pkuseg,LTP,jieba分词实践
pkuseg
pkuseg具有如下几个特点:
多领域分词。不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文本的领域特点,用户可以自由地选择不同的模型。 我们目前支持了新闻领域,网络领域,医药领域,旅游领域,以及混合领域的分词预训练模型。在使用中,如果用户明确待分词的领域,可加载对应的模型进行分词。如果用户无法确定具体领域,推荐使用在混合领域上训练的通用模型。各领域分词样例可参考 example.txt。 更高的分词准确率。
相比于其他的分词工具包,当使用相同的训练数据和测试数据,pkuseg可以取得更高的分词准确率。 支持用户自训练模型。支持用户使用全新的标注数据进行训练。 支持词性标注。
https://github.com/lancopku/PKUSeg-python
#对文件分词 中文需要保存为utf-8
import pkuseg
pkuseg.test('./NLPdata/input.txt', './NLPdata/output.txt', nthread=2) #20
# 对input.txt的文件分词输出到output.txt中
# 额外使用用户自定义词典
import pkuseg
seg = pkuseg.pkuseg(user_dict='./data/my_dict.txt') # 给定用户词典为当前目录下的"my_dict.txt"
text = seg.cut('我爱北京天安门') # 进行分词
print(text)
#额外使用用户自定义词典
import pkuseg
seg = pkuseg.pkuseg(model_name='./ctb8') # 假设用户已经下载好了ctb8的模型并放在了'./ctb8'目录下,通过设置model_name加载该模型
text = seg.cut('我爱北京天安门') # 进行分词
print(text)
#练新模型 (模型随机初始化)
import pkuseg
# 训练文件为'train.txt'
# 测试文件为'test.txt'
# 加载'./pretrained'目录下的模型,训练好的模型保存在'./models',训练10轮
pkuseg.train('train.txt', 'test.txt', './models', train_iter=10, init_model='./pretrained')
LTP
语言技术平台( Language Technology Plantform,简称LTP),经过哈工大社会计算与信息检索研究中心11 年的持续研发和推广, 是国内外最具影响力的中文处理基础平台。详情见官网:http://ltp.ai/
提供的功能包括:中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注等
安装LTP:pip install ltp
pyltp 是 LTP 的 Python 封装,提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注的功能。安装pyltp(python版本3.7以下),下载ltp_data_v3.4.0文件,可参考https://blog.csdn.net/jknpocca/article/details/107675020
notebook
#分句
from pyltp import SentenceSplitter
sents = SentenceSplitter.split('元芳你怎么看?我就趴窗口上看呗!') # 分句
print('\n'.join(sents))

#命名实体识别
import os
LTP_DATA_DIR='F:\python-machine-learning-package-win-amd64\ltp_data_v3.4.0'
ner_model_path = os.path.join(LTP_DATA_DIR, 'ner.model') # 命名实体识别模型路径,模型名称为`pos.model`
from pyltp import NamedEntityRecognizer
recognizer = NamedEntityRecognizer() # 初始化实例
recognizer.load(ner_model_path) # 加载模型
words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
netags = recognizer.recognize(words, postags) # 命名实体识别
print('\t'.join(netags))
recognizer.release() # 释放模型
![]()
#依存句法分析
import os
LTP_DATA_DIR='F:\python-machine-learning-package-win-amd64\ltp_data_v3.4.0\ltp_data_v3.4.0'
par_model_path = os.path.join(LTP_DATA_DIR, 'parser.model') # 依存句法分析模型路径,模型名称为`parser.model`
from pyltp import Parser
parser = Parser() # 初始化实例
parser.load(par_model_path) # 加载模型
words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
arcs = parser.parse(words, postags) # 句法分析
print("\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs))
parser.release() # 释放模型
![]()
#语义角色标注
import os
LTP_DATA_DIR='F:\python-machine-learning-package-win-amd64\ltp_data_v3.4.0\ltp_data_v3.4.0'
srl_model_path = os.path.join(LTP_DATA_DIR, 'pisrl_win.model') # 语义角色标注模型目录路径,模型目录为`srl`。注意该模型路径是一个目录,而不是一个文件。
from pyltp import SementicRoleLabeller
labeller = SementicRoleLabeller() # 初始化实例
labeller.load(srl_model_path) # 加载模型
words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
# arcs 使用依存句法分析的结果
roles = labeller.label(words, postags, arcs) # 语义角色标注
# 打印结果
for role in roles:
print(role.index, "".join(
["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))
labeller.release() # 释放模
![]()
jeiba分词
“结巴”分词是一个Python 中文分词组件,参见https://github.com/fxsjy/jieba
可以对中文文本进行分词、词性标注、关键词抽取等功能,并且支持自定义词典。
jieba分词的原理
- 利用一个中文词库,确定汉字之间的关联概率
- 汉字间概率大的组成词组,形成分词结果
安装包jieba分词包 :pip install jieba
实践(工具:Anaconda的notebook)
import jieba
if __name__ == '__main__':
#jieba分词有三种不同的分词模式:精确模式、全模式和搜索引擎模式:
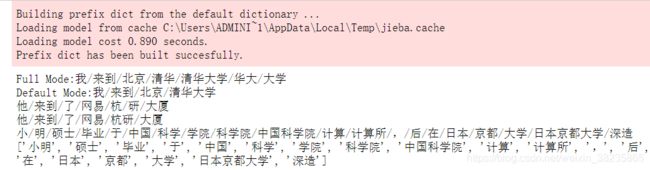
seg_list = jieba.cut("我来到北京清华大学", cut_all=True) #全模式
print("Full Mode:" + "/".join(seg_list))
seg_list = jieba.cut("我来到北京清华大学", cut_all=False) #精确模式
print("Default Mode:" + "/".join(seg_list))
seg_list = jieba.cut("他来到了网易杭研大厦", HMM=False) #不使用HMM模型
print("/".join(seg_list))
seg_list = jieba.cut("他来到了网易杭研大厦", HMM=True) #使用HMM模型
print("/".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造", HMM=False) #搜索引擎模式
print("/".join(seg_list))
seg_list = jieba.lcut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造", HMM=True)
print(seg_list)
关键词抽取
有两种算法,基于TF-IDF和基于TextRank
import jieba.analyse as analyse
text = "坚定着信念,接受着试练,地平线已不再遥远"
# TF-IDF
tf_result = analyse.extract_tags(text, topK=5) # topK指定数量,默认20
print(tf_result)
# TextRank
tr_result = analyse.textrank(text, topK=5) # topK指定数量,默认20
print(tr_result)

主题模型
#读取数据与分词
import jieba
filepaths = ['NLPdata/test1.txt', 'NLPdata/test2.txt', 'NLPdata/test3.txt', 'NLPdata/test4.txt']
docs = [open(f).read() for f in filepaths]
docs = [jieba.lcut(doc)
for doc in docs]
docs
#.去除停止词,只保留词语长度大于1的
docs = [[w
for w in doc
if len(w)>1]
for doc in docs]
#sklearn默认分析的语言是英文,我们要组织成类似英文那样以空格间隔的语言形式。
#corpus现在是一个列表,列表中有四个字符串。
#每个字符串就是一个文档
corpus = [' '.join(doc)
for doc in docs]
corpus
#构建Tfidf矩阵每一行代表一个test的文档,每一列代表一个词语的tfidf值。学过的sklearn的都知道fit和transform的意义,如果对tfidf不懂的可以查看咱们之前分享的文章。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(corpus)
tfidf_matrix
#LDA分析
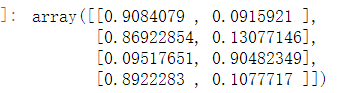
lda = LatentDirichletAllocation(n_components=2, random_state=0)
docres = lda.fit_transform(tfidf_matrix)
docres
import nltk
import math
import string
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = ['祝福你前程似锦',
'祝福你未来星光璀璨',
'祝福你求仁得仁,'
]
vectorizer = TfidfVectorizer(min_df=1)
cret = vectorizer.fit_transform(corpus)
print(cret)
fnames = vectorizer.get_feature_names()
print(fnames)
arr = vectorizer.fit_transform(corpus).toarray()
print(arr)
#!/usr/bin/python没有词cnews.train_jieba
# -*- coding:utf-8 -*-
import jieba,os,re
from gensim import corpora, models, similarities
"""创建停用词列表"""
def stopwordslist():
stopwords = [line.strip() for line in open('./stopwords.txt',encoding='UTF-8').readlines()]
return stopwords
"""对句子进行中文分词"""
def seg_depart(sentence):
sentence_depart = jieba.cut(sentence.strip())
stopwords = stopwordslist()
outstr = ''
for word in sentence_depart:
if word not in stopwords:
outstr += word
outstr += " "
# outstr:'黄蜂 湖人 首发 科比 带伤 战 保罗 加索尔 ...'
return outstr
"""如果文档还没分词,就进行分词"""
if not os.path.exists('./cnews.train_jieba.txt'):
# 给出文档路径
filename = "./cnews.train.txt"
outfilename = "./cnews.train_jieba.txt"
inputs = open(filename, 'r', encoding='UTF-8')
outputs = open(outfilename, 'w', encoding='UTF-8')
# 把非汉字的字符全部去掉
for line in inputs:
line = line.split('\t')[1]
line = re.sub(r'[^\u4e00-\u9fa5]+','',line)
line_seg = seg_depart(line.strip())
outputs.write(line_seg.strip() + '\n')
outputs.close()
inputs.close()
print("删除停用词和分词成功!!!")
#分词cnews.train。txxt
# @Blog :http://blog.csdn.net/u010105243/article/
# Python3
import jieba
# jieba.load_userdict('userdict.txt')
# 创建停用词list
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 对句子进行分词
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('./stopwords.txt') # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
inputs = open('./cnews.train.txt', 'r', encoding='utf-8')
outputs = open('./cnews.train_jieba.txt', 'w',encoding='utf-8')
for line in inputs:
line_seg = seg_sentence(line) # 这里的返回值是字符串
outputs.write(line_seg + '\n')
outputs.close()
inputs.close()
"""准备好训练语料,整理成gensim需要的输入格式"""
fr = open('./cnews.train_jieba.txt', 'r',encoding='utf-8')
train = []
for line in fr.readlines():
line = [word.strip() for word in line.split(' ')]
train.append(line)
# train: [['黄蜂', '湖人', '首发', '科比', '带伤', '战',...],[...],...]
"""构建词频矩阵,训练LDA模型"""
dictionary = corpora.Dictionary(train)
# corpus[0]: [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1),...]
# corpus是把每条新闻ID化后的结果,每个元素是新闻中的每个词语,在字典中的ID和频率
corpus = [dictionary.doc2bow(text) for text in train]
lda = models.LdaModel(corpus=corpus, id2word=dictionary, num_topics=3)
topic_list = lda.print_topics(3)
print("3个主题的单词分布为:\n")
for topic in topic_list:
print(topic)
pkuseg与pyltp分词和词性标注效果对比
pkuseg结果跟LTP一样,但是更直观
pkuseg
#分词同时进行词性标注
seg = pkuseg.pkuseg(postag=True) # 开启词性标注功能
text = seg.cut('元芳你怎么看') # 进行分词和词性标注
print(text)
![]()
pyltp
#词性标注
import os
from pyltp import Segmentor
from pyltp import Postagger
LTP_DATA_DIR='F:\python-machine-learning-package-win-amd64\ltp_data_v3.4.0'
pos_model_path = os.path.join(LTP_DATA_DIR, 'pos.model') # 词性标注模型路径,模型名称为`pos.model`
postagger = Postagger() # 初始化实例
postagger.load(pos_model_path) # 加载模型
words = ['元芳', '你', '怎么', '看'] # 分词结果
postags = postagger.postag(words) # 词性标注
print('\t'.join(postags))
postagger.release() # 释放模型
![]()