并行计算机系统结构基础
一、并行计算机系统结构
1.并行性
并行性:计算机系统在同一时刻或者同一时间间隔内 进行多种运算或操作
并行性包括两方面的含义
- 同时性:两个或两个以上的事件在同一时刻发生
- 并发性:两个或两个以上的事件在同一时间间隔 内发生
从处理数据的角度来看,并行性等级从低到高可分为
- 字串位串:每次只对一个字的一位进行处理(串行处理,不存在并行性)
- 字串位并:同时对一个字的全部位进行处理,不 同字之间是串行的 (开始出现并行性)
- 字并位串:同时对许多字的同一位(称为位片) 进行处理( 具有较高的并行性)
- 全并行:同时对许多字的全部位或部分位进行处理(最高一级的并行)
从执行程序的角度来看,并行性等级从低到高可分为:
- 指令内部并行:单条指令中各微操作之间的并行
- 指令级并行(Instruction Level Parallelism,ILP):并行执行两条或两条以上的指令
- 线程级并行(Thread Level Parallelism,TLP):并行执行两个或两个以上的线程 (通常是以一个进程内派生的多个线程为调度单位)
- 任务级或过程级并行:并行执行两个或两个以上 的过程或任务(程序段)(以子程序为调度单位 )
- 作业或程序级并行:并行执行两个或两个以上的 作业或程序
2.并行计算机系统结构
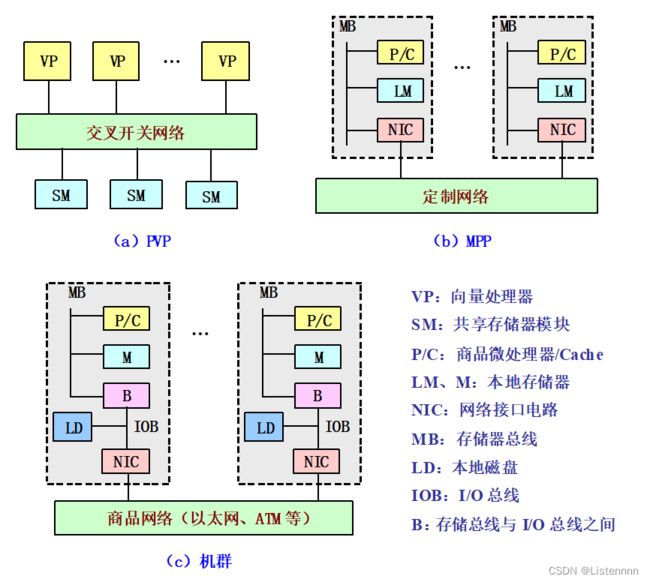
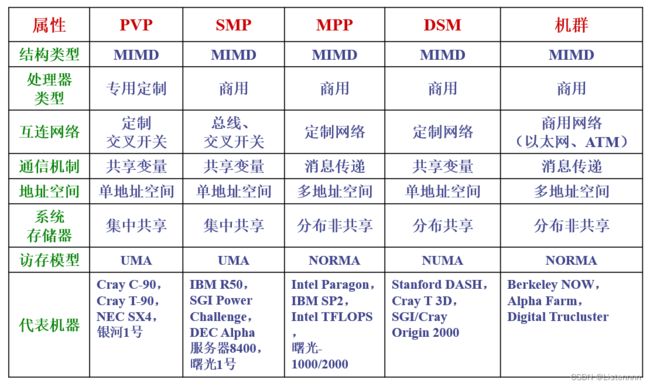
目前流行的高性能并行计算机系统结构通常可以分成以下5类
- 并行向量处理机(PVP,Parallel Vector Processor)
- 对称式共享存储器多处理机(SMP,Symmetric Multi-Processing)(这里的共享指的是共享同一个物理存储器)
- 分布式共享存储器多处理机(DSM,Distributed Shared Memory)(注意:这里的“共享”是指地址空间的共享,并非是只具有一个集中的存储器,不同处理器上的同一个物理地址指向的是同一个存储单元)
- 大规模并行处理机(MPP,Massive Parallel Processor)
- 机群计算机(Cluster)
3.机群系统
因其低廉的价格、极强的灵活性和可缩放性 成为近年来发展势头最为强劲的系统结构。所以下面着重介绍一下机群系统

机群系统的硬件
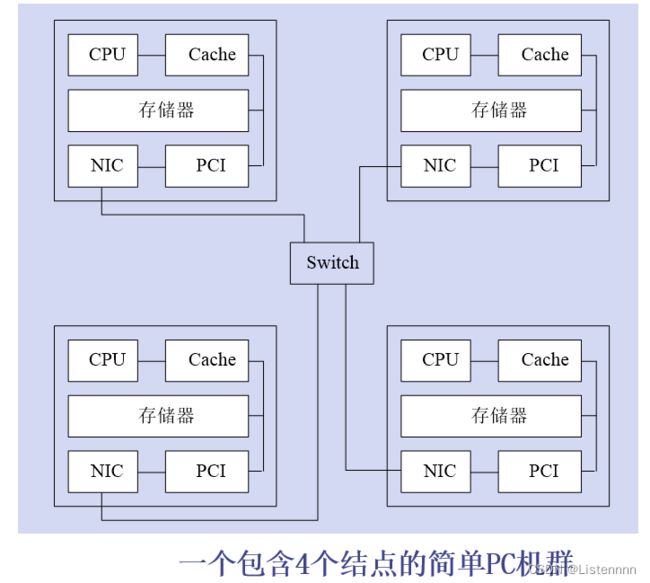

- 构成机群的每台计算机都被称为一个结点
- 机群的各个结点一般通过商品化网络连接在一起
- 网络接口与结点的I/O总线以松散耦合的方式相连

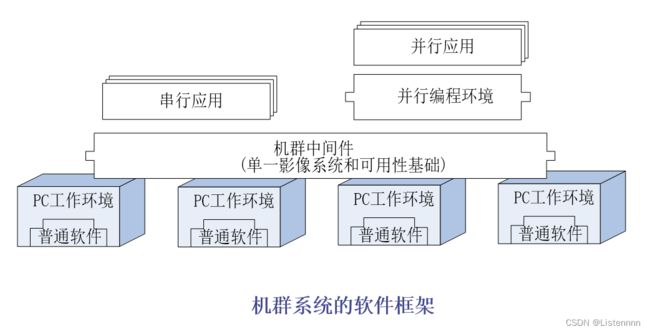
机群系统的软件
机群操作系统:在各结点的操作系统之上建立一层操作系统来管理整个机群
机群操作系统的功能:提供硬件管理、资源共享以及网络通信,还有一个最重要的功能是实现单一系统映象(Single System Image,SSI),它机群的一个重要特征

机群系统中的SSI至少应该提供以下三种服务


机群系统的特点




机群系统的分类

高可用机群

负载均衡机群
负载均衡机群适用于提供静态数据的服务;而高可用性机群既适用于提供静态数据的服务,又适用于提供动态数据的服务

高性能计算机群

按照构建方式将机群分类
机群系统中的异构结点指的是由不同类型或者配置的计算节点组成的机群系统。这些节点可以是不同的处理器架构、存储器大小或者网络性能等方面存在着差异。由于异构节点的存在,机群节点间的通信和任务分配需要通过一定的调度算法和框架来进行管理和协调,以达到系统整体性能的最优化

4.分布式计算的三个核心问题
- 垂直扩展和水平扩展的选择问题
- 如何保持高可用性(High Availability)
- 一致性问题(Consistency)
Web服务器有两种增强服务性能的方式:第一个选择是升级现在这台服务器的硬件,使用更多cpu和更大的内存,这样的选择我们称之为垂直扩展(Scale Up)。第二个选择则是我们再租用一台和之前一样的服务器。这样的选择我们称之为水平扩展(Scale Out)
一旦开始采用水平扩展,我们就会面临在软件层面改造的问题了。也就是我们需要开始进行分布式计算了。我们需要引入负载均衡(Load Balancer)这样的组件,来进行流量分配。我们需要拆分应用服务器和数据库服务器,来进行垂直功能的切分。我们也需要不同的应用之间通过消息队列,来进行异步任务的执行。
所有这些软件层面的改造,其实都是在做分布式计算的一个核心工作,就是通过消息传递(Message Passing)而不是共享内存(Shared Memory)的方式,让多台不同的计算机协作起来共同完成任务
理解高可用性和单点故障
1 核变 2 核的这种垂直扩展的方式,扩展完之后,我们还是只有 1 台服务器。如果这台服务器出现了一点硬件故障,比如,CPU 坏了,那我们的整个系统就坏了,就不可用了
如果采用了水平扩展,即便有一台服务器的 CPU 坏了,我们还有另外一台服务器仍然能够提供服务。负载均衡能够通过健康检测(Health Check)发现坏掉的服务器没有响应了,就可以自动把所有的流量切换到第 2 台服务器上,这个操作就叫作故障转移(Failover),我们的系统仍然是可用的
垂直拓展是不可持续的,归根到底,我们一定要走上水平扩展的路径
系统的可用性(Avaiability)指的就是,我们的系统可以正常服务的时间占比
有些系统可用性的损失,是在我们计划内的。比如上面说的停机升级,这个就是所谓的计划内停机时间(Scheduled Downtime)。有些系统可用性的损失,是在我们计划外的,比如一台服务器的硬盘忽然坏了,这个就是所谓的计划外停机时间(Unscheduled Downtime)
之所以会出现这个问题,是因为在这个场景下,任何一台服务器出错了,整个系统就没法用了。这个问题就叫作单点故障问题(Single Point of Failure,SPOF)。这个假设特别糟糕。我们假设这 1000 台服务器,每一个都存在单点故障问题。所以,我们的服务也就特别脆弱,随便哪台出现点风吹草动,整个服务就挂了
要解决单点故障问题,第一点就是要移除单点。其实移除单点最典型的场景,在我们水平扩展应用服务器的时候就已经看到了,那就是让两台服务器提供相同的功能,然后通过负载均衡把流量分发到两台不同的服务器去。即使一台服务器挂了,还有一台服务器可以正常提供服务
不过光用两台服务器是不够的,单点故障其实在数据中心里面无处不在。我们现在用的是云上的两台虚拟机。如果这两台虚拟机是托管在同一台物理机上的,那这台物理机本身又成为了一个单点。那我们就需要把这两台虚拟机分到两台不同的物理机上
不过这个还是不够。如果这两台物理机在同一个机架(Rack)上,那机架上的交换机(Switch)就成了一个单点。即使放到不同的机架上,还是有可能出现整个数据中心遭遇意外故障的情况
面对这种情况,我们就需要设计进行异地多活的系统设计和部署。所以,在现代的云服务,你在买服务器的时候可以选择服务器的 area(地区)和 zone(区域),而要不要把服务器放在不同的地区或者区域里,也是避免单点故障的一个重要因素
只是能够去除单点,其实我们的可用性问题还没有解决。比如,上面我们用负载均衡把流量均匀地分发到 2 台服务器上,当一台应用服务器挂掉的时候,我们的确还有一台服务器在提供服务。但是负载均衡会把一半的流量发到已经挂掉的服务器上,所以这个时候只能算作一半可用。想要让整个服务完全可用,我们就需要有一套故障转移(Failover)机制。想要进行故障转移,就首先要能发现故障
以我们这里的 PHP-FPM 的 Web 应用为例,负载均衡通常会定时去请求一个 Web 应用提供的健康检测(Health Check)的地址。这个时间间隔可能是 5 秒钟,如果连续 2~3 次发现健康检测失败,负载均衡就会自动将这台服务器的流量切换到其他服务器上。于是,我们就自动地产生了一次故障转移。故障转移的自动化在大型系统里是很重要的,因为服务器越多,出现故障基本就是个必然发生的事情。而自动化的故障转移既能够减少运维的人手需求,也能够缩短从故障发现到问题解决的时间周期,提高可用性
在这种情况下,我们其实只要有任何一台服务器能够正常运转,就能正常提供服务。
在实际情况中,可用性没法做到那么理想的地步。光从硬件的角度,从服务器到交换机,从网线连接到机房电力,从机房的整体散热到外部的光纤线路等等,可能出现问题的地方太多了。这也是为什么,我们需要从整个系统层面,去设计系统的高可用性
服务器硬件的损坏只是可能导致可用性损失的因素之一,机房内的电力、散热、交换机、网络线路,都有可能导致可用性损失。而外部的光缆、自然灾害,也都有可能造成我们整个系统的不可用
二、SIMD技术
- MMX和SSE的指令集就是单指令多数据流(Single Instruction Multiple Data)技术的实现
- MMX(Multi Media eXtension,多媒体扩展指令集)指令集是Intel公司于1996年推出的一项多媒体指令增强技术。MMX指令集中包括有57条多媒体指令,通过这些指令可以一次处理多个数据
- MMX指令并没带来3D游戏性能的显著提升,故推出SSE指令, 并陆续推出SSE2、SSE3、SSSE3和SSE4等采用SIMD技术的指 令集,这些统称为SSE指令集
- SSE指令集将80位浮点寄存器扩充到128位多媒体扩展通用寄存 器XMM0~XMM7,可同时处理16个字节,或8个字,或4个双 字(32位整数或单精度浮点数),或两个四字的数据 。从SSE2开始,还支持128位整数运算,或同时并行处理两个64位 双精度浮点数
- 如果是一个多核 CPU 呢,那么它同时处理多个指令的方式可以叫作 MIMD,也就是多指令多数据(Multiple Instruction Multiple Data)
执行向量运算时,SIMD指令能快很多,因为SIMD在获取数据和执行指令的时候,都做到了并行。从内存里面读取数据的时候,SIMD是一次性读取多个数据。在数据读取到了之后,在指令的执行层面,SIMD也是可以并行进行的。4 个整数各自加1,互相之前完全没有依赖,也就没有冒险问题需要处理。只要 CPU 里有足够多的功能单元,能够同时进行这些计算,这个加法就是4路同时并行的
对于那些在计算层面存在大量数据并行(Data Parallelism)的计算中,使用 SIMD 是一个很划算的办法。在这个大量的数据并行,其实通常就是实践当中的向量运算或者矩阵运算。在实际的程序开发过程中,过去通常是在进行图片、视频、音频的处理。最近几年则通常是在进行各种机器学习算法的计算
SIMD技术配合超线程技术:同一个向量的不同维度之间的计算是相互独立的。而超线程 CPU 里的寄存器,又能放得下多条数据。于是,我们可以一次性取出多条数据,交给 CPU 并行计算