左)所示,完美地学习到了三个关键的归纳偏差。并且在图 3b(右)中的情况,MLC捕获了更细微的响应模式,但仅使用了部分的归纳偏差。
04. 总结
目前,关于神经网络的系统性争论仍然存在,即使对于最近的大型语言模型(例如GPT-4),系统性仍然是一个挑战问题。本文针对该问题设计了一种元学习框架MLC,MLC以一种动态的方式对训练阶段的已知任务进行组合,从而实现了模仿人类泛化能力的效果。MLC可以精确的对神经网络的组合技能进行优化,这样的优化手段相比以标准方式训练的神经网络表现出了更强的系统性,并且比符号模型表现出更细致的行为。如果将MLC框架应用到目前更为先进的网络上(例如GPT系列大模型),是否会出现更加接近于通用人工智能的效果呢?
参考
[1] Fodor, J. A. & Pylyshyn, Z. W. Connectionism and cognitive architecture: a critical analysis. Cognition 28, 3–71 (1988).
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区