并行与分布式计算 第二章 线程级的并行:OpenMP编程
文章目录
- 并行与分布式计算 第二章 线程级的并行:OpenMP编程
-
- 2.1 线程级并行基础概念
-
- 2.1.1 访存模型(共享内存)
- 2.1.2并行计算编程模型
- 2.2 线程级并行编程模型:OpenMP
-
- 2.2.1 openmp体系结构
- 2.2.2 FORK-JOIN 模型
- 2.2.3 详细介绍OPENMP
并行与分布式计算 第二章 线程级的并行:OpenMP编程
2.1 线程级并行基础概念
当一个处理器不足以满足计算需求时,除了增强单个核心的计算性能(但这很难),最直观的方法就是增加核心数量(线程级并行,TLP)我们称这种拥有多个处理机的结构为多处理机,其特点是多个处理机共用一个共有的内存,也称为共享内存模型
2.1.1 访存模型(共享内存)
- UMA: Uniform Memory Access,一致访存,所有处理器对内存的访问是一致的,可以有私有cache
- NUMA: Non uniform Memory Access,非一致访存,处理器有各自的存储器

典型的UMA:集中式共享存储器SMP

典型的NUMA:分布式共享存储器DSM

举例说明
- 在1块消费级主板上往往只有1颗CPU(package),其中可能包含多个core,共用主存,因此属于UMA
- 在一些企业级主板上,可以同时安装多颗CPU,每颗CPU拥有自己的内存控制器,CPU之间使用外部总线连接;所有CPU共用一个内存地址空间,但其各自管理着属于自己的内存,因此属于NUMA
线程与进程
- 进程:一个正在执行程序的实例,包括程序计数器、寄存器和变量的当前值(更独立,有独自的地址空间)
- 线程:轻量级进程,共享地址空间,但各有一套堆栈
本章所述“线程级并行”指的更多是在多处理器上的硬件级线程并行,而非操作系统中实现的软件控制的并发

2.1.2并行计算编程模型
根据进程交互方式,我们有以下几类并行编程模型:
• 隐式交互(完全由编译器实现,这里不展开)
• 共享变量(英特尔Cilk、OpenMP)
• 消息传递(MPI)

| 共享变量 | 消息传递 |
|---|---|
| 适合于SMP、DSM | 适合于MPP、COW |
| 单一地址空间 | 多地址空间 |
| 隐式通信 | 显式通信 |
| 在集群中,一般用于一个节点的多个核上 | 一般用于集群中的多个节点上 |
共享变量编程存在的隐藏问题
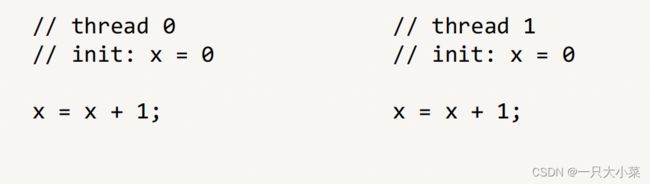
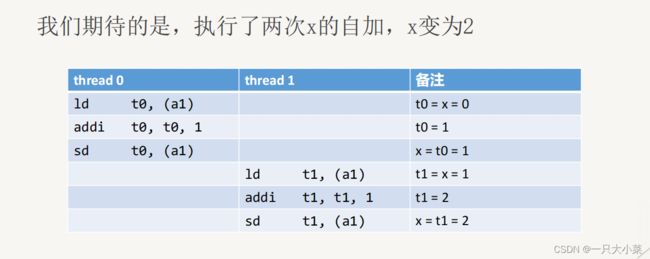

上述问题被称为:竞态(race condition)当程序的正确运行依赖于程序中各线程的特定时序时(执行顺序不同会产生不同的结果),就会出现竞态。这种依赖往往发生在多个线程对同一个资源的竞争中,尤其当其中存在修改资源状态的操作(写操作)时。在内存上,这被称为数据竞争(data race)
数据竞争的解决方法:利用同步,确保操作是原子性的,从而对操作进行排序,将资源与操作“保护”起来
注意:“排序”并不意味着顺序是确定的,因此解决了数据竞争并不意味着完全解决了竞态
指令重排序
指令可能由于cache不命中导致乱序执行,从而导致出现错误
内存重排序

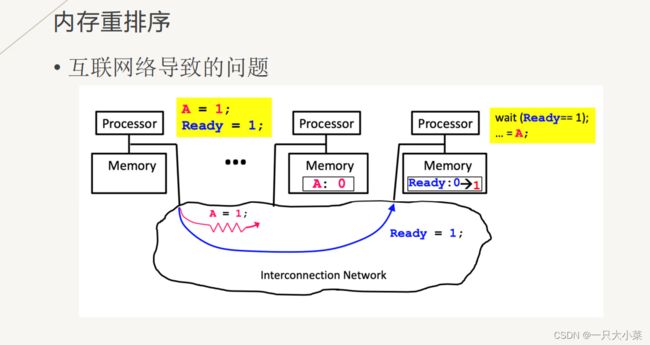
•可以看到,一个线程内的几条指令之间(在对于另一个线程的可见性上)出现了难以预见的重排序情况
• 这种重排序对单线程没有影响,但对于多线程则产生了问题
• 解决方法也是通过同步(锁、栅栏等技术)
综上所述,在编写多线程代码时,请时刻注意以上问题,并合理利用同步技术
2.2 线程级并行编程模型:OpenMP
2.2.1 openmp体系结构

OPENMP并行编程模型:OPENMP是基于线程的并行编程模型,一个共享的进程由多个线程组成。使用FORK-JOIN并行模型,主线程(MASTER THREAD)串行执行,直到编译制导并行域(PARALLEL REGION)出现。
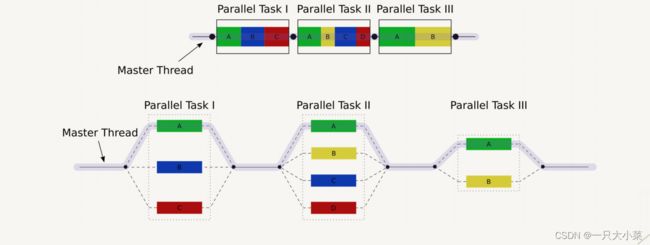
2.2.2 FORK-JOIN 模型
- 将程序划分为许多段的串行部分或并行部分
- 串行部分使用单个线程处理
- 并行部分的各个子任务使用多个线程分而治之
- 并行任务拆分出的子任务可以继续拆分
- 使用fork进入并行(子任务)部分,使用join回到串行(父
任务)部分
2.2.3 详细介绍OPENMP
- 一种基于fork-join模型的多线程并行编程API
- 在C、C++、Fortran等语言上提供接口
- 主要适用于共享内存结构的多处理机
OpenMP 存储模型
- OpenMP中将存储分为shared和private两类
- shared变量将在各个线程之间共享(因此在对其进行操
作时,请注意竞态和重排序问题,并合理使用同步) - private变量是各线程独有的,互不影响
OPENMP的语法
OPENMP的语法之环境变量
| 环境变量 | 描述 |
|---|---|
| OMP_SCHEDULE | 只能用于parallel for和for,决定循环中各个迭代的调度方式 |
| OMP_NUM_THREADS | 可以使用的最大线程数量 |
| OMP_DYNAMIC | 布尔类型,确定是否允许动态设置并行域的线程数 |
| OMP_NESTED | 布尔类型,确定是否允许嵌套并行 |
OPENMP的语法之运行库函数
| 函数 | 描述 |
|---|---|
| omp_get_num_procs | 返回运行当前线程的多处理器的处理器个数 |
| omp_get_num_threads | 返回当前并行区域中的活动线程个数 |
| omp_get_thread_num | 返回当前线程的线程号 |
| omp_set_num_threads | 设置并行执行代码的线程个数 |
| omp_init_lock | 初始化一个简单锁 |
| omp_set_lock | 上锁操作 |
| omp_unset_lock | 解锁操作,需要与omp_set_lock函数配对使用 |
| omp_destroy_lock omp_init_lock | 函数的配对操作函数,关闭一个锁 |
OPENMP的语法之编译制导
编译制导是对程序设计语言的扩展,OpenMP通过对串行程序添加制导语句实现并行化

| 制导指令 | 描述 |
|---|---|
| parallel | 用在一个代码段之前,表示这段代码将被多个线程并行执行 |
| for | 用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性 |
| sections | 用在可能会被并行执行的代码段之前 |
| single | 用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行 |
| critical | 用在一段代码临界区之前 |
| barrier | 用于并行区内代码的线程同步,所有线程执行到barrier时要停止直到所有线程都执行到 |
| atomic | 用于指定一块内存区域被原子更新 |
| master | 用于指定一段代码块由主线程执行 |
| ordered | 用于指定并行区域的循环按顺序执行 |
| threadprivate | 用于指定一个变量是线程私有 |
并行域结构

并性域结构:REDUCTION子句

任务划分结构
用来表明任务如何在多个线程间分配,任务划分结构将它所包含的代码
划分给线程组的各成员来执行。它不产生新的线程,在任务划分结构的
入口点没有路障,但在其结束处有一个隐含的路障。一个共享任务结构
必须动态地封装在一个并行域中,以使制导语句可以并行执行。
• 并行DO/for循环制导,用于数据并行
• 并行SECTIONS制导,用于功能并行
• SINGLE制导,用于串行执行

DO/FOR循环制导
用来将循环划分成多个块,并分配给各线程并行执行,在C
语言中使用的是for循环制导
#pragma omp for [clauses]
for 循环
• DO/for循环可以带有PRIVATE和FIRSTPRIVARE等子句
• 循环变量是私有的
调度子句SCHEDULE
控制for循环并行化的任务调度方式(划块方式)
• schedule(kind[, chunksize])
• kind: static, dynamic, guided, runtime
• chunksize是一个整数表达式
SCHEDULE (STATIC [, CHUNKSIZE])
•省略chunksize,迭代空间被划分成(近似)相同大小的区域,每个
线程被分配一个区域;
• 如果chunksize被指明,迭代空间被划分为chunksize大 小,然后
被轮转的分配给各个线程

SCHEDULE(DYNAMIC [,CHUNKSIZE])
• 划分迭代空间为chunksize大小的区间,然后基于先来先服务方式分配给各线程;
• 当省略chunksize时,其默认值为1。
SCHEDULE(GUIDED[,CHUNKSIZE])
• 类似于DYNAMIC调度,但区间开始大,然后迭代区间越来越小
• chunksize说明最小的区间大小。当省略chunksize时,
其默认值为1
SCHEDULE(RUNTIME)
• 调度选择延迟到运行时,调度方式取决于环境变量
OMP_SCHEDULE的值,例如:
export OMP_SCHEDULE=“DYNAMIC, 4”
• 使用RUNTIME时,指明chunksize是非法的;

SECTIONS制导

SINGLE制导
结构体代码仅由一个线程执行;并由首先执行到该代码的线程执行;其它线程等待直至该结构块被执行完 。

同步结构
| 同步结构 | 描述 |
|---|---|
| master | 指定代码段将只由主线程执行,其他线程将忽略该代码段 |
| critical | 指定代码段为线程互斥临界区,在同一时刻只能由一个线程执行 |
| barrier | 用于同步一个线程组中的所有线程,先执行到达该语句的线程阻塞 |
| atomic | 指定特定的存储单元被原子地更新 |
| flush | 用于标识一个同步点,确保所有线程看到一致的存储器视图 |
| ordered | 指定代码中所包含的循环以串行方式执行,任何时候只能有一个线程执行 |
| threadprivate | 使一个全局文件作用域的变量在并行域内变成每个线程私有,每个线程对该变量复制一份私有拷贝 |
CRITICAL制导
- 由critical指令指定的代码区域(临界区),一次只能由一个线程执行。
- 如果一个线程当前正在一个critical区域内执行,而另一个线程到达该区域并试图执行它,它将阻塞,直到第一个线程退出该区域。

• 如果为临界区指定了name,该名称充当critical区域全局标识符,相同名称的不同临界区域被视为同一区域
• 所有未命名的critical区域均视为同一区域
BARRIER制导
• barrier指令同步所有线程,组内任何线程到达barrier指令时将在该点等待,直到所有其他线程都到达该barrier处为止。然后所有线程才继续并行执行后续代码
• 在DO/FOR、SECTIONS和SINGLE等制导后,有一个隐式barrier存在
ATOMIC制导
• ATOMIC编译制导表明一个特殊的存储单元只能原子的更新,而不允许让多个线程同时去写,一般用于对共享变量的操作
• 提供了一个最小的临界区(critical),其效率比临界区高
FLUSH制导
• flush指令标识一个同步点,在该点上list中的变量都要被写回内存,而不是暂存在寄存器中,保证线程读取到的共享变量的最新值,从而保证多线程数据的一致性。
#pragma omp flush
以下指令隐含flush操作:
• barrier、parallel、critical、ordered
• for、sections、single
• atomic修饰的语句
ORDERED制导
• 在并行化的for循环中,指定一部分代码应当按循环迭代顺序执行
• 只能用于带有ordered子句的for或parallel for结构当中,且在一个循环中只能出现一次ordered制导