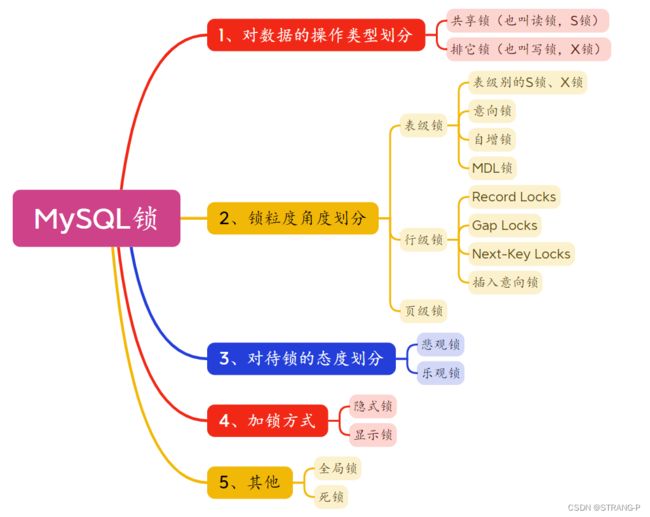
多维度梳理 MySQL 锁
多维度梳理 MySQL 锁
- 1、并发问题的解决方案
- 2、MySQL的各类型锁
-
- 2.1、从数据操作的类型划分 (读锁、写锁)
- 2.2、从数据操作的粒度划分
-
- 2.2.1、表锁
-
- 2.2.1.1、表级别的S 锁、X 锁
- 2.2.1.2、意向锁(IS、IX)
- 2.2.1.3、自增锁
- 2.2.1.4、元数据锁
- 2.2.2、行锁
-
- 2.2.2.1、记录锁(Record Locks)
- 2.2.2.2、间隙锁(Gap Locks)
- 2.2.2.3、临键锁(Next-Key Locks)
- 2.2.2.4、插入意向锁(Insert Intention Locks)
- 2.2.3、页锁
- 2.3、从对锁态度划分:乐观锁、悲观锁
-
- 2.3.1、悲观锁
- 2.3.2、乐观锁
- 2.4、从加锁方式划分
-
- 2.4.1、 隐式锁
- 2.4.2、显式锁
- 2.5、其他锁
-
- 2.5.1、全局锁
- 2.5.2、死锁
- 3、锁监控
在数据库中,除传统的计算资源(如 CPU、RAM、I/O等)的争用以外,数据也是一种供许多用户
共享的资源。为 保证数据的一致性,需要对 并发操作进行控制,因此产生了锁。同时 锁机制也为实现 MySQL 的各个隔离级别提供了保证。锁冲突也是影响数据库 并发访问性能的一个重要因素。所以锁对数据库非常重要,且复杂。并发事务访问同一记录的情况,大致分为:读-读、写-写、读-写。
1、并发问题的解决方案
并发问题的解决方案:
-
① 读操作利用
多版本并发控制(MVCC),写操作进行加锁。-
采用
MVCC方式,读-写操作彼此并不冲突,性能更高。 -
MVCC:就是生成一个ReadView,通过ReadView找到符合条件的记录版本(历史版本由undo 日志构建)。查询语句只能读到在生成ReadView 之前已提交事务所做的更改,在生成 ReadView 之前未提交的事务或者之后才开启的事务所做的更改是看不到的。而写操作是针对最新版本的记录,读记录的历史版本和改动记录的最新版本本身并不冲突。所以,采用MVCC时,读-写操作并不冲突。普通的 SELECT 语句在 READ COMMITTED 和 REPEATABLE READ 隔离级别下会使用到 MVCC 读取记录。
- 在
READ COMMITTED隔离级别下,一个事务在执行过程中,每次执行 select 操作时都会生成一个 ReadView。ReadView 保证了事务不可读取到未提交的事务所做的修改,即避免了脏读现象。 - 在
REPEATABLE READ隔离级别下,一个事务在执行过程中,只有**第一次执行 select 操作** 才会生成一个 ReadView,之后的 select 操作都是**复用**这个 ReadView ,即避免了不可重复读和幻读的问题。
- 在
-
-
② 读、写操作都采用
加锁的方式。- 采用
加锁方式,读-写操作彼此需要排队执行,影响性能。
- 采用
一般情况下都是采用 MVCC来解决读-写操作并发执行的问题,但是在某些特殊业务情况下(比如银行在存取款业务中),必须采用加锁的方式执行。
2、MySQL的各类型锁
2.1、从数据操作的类型划分 (读锁、写锁)
从数据操作的类型划分:读锁、写锁。
数据库中并发事务的 读-读并不会引发问题。在使用加锁的方式,解决并发事务的读-写问题时,MySQL 实现了一个由两种类型的锁组成的锁系统来解决,即S锁和X锁。
读锁(也称共享锁 或 S锁):针对同一份数据,多个事务的读操作可以同时进行,而不会相互影响,相互不阻塞。写锁(也称排它锁 或 X 锁):当前写操作没有完成前,它会阻断其他写锁和读锁。可以确保在给定的时间里,只有一个事务能执行写入,并防止其他用户读取正在写入的同一资源。
注意:对于 InnoDB 存储引擎而言,读锁和写锁可以加在表上,也可以加在行上。
S 锁、X 锁彼此的兼容性如下:
| 锁类型 | X 锁(排它锁/写锁) | S 锁(共享锁/读锁) |
|---|---|---|
| X 锁(排它锁/写锁) | 互斥 | 互斥 |
| S 锁(共享锁/读锁) | 互斥 | 兼容 |
2.2、从数据操作的粒度划分
从数据操作的粒度划分:表级锁、页级锁、行锁。
2.2.1、表锁
表锁分为:表级别的S锁和X锁、意向锁、自增锁、元数据锁。
2.2.1.1、表级别的S 锁、X 锁
表级别的S 锁、X 锁:
在对某个表执行增删查改语句时,InnoDB 是不会对该表添加表级别的S锁或X锁。当对表执行 ALTER TABLE、DROP TABLE 这类 DDL 语句时,其他事务对该表并发执行增删查改语句时,会发生阻塞。同理,一个事务对某表执行增删查改语句时,在其他会话中对该表执行 DDL 语句时,也会发生阻塞。该过程是通过在数据库的 server层使用 元数据锁 结构来实现。
通常不会使用 InnoDB 提供的表级别的 S锁和 X锁。特殊情况除外,比如在 崩溃恢复 等过程中使用。
2.2.1.2、意向锁(IS、IX)
InnoDB 支持 多粒度锁,它允许 行级锁和 表级锁共存,而 意向锁 就是其中的一种 表锁。
意向锁是由存储引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InnoDB 会先获取该数据行 所在数据表的对应意向锁。如果我们给某一行数据加上了排它锁(X锁),数据库会自动给更大一级的空间(比如数据页或数据表)加上意向锁,告诉其他人这个数据页或数据表已经有人上过排他锁了。意向锁分为两种:
-
意向共享锁(IS):事务有意向对表种的某些行加共享锁(S锁)。
如果事务要获取某些行的 S 锁,必须先获得表的 IS 锁。
-
意向排它锁(IX):事务有意向对表中的某些行加排它锁(X锁)。
如果事务要获取某些行的 X 锁,必须先获得表的 IX 锁。
IS 锁、IX 锁彼此的兼容性如下:
| 锁类型 | 意向共享锁(IS) | 意向排他锁(IX) |
|---|---|---|
| 意向共享锁(IS) | 兼容 | 兼容 |
| 意向排他锁(IX) | 兼容 | 兼容 |
IS 锁、S锁、IX 锁、X锁的兼容性(这里的S锁和X锁是表锁级别的,需要明确 意向锁是不会与行级的S锁、X锁互斥的)如下:
| 锁类型 | 意向共享锁(IS) | 意向排他锁(IX) |
|---|---|---|
| 共享锁(S) | 兼容 | 互斥 |
| 排他锁(X) | 互斥 | 互斥 |
意向锁总结:
- 意向锁的存在是为了协调行锁和表锁的关系,支持多粒度(表锁与行锁)的锁共存。
- 意向锁是一种
不与行级锁冲突的表级锁,且意向锁之间互不排斥。 - 意向锁表明
某个事务正在某些行持有了锁,或该事务准备去 持有锁。 - 意向锁在保证并发性的前提下,实现了
行锁和表锁共存,且满足事务隔离性的要求。
2.2.1.3、自增锁
MySQL表级锁的自增锁(Auto-increment Lock),是为了确保自增主键的唯一性和连续性而使用的一种锁机制。当一个表具有自增主键(AUTO_INCREMENT)时,每当插入新行时,主键的值会自动递增。它通过在插入操作时获取表级锁来防止并发事务之间的冲突和重复,确保每个事务获得唯一的自增值。在高并发场景下,表级别的自增锁可能会成为性能瓶颈。
2.2.1.4、元数据锁
元数据锁(MDL锁)属于表锁范畴,当对一个表做增删查改操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。读锁之间不互斥,读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性,解决了DML和DDL 操作之间的一致性问题。不需要显式使用,在访问一个表的时候会被自动加上。
DDL(Data Definition Languages、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。主要的语句关键字包括 CREATE 、 DROP 、 ALTER 等。
DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等。
DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括 GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等。
2.2.2、行锁
MySQL 服务器层并没有实现行锁机制,行锁只是在存储引擎层实现,以下行锁我们都讨论 InnoDB 下的行锁。InnoDB 和 MyISAM 最大的不同点:① 支持事务 ② 采用了行级锁。
| 行锁优点 | 行锁缺点 |
|---|---|
锁定粒度小,发生锁冲突概率低,可实现的并发度高。 |
锁的开销比较大,加锁比较慢,易出现死锁情况。 |
MySQL的行级别锁有 记录锁(Record Locks)、间隙锁(Gap Locks)、临键锁(Next-Key Locks)、插入意向锁(Insert Intention Locks)。
2.2.2.1、记录锁(Record Locks)
记录锁(Record Lock),用于锁定数据库表中的特定记录。当事务需要对某条记录进行修改或访问时,可以使用记录锁来确保数据的一致性和并发控制。记录锁的主要作用是防止多个事务同时对同一条记录进行修改,从而避免数据冲突和不一致的结果。当一个事务获取了一条记录的锁时,其他事务无法对该记录进行修改,直到锁被释放。
记录锁分为S型记录锁和X型记录锁 :
-
当一个事务获取了一条记录的 S 型记录锁后,其他事务可以继续获取该记录的 S 型记录锁,但不能继续获取该记录的 X 型记录锁。
-
当一个事务获取了一条记录的 X 型记录锁后,其他事务既不可以获取该记录的 S 型记录锁,也不可以获取该记录的 X 型记录锁。
2.2.2.2、间隙锁(Gap Locks)
间隙锁是在 innodb的 可重复读级别才会生效,且 Next-Key Locks 实际上是由间隙锁加行锁实现的。
间隙锁(Gap Locks) 是为了 防止 并发事务中的 幻读 问题,并确保数据的一致性。许多公司的配置为:读已提交隔离级别,加上 binlog_format=row,业务上不需要可重复读的保证,就可以考虑 读已提交下操作数据的锁范围更小(没有间隙锁)。
间隙锁的工作机制:
-
- 锁定间隙:
间隙锁不仅锁定实际存在的记录,还会锁定索引中不存在的间隙。这意味着如果一个事务执行范围查询,间隙锁将会锁定查询范围内的索引条目,以及范围边缘的间隙。
- 锁定间隙:
-
- 结合行锁:间隙锁通常与行锁一起使用。当一个事务获取行锁时,InnoDB会自动获取相应的间隙锁,以确保间隙不被其他事务修改。
- 结合行锁:间隙锁通常与行锁一起使用。当一个事务获取行锁时,InnoDB会自动获取相应的间隙锁,以确保间隙不被其他事务修改。
2.2.2.3、临键锁(Next-Key Locks)
Next-Key Locks 是在InnoDB 存储引擎下,事务级别在 可重复读 的情况下使用的数据库锁,InnoDB 默认的锁就是 Next-Key Locks. Next-Key 锁本质就**是一个记录锁和一个 Gap 锁的合体**,它既能保护该条数据记录,又能阻止别的事务将新记录插入被保护记录前边的间隙。
Next-Key locks 的加锁规则,两原则、两优化、一Bug :
- 原则 ① :加锁的基本单位是 next-key lock,
next-key lock 是前开后闭区间。 - 原则 ② :查找过程中访问到的对象才会加锁。任何辅助索引上的锁,或者非索引列上的锁,最终都要回溯到主键上,在主键上也要加一把锁。
- 优化 ①:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。也就是说如果 InnoDB 扫描的是一个主键,或者是一个唯一索引的话,那 InnoDB 只会采用行锁方式来加锁。
- 优化 ②:索引上(不一定是唯一索引)的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
- 一个Bug:唯一索引上的范围查询,会访问到不满足条件的第一个值为止。
示例表 tb_table 结构及数据:
| id(主键) | user_name | tel_phone |
|---|---|---|
| 1 | 张三 | 13166666667 |
| 5 | 李四 | 13166666668 |
| 10 | 王五 | 13166666669 |
# 以下示例在 innoDB 存储引擎 可重复读 的隔离级别前提下展开
## 情况一: Session 会话1
begin;
#这一步会锁定id区间为 (1,5)之间的数据,如果其他 session会话2插入id为2,3,4的数据会阻塞。
select * from tb_table where id = 3 FOR update;
commit;
-- --------------------
## 情况二: Session 会话1
begin;
# 这一步会锁定id区间为 (1,10]之间的数据,
# 如果其他 session会话2插入id区间为(2,3,4]和[6,10)的数据会阻塞,更新id=5或id=10的数据也会阻塞。
select * from zim_user where id >3 and id <7 FOR update;
commit;
-- --------------------
## 情况三: Session 会话1
begin;
# 这一步会锁定id区间为 (1,5]之间的数据,
select * from zim_user where id >3 and id <5 FOR update;
commit;
-- --------------------
## 情况四: Session 会话1
begin;
# 这一步会锁定id区间为 (1,10]之间的数据,
select * from zim_user where id >3 and id <=5 FOR update;
commit;
-- --------------------
## 情况四: Session 会话1
begin;
# 这一步会锁定id = 5 的数据,就是单纯的行记录锁。
select * from zim_user where id =5 FOR update;
commit;
2.2.2.4、插入意向锁(Insert Intention Locks)
一个事务在插入一条记录时,需要判断一下插入位置是不是被其他事务加了 gap 锁(next-key 锁也包含了 gap 锁),如果有的话,插入操作需要等待,直到 gap 锁的那个事务提交。但是 InnoDB 规定事务在等待的时候,也需要在内存中生成一个锁结构,表明有事务想在某个间隙中插入新记录,但是现在在等待。InnoDB 就把这种类型的锁称为 插入意向锁。插入意向锁是一种 Gap 锁,在 insert 操作时产生。
插入意向锁之间互不排斥,即使多个事务在同一区间插入多条记录,只要记录本身(主键、唯一索引)不冲突,那么事务之间就不会出现冲突等待。
示例表 tb_table 结构及数据:
| id(主键) | user_name | tel_phone |
|---|---|---|
| 1 | 张三 | 13166666667 |
| 5 | 李四 | 13166666668 |
| 10 | 王五 | 13166666669 |
# 事务T1 给 id = 5 的数据加一个gap 锁。
begin;
# 这一步会锁定id区间为 (1,5]之间的数据,
select * from zim_user where id >3 and id <5 FOR update;
# 这里不 执行 commit; 保证事务 T1 一直持有锁
-------------------------------------------
# 事务 T2 插入一条数据
begin;
# 由于 T1 的间隙锁,导致 这一步阻塞,同时这里添加一个插入意向锁
insert into tb_table (id,user_name,tel_phone) values (2,'tom','13166666662');
-------------------------------------------
# 事务 T3 插入一条数据
begin;
# 由于 T1 的间隙锁,导致 这一步阻塞,同时这里添加一个插入意向锁
insert into tb_table (id,user_name,tel_phone) values (3,'jey','13166666663');
-------------------------------------------
## 事务 T1 提交后,事务T2 和事务T3 的插入并不互斥,插入意向锁之间互不排斥。

2.2.3、页锁
页锁就是在 页的粒度 上进行的锁,锁定的数据资源比行锁要多,因为一个页可以有多个行记录。页锁的开销介于表锁和行锁之间,会出现死锁。锁粒度介于表锁和行锁之间,并发度一般。
由于锁会占用内存空间,锁空间的大小是有限的,所以每个层级的锁数量是有限制的。当某个层级的锁数量超过了这个层级的阈值时,就会进行**锁升级**。锁升级就是用更大粒度的锁,代替多个更小粒度的锁,比如 InnoDB 中行锁升级为表锁,这个做可以降低占用的所空间,但是数据的并发度会降低。
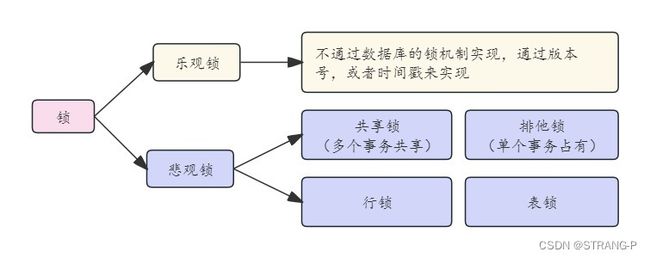
2.3、从对锁态度划分:乐观锁、悲观锁
从对待数据并发思维方式的角度来看,可将锁分为乐观锁和悲观锁。这里说的乐观锁和悲观锁并不是锁,而是锁的设计思想。
2.3.1、悲观锁
悲观锁 对数据被其他事务的修改,持悲观的保守态度,会通过数据库自身的锁机制来实现,从而保证数据操作的排他性。
悲观锁每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其他线程阻塞,用完后再把资源转让给其他线程)。比如行锁,表锁,读锁,写锁等,都是在操作之前先上锁,当其他线程想要访问数据时,都需要阻塞挂起。Java 中 synchronized 和 ReentrantLock 等独占锁就是悲观锁思想的实现。
select … for update 是 MySQL 中的悲观锁。
select … for update 语句执行过程中所有扫描的行都会被锁上,因此**在 MySQL 中用悲观锁必须确定使用了索引,而不是全表扫描,否则将会把整个表锁住**。
-- 对于并发量不高的场景,悲观锁解决 超卖示例(1、2、3步在同一个事务中):
# 第1步:查出商品库存
select quantity from tb_item where id = 1099 for update;
# 第2步:如果库存大于0,则根据商品信息产生订单
insert into tb_orders(item_id) values(1099);
# 第3步:修改商品的库存,num 表示购买数量
update tb_items set quantity = quantity-num where id = 1099;
悲观锁大多数情况下依靠数据库的锁机制来实现,以保证程序的并发访问性,但是这样对数据库性能开销影响很大,特别是对 长事务 而言,这样的开销往往无法承受,就需要乐观锁来解决。
2.3.2、乐观锁
乐观锁对同一数据的并发操作,不用每次都对数据上锁,但是在更新的时候会判断一下,在此期间别人有没有去更新这个数据。乐观锁不采用数据库自身的锁机制,而**是通过在程序上采用 版本号 或者 CAS 机制实现**。乐观锁 适用于多读 的应用类型,可以提高吞吐量。在 Java 中 java.util.concurrent.atomic 包下的原子变量类,就是使用了乐观锁的一种实现方式:CAS 实现的。
-
① 乐观锁的版本号机制
在表中设计一个
版本字段 version,第一个读的时候获取 version 的值version_value,然后对数据进行更新或者删除时,执行update … set version = version+1 where version = version_value,此时如果已经有事务对这条数据进行了更改,修改就不会成功。 -
② 乐观锁的时间戳机制
- 时间戳和版本号机制一样,也是在更新提交的时候,将当前数据的时间戳和更新之前取得的时间戳进行比较,如果两者一致则更新成功,否则就是版本冲突。
-- 对于并发量不高的场景,乐观锁解决超卖问题 示例(1、2、3步在同一个事务中):
# 第1步:查出商品库存
select quantity from tb_item where id = 1099;
# 第2步:如果库存大于0,则根据商品信息产生订单
insert into tb_orders(item_id) values(1099);
# 第3步:修改商品的库存,num 表示购买数量
update tb_items set quantity = quantity-num,version = version+1 where id = 1099 and version = #{version};
### 注意:以上方案存在两个问题:
### - ① 如果数据表是读写分离的表,当 master表中写入的数据没有及时同步到slave表中时,会造成更新一直失 败,此时需要强制读取 master表中的数据(即将select 语句放到事务中即可)。
### - ② 如果高并发场景下,每次修改库存只有一个事务能更新成功,在业务感知上就有大量的失败操作。
### 优化方案(1、2、3步在同一个事务中):
# 第1步:查出商品库存
select quantity from tb_item where id = 1099;
# 第2步:如果库存大于0,则根据商品信息产生订单
insert into tb_orders(item_id) values(1099);
# 第3步:修改商品的库存,num 表示购买数量
update tb_items set quantity = quantity-num where id = 1099 and quantity-num > 0;
乐观锁和悲观锁的适用场景:
乐观锁适合 读操作多的场景,相对来说写的操作比较少。它的**优点在于 程序实现,不存在死锁问题**。乐观锁阻止不了除了程序以外的数据库操作,所以适用场景也会相对乐观。悲观锁适合写操作多的场景,因为写的操作具体排他性。采用悲观锁的方式,可以在数据库层面阻止其他事务对该数据的操作权限,防止 读-写 和写-写 冲突。
2.4、从加锁方式划分
从加锁方式划分,可以分为 隐式锁、显式锁。
2.4.1、 隐式锁
隐式锁并不是在SQL语句中明确指定的,而是由InnoDB引擎根据特定操作自动添加的。
一个事务对新插入的记录可以不显式的加锁(生成一个锁结构),但是由于事务id 的存在,相当于加了一个 隐式锁。别的事务在对这条记录加 S 锁 或 X 锁 时,由于 隐式锁 的存在,会先帮助当前事务生成一个锁结构,然后自己再生成一个锁结构后进入等待状态。隐式锁是一种 延迟加锁 的机制,从而来减少加锁的数量。隐式锁在实际内存对象中,并不含有这个锁信息,只有当产生锁等待时,隐式锁转化为显式锁。
隐式锁的逻辑过程如下:
- ① InnoDB 的每条记录中,都有一个隐含的
trx_id字段,这个字段存在于聚簇索引的 B+Tree 中。- ② 在操作一条记录前,首先根据记录中的 trx_id 检查该事务是否是活动的事务(未提交或未回滚),如果是活动的事务,首先将
隐式锁转换为显式锁(就是为该事务添加一个锁)。- ③ 检查是否有锁冲突,如果有冲突,创建锁,并设置为 waiting 状态。如果没有冲突不加锁,跳到第 ⑤ 步。
- ④ 等待加锁成功,被唤醒,或者超时。
- ⑤ 写数据,并将自己的 trx_id 写入 trx_id 字段。
2.4.2、显式锁
通过特定的语句进行加锁,我们一般称之为显式锁,例如:
# 显式加共享锁:
select … lock in share mode;
# 显式加排它锁
select … for update;
2.5、其他锁
2.5.1、全局锁
全局锁就是对 整个数据库实例 加锁,当需要对整个数据库处于 只读状态 的时候,可以使用该命令,之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。全局锁的典型使用场景是:做全库逻辑备份。
# 全局锁命令:
Flush tables with read lock;
2.5.2、死锁
死锁:两个及以上事务,都持有对方需要的锁,并且在等待对方释放,并且双方都不会释放自己的锁。示例:
| 步骤 | 事务1 | 事务2 |
|---|---|---|
| 1 | start transaction; update account set money =50 where id =2; |
start transaction; |
| 2 | update account set money = 10 where id =4; | |
| 3 | update account set money = 20 where id =4; | |
| 4 | update account set money =60 where id =2; |
产生死锁的必要条件:
① 两个或者两个以上的事务,每个事务都已经持有锁,并且申请新的锁。
② 锁资源同时只能被同一个事务持有或者不兼容。
③ 事务之间因为持有锁和申请锁导致彼此循环等待。
死锁的关键在于:两个及以上的 Session会话加锁的顺序不一致。
如何处理死锁:
-
① 等待,直到超时(innodb_lock_wait_timeout=50s).
- 当两个事务相互等待时,当一个事务等待时间超过设置的阈值时,就将其
回滚,另外事务继续进行。InnoDB中,参数innodb_lock_wait_timeout用来设置超时时间。 - 缺点:对于在线服务来说,该等待时间往往无法接受。
- 当两个事务相互等待时,当一个事务等待时间超过设置的阈值时,就将其
-
② 使用 InnoDB 的 wait-for graph 算法来主动进行死锁检测,从而处理死锁。
- 每当加锁请求无法立即满足需要,并进入等待时,wait-for-graph 算法都会被触发。
- wait-for graph 死锁检测的原理,是构建一个以事务为顶点、锁为边的有向图,判断有向图是否存在环,存在既有死锁。
- 一旦检测到回路、有死锁,InnoDB会选择
回滚undo量最小的事务,让其他事务继续执行(innodb_deadlock_detect=on表示开启这个逻辑)。 - 缺点:每个新的被阻塞的线程,都有判断是不是由于自己的加入导致了死锁,该操作的时间复杂度为O(n),如果100个并发线程同时更新同一行,意味着要检测 100*100=1万次。可以使用消息中间件,控制同一行数据的并发访问。
如何避免死锁:
- ① 合理设计索引,使业务 SQL 尽可能通过索引定位更少的行,减少锁竞争。
- ② 调整业务逻辑 SQL 执行顺序,避免 update/delete 长时间持有锁的 SQL 在事务前面。
- ③ 避免大事务,尽量将大事务拆成多个小事务来处理,小事务缩短锁定资源的时间,发生锁冲突的几率也更小。
- ④ 在并发比较高的系统中,不要显式加锁,特别是在事务里显式加锁。(如 select … fro update 语句,如果在事务里运行了 start transaction 或设置了 autocommit = 0,那么就会锁定所查找到的记录)
- ⑤ 降低隔离级别。如果业务允许,将隔离级别降低也可避免死锁。比如将隔离级别从 RR 调整到 RC,可以避免很多因为 gap 锁造成的死锁。
3、锁监控
MySQL 锁的监控,一般通过检查 innodb_row_lock 等状态变量来分析系统上的行锁的争夺情况。
show status like 'innodb_row_lock%';

- Innodb_row_lock_current_waits : 当前正在等待锁定的数量。
Innodb_row_lock_time:从系统启动到现在锁定总时间长度;(等待总时长)。Innodb_row_lock_time_avg:每次等待所花平均时间;(等待平均时长)。- Innodb_row_lock_time_max : 从系统启动到现在,等待最常的一次所花的时间。
Innodb_row_lock_waits:系统启动后到现在总共等待的次数;(等待总次数)。
MySQL 把事务和锁信息记录在 information_schema 库中,涉及到的三张表分别是 INNODB_LOCKS、INNODB_LOCK_WAITS、INNODB_TRX.
MySQL8.0 版本删除了
information_schema.INNODB_LOCKS,添加了performance_schema.data_locks查看事务的锁情况,其可以看到阻塞该事务的锁,也可看到该事务所持有的锁。MySQL8.0 版本
information_schema.INNODB_LOCK_WAITS被performance_schema.data_lock_waits所取代。
.