《汇编语言》——王爽第三版笔记(7-9章)
书籍电子版 提取码: b62a
第七章:更灵活的定位内存地址的方法
and和or指令
按位与和按位或,and置0,or置1
and ax, 11111110 ;最后一位置0
or ax, 00000001 ;最后一位置1
关于ASCIIC码
一种常用的编码方案,a = 97 = 61H, A = 65 = 41H
以字符形式给出数据
在汇编程序中用’……'的方式指明数据是以字符的形式给出的,编译器可以将它们转化为相应的ASCII码
assume cs:code, ds:data
data segment
db 'unIX'
data ends
……
显然ASCII码不超过255, 也就是FFH,所以一个字节表示一个字母。
大小写转换问题
'A’的ASCII码是65,'a’的ASCII码是97。后面的字母又是一个接一个接上的,所以大小写的转换可以用加减32进行计算。

但是程序必须判断出当前字母是大写或是小写。还没有学if语句,怎么办。
通过观察它们的二进制数可以得出一个规律,大写字母的第5位二制数都是0,而小写字母的二进制数都是1。
如果想把大写转小写,就把第5位置1,可以用or来实现。
如果想把小写转大写, 就把第5位置0,可以用and来实现。
assume cs:code, ds:data
data segment
db 'BaSiC' ;五个字母
db 'iNfOrMaTiOn' ;十一个字母
data ends
code segment
start: mov ax, data
mov ds, ax ;获得data的地址
mov bx, 0 ;偏移地址清零
mov cx, 5 ;五个字母循环5次
s: mov al, [bx]
and al, 11011111b ;第5位置0,转成大写
mov [bx], al ;置完送回原位
inc bx
loop s
mov bx, 5
mov cx, 11
s0: mov al, [bx]
or al, 00100000b
mov [bx], al
inc bx
loop s0
mov ax, 4c00h
int 21h
code ends
end start
[bx + idata]
mov ax, [bx + idata]
可以用[bx + idata]来指明内存单元,也可以写成下面格式
mov ax, [idata + bx]
mov ax, idata[bx]
mov ax, [bx].idata
用[bx + idata]的方式进行数组的处理
assume cs:code, ds:data
data segment
db 'BaSiC'
db 'MinIX'
data ends
code segment
start: mov ax, data
mov ds, ax
mov bx, 0
mov cx, 5
s: mov al, [bx] ; mov al, 0[bx]
and al, 11011111b
mov [bx], al ; mov 0[bx], al
mov al, [5+bx] ; mov al, 5[bx]
or al, 00100000b
mov [5+bx], al ; mov 5[bx], al
inc bx
loop s
mov ax, 4c00h
int 21h
code ends
end start
SI和DI
source index 源变址寄存器
destination index 目的变址寄存器
这两个寄存器与bx的功能相近,但是不可以分成两个8位寄存器来使用
assume cs:code, ds:data
data segment
db 'welcome to masm!'
db '................' ;将上面的移到下面
data ends
code segment
start: mov ax, data
mov ds, ax
mov si, 0
mov cx, 8
s: mov ax, [si]
mov 16[si], ax
add si, 2
loop s
mov ax, 4c00h
int 21h
code ends
end start
[bx+si]和[bx+di]
mov ax, [bx+si]
mov ax, [bx][si]
[bx+si+idata]和[bx+di+idata]
多种表达,注意idata表示常量
mov ax, [bx + idtata + si]
mov ax, 200[bx][si]
mov ax, [bx][si].200
mov ax, [bx].200[si]
不同寻址方式的灵活应用
- 将每个单词的首字母都改成大写
assume cs:code, ds:data
data segment
;db '0123456789abcdef'
db '1. file '
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
data ends
code segment
start: mov ax, data
mov ds, ax
mov bx, 0
mov cx, 6
s: mov al, [bx + 3]
and al, 11011111b
mov [bx + 3], al
add bx, 16
loop s
mov ax, 4c00h
int 21h
code ends
end start
- 将每个单词都改成大写
assume cs:code, ds:data, ss:stack
data segment
;db '0123456789abcdef'
db 'ibm '
db 'dec '
db 'doc '
db 'vax '
data ends
stack segment
stack ends
code segment
start: mov ax, data
mov ds, ax
mov bx, 0
mov ax, stack
mov ss, ax
mov sp, 16
mov cx, 4
s0: push cx
mov si, 0
mov cx, 3
s: mov al, [bx + si]
and al, 11011111b
mov [bx + si], al
inc si
loop s
add bx, 16
pop cx
loop s0
mov ax, 4c00h
int 21h
code ends
end start
这里用到了二重循环,用bx来表示首字母开头,用si来表示后面的字母。最终字母由[bx+si]来确定。
重点是cx只有一个,但是两个循环都要靠它,那怎么办。
内层在循环是势必要用到cx,而外层的cx就变成了内层的,只要将外层的cx在开始时保存起来,loop时再放回cx中,让它减1。可以用寄存器来,但是寄存器是有限的,所以最好不要,最后选择了内存,而栈内存正好可以满足。
所以,用栈来存外层的cx
C语言等高级语言,也是用栈来存每次调用函数中的内容。 一般来说,在需要暂存数据的进候,都应该使用栈。
将段中每个单词的前4个字母改成大写
assume cs:code, ss:stack, ds:data
data segment
;db '0123456789abcdef'
db '1. display '
db '2. brows ' ;额头
db '3. replace ' ;代替
db '4. modify ' ;修改
data ends
stack segment
stack ends
code segment
start: mov ax, data
mov ds, ax
mov ax, stack
mov ss, ax
mov sp, 10h ;栈顶别忘了
mov cx, 4
s0: push cx
mov si, 3
mov cx, 4
s: mov al, [bx + si]
and al, 11011111b
mov [bx + si], al
inc si
loop s
add bx, 16
pop cx
loop s0
mov ax, 4c00h
int 21h
code ends
end start
实验6:上面已经完成
第八章:数据处理的两个基本问题
处理的数据在什么地方
要处理的数据有多长
定义
-
reg为寄存器
-
sreg为段寄存器
bx, si, di, bp
-
在8086CPU中,这四个寄存器都可以用在[……]中
-
它们可以单独出现, 或者只能4种组合出现
- bx和si
- bx和di
- bp和si
- bp和di
至于bx和bp,si和di是不可以同时出现的,简单来说,就是不能出现字母一样的。
-
如果只给了[bp],那么它的段地址就是ss
机器指令处理的数据在什么地方
处理可以分为3类:
- 读取
- 写入
- 计算
在数据的数据也可以在3个地方
- CPU内部
- 内存
- 端口
汇编语言中数据位置的表达
- 立即数(idata)
- 寄存器
- 段地址(SA)偏移地址(EA)
寻址方式

指令要处理的数据有多长
- 通过寄存器名指明要处理的数据的尺寸
mov ax, [0] ;长度就为2字节,也就是一个字
mov al, [0] ;长度就为1字节
- 如果没有寄存器名,可以用操作符X ptr, X在汇编中可以是word或byte
mov word ptr ds:[0], 1 ;指明访问的内存单元是一个字
mov byte ptr [1], 2 ;指明访问的内存单元是一个字节
- 其它方法(push只对字进行操作)
寻址方式的综合运用

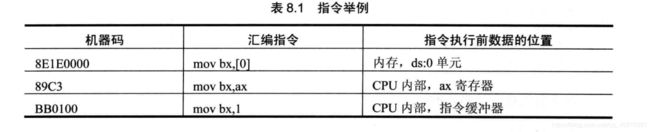
如题,题目描述与内存结构如图表示。
现要将其中的内容进行更改:
- 排名改至38位
- 收入增加70
- 产品变成VAX
assume cs:code, ds:data
data segment
;db '0123456789abcdef'
db 'DEC ' ;00h
db 'Ken Oslen ' ;10h
dw 137, 0, 0, 0, 0, 0, 0, 0 ;20h
dw 40, 0, 0, 0, 0, 0, 0, 0 ;30h
db 'PDP ' ;40h
data ends
code segment
start: mov ax, data
mov ds, ax
mov bx, 0
mov word ptr [bx + 20h], 38
add word ptr [bx + 30h], 70
mov si, 0
mov byte ptr [bx + 40h + si], 'V'
inc si
mov byte ptr [bx + 40h + si], 'A'
inc si
mov byte ptr [bx + 40h + si], 'X'
mov ax, 4c00h
int 21h
code ends
end start
这里数字没有用’'包起来, 是因为最后表示的是ASCII码,这样不便于加减。
[bx].10h[si]
dec.cp[i]
这两条指令是不是很相似?


div指令
除法指令:
除数:8位或者16位, 在一个reg或者内存单元中
被除数:
- 如果除数是8位,被除数就为16位,放在AX中
- 如果除数是16位,被除数就为32位,放在DXAX中,其中DX在高位,AX在低位
结果:
- 如果除数是8位,AL为商,AH为除数
- 如果除数是16位,AX为商,DX为除数
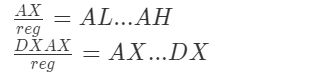
可以看出,商一定AX中。
编程:利用除法指令计算100001/100
- 被除数大于65535,不能于ax存放,所以用dxax,100001d = 186a1h
mov dx, 1h
mov ax, 86a1h
- 除数放入bx中
mov bx, 100
- 得到结果
div bx
编程:利用除法指令计算1001/100
mov ax, 1001
mov bl, 100
div bl
除数一定要明确是8位还是16位
伪指令dd
定义双字型数据
dup
和dd,dw,db一样的伪指令,dup用来进行数据的重复
db 3 dup (0)定义了三个字节
db 3 dup (0, 1, 2)定义9个字节,0,1,2,0,1,2,0,1,2
实验7:寻址方式在结构化数据访问中的应用
第9章:转移指令的原理
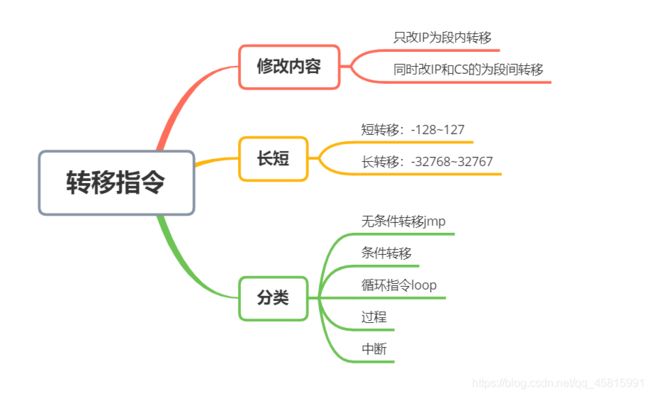
可以修改IP,或同时修改CS和IP的指令统称为转移指令
操作符offset
取得标号的偏移地址
jmp指令
给出两种信息:
- 转移的目的地址
- 转移的距离(段间转移、段内短转移、段内近转移)
依据位移进行转移的jmp指令
jmp short 标号
这条语句执行:会将IP加上一个8位位移
- 8位位移=标号处的地址-jmp指令后的第一个字节的地址
- short表明是8位位移
- 范围应该是-128~127,用补码表示
- 8位位移由编译器在编译时算出
相似的是
jmp near ptr 标号
不过它是16位的位移
转移的目的地址在指令中的jmp指令
前面的jmp指令,其对应的机器指令中并没有转移的目的地址。而是相对于当前IP的转移。
jmp far ptr 标号
CS = 标号所在的段地址
IP = 标号所在的偏移地址
转移地址在寄存器中的jmp指令
格式:jmp 16位reg
功能:IP= 16位reg
转移地址在内存中的jmp指令
-
jmp word ptr 内存单元地址(段内转移)内存单元中的是偏移地址
-
jmp dword ptr 内存单元地址(段间转移)内存单元中高地址是目的段地址,低地址是转移的目的偏移地址
CS = 内存单元+2
IP = 内存单元
jcxz指令
有条件转移指令,短转移,在对应机器码中包含转移的位移。范围-128~127
指令格式:jcxz 标号 (如果cx = 0,转移到标号处执行)
操作:当cx为0时, IP = IP + 8位位移
loop指令
循环指令,短转移。范围-128~127
指令格式:loop 标号(cx = cx - 1,cx不为0,转到标号)
操作:cx = cx - 1,如果cx不为0,IP = IP + 8位位移
根据位移进行转移的意义
方便程序段在内存中浮动装配,在内存中的不同位置都可以执行。
编译器对转移位移超界的检测
转移范围-128~127,超了程序会报错。