Flink的RocksDBStateBackend一些使用经验
Flink的RocksDBStateBackend一些使用经验
一、idea依赖
RocksDBStateBackend是Flink中内置的第三方状态管理器,和其他两种(MemoryStateBackend和FsStateBackend)不同,使用时需添加相关依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.7.0</version>
</dependency>
二、flink配置文件
1.全局配置:
flink可以通过flink-conf.yaml 配置原因全局配置state backend。
使用 state.backend 选项进行state backend类型配置:可选值包括: jobmanager (MemoryStateBackend), filesystem (FsStateBackend), rocksdb (RocksDBStateBackend)。
使用state.checkpoints.dir选项设置checkpoints数据和元数据文件。
要打开它可以在flink-conf.yaml中配置:
# The backend that will be used to store operator state checkpoints
state.backend: rocksdb
# Directory for storing checkpoints
state.checkpoints.dir: hdfs://JT-1-60:9000/statebackend/rocksDB
Hdfs地址:hdfs://JT-1-60:9000/statebackend/rocksDB
#开启增量checkpoints机制
state.backend.incremental: true
一些配置参数及注释:
state.backend.rocksdb.checkpoint.transfer.thread.num: 1
#本地存储地址,在task节点上
state.backend.rocksdb.localdir: /opt/rockdb/flink/checkpoints
state.backend.rocksdb.timer-service.factory: HEAP
state.backend.rocksdb.checkpoint.transfer.thread.num: 用于指定同时可以操作RocksDBStateBackend的线程数量,默认是1,如果状态量比较大可以将此参数适当增大。
state.backend.rocksdb.localdir:用于指定RocksDB存储状态数据的本地文件路径,在每个TaskManager提供该路径节点中的状态存储。
state.backend.rocksdb.timer-service.factory:用于指定定时器服务的工厂类实现类,默认为“HEAP”,也可以指定为“RocksDB”
将配置选项设置state.backend.rocksdb.timer-service.factory为heap(而不是默认值rocksdb)以将计时器存储在堆上。
注意:标红为必配配置。
2.单任务配置
![]()
官方建议是配置全局的状态后端管理,若配置单任务(通过env.setStateBackend(…)单独调整state backend配置)这种方式会覆盖全局配置。
三、一些踩坑的总结
1.开启检查点

2.单任务配置已过时,不推荐使用,本地运行会报错,所以使用时放到集群运行,配置全局配置。
3.关于配置profile文件
参照官网解读,整合hadoop的使用大致如下
(https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/deployment/hadoop.html)
为了使用Hadoop功能(例如YARN,HDFS),必须为Flink提供所需的Hadoop类,因为默认情况下未捆绑这些类。
这可以通过以下步骤来完成:
1)将Hadoop类路径添加到Flink
2)将所需的jar文件放入Flink发行版的/ lib目录中
选项1)只需很少的工作,可以与现有的Hadoop设置很好地集成在一起,应该是首选方法。但是,Hadoop的依赖项占用量很大,这增加了发生依赖项冲突的风险。如果发生这种情况,请参阅选项2)。
具体操作:
(1)添加Hadoop类路径
Flink将使用环境变量HADOOP_CLASSPATH来增加启动Flink组件(例如Client,JobManager或TaskManager)时使用的类路径。默认情况下,大多数Hadoop发行版和云环境不会设置此变量,因此,如果Flink选择Hadoop类路径,则必须在运行Flink组件的所有计算机上导出环境变量。
export HADOOP_CLASSPATH=hadoop classpath
请注意,这hadoop是hadoop二进制文件,并且classpath是一个参数,它将使它打印配置的Hadoop类路径。
将Hadoop配置与Hadoop库放在相同的类路径中,使Flink可以选择该配置。
(2)将Hadoop添加到/ lib
Flink项目发布了特定版本的Hadoop发行版,该发行版重新定位或排除了多个依赖项,以减少依赖项冲突的风险。这些可以在下载页面的“ 其他组件”部分中找到。对于这些版本,下载相应的Pre-bundled Hadoop组件并将其放入/libFlink分发目录中就足够了。
如果下载页面上未列出使用的Hadoop版本(可能由于是特定于供应商的版本),则有必要针对该版本构建flink阴影。您可以在下载页面的“ 其他组件”部分中找到该项目的源代码。
注意如果你想建立flink-shaded对供应商特定的Hadoop版本,您必须首先描述配置特定供应商的Maven仓库在本地Maven安装在这里。
运行以下命令以flink-shaded针对所需的Hadoop版本(例如version 2.6.5-custom)进行构建和安装:
mvn clean install -Dhadoop.version=2.6.5-custom
完成此步骤后,将flink-shaded-hadoop-2-uberjar放入/libFlink分发目录中。
flink-shaded-hadoop-2-uberjar下载地址:
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/
或者官网:
https://flink.apache.org/downloads.html#additional-components其他组件中下载。
目前只整合到Hadoop2.8.3和flink1.10.0版本。
Hadoop其他版本可以直接执行maven命令进行操作。添加完如下:在flink的lib下:

四、使用
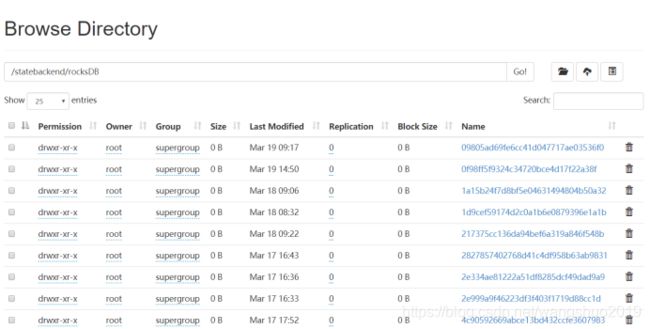
使用时,jar包运行时,可查看namenode:50070地址查看hdfs路径下的文件变化
Rocksdb一般时先在本地路径下进行存储,再进行flush到hdfs中
本地:

Hdfs下:


五、故障恢复
1.手动添加保存点savepoint
Savepoint是checkpoint的一种特殊实现,可用于在升级和维护集群过程中保存系统的状态。
(1)TargetDirectory配置
在flink配置文件flink-conf.yaml中配置

Savepoint目录构成:

注意:在手动恢复时,指定路径到JobID即可,系统会自动获取内部metadata文件进行解析处理。例:
./flink run -s hdfs://jt-1-60:9000/savepoints/rocksDB/savepoint-cc4e9d-5de0e2088f20 -c com.clue.dimension.service.state.stateDimensionTest /opt/module/dimensionTest-1.0-SNAPSHOT-jar-with-dependencies.jar
(2)命令行操作
①手动触发savepoint
bin/flink savepoint jobid [targetDirectory]
Jobid:每个job生成时的唯一id
targetDirectory:保存点路径,如果全局已经配置,可以不指定,会默认使用全局配置路径
②取消任务并触发savepoint
Bin/flink cancel -s [targetDirectory] jobid
Jobid:每个job生成时的唯一id
targetDirectory:保存点路径,如果全局已经配置,可以不指定,会默认使用全局配置路径
③手动从savepoint恢复任务
Bin/flink run -s savepointPath [runArgs]
-s 后面指定保存点路径
后面可加运行jar的参数
例:
./flink run -s hdfs://jt-1-60:9000/savepoints/rocksDB/savepoint-cc4e9d-5de0e2088f20 -c com.clue.dimension.service.state.stateDimensionTest /opt/module/dimensionTest-1.0-SNAPSHOT-jar-with-dependencies.jar
注意:恢复后和恢复前可能状态中算子会产生改变(例如修改或者删除某个算子),这时就会出现任务不能恢复的情况,此时可以通过加入参数 --n(–allowNonRestoredState)设置忽略状态无法匹配的问题。
(3)指定算子唯一ID
Operator id配置

2.手动从checkpoint恢复
这里与savepoint类似,但是目录构成有些差别

增量状态数据存入在chk-*的文件下
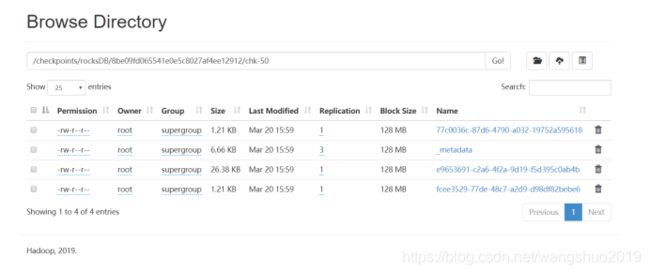
所以恢复时也要多一级目录
例:
./flink run -s hdfs://jt-1-60:9000/checkpoints/rocksDB/8be09fd065541e0e5c8027af4ee12912/chk-50 -c com.clue.dimension.service.state.stateDimensionTest /opt/module/dimensionTest-1.0-SNAPSHOT-jar-with-dependencies.jar
俩种手动方式都可以实现,集群挂机后重新读取状态数据进行恢复任务。