Speech Synthesis,语音合成详解——语音信号处理学习(八)
参考文献:
[1] Speech Synthesis(1/2)- Tacotron哔哩哔哩bilibili
[2] 2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 TTS - 14 - 知乎 (zhihu.com)
[3] Speech Synthesis (2/2) - More than Tacotron哔哩哔哩bilibili
[4] 2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 Beyond Tacotron - 15 - 知乎 (zhihu.com)
本次省略所有引用论文
目录
一、简单的背景介绍
课程大纲介绍
最早的语音合成
Concatenative Approach(拼接方法)
Parametric Approach(参数化方法)
Deep Voice
二、Tacotron:End-to-end TTS
模型对比
Tacotron 模型介绍
Tacotron Encoder
Tacotron Attention
Tacotron Decoder
Tacotron Post Processing Network
三、Tacotron的表现
一代与二代的表现差异
Dropout 的妙用
四、Tacotron 之外
Tacotron 的问题
Tacotron 的改进——Encoder
Tacotron 的改进——Attention
Fast Speech——不用Seq2Seq
Dual Learning(双向学习):ASR & TTS
五、Controllable TTS(可控文本到语音)
简单的分类
TTS vs VC (Voice Conversion)
怎么做
GST-Tacotron
Two-Stage Training
六、补充一些问题
一、简单的背景介绍
课程大纲介绍
-
TTS:Text-to-Speech,即文字到语音,也就是我们这个课程所要完成的内容:语音合成。目前的语音合成技术都是端对端训练的。课程大纲会先讲在深度学习流行之前,业界是怎么做的,再讲我们要怎样控制 TTS 来合成出我们想要的声音。
-
下图就是本课程的大纲:
最早的语音合成
-
语音合成最早能找到的资料在1939年。VODER 是一个在美国世博会上展示的语音合成系统。例子可以参考 vintagecomputermusic.com/mp3/s2t9_Computer_Speech_Demonstration.mp3。当时的语音合成像电子琴。通过操控琴键去合出不同的声音。
-
在1960年代,Johb 在贝尔实验室,用一台 IBM 的电脑,合成出了语音。链接点进去可以试听。它听起来像是机器人的声音。唱歌的时候像是鬼畜。但是现在的语音合成声音都太真实了,没有还原机器人声音的感觉。有时候,我们会特地让合成的人声不那么真实,以防用户听起来难辨真假,造成恐怖谷效应。
Concatenative Approach(拼接方法)
-
过去商业使用的语音合成技术采用的就是拼接方法 Concatenative Approach。它的思路很直观,直接构建一个庞大的声音数据库。比如想合成“你好吗”,就从数据库中挑出“你”,“好“,”吗”三个字的声音,然后拼接在一起。

-
直接拼接出来声音会听得不自然,这也是这个方法的研究方向,即怎么挑选出能拼接起来听得自然的语音片段。很多b站的鬼畜就是把一个人说话的字扒下来然后组合,也就是被调侃的所谓“活字印刷术”,就是类似的技术。
-
然而,这个方法有一个很大的缺陷,即合成声音不丰富,要合成某人的声音,语料库里必须要有和这个人声音类似的声音资料才行,而不能合成语音数据中没有的。并且如果需要使用,则必须将整个语料库都存在本地中,非常占用存储空间。
Parametric Approach(参数化方法)
-
进入机器学习的时代,我们就希望能用机器学习来完成语音合成。这其中诞生了使用HMM、Deep Learning等技术来做的语音合成。最有名的当属 HTS 。然而,果用 HMM 筛选出每个 STATE 概率最高的语音,那么你得到的通常都是同一段语音。它们也不是端对端的,而是参数化的方法,非常复杂,这也不是我们需要研究的。

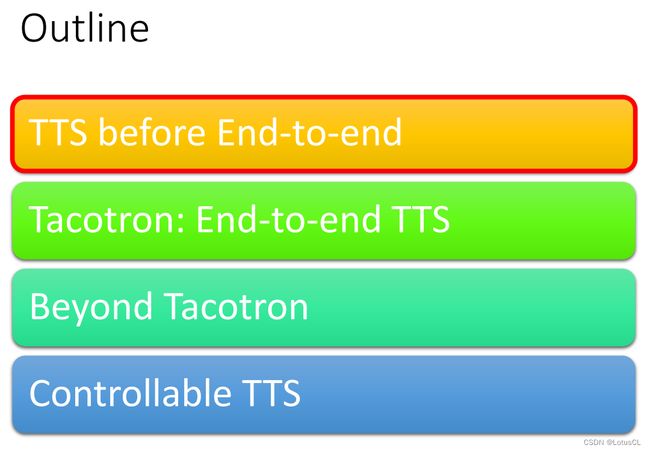
Deep Voice
-
这个模型是进入端到端语音模型时代前最接近端到端的模型,百度开发的。它将许多module串联起来,实现了语音合成。我们简单介绍一下各个module:
-
Grapheme-to-phoneme:给定文字猜测发音(phoneme)。并将输出结果传入给另外两个module。
-
Duration Prediction:给定phoneme,来猜测每个发音需要读的时间。
-
Fundamental Frequency Prediction:给定phoneme,预测发音的音高,即声带振动频率。有一些音素,人是不发声的。这个模块也会考虑决定把那些不发声的音素给标记上。
-
Audio Synthesis:语音合成的network,吃上面3个module的输出,抛出对应的一段语音。
-
-
事实上,以上这四个模块都是基于深度学习的,串起来进行训练就是端对端的了。然而,第一代的 Deep Voice 是分开进行训练然后再串起来的。Deep Voice 在第三代改进成了端对端。
二、Tacotron:End-to-end TTS
Taco 的意思是一种墨西哥卷饼,加上 tron 是为了增加它的科技感。之前它的名字本来叫作 Talktron,由于作者喜欢吃墨西哥卷饼,Talktron 又与 Tacontron 谐音,所以取了这个名字。
声谱图(spectrogram):其是一种表示语音信号在频率和时间上的信息的图像。它将语音信号在时域上进行短时傅里叶变换(Short Time Fourier Transform,STFT),然后将得到的频谱信息绘制成图像。声谱图的横轴表示时间,纵轴表示频率,而颜色或亮度则表示在特定时间和频率上的信号强度或能量。
Rule-based vocoder(基于规则的声码器):是一种合成语音的方法,它使用声码器(vocoder)基于一组预定义规则或规则集生成语音信号。与许多现代声码器不同,这种方法不依赖于机器学习或统计模型,而是使用明确定义的规则来模拟和合成语音。
模型对比
-
事实上,在 Tacotron 前就有一些端到端的TTS尝试。Tacotron的输入输出如下:
-
Input:character(字母)
-
Output:(linear) spectrogram
-
-
是的,其输出 spectrogram 线性声谱图 与 Wave 波形 只差了一个相位(phase)的信息。二者转换其实并不需要太强的 Vocoder,一个 Rule-based 的就足够了。

-
那么其他的模型呢,之前有人做过输入是 phoneme 输出是声学特征向量的,端对端的 TTS 模型。STRAIGHT 的意思是,这些声学特征向量需要丢入一个特殊的 Vocoder 才能输出声音信号;也有人做过 Char2wav 模型,输入是字,输出是 SampleRNN 的声学特征向量。
-
在所有模型中,只有 Tacotron 的方式是最一步到位的。
Tacotron 模型介绍
-
Tacotron 用的是一个典型的 Seq2Seq + Attention 的模型架构。它输出还会有个后处理(Post-processing)才会产生声音频谱(spectrogram)。

Tacotron Encoder
-
Encoder 的目的就是输入进一些字母和标点符号,输出一堆向量,类似于转为phoneme向量,告诉Decoder和注意力模块这些字母应该怎么发音。
-
字母首先通过transform变为input embeddings,然后进入一个pre-net(几层全连接层加上dropout),然后进入一个CBHG,模块架构比较复杂,架构如图所示,目的也是为了学习输入文本的高级表示。

实际上,CBHG在第二个版本中就得到了改进,变成了3层卷积和一个BiLSTM。

Tacotron Attention
-
注意力模块其实就是我们学习的普通的注意力模块。当我们开始讨论注意力模块的时候,首先要明确的一点就是实际上,输入的文字和输出的音频都有单调对应(monotonic aligned)的性质。
-
而attention模块的目的就是让机器能自动学习到每一个字母所代表的 embedding 在 decoder 那里会产生多长的声音讯号。而单调对应就意味着当我们将注意力可视化(x轴表示文字embedding,也就是编码器的输出,y轴表示音频,也就是decoder的输出),生成的可视化图案应该是呈对角线分布的。

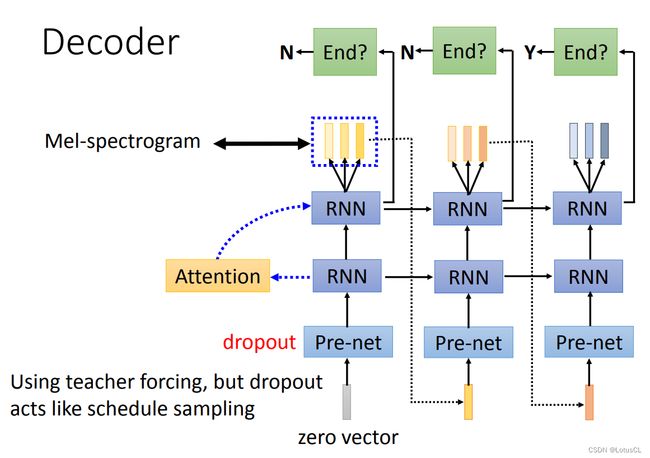
Tacotron Decoder
Mel频谱图(Mel-Spectrogram):是音频信号的一种表示形式,通常用于语音处理和音频处理任务。它是在音频信号上应用Mel滤波器组并进行傅里叶变换后得到的一种频域表示。
-
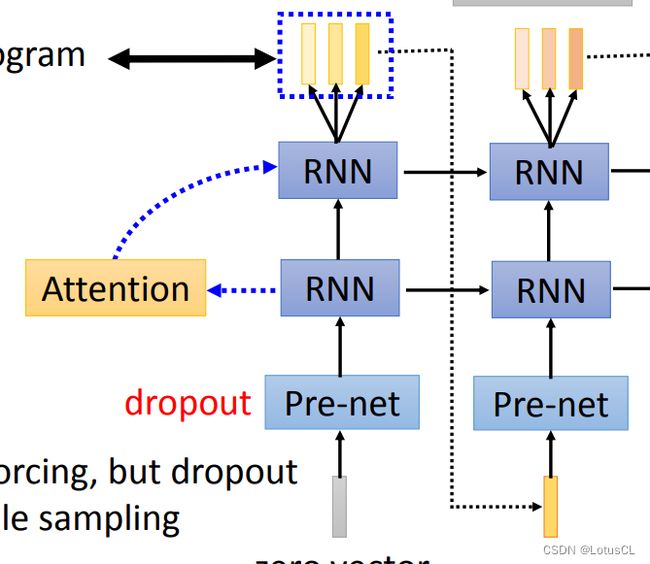
这里采用的Decoder其实就是Seq2Seq里面的Decoder。起始零向量通过一个pre-net丢给RNN,RNN做一遍attention,得到的上下文向量(context vector)丢给下一层RNN产生输出。输出再当成下一轮的输入。
-
特别的是,这次的Decoder并不是一次只产生一个vector,而是产生很多个vector,这些输出就是Mel-spectrogram。产生的数目叫作 r frames。Tacotron 的第一版中,r 可以是3或5。为什么要让它一次产生多个向量呢?因为声音信号非常长,而解码器每个时间步生成的声音又非常的短。为了让产生的速度更快,我们允许模型一次多产生几个频谱向量。
不过,在第二版Tacotron中,r就又变成1了。
-
当输出是多个向量时,我们可以把它们串起来当作下一个 RNN 的输入,也可以把最后那个向量当作下一个 RNN 的输入。同时,Pre-net module中我们也加入了 dropout 操作,这个操作扮演着极其重要的角色。
-
同样,训练时我们依旧采用 teacher forcing ,有意思的是在Seq2Seq中,最后的输出是通过采样获得的,而Tacotron 却没有采样过程,那么就会导致训练和测试脱节(训练每层吃的都是正确输出,这咋整),这时 dropout 就能够让正确答案变得不那么正确,可以模拟出RNN出错的情景,也就类似于采样过程了。
-
同样,以前的Seq2Seq输出的是token,我们可以判断是否模型输出了终止token来判断是否停止。这次换成了连续的向量,所以我们需要一个额外的模块,通常是一个binary classifier,来决定什么时候结束。它的输入是 RNN 的最后一个隐层和Cell,输出是一个 [0,1] 的数值,代表是否要结束的概率。
Tacotron Post Processing Network
-
在Decoder之后,Tacotron还有一个Post Processing(后处理模块),其第一代就是一个CBHG,第二代是一堆卷积层。它会把解码器输出的全部向量当作输入,然后再输出另外一排向量。
-
为什么要多这一步操作呢?因为 RNN 输出的这些向量是按顺序产生的,它只能通过前面产生的向量来产生后面的向量。有可能中途有遇到问题,想要再去改,却没有机会了。这个后处理的目标就是为了修正这些中途可能遇到的问题。
-
因而在训练Tacotron时,我们一般会有两个loss,一个是RNN的输出与正确答案的Mel-spectrogram的差距,还有一个是通过 Post Processing 后与正确答案的差距,这两个越接近越好。使用时我们还是取 Post Processing 的输出,将这些 acoustic features 丢到 vocoder 中去。
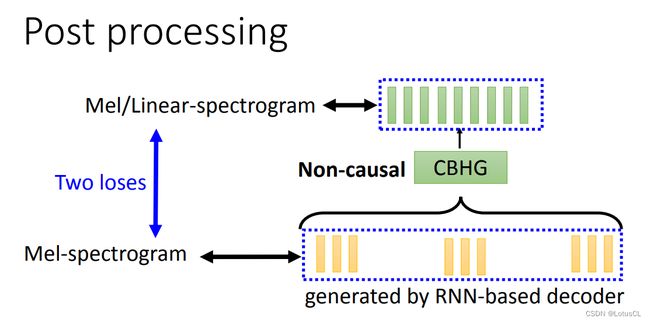
-
值得一提的是,第一代的 Tacotron 用的是一个基于规则的 Vocoder,第二代就用上了 Wavenet。

三、Tacotron的表现
一代与二代的表现差异
-
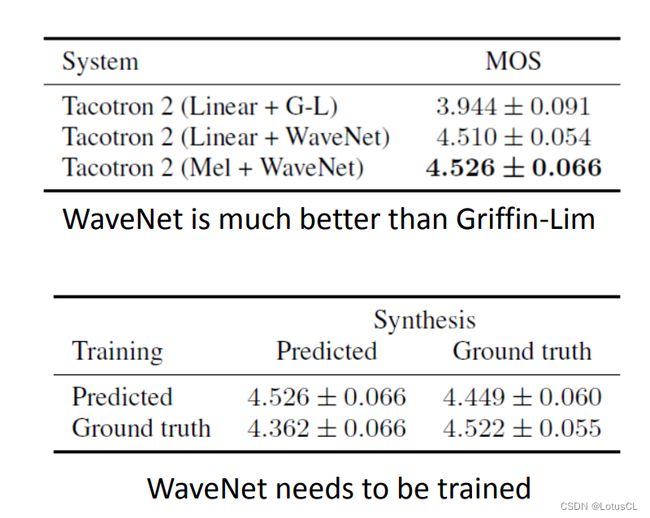
Tacotron 的结果表现如何呢?我们通常会使用一个 mean opinion score 来评估生成的语音质量。它的计算是通过找一群人,让他们听声音,给分数一个 1-5 的分数。第一代的 Tacotron 评分在 3.82,但第二代已经是 4.53 了。这个已经非常接近 Ground truth。

-
一二代的 Tacotron 差距咋这么大?主要原因是它更换了 Vocoder。从基于规则的简单Vocoder换成了基于机器学习的 Wavenet 。Wavenet 也需要数据进行训练。选择不同的数据,最终的表现也会不同。有趣的是,如果直接采用真实声音进行训练,效果反而没有采用合成的声音进行训练的效果要好。其原因也就是合成出来的 spectrogram 和 真实声音的 spectrogram 还是有一些微妙的差别的,提前告诉 Vocoder 合成的 spectrogram 长什么样,这样才能让效果变得更好。
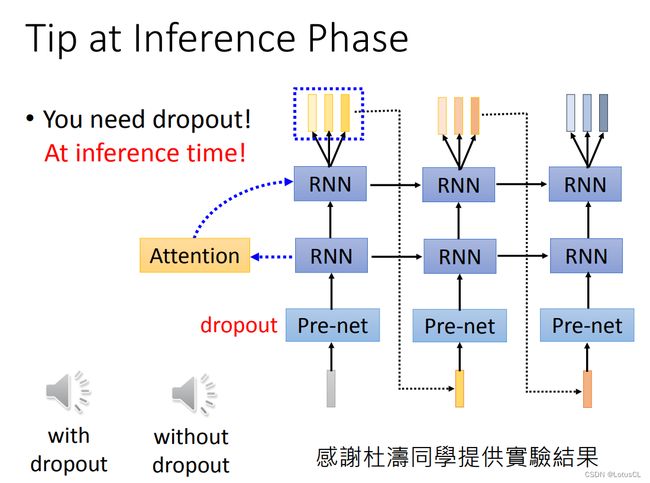
Dropout 的妙用
-
还有一个更有趣的问题,其在推理阶段也需要进行 dropout 操作。大多数模型都只是在训练的时候加入dropout,是为了让模型的健壮性更强。不会产生过拟合,而测试推理阶段则不会使用dropout。测试不用 Dropout,出来的声音是坏掉的。为什么会这样呢?目前还没有非常好的解释。
至于解释,老师在讲述的过程中给了一个类比:在用 GPT-2生成句子的时候,其实也有类似的问题。如果你每次都让 GPT-2 生成概率最大的那个词汇,它就会陷入一个奇怪的循环。它会不断地跳帧,不断地产生重复的词。所以我们需要让 GPT-2 产生一些随机文章的时候,需要让它具备一定的随机性,即用分布采样得到输出的词汇。这样其它概率的词也有机会生成出来。由此我们可以推断,Tacotron 需要在测试用 Dropout 的理由也是这样的。Dropout 能让 Tacotron 在生成新语音频谱的时候,考虑一些随机性。不然它就会像 GPT-2 那样陷入重复循环。
四、Tacotron 之外
Tacotron 的问题
-
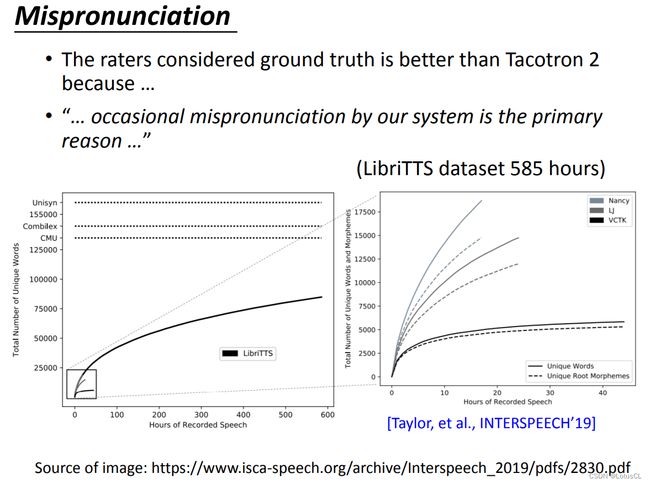
虽然 Tacotron 2代的音质已经非常好了,但偶尔会出现单词发音出错的问题。原因是什么?我们说,实际上语音合成任务并不需要像训练语音识别模型那样上万小时的有标注数据。 数据集平均一个人的声音有 20 多个小时,就能保证合成出来的声音品质非常高。但是,20多个小时的人声是无法保证词汇量的。VCTK 数据集词汇大概在 5000 左右。就算是 Nancy 词汇量也不到 2 万。目前最大的公开数据集像 LibriTTS 的词汇量也才不到 10 万。一般英文词典的数量,都是十万以上。
-
模型虽然能猜测英文的单词的音素。但是它看过的词汇不够,没法准确估计出每个词应有的发音方式。所以它在看到生僻词或新词时,会念错。使用者会对此难以接受。我们要怎么办呢?
-
一个解决方法是,我们不再选用字符character作为输入,而是选择一个高质量词表(lexicon),将字符转为音素phoneme,这样似乎就不会念错。但这样的方法仍然有问题。比如说创造的新的词汇,那就不在词典里,就无法发音了。那咋办?我们可以同时考虑字符和音素混合输入(hybrid input)。以及如果发现模型预测的声音错了,在知道了正确的发音后,我们可以将正确发音加入词表中,这样就能立即纠正模型。

Tacotron 的改进——Encoder
BERT(Bidirectional Encoder Representations from Transformers):是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。BERT的关键在于使用了双向(Bidirectional)的训练方式来理解上下文,并且采用了Transformer的机制。
-
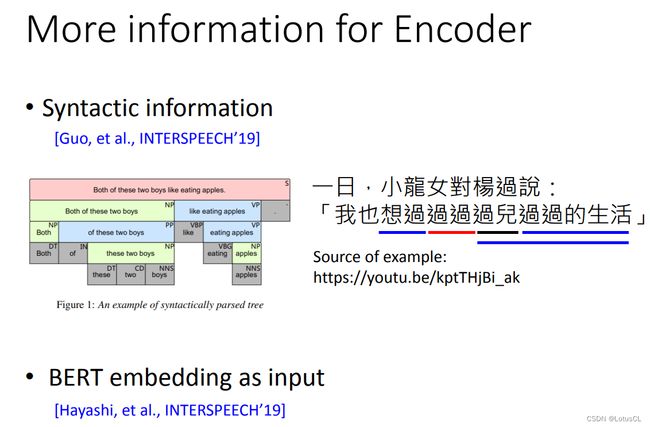
对于 Encoder,我们也可以加上文法的信息。文法会将一句话切割成各类成分,比如主语宾语名词等,这将对一个句子的语气、停顿等起到作用。
应用场景:比如小龙女对杨过说:”我也想过过过过儿过过的生活。“,在拆分后模型就知道了应该拆成:”我也想过/过过/过儿/过过/的生活。“
-
也有人把 BERT 的嵌入当作是 Tacotron 的输入来做语音合成。其中的直觉是,BERT 利用自注意力机制,它的每一个字嵌入都融合了上下文信息,当然也融合了语义句法信息。这些信息对语音合成是有帮助的。
Tacotron 的改进——Attention
-
在前面我们说过,希望注意力机制中,有关文本和语音的注意力对应关系呈一条对角线。那么我们如何才能达到这种效果呢?我们可以采用 Guided Attention 。原来的 Tacotron 损失是计算模型输出与目标语音越接近越好。而 Guided Attention 则是在原来的损失上,再加上一项对注意力的正则化(regulation)。我们让红色部分一旦出现权重则loss就会非常大,给予一定的惩罚,这样就可以了。

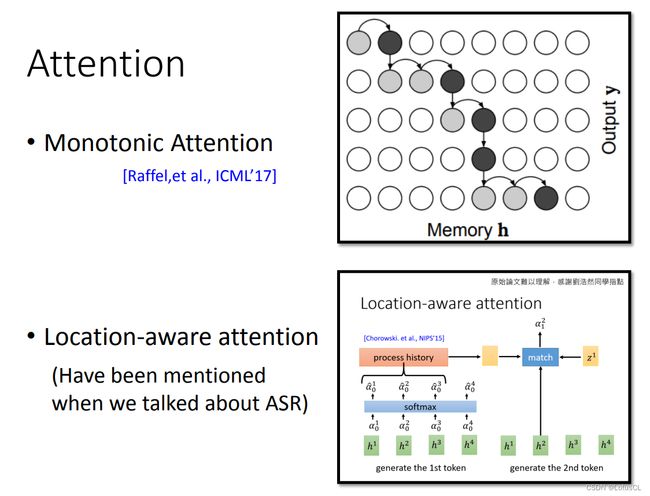
-
除此以外,还有一些非常强的限制,比如 Monotonic Attention 会要求注意力一定要从左往右。还有在 ASR 中讲到过的 Location-aware attention,这其中就是要求在产生attention时,必须要知道前一个产生的attention。
-
事实上,注意力机制有很多值得研究的奇技淫巧,并且注意力机制对于最终的模型生成质量也有很大的影响。
-
ICASSP 2020 的这篇文章有分析注意力对语音合成有多么重要。这篇论文做了一个有趣的实验。它只拿 LJ Speech 数据集中小于 10s 的声音训练。但测试的时候,故意让机器去念哈利波特的很长的超过 10s 的句子。结果发现,如果 Attention 选的不好,比如用 Content-Based 都是会训练坏掉。

-
衡量指标的计算方式为,用合成的声音,喂给现有的语言识别系统转换为文字后,对照目标的文稿看看有多少词汇是错的。这个错的差异越大,代表语音合成系统表现越糟。实验表明,用 GMMv2b 或 DCA 的注意力结果就会好。
-
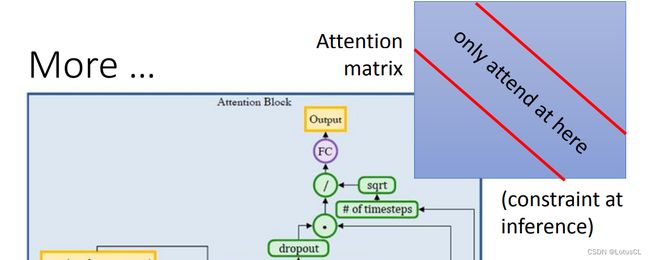
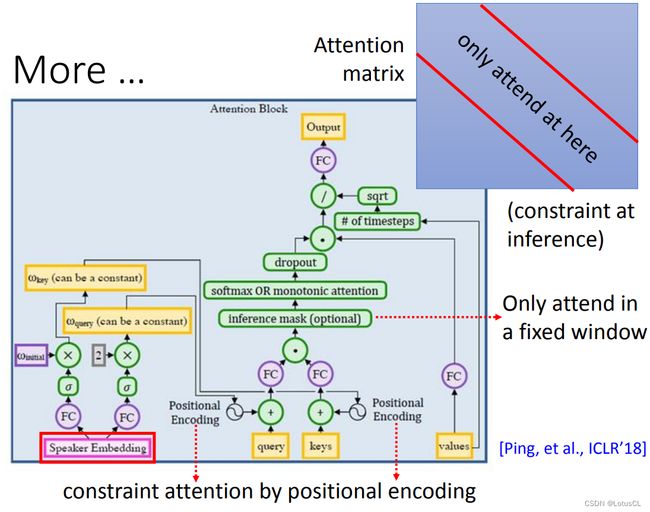
或者,我们可以做得更决绝一些。既然我们希望解码器的注意力权重矩阵是成对角线的,何不直接在推断的时候,把attention 的 weight 非对角线的区域直接设置为0呢?结果发现这个技巧是很有用的。而且不需要改变训练过程。
-
此外,还有一个神奇的技巧是,它把输入注意力的 Query (decoder 产生) 和 Keys (encoder 产生) 都加上了位置编码信息。这样可以加强注意力的计算。而且 Positional Encoding 是由 Speaker 的嵌入信息来调整操控的。这个 Speaker 嵌入包含了说话者的音色、感情和速度等信息。直觉上看,说话者的速度信息是会影响到位置编码的。
Fast Speech——不用Seq2Seq
Fast Speech 和 Duration Informed Attention 是不同团队在同一时间提出的类似的想法。
-
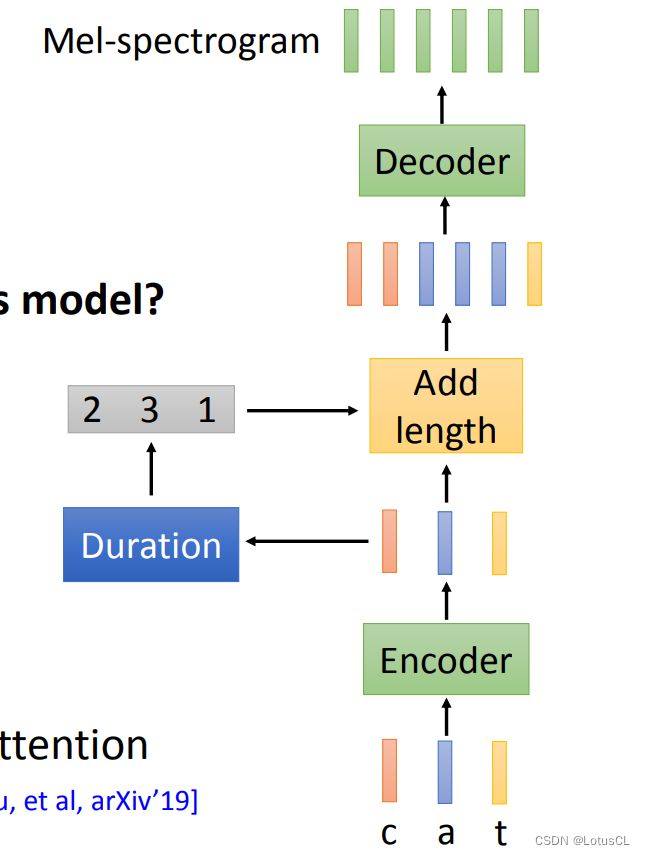
我们在 Tacotron 中使用了有 attention 的 Seq2Seq 模型,是因为我们的输入和输出序列长度不同,所以采用了 Seq2Seq。而这类模型有类弊端就是可能会遗漏或重复某些片段。而现在就有一类模型没有采用 Seq2Seq。这就是 Fast Speech 模型。
-
同样有 Encoder 转 character 为 embeddings,不同的是在编码器和解码器之间单独训练了 Duration 模块,可以预测每个 character 要念多长。这个 Duration 模块会输入一个单词嵌入,输出每个字符要说的长度。比如输出是2,它就要把当前的字符嵌入复制两次。
-
那么我们应该怎么训练这个模型呢?要知道,Duration 输出的结果并不是连续的数,而是整数(离散数字),这是不能微分的。我们采用的方法是,使用正确答案单独训练 Duration,而模型其他部分的训练则也是采用正确答案对原来的 embedding 进行扩展。

-
那这个用来训练的正确答案应该从何而来?在 Fast Speech 论文中,是先训练了一个 Tacotron ,然后根据 Tacotron 的 Attention 来计算 character 和 acoustic feature 长度的对应关系。当然理论上也可以通过语音识别系统做 Alignment 来获得。
-
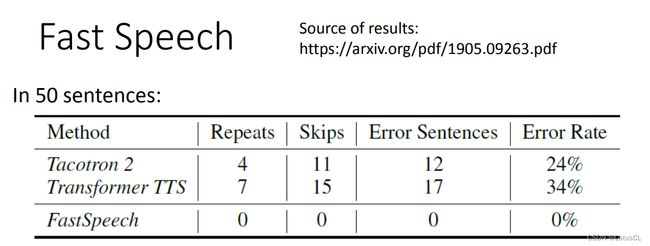
模型的表现如何?原论文做的实验中,FastSpeech 使用了 Duration 模块的好处是,它不会像 Tacotron 或 基于 Transformer 的 TTS 那样,有一些发音上的瑕疵,比如结巴,跳过词汇没念,念错词汇的情况。直觉上看,FastSpeech 在 Duration 上做了一个更大的限制,来避开这些错误。
-
其实 Tacotron 也没有论文中说的表现那么差。之所以错误这么多,是因为测试的句子是一些特殊的案例。比如很多相同的单词,或念一段网址。由于 Tacotron 训练数据中缺乏这类的语料,所以说起来比较有难度。

Dual Learning(双向学习):ASR & TTS
双向学习(Dual Learning):是一种机器学习框架,旨在通过两个相互补充的学习过程来提高模型性能。这个框架通常用于序列到序列(Sequence-to-Sequence)任务,比如机器翻译、对话生成等。
-
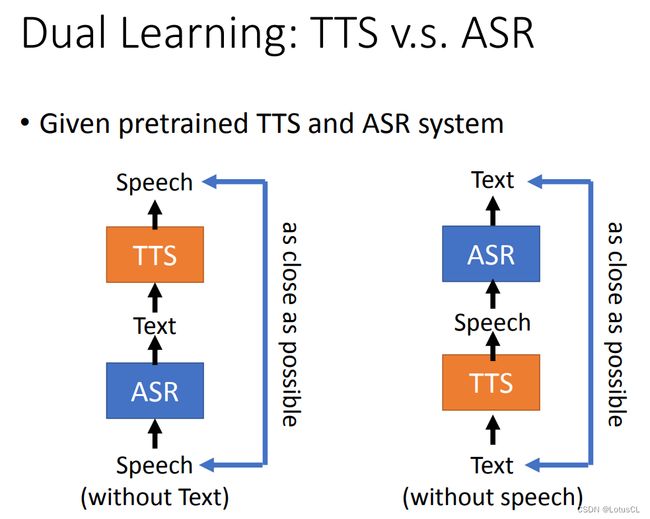
我们不难发现,ASR 和 TTS 是两个互为表里的任务,ASR 将语音转为文字,TTS 将文字转为语音。当他们串在一起就可以组成一个 Speech Chain,这个 Chain 有什么用呢?我们可以拿它来做 Dual Learning,让二位互相增进自己的能力。

-
如何来进行双向学习?假如你获得了一些语音资料,没有对应的文本,我们就可以将语音先喂给 ASR,产生对应的文字,然后再将产生的文字喂给 TTS,这样就又能产生语音,我们的训练目标就是让最终产生的语音和之前的语音尽可能接近。反过来,有文本而没有语音资料也是如此。
-
效果咋样?在实验中,我们先用成对的资料去训练两个模型,然后再加上非成对资料,使用双向学习进行训练,两个模型都有了一定的改善提升。

五、Controllable TTS(可控文本到语音)
-
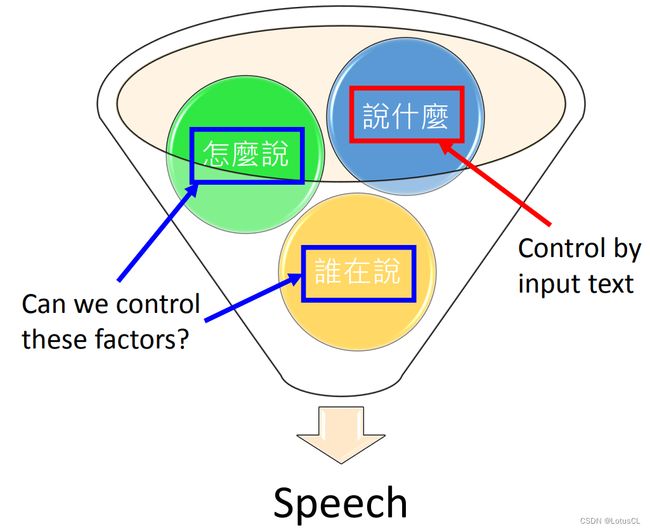
啥是 Controllable TTS ?为什么我们需要 Controllable TTS ?事实上,我们刚刚讨论的模型中,在语音层面,我们都是只关注了语音的内容,即 Speech 说了什么。然而,语音中所包含的信息远比这要多得多。比如谁在说(音色),怎么说(语速,包含的情绪,抑扬顿挫等),所以就需要对生成的语音输出进行更精细的控制和调整,以满足特定需求或实现特定效果。
简单的分类
因而,研究方向就可以分为两大类:
-
谁在说:
-
也就是合成一个特定人的声音,这种技术也被称为声音克隆(voice cloning)。
-
如果有对应目标的很多语音,我们自然可以用这些语音来对模型进行微调。然而,大部分情况下我们都难以找到足够的对应目标的高质量资料。如何用少量的资料来达成目的?
-
-
怎么说:
-
同一句话,语调、重音、韵律都可以控制
-
这些性质我们统称为抑扬顿挫(Prosody)。不过这玩意挺难定义的,有一个简单的定义如图,从反面去定义 Prosody ,讲它不是声音信号中的内容、语者音色,也不是环境的混响。

-
TTS vs VC (Voice Conversion)
-
原来的模型接受文本输出对应语音。这里我们希望再加一个参考语音(Reference audio),尝试让模型学习这个语音的说话方式。

-
这就有点像 Voice Conversion 任务了,它也是给一段 Reference Audio,抽取其中的音色信息,让模型能输出对应音色的语音。事实上,二者确实非常相像,尤其是二者的训练过程十分类似。不过前者输出的语音内容是由给定的文字决定的,后者输出的语音内容则需要另外提供一段语音来决定。

怎么做
-
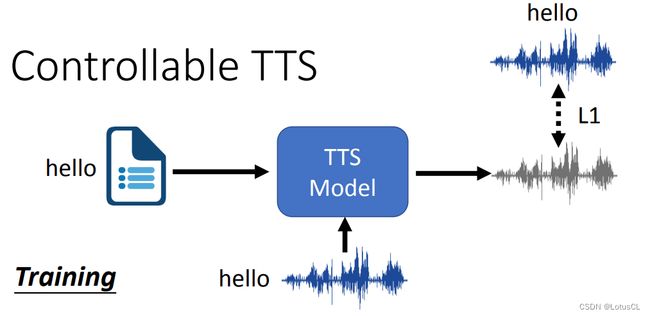
我们应该如何训练呢?理论上,我们应该将 ground truth 拿来作为 Controllable TTS 模型的输入,抽取其中的信息,然后加上文本数据,最终输出对应的语音。这听起来 CTTS 有点像 Auto Encoder,就是又多加了文字的信息罢了。
-
但是等等,你这不是直接在训练中给出了答案,让模型在训练时直接看到了答案了吗,那我直接忽略文字信息,直接复制输入的 Reference audio 岂不是就行了?这就是 Controllable TTS 的一大研究领域,即如何阻止直接复制的发生,让模型只从 Reference audio 中抽取语者的信息,而不会抽取内容的信息。

-
那么怎么做呢?我们可以用一个 Speaker Embedding 的模型,这个模型可以吃一段声音信号,吐出的向量中只包含语者的信息。这个模型需要提前训练好,在训练 TTS 的时候是固定参数不参与权重更新的。这样就逼迫着 TTS 必须要看文本信息,才能输出最终语句。

GST-Tacotron
GST 为 Global Styple Tokens 的缩写。
-
这个模型是如何阻断复制行为的呢?从名字上我们可以看出,它是 Tacotron 的进阶版本。其原理是,我们会先用一个 Encoder 来把文字变成嵌入,至于参考语音则会通过一个特征提取器变成音色的嵌入。值得一提的是,这里的特征提取器并不是预训练得到的,而是跟着整个 TTS 的模型一起训练得到的。
-
特征提取器只会输出一个向量,我们将这个向量进行复制,复制到长度和刚刚得到的 text embedding 长度一样,然后再将两个拼接(Concatenate)起来(也可以嵌入相加等其他操作),然后做 attention,之后的过程就和原版的 Tacotron 相同了。

-
那特征提取器就不会进行复制行为,将内容的信息也一并提取出来吗?精妙就在这里,GST-Tacotron 的 Feature Extractor 做了特殊的设计。
-
我们将特征提取器放大,其中的 Encoder 会把参考语音编码成一个向量,但是这个向量并不会直接当成输出,而是作为了 Attention Weight。而特征提取器里还预先定义了一组 vector set,这个 set 你可以理解为特征提取器的“参数”,当然,这些“参数”也是提前训练出来的。我们把二者加权求和(Linear Combination),才得到特征提取器的最终输出。

-
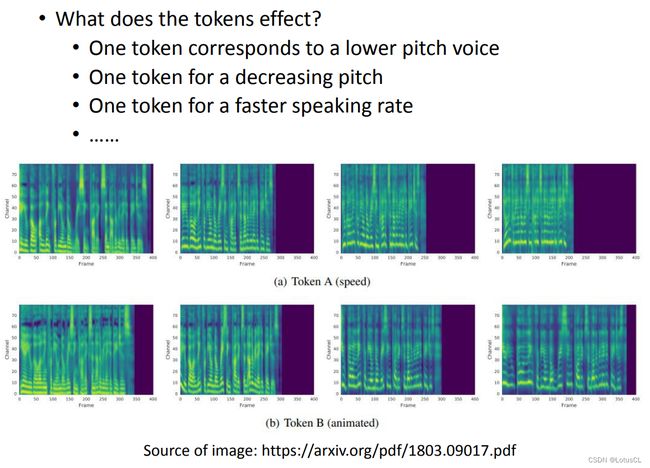
这样,编码器唯一能做到的就是控制特征参数的注意力的权重,而无法再将内容信息带出来。而这些特征参数,就是我们的 Global Style Tokens。
-
事实上,取名为 Style Tokens,正是因为这些学到的 Vector set 每个维度向量都对应了说话的每一种方式。如果你把它对应的注意力权重调高,声音就会往相应维度风格变化,即某种抑扬顿挫的元素会被改变。举例来说,某些 Style Tokens 对应了说话声音的高低,有些则对应了说话的语速。
Two-Stage Training
两阶段训练(Two-Stage Training):是一种机器学习训练策略,常用于复杂模型或任务的训练过程中。这种策略通过分阶段的训练过程来提高模型的性能和收敛速度。通常,两阶段训练的流程包括预训练阶段(Pre-training Stage)和微调阶段(Fine-tuning Stage)。
预训练阶段(Pre-training Stage): 在第一阶段,模型被用于执行一个相关但相对简单的任务或者被暴露于大规模数据集上进行无监督学习。这一阶段的目标是让模型学习到通用的特征表示或者某些模式,提高模型的初始性能和泛化能力。
微调阶段(Fine-tuning Stage): 第二阶段将在特定任务或特定数据集上对模型进行微调,以适应目标任务的需求。在这个阶段,模型会根据目标任务的标注数据或者有监督学习的方法来进一步调整参数,使得模型在特定任务上表现更好。
两阶段训练的优势在于预训练阶段可以为模型提供更好的初始化参数,使其更容易收敛到一个较好的局部最优解,同时减少了对大规模标注数据的依赖。
-
还有一种阻断方法,就是采用两阶段训练。第一阶段我们正常训练,使用的 Reference audio 和 ground truth,也就是输入的文字信息是一样的。而在第二阶段训练中,我们让文字的内容和 Reference audio 故意不一样,来进行训练。问题来了,我们哪来的 ground truth?我们可不知道用 I love you 的说话方式去说 good bye 会是什么样子的。怎么办?

-
我们可以在后面再接上一个好的 ASR,将输出的语音再转为文字,去最小化最终输出的文字与最开始输入的文字的差距,这样 TTS 就不会再从参考语音中抽出内容信息了。

-
当然,如果 TTS 和 ASR 都是 Seq2Seq model,都用到了注意力机制,我们也可以进行 attention consistency。对于 TTS 的注意力而言,输入的字母会对应它产生的声音信号。我们期待 ASR 的注意力在看到同一段声音的时候,应该也要产生相同的字母。即让两个注意力权重矩阵保持一致。
补充:
注意力一致性(Attention Consistency):是指在一种模型结构中确保多个副本或多个视图的注意力权重保持一致或者稳定的性质。这个概念通常与多模态学习或多模态注意力机制相关联。
当一个模型同时处理多个输入模态(比如图像、文本、音频等)时,它可能会采用多模态注意力机制来确定不同模态之间的相关性和重要性。在这种情况下,注意力一致性变得很重要。
具体来说,注意力一致性通常包括以下几个方面:
跨模态一致性(Cross-Modal Consistency): 在多模态任务中,不同模态之间的注意力权重应该是一致的,即相同输入的不同表示形式之间的注意力应该是稳定的。比如,在图像描述生成任务中,图像的视觉特征和对应的文本描述之间的注意力应该是一致的。
时间一致性(Temporal Consistency): 对于时序数据,例如视频处理或者音频处理中,不同时间步之间的注意力权重应该保持稳定或者有一定的连续性。这确保了模型能够持续关注相似的特征或上下文信息。
空间一致性(Spatial Consistency): 对于空间数据,如图像处理中的不同区域或对象,模型在不同部分的注意力应该保持一致,这有助于确保模型对整体和局部信息都能够合理地关注。
保持注意力一致性可以提高模型对多模态数据的理解和处理能力,有助于生成更准确和一致的预测结果。为了实现这种一致性,研究人员通常会设计特定的损失函数、约束或者正则化项,以确保模型在学习过程中保持注意力的稳定性和一致性。
六、补充一些问题
-
如何知道 GST-Tacontron 学到的不是 Speaker Identity,而是 Prosody 呢?
-
因为 GST 的数据集中只有一个说话人,所以不会有不同说话人的差异,只有抑扬顿挫的差异。
-
如果我们想做得更好一点,我们需要把 Speaker Identity 和 Prosody 再做特征分离。在语音数据集中,我们需要知道哪些句子是同一个人说的。从这些句子中,我们会抽出某些共同的 Style Vector。除掉这些共同的特征后剩下的就会是表征 Prosody 信息的向量。
-
-
GST-Tacontron 只用一个向量来表征说话的风格,这是否足够表征抑扬顿挫信息呢?
-
一个向量的表征能力有限。这未必是一个好的解决思路。我们需要实验研究,说话风格能否用一个向量来表示。会不会太粗糙了,有些信息损失,没有表示到。
-
因此有些做可控 TTS 的模型会考虑用一排向量,数量为输入序列的长度。这样每一小段声音信号,都有一个向量表征。或许这样才能真正地 Control 一个句子的 Prosody。这是一个尚待研究的问题。
-