亚马逊一口气发布了9款机器学习产品
AI前线导读: 今天,在拉斯维加斯举行的AWS re:invent进行到第三个日程,大会上,AWS CEO Andy Jassy在主题演讲上一口气做了二十个新发布,其中包括9款机器学习产品!
更多干货内容请关注微信公众号“AI前线”(ID:ai-front)
在这9款机器学习产品中,最重磅和引人关注的是将于明年下半年发布的云端机器学习推理芯片Inferentia。此外,其他的机器系学习产品还包括Amazon Elastic Inference、Amazon SageMaker Ground Truth等。下面,AI前线将对这些产品做详细的介绍。
AWS Inferentia(预告)

本次的机器学习发布之一,专门擅长做推理的芯片,计划在明年年底发布。
Inferentia旨在降低成本,提高性能,将支持TensorFlow、Apache MXNet和 PyTorch深度学习框架,以及使用ONNX模式的模型,并可用于Amazon SageMaker、Amazon EC2和Amazon Elastic Inference。
使用Amazon Elastic Inference,开发人员可以通过将GPU驱动的推理加速功能附加到Amazon EC2和Amazon SageMaker实例,将推理成本降低75%。据介绍,Inferentia芯片的推理能力达数百个TOPS(每秒tera操作),可以让复杂的模型进行快速预测,使用多个AWS Inferentia芯片,性能可以提高数千TOPS。
在这里(https://pages.awscloud.com/AWSInferentia-preview.html) 注册,当Inferentia可用时用户将接到通知。
Amazon Elastic Inference
本次的机器学习发布之二,GPU深度学习推理加速,可以按需使用GPU资源,号称能够节省75%的推理成本。
在大规模模型训练推理过程中,RAM和CPU的分配可能比推理速度对于一个应用来说更加重要。Elastic Inference 服务可以让Amazon EC2、SageMaker notebook用例和端点合理配置所需的GPU推理加速能力,加速内置算法和深度学习环境。
Elastic Inference支持主流机器学习框架TensorFlow、Apache MXNet和ONNX (通过MXNet)。用户无需过多调整代码,但需要使用AWS优化的构建,这些构建会自动检测附加到实例的加速器,确保仅允许授权访问,并在本地CPU资源和连接的加速器之间合理分配计算。这些构建在Amazon S3上的AWS深度学习AMI中可用,因此你可以将其构建到自己的图像或容器中。
Amazon Elastic Inference有三种类型可供选择,适用于各种推理模型,包括计算机视觉、自然语言处理和语音识别。
- eia1.medium:混合精度性能达8 TeraFLOP。
- eia1.large:混合精度性能达16 TeraFLOP。
- eia1.xlarge:混合精度性能达32 TeraFLOP。
这样,用户可以为自己的应用选择最具性价比的服务。例如,使用eia1.medium加速配置的c5.large实例每小时费用为0.22美元(us-east-1),仅比p2.xlarge实例慢10-15%。后者使用专用的NVIDIA K80 GPU,每小时费用需要0.90美元(us-east-1)。结论:选择最适合你的应用实例的同时,可以降低75%的成本,获得相同的GPU性能。
Amazon SageMaker Ground Truth

本次的机器学习发布之三,为不知道怎么做数据集、或者觉得做数据集太麻烦的开发者而设计,大意是,你可以让SageMaker帮你自动标记数据,或者委托SageMaker找第三方帮你标记数据,创建高精度数据机,标记成本降低70%。
现在,开发者和数据科学家可以使用大量现成的算法和推理数据集。深度学习让图像数据集,如 MNIST, CIFAR-10 和 ImageNet大受欢迎,更多用于机器翻译和文本分类任务的数据集也不断出现。但是,创建数据集是一个复杂的问题,尤其是规模巨大的数据集需要花费大量的时间在数据标记上。
为此,Amazon SageMaker Ground Truth让用户可以更精准、高效地标记机器学习系统数据集,包括创建:
- 文本分类。
- 图像分类,即对特定类别的图像进行分类。
- 对象检测,即在具有边界框的图像中定位对象。
- 语义分割,即以像素级精度定位图像中的对象。
- 用户自定义任务。
Amazon SageMaker Ground Truth可以选择使用主动学习来自动标记输入数据。主动学习是一种机器学习技术,可识别需要由人类标记的数据和可由机器标记的数据。自动数据标记会产生Amazon SageMaker训练和推理成本,但相比手动标记,可以降低成本(高达70%)和标记数据集所需的时间。
当需要手动操作时,你可以选择雇用拥有超过500,000名员工的亚马逊土耳其机器人( Amazon Mechanical Turk )众包服务,自己的专业人员,或AWS Marketplace上列出的第三方供应商。
标记数据集需要:
- 将数据存储在Amazon S3中,
- 组建标记人员团队
- 创建标签作业
- 开始工作
- 效果可视化
AWS 机器学习Marketplace
本次的机器学习发布之四。最近年年都有机器学习新算法,哪个好用哪个不好用,一个一个找起来挺费功夫。于是AWS把算法也做成商品放市场里面卖,用户找起来方便,算法研发人员也有钱赚。
亚马逊Marketplace上将会提供Machine Learning category商品,包括150+算法和模型包,而且每天会增加新品。
AWS Marketplace为垂直行业提供定制化选择,如零售(35种产品),媒体(19种产品),制造业(17种产品),HCLS(15种产品)等。客户可以找到关键用例的解决方案,如乳腺癌预测,淋巴瘤分类,再入院,贷款风险预测,车辆识别,零售定位器,僵尸网络攻击检测,汽车远程信息处理,运动检测,需求预测和语音识别。
客户可以在AWS Marketplace中搜索、浏览算法和模型包列表。客户订购机器学习解决方案后可以直接从SageMaker控制台,Jupyter笔记本电脑,SageMaker SDK或AWS CLI进行部署。 Amazon SageMaker通过采用静态扫描,网络隔离和运行时监控等安全措施来保护买方数据。
算法和模型包工件在传输和静态时受加密保护,以保障AWS Marketplace上的卖方知识产权安全,并使用安全(SSL)连接进行通信,确保基于角色访问部署工件。AWS为卖家提供了一种安全的方式,可以通过无障碍的自助服务流程发布他们的算法和模型包,将成果变现。
使用和定价
为使用算法或模型包,用户需要支付订阅费和AWS资源费。AWS Marketplace将为所有购买的订阅用户提供月度帐单。
推出时,AWS 机器学习Marketplace的产品将包括来自Deep Vision AI Inc,Knowledgent,RocketML,Sensifai,Cloudwick Technologies,Persistent Systems,Modjoul,H2Oai Inc,Intel,AWS Gluon Model Zoos和更多定期添加的卖家的产品。如果你有兴趣销售机器学习算法和模型包,请联系[email protected]。
Amazon SageMaker RL

本次的机器学习发布之五。在监督学习和无监督学习之外,强化学习(reinforcement learning)最近很多人在搞,于是AWS把增强学习的能力也放进了SageMaker。
在2017年的AWS re:Invent 上,亚马逊发布Amazon SageMaker,帮助用户快速创建、训练和部署AI模型。今天,Amazon SageMaker RL 发布,将强化学习拓展到 Amazon SageMaker中,让没有机器学习经验的开发者和数据科学家也可以使用。
Amazon SageMaker RL构建于Amazon SageMaker之上,添加了预先打包的RL工具包,可以轻松集成任何模拟环境。如你所想,训练和预测基础架构是完全托管的,因此用户可以不用管理服务器,专注于RL问题。
现在,用户可以使用SageMaker为Apache MXNet和Tensorflow提供的容器,包括Open AI Gym,Intel Coach和Berkeley Ray RLLib。与Amazon SageMaker一样,用户可以使用其他RL库(如TensorForce或StableBaselines)轻松创建自己的自定义环境。
在模拟环境中,Amazon SageMaker RL支持以下选项:
- 适用于AWS RoboMaker和Amazon Sumerian的第一方模拟器。
- 使用Gym界面开发的开源AI Gym环境和模拟环境,如Roboschool或EnergyPlus。
- 客户开发的、使用Gym界面的模拟环境。
- 商业模拟器,如MATLAB和Simulink(客户需要自行管理许可证)。
亚马逊SageMaker RL还附带了一系列Jupyter notebook,和Amazon SageMaker一样可以在Github上获得,包括简单的例子和各种领域的最新用例,如机器人,运算学,金融等。用户可以扩展这些notebook,并根据自己的业务问题进行自定义。
此外,还有说明如何使用同构或异构缩放来缩放RL的示例。后者对许多RL应用尤其重要,因为在这些应用中,模拟和训练在CPU上进行。模拟环境可以在不同网络中在本地或远程运行,SageMaker将设置好一切。
AWS DeepRacer \u0026amp; DeepRacer League

本次的机器学习发布之六。DeepRacer是一款自动驾驶赛车,尺寸是真车的1/18。把你的增强学习的模型搞到DeepRacer里面,让它去跑赛道参加比赛,赢了可以获奖。
DeepRacer搭载IntelAtom®处理器,一台400万像素、1080p分辨率的摄像头,快速(802.11ac)WiFi,以及多个USB端口,电池电量续航约2小时。Atom处理器运行Ubuntu 16.04 LTS,ROS(机器人操作系统)和Intel OpenVino™计算机视觉工具包。
AWS DeepRacer包含一个完全配置的云环境,可以用来训练强化学习模型。它可以使用Amazon SageMaker中新增的强化学习功能,还包括由AWS RoboMaker提供支持的3D仿真环境。使用模拟器中预定义的赛道集合,用户可以训练自动驾驶模型并进行虚拟评估,或将其下载到AWS DeepRacer,在现实世界中验证其性能。
现在,AWS DeepRacer可接受预订,预订地址:https://amazonaws-china.com/cn/deepracer/

而且,此次大会的参会者还有机会加入DeepRacer workshop,学习如何创建DeepRacer自动驾驶模型。与此同时,AWS还宣布举行全球第一场自动驾驶赛事,并成立了全球第一个自动驾驶联盟DeepRacer League。赛事规定,此次比赛的Top3开发者将晋级2018年总决赛,争夺AWS DeepRacer 2018冠军。总决赛将会在会议期间的周四(当地时间),全球所有人都可以参加。
Amazon Textract(预览)
本次的机器学习发布之七,简单来说是一种自动从扫描文档中提取文本和数据的服务,不仅包括简单的光学字符识别(OCR),还能识别表格中存储的表格和信息中的字段内容。
通过机器学习,Amazon Textract可以即时“读取”几乎所有类型的文档来,准确提取文本和数据,而无需任何手动操作或自定义代码;可以快速自动化文档工作流程,使用户能够在数小时内处理数百万个文档页面;可以通过标记可能需要编辑的数据来创建智能搜索索引,构建自动批准工作流,更好地整理文档。
Amazon Personalize
本次的机器学习发布之八,简单来说是实时个性化推荐引擎,不需要任何机器学习的知识就能使用,号称与Amazon.com使用的是同一套技术。
Amazon Personalize支持存储在Amazon S3中的数据集和流数据集,如从JavaScript跟踪器或服务器端实时发送的事件。过程如下所示:
- 创建描述数据集的模式,使用个性化关键字作为用户ID,项目ID等。
- 创建一个数据集组,其中包含用于构建模型和预测的数据集:用户项交互(也就是“谁喜欢什么”),用户和项目。最后两个是可选的。
- 将数据发送到Personalize。
- 创建解决方案,即选择个性化推荐并在数据集组上进行训练。
- 预测新样本。
使用存储在Amazon S3中的数据,将数据发送到Personalize会将数据文件添加到数据集组,并自动触发提取。
Amazon Forecast
本次的机器学习发布之九,可以根据历史数据进行预测,比如销售量预测、网站流量预测等。
现在,大多数时间序列预测工具主要通过查询时间序列数据进行预测,但是对于预测具有不规则趋势的大型数据集预测准确度不够,而且结合随时间变化的数据序列时很容易失败。
Amazon Forecast可以解决众多领域,包括零售、供应链、服务器存在了二十多年的挑战,这个完全管理深度学习时间序列预测服务可以根据时间序列数据生成预测评估,包括:
- 运营指标,如服务器的Web流量,AWS使用情况或IoT传感器指标。
- 业务指标,如销售额,利润和费用。
- 资源需求,如满足特定需求所需的电量或带宽量。
- 制造过程所需的原材料、服务或其他投入的数量。
- 考虑到价格折扣,市场促销和其他活动的影响下的零售需求。
亚马逊预测主要有以下三个优点:
- 准确性,使用深度神经网络和传统的统计方法进行预测。亚马逊预测可以自动从数据中学习,并选择最佳算法来训练定制化模型。当涉及多个相关的时间序列时,使用亚马逊预测深度学习算法(如DeepAR和MQ-RNN)进行的预测往往比使用传统方法(如指数平滑)所做的预测更准确。
- 端到端管理,自动化整个预测工作流程,从数据上传到数据处理,模型训练,数据集更新和预测。企业系统可以直接将预测作为API使用。
- 可用性,用户可以在控制台中查找并对任何时间序列预测进行不同粒度的可视化,还可以查看预测变量准确性的指标。没有机器学习专业知识的开发人员也可以使用Amazon Forecast API,AWS命令行界面(CLI)或控制台,将训练数据导入一个或多个Amazon Forecast数据集,训练并部署模型以生成预测。
使用亚马逊预测
在Amazon Forecast中创建预测项目时,用户主要会用到以下资源:
- 数据集,用于上传用户数据。Amazon Forecast算法使用数据集来训练模型。
- 数据集组是一个或多个数据集的容器,可以使用多个数据集进行模型训练。
- 预测器,训练模型的结果。创建预测器需要提供数据集组和算法,或让Amazon Forecast确定哪种预测模型效果最佳。该算法使用数据集中的数据训练模型。
- 预测器,运行推理来生成预测。
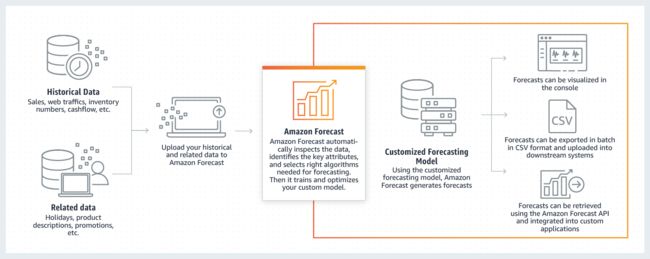
用户可以将Amazon Forecast与AWS控制台,CLI和SDK一起使用。例如,使用AWS SDK for Python在Jupyter notebook中训练模型或获取预测,或使用AWS SDK for Java将预测功能添加到现有业务应用程序。
定价和供货
用户需要支付三类费用:
- 生成的预测:对任意时间范围内单个变量的未来值的预测。按每1,000单位收费(四舍五入到最接近的千位)。
- 数据存储:存储和用于训练模型,按GB收费。
- 训练时间:基于客户提供的数据定制模型,按小时收费。
作为AWS免费套餐的一部分,在首次使用亚马逊预测的前两个月,用户无需支付以下费用:
- 生成的预测:每月10K时间序列预测封顶
- 数据存储:每月最多10GB
- 训练时间:每月最多10个小时
Amazon Forecast在这些地区已有预览版:US东部(北维吉尼亚州),US西部(俄勒冈州)。

链接:http://t.cn/E28YBT9