【重学c++primer】第二章 深入浅出:变量的类型
文章目录
- 【重学c++primer】第二章 变量以及变量的基本类型
- 1、从初始化/赋值语句说起
- 2、类型详解
-
- 一些未定义部分
- 字面值
- 变量以及变量的类型
- 隐式类型转换
- 3、复合类型:从指针到引用
-
- 指针的操作
- void*
- 指针的好处
- 引用
- 指针的引用
- 4、常量和常量表达式类型
-
- const和指针
- const的赋值
- 常量表达式
- 5、类型别名和类型的自动推导
-
- 类型别名
- 类型的自动推导
-
- auto
-
- 类型退化
- decltype(val)
-
- 不会发生类型退化
- 左值加引用
- 变量名称
- c++14的优化
- c++20
- 6、域和对象的声明周期
【重学c++primer】第二章 变量以及变量的基本类型
1、从初始化/赋值语句说起
初始化 / 赋值语句是程序中最基本的操作,其功能是将某个值与一个变量关联起来
- 值:字面值、对象(变量或常量)所表示的值……
- 标识符:变量、常量、引用……
- 初始化基本操作:
- 在内存中开辟空间,保存相应的数值
- 在编译器中构造符号表,将标识符与相关内存空间关联起来
- 值与对象都有类型
- 初始化 / 赋值可能涉及到类型转换
2、类型详解
类型是编译期的概念,在可执行文件中并没有,也就是说类型是语言的东西,而不是操作系统的东西。那有一个疑问就是为什么要引入类型的概念?
其实是为了更好的描述程序,防止误用,具体为:
- 内存空间:一个类型占据了多大的内存空间,可以使用sizeof查看一个类型的尺寸,比如说笔者的环境下int占4个字节,char占1个字节
- 取值范围:在c++中,可以用
std::numeric_limits的一些api获取一个类型的边界数值。比如说char,一个字节,对应8个bit,可以有2^8种数,无符号的情况下是0~63,一旦定义了一个数据类型,那么存储的数值范围就确定下来了,一旦发生上溢或者下溢,就等价于取模运算。比如说无符号int,那么最大数值是4G-1,如果还加1,就会模4G-1,最终值为0,背后原理其实就是进位被舍弃了 - 对齐信息:当你定义一个int类型的变量的时候,系统会开辟连续的4个字节,但是操作系统读取数据是根据地址总线的位数,比如说64位机器就可以一次性读64位,8个字节。如果没有字节对齐,假设某个int变量放在了710,操作系统第一次会读取到07,第二次读取815,也就是说,操作系统要读取两次IO才能读取这个数据,但是如果是放在03,那么一次就会命中,性能的差别就体现出来了。可以使用
alignof获取对齐信息
一些未定义部分
- char是否有符号:影响可移植性
- 整数在内存中的保存方式:大端和小端,影响可移植性
- 每种类型的大小:影响可移植性
特别的,unsigned和unsigned int是等价的,因为int太常用了
字面值
字面值:在程序中直接表示为一个具体数值或字符串的值
整数:20(十进制),024(8进制),0x14(十六进制),
浮点数:1.3,1e8
字符字面值:‘c’,‘\n’,‘\x4d’
字符串字面值:“hello”
布尔字面值:true/false
指针字面值:nullptr(nullptr_t类型)
当你使用1.3或者1e8的时候,就是double类型,但是如果想直接是float的话,可以1.3f,这样就直接的表示了1.3是float类型的浮点数,在c++11中,可以使用operator “” _w来自定义后缀,例如:
#include
using namespace std;
// _w可以自定义,笔者定义成了iii,一个名字罢了
// 形参类型是有限制的,具体可以看一些文档
int operator "" iii(long double x)
{
// 类型转换
return static_cast(x) * 2;
}
int main()
{
int x = 3.14iii;
cout << x << endl;
return 0;
}
变量以及变量的类型
变量:对应了一段存储空间,可以改变其中内容
变量的类型在首次声明/定义的时候指定
变量声明和定义的区别:extern前缀
值得注意的是,当你使用extern声明一个变量的时候,注意不能有初始值,不然就变成了定义一个变量而不是声明
变量的初始化和赋值
初始化:构造变量之初为其赋予初始的值
初始化分为:缺省初始化、直接/拷贝初始化和其他初始化
赋值:修改变量所保存的数值
隐式类型转换
特别的,留心隐式类型转换以及发生的场景,如:
#include
using namespace std;
int main()
{
int x = -1;
unsigned int y = 3;
cout << (x < y) << endl;
return 0;
}
在我们的认知中,-1小于3,但是实际输出0,也就是false,违背了-1小于3的数学认知,原因就是因为发生了隐式的类型转换,使得int的-1转换成无符号的int,而转换后的结果是一个非常大的正整数,因此结果为假
还有一些其他的转换,比如说int赋值给double,double赋值给int,int类型和bool类型的关系比较都会发现类型转换
对此,c++20提供了cmp_equal,cmp_less,cmp_greater之类的api,进行比较,这样就可以避免发生隐式类型转换的发生导致错误的结果
3、复合类型:从指针到引用
指针本身的内存占用取决于机器是32还是64,如果是64,那么要表示一个地址就要64bit,也就是8个字节,那么显然指针就必须要占用8个字节的大小,同理32位要占用4个字节
关于指针的解引用,操作系统会根据指针指向的地址来访问对应的地址,但是一个很明显的问题是,怎么知道要访问多大的地址?也就是根据指针的类型,比如int*只能访问int大小的内存地址空间,所以才会要求指针的类型和指向的变量的类型匹配
指针的操作
- 取地址/解引用
- 对指针加减:移动指针的位置,如:
int x = 42;
int *p = &x;
p = p + 1;
p就相当于往后移动了一个int的内存地址大小,也就是往后移动了4个字节,所以对指针的加减就是移动指针指向类型的内存大小
- 指针之间的减:一般为指向一个数组的两个指针之间的距离
- 判等:如:== 表示两个指针指向的地址是否相同。还有!=,注意不要用<、>、<=、>=,因为这涉及到内存分配的问题,如果要比较两个指针之间的大小,其实就是看变量被分配的地址,如果非要比较,请在类似于
指向一个数组的两个指针这样的场景进行比较
特别的,要留意指针和bool类型的转换,非空指针会被转换为true,反之为false
void*
由于都是指针类型,因此占用的内存大小是一致的,所以可以认为任何指针类型转换为void*都是允许的,同理,void*转换为任何指针类型也是允许的。
但是void*丢弃了一些信息,如:
#include
using namespace std;
void func(void* param)
{
// 非法
// cout << param + 1<< endl;
}
int main()
{
int x = -1;
int* p = &x;
cout << p << endl;
cout << p + 1 << endl;
func(p);
return 0;
}
可以看出,正常指针是允许执行对指针的加减操作的,但是对于void*指针,编译器不明白void*类型的加减到底该往后移动多少个字节,因此会报错,当然这更多还是取决于编译器,如在gcc里:
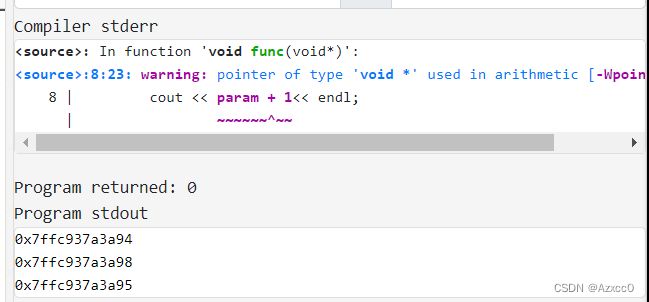
在gcc里是可以编译且执行的,并且是往后了1个字节,但是gcc也给出了警号,我们要知道这其实是不合法的行为
指针的好处
指针指向了一个变量,是对一个变量的间接使用,那这种间接有什么好处呢?为什么不直接使用原变量呢?
答案是:减少传输成本
对象的大小不同,但是指针的大小是一致的,也就是说,复制一份变量的成本是不确定的,并且往往是大于指针的成本,如:
#include
using namespace std;
void func(int x)
{
}
int main()
{
int x = -1;
func(x);
return 0;
}
以上的demo看出,函数的形参是一个整型的变量,当发生函数调用的时候,就会拷贝出一个临时变量,然后再用临时变量来赋值给形参,这是非常低性能的,以上的demo只是一个整型的,但是如果是某个对象,那么代价就非常大,更何况一些数据类型可能会不支持复制操作,是独占的。所以这些情况下可以求助于指针,如:
#include
using namespace std;
void func(int *x)
{
}
int main()
{
int x = -1;
int* p = &x;
func(p);
return 0;
}
指针的优缺点:
- 指针支持拷贝
- 指针仅占4/8个字节,拷贝成本低(但是还是拷贝)
- 读/写成本更高,涉及到解引用
- 可能会对对原变量的修改,也就是值传递和地址传递,函数里对普通变量的修改不会影响到实参,但是传指针会
引用
- 是对象的别名,但是不能绑定字面值
- 构造时绑定,也就是必须要初始化,并且在生命周期内不能绑定到其他对象上
- 不存在空引用,但是可能存在非法引用
- 属于编译时期概念,底层还是通过指针来实现
非法引用demo:返回局部变量的引用
int& func()
{
int x;
return x;
}
指针的引用
#include
using namespace std;
int main()
{
int x = -1;
int* p = &x;
// 指针的引用
int*& ref = p;
return 0;
}
对于复杂类型采用从右到左,因此ref先看出来是一个引用,引用什么类型的对象呢?看到*符号,因此可以看出,ref绑定到int*类型上
那么一个问题就是:是否存在引用的引用?
变量是一个对象,可以有引用,指针终归还是对象的一种,因此可以有引用
答案是不可以的:因为引用并不是对象,只是一个别名
4、常量和常量表达式类型
常量和变量相对,表示一个不可修改的值
常量是编译时期的概念,编译器利用其来防止非法操作和进行优化程序逻辑
非法操作比如说if语句里误把==写成了=,优化程序可以理解为
int x = 4;
const int y = 4;
int z = x + 1; // 编译器要进行一次内存访问
int u = y + 1; // 编译器可以直接在编译时期求出5,然后赋值给U
const和指针
这里可以补充的看看c++primer第二章
顶层const:本身不能被修改
底层const:指向的对象不能被修改
如果理解不了const修饰指针是造成底层const还是顶层const,可以看看浙大翁凯的c语言进阶教程p15指针的使用
这里就不多解释,以后可能会专门出一个博客解释一下,但是也只是重复c++primer或者翁凯视频的内容
const的赋值
int x =4;
// 发生了隐式的类型转换
// 从int 到const int
// 合理的,因为是增加了限制,可读可写变成了只能读
// 反过来不合理,因为是从const int 到int的转换
const int *ptr = &x;
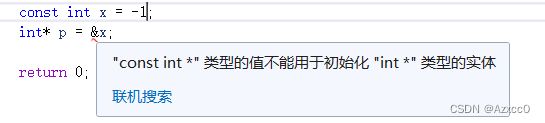
结论就是底层const不支持赋值,如:
#include
using namespace std;
// 本例非法
// 从可读到可读可写的转换
int main()
{
const int x = -1;
int* p = &x;
return 0;
}
常量的引用
#include
using namespace std;
int main()
{
int x = 3;
const int& ref = x;
return 0;
}
常量引用的主要用途是用于函数的形参,具有引用的特性避免拷贝的损耗,同时又只读
可能会有人有疑问,这样的工作指针也可以完成,那么,为什么使用常量引用呢?
- 指针需要考虑非法问题,在被调用函数的地方要常常对指针的有效性进行判断
特别的,常量引用可以绑定字面值,普通的引用是不可以绑定到字面值上的,原因其实不是因为const,而是历史,C程序员习惯传参的时候传字面值,所以c++特别规定了常量引用可以绑定到字面值
常量表达式
#include
using namespace std;
int main()
{
int x = 3;
cin >> x;
const int y1 = x;
const int y2 = 3;
return 0;
}
看上去y1和y2的类型都是一样的,但是其实y1和y2有本质的区别,因为y1绑定到变量x上,所以y1是动态绑定的,y2却是静态绑定的,也就是编译期就确定了的
这样有什么结果呢?加入有如下的代码块
if (y1 == 3)
{
}
if (y2 == 3)
{
}
y1是动态绑定的,也就是说编译器在遇到if语句的时候只能老老实实的编译一遍,根据y1实际的值决定程序流程,而y2则会直接优化,删除If的判断,然后展开if的语句块,或者一些其他的优化手段
因此,c++11引入了constexpr,用于主动提供给编译器优化
特别的,当你给出如下表达式的时候
constexpr const int* ptr = nullptr;
ptr的类型其实就是const int* const类型,ptr指向了const int*,本身又是const的
也就是说constexpr是修饰指针本身的,而不是指针所指的对象,也就是说constexpr不是修饰类型的关键字
5、类型别名和类型的自动推导
类型别名
可以为类型引入别名,让类型更加方便的使用,如size_t因为unsigned int的长度各家实现并不相同,所以size_t实际实现并不但是,只要你使用的是size_t,那么就是可以移植的
使用别名的方式
- typedef :
typedef int MyInt; - using:
using MyInt = int;(c++11引入)
以上方法使用using 更好,因为更加友好,如
typedef char MyCharArr[4];
using MyCharArrr = char[4];
可以看出,using 更加直观
特别的,类型别名并不是简单的替代,如:
#include
using namespace std;
// 合法
int main()
{
int x = 3;
const int* ptr = &x;
int y = 2;
ptr = &y;
return 0;
}
#include
using namespace std;
using IntPtr = int*;
// 非法
int main()
{
int x = 3;
const IntPtr ptr = &x;
int y = 2;
ptr = &y;
return 0;
}
对于第一个demo,不能修改指针所指向的内存空间,但是可以修改指针本身,但是第二个却变成了不能修改指针本身,可以修改指针所指向的地址空间,也就是变成了int *const ptr从底层const变成了顶层const,第二个demo的const从修饰int *ptr变成了修饰ptr
特别的,不能利用类型别名构造引用的引用
类型的自动推导
通过初始化来推导变量的类型,但是自动类型推导并不意味着c++变成了弱类型的语言
自动推导的常见形式:
● auto: 最常用的形式,但会产生类型退化
● const auto / constexpr auto: 推导出的是常量 / 常量表达式类型
● auto& : 推导出引用类型,避免类型退化
● decltype(exp) :返回 exp 表达式的类型(左值加引用)
● decltype(val) :返回 val 的类型
● decltype(auto) :从 c++14 开始支持,简化 decltype 使用
● concept auto :从 C++20 开始支持,表示一系列类型( std::integral auto x = 3; )
auto
类型退化
类型退化涉及到一个变量作为左值和右值类型可能会发生一些改变,如
#include
#include
using namespace std;
int main()
{
int x = 1;
int& ref = x; // ref是int&
ref = 3; // ref是int&
int y = ref; // ref此时是int
auto ref2 = ref; // 此时ref2是int
const int n = 1; // n是const int
auto m = n; // n此时是int ,y是int,顶层const 被舍弃
return 0;
}
我们的初衷是定义一个引用,但是因为类型退化,r整型引用退化为整型,所以ref2的类型是整型
常见典型的类型退化有:
- 引用退化,如上面的例子
- const退化,如const int& -> int
- 数组退化为指针
如何证明呢?如:
#include
#include
using namespace std;
int main()
{
int x = 1; // x是int
int& ref = x; // ref是int&,x是int
ref = 3; // ref是int&
int y = ref; // ref此时是int
auto ref2 = ref; // 此时ref2是int
// 输出1,证明了ref2的类型就是int
cout << is_same_v << endl;
return 0;
}
以上,要留心auot类型推导的类型退化,所以采用其他的一些关键词进行补充的修饰,如有:
- const auto
- auto&
- constexpr auto :等价于const auto
- const auto &
特别的,一旦有auto&,推导出引用类型,会避免发生类型退化,也就是不会发生类型退化,验证如下:
#include
#include
using namespace std;
int main()
{
const int x = 1;
auto& y = x;
// 输出1,表示const属性并没有被丢弃,那么反推出来,x就是const int
cout << is_same_v << endl;
return 0;
}
再看一个demo
#include
#include
using namespace std;
int main()
{
int x[3] = { 0 }; // x是int x[3]类型
auto x1 = x; // x被退化为指针
// 输出1,表示x1的类型是int*,反推出x的类型是指针
cout << is_same_v << endl;
return 0;
}
验证如下:
#include
#include
using namespace std;
int main()
{
int x[3] = { 0 }; // x是数组
auto& x1 = x; // x被退化为指针
// 输出0,表示x1的类型不是int*,反推出x的类型并没有退化
cout << is_same_v << endl;
// 输出1,表示x1的类型是int(&)[3],反推出x的类型没退化
cout << is_same_v << endl;
return 0;
}
decltype(val)
不会发生类型退化
返回表达式类型,如:
#include
#include
using namespace std;
int main()
{
// 让编译器依据0.3 + 3L的结果推导x的类型
auto x = 0.3 + 3L;
// 获得0.3 + 3L表达式结果的类型,用此类型定义x
decltype(0.3 + 3L) x = 3.5 + 3L;
return 0;
}
这样子看上去似乎是和auto没啥区别,其实是有的,就是decltype不会产生类型退化,验证如下:
#include
#include
using namespace std;
int main()
{
int x = 3;
int& y1 = x; // y1此时的类型是int &
auto y2 = y1; // y1此时是int,发生了类型退化
decltype(y1) y3 = y1; // y1此时是int &,没有发生类型退化
// 输出1,表示y3并没有发生类型退化
cout << is_same_v << endl;
// 输出1,发生了类型退化
cout << is_same_v << endl;
return 0;
}
auto可以加一个引用&,避免类型退化,但是会额外带上引用类型,有时候这是我们不想要的
左值加引用
我们正常使用decltype的时候,形如:decltype(expression)
如果表达式是一个右值,那没有任何问题,但是如果表达式是一个左值,那么会额外加上一个引用
#include
#include
using namespace std;
int main()
{
int x = 3;
int* ptr = &x;
*ptr = 4; // ptr作为左值使用,把ptr指向的地址空间的内容更改为4
// 输出1,表示decltype附加上了一个引用
cout << is_same_v << endl;
return 0;
}
本demo可能让人有些不解
- x是int类型,左值
- ptr是int *类型,左值
- *ptr是int类型,左值
所以,符合表达式如果是一个左值,那么会自动加上引用类型,因此,*ptr就是int&类型
这样看来是不是没有任何疑惑,很符合我们的结论,但是咋一看似乎是很对,因为我并没有指出不对的地方
答案揭晓:
#include
#include
using namespace std;
int main()
{
int x = 3;
int* ptr = &x;
decltype(x); // 推导出int 类型,x是左值
decltype(*ptr); // 推导出int &类型,*ptr是左值
return 0;
}
大家都是左值,为啥一个有引用,一个没有?
变量名称
上一个demo类型不一致的原因其实就是因为x是一个变量的名称,*ptr是一个表达式
有人可能会反驳,哎呀你说的不对,x单单拿出来也可以是表达式,但是*ptr更一般,更符合表达式的特征,是变量+操作符
所以完整的结论就是,如果是右值,就啥类型推导出啥类型,如果是一个变量,那么同右值,如果是一个表达式,那么会发生附加引用
下面测验一下你对decltype的掌握程序,如果可以全解释清楚,那么就勉强合格
#include
#include
using namespace std;
int main()
{
int x = 3;
int* ptr = &x;
const int y1 = 3;
const int& y2 = y1;
以下全输出1
cout << is_same_v << endl;
cout << is_same_v << endl;
cout << is_same_v << endl;
cout << is_same_v << endl;
cout << is_same_v << endl; // 右值
cout << is_same_v << endl;
cout << is_same_v << endl;
cout << is_same_v << endl;
cout << is_same_v << endl; // 即使y1不能放在等号的左边,但是也被视作左值
cout << is_same_v << endl; // 因为没有引用的引用,因此推导出来还是const int&
// 小题一下,大概可以理解为可以访问内存的是左值,不可以的是右值
return 0;
}
c++14的优化
#include
#include
using namespace std;
int main()
{
// 啰嗦
decltype(3.5 + 3L) x = 3.5 + 3L;
// 简洁
decltype(auto) y = 3.5 + 3L;
return 0;
}
c++20
concept auto:表示一系列的类型
一系列的意思就是,int、short、long 、long long 属于intergral类型
float、double、long double属于一种concept,是浮点数类型的
#include
#include
// 需要引用头文件
#include
using namespace std;
// 记得打开c++20的标准
int main()
{
integral auto y = 3;
cout << is_same_v << endl;
return 0;
}
这有什么用呢?
其实是限制类型推导在某个类型的范围,比如说上面这个demo的y,一定会被限制为整型,如果初值为浮点数就会报错
6、域和对象的声明周期
域(scope表示程序中的一部分
- 全局域:程序最外围的域,其中定义的对象是全局对象
- 块域:使用大括号所限定的域,其中定义的对象是局部对象
- 还存在其它的域:类域,名字空间域……
- 域可以嵌套,嵌套域中定义的名称可以隐藏外部域中定义的名称
- 对象的生命周期起始于被初始化的时刻,终止于被销毁的时刻
特别的,通常来说
– 全局对象的生命周期是整个程序的运行期间
– 局部对象生命周期起源于对象的初始化位置,终止于所在域 被执行完成
关于生命周期的概念,是非常有用的,对于c++的程序员来说可以精准的控制一个对象的生命周期
关于生,以下的代码只会输出1,因为main函数里先执行到了cout语句,此时后续的x还没被定义出来,所以只会输出全局的x
#include
#include
using namespace std;
int x = 1;
int main()
{
cout << x << endl;
int x = 2;
return 0;
}
关于消亡,某个对象包含个资源,比如说某个socket代表了某个连接,当对象被销毁的时候,代表着它的资源被释放,也就是其他的对象可以使用此资源
再比如,文件有一个缓冲区,执行写操作的时候,实际并不会马上执行写操作,而是缓冲区满或者对象消亡了才会实际的执行写操作
这样的优缺点
- 需要程序员事无巨细的控制对象的生命周期
- 性能得到极大的提升