YOLOV8目标识别——详细记录从环境配置、自定义数据、模型训练到模型推理部署
一、概述
Yolov8建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性。Yolov8具有以下特点:
- 高效性:Yolov8采用了新的骨干网络、新的Ancher-Free检测头和新的损失函数,可在CPU到GPU的多种硬件平台上运行,使得模型在运行速度和准确性方面都表现出色。
- 创新性:Yolov8借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,全面提升改进了Yolov5模型结构,同时保持了Yolov5工程化简洁易用的优势。
- 易用性:Ultralytics没有直接将开源库命名为Yolov8,而是直接使用"ultralytics",将其定位为算法框架,而非某一个特定算法。这使得Yolov8开源库不仅仅能够用于Yolo系列模型,而且能够支持非Yolo模型以及分类分割姿态估计等各类任务。
- 全面性:Yolov8在目标检测、图像分割、姿态估计等任务中都表现出色,成为实现这些任务的最佳选择。
二、YoloV8目标识别
1.目标识别
目标检测是计算机视觉中的一个重要任务,旨在识别图像或视频中的物体并确定它们的位置。有许多目标检测算法,其中一些是经典的方法,而另一些是基于深度学习的最新方法。常见的目标检测算法:
-
R-CNN系列(R-CNN、Fast R-CNN、Faster R-CNN):
- R-CNN(Region-based Convolutional Neural Network): 首次引入了区域建议网络(Region Proposal Network),然后对提议的区域进行分类。
- Fast R-CNN: 对R-CNN进行了加速,将区域提议和特征提取合并为一个单一的神经网络。
- Faster R-CNN: 进一步优化,将区域提议网络集成到主干网络中,提高了速度和性能。
-
YOLO系列(YOLO、YOLOv2、YOLOv3、YOLOv4、YOLOv5):
- YOLO(You Only Look Once): 通过将图像划分为网格,并在每个网格中同时预测边界框和类别,实现了快速目标检测。
- YOLOv2(YOLO9000): 引入了Anchor Boxes和Darknet-19网络,提高了性能。
- YOLOv3: 进一步改进,引入了多尺度预测、跨尺度连接等特性,提高了检测性能。
- YOLOv4: 引入了CSPNet、PANet等创新,提高了速度和精度。
- YOLOv5: 通过引入更强大的骨干网络(backbone)和改进的训练策略,进一步提高了性能。
-
SSD(Single Shot MultiBox Detector):
- 通过在不同尺度上预测边界框,实现了单次前向传播内的目标检测。
-
RetinaNet:
- 引入了Focal Loss,解决了类别不平衡问题,提高了检测性能。
-
EfficientDet:
- 结合了EfficientNet的高效网络结构和目标检测任务的特定优化,实现了高性能的目标检测。
-
Mask R-CNN:
- 在Faster R-CNN的基础上,增加了对目标实例分割的支持,能够生成每个检测到的物体的二进制掩码。
这些算法具有各自的特点和适用场景,选择合适的算法通常取决于具体的应用需求、计算资源以及性能要求。深度学习方法在目标检测领域取得了显著的进展,但也有一些经典的非深度学习方法在特定情境下仍然具有优势。
2.Yolov8目标识别
YOLOv8 的主要具有以下特点:
- 对用户友好的 API(命令行 + Python);
- 模型更快更准确;
- 模型能完成目标检测、实例分割和图像分类任务;
- 与先前所有版本的 YOLO 兼容可扩展;
- 模型采用新的网络主干架构;
- 无锚(Anchor-Free)检测;
- 模型采用新的损失函数。
YOLOv8 还高效灵活地支持多种导出格式,并且可在 CPU 和 GPU 上运行该模型。YOLOv8 的整体架构如下图所示:
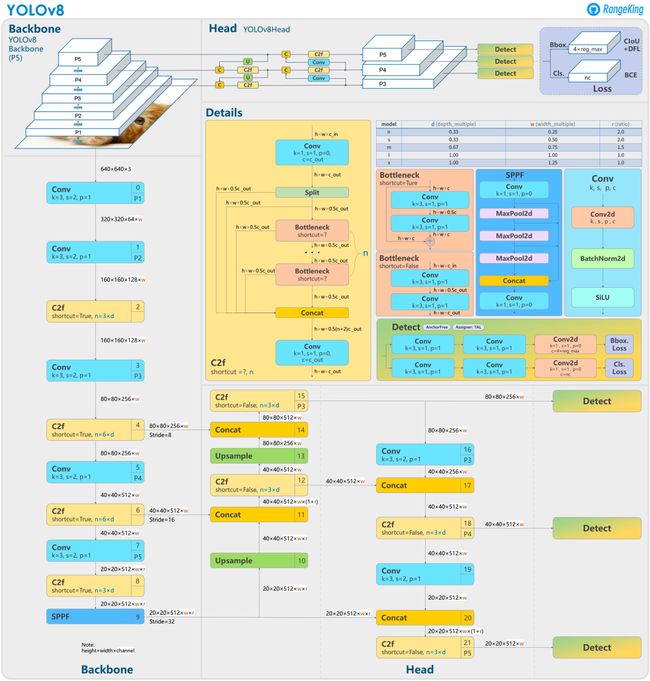
YOLOv8是一种无锚(Anchor-Free)模型,这意味着它直接预测对象的中心,而不是通过预测锚框的偏移量来定位对象。相对于使用锚框的传统方法,无锚模型通过减少需要预测的边界框的数量,加速了复杂的推理步骤,如非极大值抑制(NMS)。
YOLOv8系列包含5个模型,其中YOLOv8 Nano(YOLOv8n)是最小且速度最快的模型,而YOLOv8 Extra Large(YOLOv8x)则是最准确但速度较慢的模型。这种层次结构允许用户在速度和准确性之间做出权衡,选择适合其特定需求的模型。

三、环境安装
1.直接安装
yolov8有两种安装方式,一种可直接安装U神的库,为了方便管理,还是在conda里面安装:
conda create -n yolov8 python=3.8
activate ylolv8
pip install ultralytics
2.源码安装
源码安装时,要单独安装torch,要不然训练的时候,有可能用不了GPU,我的环境是cuda 11.7。
#新建虚拟环境
conda create -n yolov8 python=3.8
#激活
conda activate yolov8
#安装torch,
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
#下载源码
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
#将requirements.txt中torch torchbision 注释掉,下载其他包
pip install -r requirements.txt
3.验证
安装完成之后,验证是否安装成功。
yolo task=segment mode=predict model=yolov8s-seg.pt source='1.jpg' show=True

4.安装错误
1.OMP: Error #15: Initializing libomp.dylib, but found libiomp5.dylib already initialize
如果在训练时出现这个错误,要么就降低numpy的版本,要么就是python的版本太高,降到3.9以下就可以了。
四、数据集处理
1.数据集采集
数据采集是深度学习和人工智能任务中至关重要的一步,它为模型提供了必要的训练样本和测试数据。在实际应用中,数据采集的方法多种多样,每种方法都有其独特的优势和适用场景。以下是一些常见的数据采集方法:
-
使用开源已标记数据集:
- 利用公开可用的已标记数据集,如ImageNet、COCO、MNIST等。这些数据集通常包含大量的图像和相应的标注,可用于训练和评估深度学习模型。
-
爬取数据集:
- 通过网络爬虫从互联网上收集数据。这对于特定领域的数据集创建非常有用,但需要注意法律和道德问题,确保数据采集的合法性和隐私。
-
自己拍摄数据集:
- 在某些情况下,特定领域或任务可能需要自己采集数据,例如拍摄独特的图像或视频。这样的数据集可以满足特定需求,但也可能需要更多的时间和资源。
-
使用数据增强生成数据集:
- 利用数据增强技术,通过对现有数据进行旋转、翻转、缩放等变换,生成更多的训练样本。这有助于模型更好地泛化到不同的场景。
-
众包数据标注:
- 将数据标注任务分发给大量工作者进行标注。这适用于大规模数据标注,但需要有效的质量控制机制。
-
合成数据集:
- 利用计算机图形学技术生成合成数据,用于模型训练。这对于某些任务,如虚拟场景下的目标检测,非常有用。
在数据采集过程中,确保数据的质量和多样性非常重要。同时,对于敏感信息的数据,需要遵循隐私法规,并采取相应的保护措施。综合使用多种数据采集方法,根据任务和需求选择最适合的方法,有助于建立高质量、多样性且具代表性的数据集,提高模型的性能和泛化能力。
2.数据集标注
LabelMe 是一种流行的开源图像标注工具,用于创建包含各种标注,如边界框、多边形、线条和点的标记的图像数据集。LabelMe进行标注的一般步骤:
-
安装LabelMe:
- 首先,确保安装了LabelMe工具。你可以在其官方GitHub存储库(https://github.com/wkentaro/labelme)中找到详细的安装说明。
-
启动LabelMe:
- 运行LabelMe应用程序,打开需要标注的图像。你可以使用命令行运行
labelme或者使用图形用户界面(GUI)。
- 运行LabelMe应用程序,打开需要标注的图像。你可以使用命令行运行
-
创建新项目或打开现有项目:
- 在LabelMe中,你可以选择创建新项目或打开现有的项目。项目是一个包含标注信息的文件夹。
-
标注对象:
- 在图像中使用不同的工具(边界框、多边形、线条、点)标注感兴趣的对象。你可以选择标注对象的类别,并为每个类别定义名称和颜色。
-
保存标注:
- 保存标注后,LabelMe将生成一个包含标注信息的JSON文件,与原始图像一起保存在项目文件夹中。
-
导出标注数据:
- 可以将标注数据导出为各种格式,例如Pascal VOC、COCO等,以便用于深度学习模型的训练和评估。
-
数据集管理:
- 可以使用LabelMe创建的标注数据集进行训练、验证和测试深度学习模型。在训练模型之前,通常需要将标注数据集转换为模型所需的特定格式。
LabelMe的灵活性和易用性使其成为图像标注领域的一种流行选择。它适用于各种项目,包括目标检测、实例分割、图像分类等。在使用LabelMe进行标注时,确保按照项目需求设置合适的类别、名称和颜色,以便后续的数据处理和模型训练。
3.数据转换
将LabelMe标注生成的JSON文件转换为YOLO格式的TXT文件需要进行一些数据格式的映射和坐标的转换。以下是一般的步骤:
- LabelMe JSON结构:
- LabelMe生成的JSON文件包含了图像的标注信息,其中每个对象都有其边界框或多边形的坐标信息,以及对象的类别等。JSON结构可能如下所示:
{
"version": "5.3.0a0",
"flags": {},
"shapes": [
{
"label": "person",
"points": [
[
55.59312320916908,
1.6332378223495834
],
[
191.40974212034385,
258.36676217765046
]
],
"group_id": null,
"description": "",
"shape_type": "rectangle",
"flags": {}
},
{
"label": "backpack",
"points": [
[
108.88825214899715,
19.684813753581675
],
[
169.63323782234957,
132.2922636103152
]
],
"group_id": null,
"description": "",
"shape_type": "rectangle",
"flags": {}
},
{
"label": "suitcase",
"points": [
[
142.69914040114614,
125.41547277936962
],
[
254.77429459472592,
259.0
]
],
"group_id": null,
"description": "",
"shape_type": "rectangle",
"flags": {}
}
],
"imagePath": "aod (2).png",
"imageData": "xxxxxx...................................",
"imageHeight": 260,
"imageWidth": 396
}
- YOLO TXT格式:
YOLO使用相对边界框坐标来描述图像中的对象。YOLO算法中的文本文件(通常以.txt为扩展名)包含了每个图像中对象的标注信息,格式通常如下:
每一行对应于图像中的一个对象,例如,如果图像中有多个对象,则每行表示一个对象的标注信息。
以下是一个示例:
0 0.5 0.4 0.2 0.3
1 0.3 0.6 0.4 0.5
在此示例中,有两个对象被标注。第一个对象属于类别0,其边界框中心位于图像宽度的50%和高度的40%,宽度占图像宽度的20%,高度占图像高度的30%。第二个对象属于类别1,其边界框中心位于图像宽度的30%和高度的60%,宽度占图像宽度的40%,高度占图像高度的50%。
- 转换过程:
- 遍历LabelMe JSON文件中的每个对象,提取类别和边界框的坐标。
- 将坐标转换为相对于图像宽度和高度的相对值。
- 将转换后的信息写入YOLO格式的TXT文件。
import os
import numpy as np
import json
from glob import glob
import cv2
from sklearn.model_selection import train_test_split
from os import getcwd
def get_file(json_path,test):
files = glob(json_path + "*.json")
files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files]
if test:
trainval_files, test_files = train_test_split(files, test_size=0.1, random_state=55)
else:
trainval_files = files
test_files = []
return trainval_files, test_files
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
#
# print(wd)
def json_to_txt(json_path,files, txt_name,classes):
if not os.path.exists('tmp/'):
os.makedirs('tmp/')
list_file = open('tmp/%s.txt' % (txt_name), 'w')
for json_file_ in files:
# print(json_file_)
json_filename = json_path + json_file_ + ".json"
imagePath = json_path + json_file_ + ".jpg"
list_file.write('%s/%s\n' % (wd, imagePath))
out_file = open('%s/%s.txt' % (json_path, json_file_), 'w')
json_file = json.load(open(json_filename, "r", encoding="utf-8"))
height, width, channels = cv2.imread(json_path + json_file_ + ".jpg").shape
for multi in json_file["shapes"]:
points = np.array(multi["points"])
xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0
xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0
ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0
ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0
label = multi["label"]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
cls_id = classes.index(label)
print(json_file_)
b = (float(xmin), float(xmax), float(ymin), float(ymax))
bb = convert((width, height), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# print(json_filename, xmin, ymin, xmax, ymax, cls_id)
if __name__ == '__main__':
wd = getcwd()
classes_name = ["person","sack", "elec", "bag", "box", "um", "caron", "boot","pail"]
path = "xxxx/images/"
train_file,test_file = get_file(path,False)
json_to_txt(path,train_file,"train",classes_name)
path = “xxxx/images/” 是标注好的数据所在的目标,里面包含了原始数据和标签json文件,当运行完上面的脚本之后,在当前目录下会多出与每个图像名称相同的txt文件。

4. 添加数据到目录
在项目根目录下创建一个dataset的目录,并在dataset目录添加三个目录,分别是images,json,labels:

把数据集里面的所有图像都拷贝到dataset/images目录下,把json文件拷贝到dataset/json目录里面,把生成的txt标签文件拷贝到dataset/labels目录下。
5. 数据验证
转换完成之后,要验证数据转换是否正确:
import cv2
import os
def Xmin_Xmax_Ymin_Ymax(img_path, txt_path):
"""
:param img_path: 图片文件的路径
:param txt_path: 标签文件的路径
:return:
"""
img = cv2.imread(img_path)
# 获取图片的高宽
h,w, _ = img.shape
con_rect = []
# 读取TXT文件 中的中心坐标和框大小
with open(txt_path, "r") as fp:
# 以空格划分
lines =fp.readlines()
for l in lines:
contline= l.split(' ')
xmin = float((contline[1])) - float(contline[3]) / 2
xmax = float(contline[1]) + float(contline[3]) / 2
ymin = float(contline[2]) - float(contline[4]) / 2
ymax = float(contline[2].strip()) + float(contline[4].strip()) / 2
xmin, xmax = w * xmin, w * xmax
ymin, ymax = h * ymin, h * ymax
con_rect.append((contline[0], xmin, ymin, xmax, ymax))
return con_rect
#根据label坐标画出目标框
def plot_tangle(img_dir,txt_dir):
contents = os.listdir(img_dir)
for file in contents:
img_path = os.path.join(img_dir,file)
img = cv2.imread(img_path)
txt_path = os.path.join(txt_dir,(os.path.splitext(os.path.basename(file))[0] + ".txt"))
con_rect = Xmin_Xmax_Ymin_Ymax(img_path, txt_path)
for rect in con_rect:
cv2.rectangle(img, (int(rect[1]), int(rect[2])), (int(rect[3]), int(rect[4])), (0, 0, 255))
cv2.namedWindow()
cv2.imshow("src",img)
cv2.waitKey()
if __name__=="__main__":
img_dir = r"xxx\images"
txt_dir = r"xxx\labels"
plot_tangle(img_dir,txt_dir)
五、模型训练
1.分割数据集
在深度学习中,数据集分割的目标仍然是将数据划分为训练集、验证集和测试集,但由于深度学习模型通常具有更多的参数和复杂性,因此划分时需要考虑更多的因素。以下是深度学习数据集分割的一般步骤:
-
训练集(Training Set):
- 用于训练深度学习模型的数据集。模型通过反向传播和梯度下降等优化算法来学习数据的特征和模式。
-
验证集(Validation Set):
- 用于调整模型的超参数、选择模型和进行早停(early stopping)等操作。验证集的性能评估不影响模型的权重和参数。
-
测试集(Test Set):
- 用于最终评估模型的性能。测试集是模型未曾见过的数据,用于评估模型在真实世界中的泛化能力。
一般而言,数据集分割的比例可能是 70%-15%-15% 或 80%-10%-10%。在深度学习中通常会追求更大的数据集,因此可以有更多的数据用于训练。
数据集分割时需要注意以下几点:
-
样本均衡: 确保每个分组中的类别分布相似,以避免模型过度适应于某些特定类别。
-
随机性: 使用随机种子(例如,
random_state参数)以确保划分的重复性。 -
数据预处理一致性: 确保对数据的任何预处理步骤在所有分组上都是一致的,以防止引入不一致性。
在深度学习任务中,合适的数据集分割是构建有效模型的重要一环,可以帮助评估模型的性能、优化超参数,并准确衡量模型在未见过数据上的表现。
分割代码:
# -*- coding:utf-8 -*
import os
import random
import os
import shutil
def data_split(full_list, ratio):
n_total = len(full_list)
offset = int(n_total * ratio)
if n_total == 0 or offset < 1:
return [], full_list
random.shuffle(full_list)
sublist_1 = full_list[:offset]
sublist_2 = full_list[offset:]
return sublist_1, sublist_2
train_p="dataset/train"
val_p="dataset/val"
imgs_p="images"
labels_p="labels"
#创建训练集
if not os.path.exists(train_p):#指定要创建的目录
os.mkdir(train_p)
tp1=os.path.join(train_p,imgs_p)
tp2=os.path.join(train_p,labels_p)
print(tp1,tp2)
if not os.path.exists(tp1):#指定要创建的目录
os.mkdir(tp1)
if not os.path.exists(tp2): # 指定要创建的目录
os.mkdir(tp2)
#创建测试集文件夹
if not os.path.exists(val_p):#指定要创建的目录
os.mkdir(val_p)
vp1=os.path.join(val_p,imgs_p)
vp2=os.path.join(val_p,labels_p)
print(vp1,vp2)
if not os.path.exists(vp1):#指定要创建的目录
os.mkdir(vp1)
if not os.path.exists(vp2): # 指定要创建的目录
os.mkdir(vp2)
#数据集路径
images_dir="D:/DL/ultralytics/dataset/images"
labels_dir="D:/DL/ultralytics/dataset/labels"
#划分数据集,设置数据集数量占比
proportion_ = 0.9 #训练集占比
total_file = os.listdir(images_dir)
num = len(total_file) # 统计所有的标注文件
list_=[]
for i in range(0,num):
list_.append(i)
list1,list2=data_split(list_,proportion_)
for i in range(0,num):
file=total_file[i]
print(i,' - ',total_file[i])
name=file.split('.')[0]
if i in list1:
jpg_1 = os.path.join(images_dir, file)
jpg_2 = os.path.join(train_p, imgs_p, file)
txt_1 = os.path.join(labels_dir, name + '.txt')
txt_2 = os.path.join(train_p, labels_p, name + '.txt')
if os.path.exists(txt_1) and os.path.exists(jpg_1):
shutil.copyfile(jpg_1, jpg_2)
shutil.copyfile(txt_1, txt_2)
elif os.path.exists(txt_1):
print(txt_1)
else:
print(jpg_1)
elif i in list2:
jpg_1 = os.path.join(images_dir, file)
jpg_2 = os.path.join(val_p, imgs_p, file)
txt_1 = os.path.join(labels_dir, name + '.txt')
txt_2 = os.path.join(val_p, labels_p, name + '.txt')
shutil.copyfile(jpg_1, jpg_2)
shutil.copyfile(txt_1, txt_2)
print("数据集划分完成: 总数量:",num," 训练集数量:",len(list1)," 验证集数量:",len(list2))
2.指定数据集路径
在ultralytics/cfg/datasets目录下复制一份coco.yaml复制ultralytics根目录,重新命名成my_coco.yaml,然后把文件内容改成自己的数据路径和自己所标注的数据名称。
# Ultralytics YOLO , AGPL-3.0 license
# COCO8 dataset (first 8 images from COCO train2017) by Ultralytics
# Example usage: yolo train data=coco8.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco8 ← downloads here (1 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/DL/ultralytics # dataset root dir
train: dataset/train # train images (relative to 'path') 4 images
val: dataset/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes
names:
0: person
1: sack
2: elec
3: bag
4: box
5: um
6: caron
7: boot
8: pail
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco8.zip
3.模型训练
模型训练有两种方式,直接pip安装ultralytics库的和源码安装的训练方法有差异。
3.1 直接安装ultralytics库
单卡
yolo detect train data=my_coco.yaml model=yolov8s.pt epochs=150 imgsz=640 batch=64 workers=0 device=0
多卡训练
yolo detect train data=my_coco.yaml model=./weights/yolov8s.pt epochs=150 imgsz=640 batch=128 workers= \'0,1,2,3\' device=0,1,2
3.2 源码安装训练方法
在根目录下新建一个train.py的文件
from ultralytics import YOLO
#train
model = YOLO('my_coco.yaml').load('yolov8s.pt') # build from YAML and transfer weights
# Train the model
model.train(data='./ultralytics/datasets/my_coco.yaml', epochs=150, imgsz=640,batch=2, workers=0)
4. 验证训练结果
在yolo环境下运行下面指令,用来验证训练的结果:
yolo task=detect mode=predict model=last.pt source='1.jpg' show=True

六、模型ONNX推理部署
关于模型推理部署,可以看我之前的博客:https://blog.csdn.net/matt45m/article/details/134221201?spm=1001.2014.3001.5502