Flink SQL深度篇
Flink SQL深度篇
问题导读
- 怎样优化Logical Plan?
- 怎样优化Stream Graph?
- TimeWindow, EventTime, ProcessTime 和 Watermark 四者之间的关系是什么?
序言
时效性提升数据的价值, 所以 Flink 这样的流式 (Streaming) 计算系统应用得越来越广泛.
广大的普通用户决定一个产品的界面和接口. ETL开发者需要简单而有效的开发工具, 从而把更多时间花在理业务和对口径上. 因此流式计算系统都趋同以 SQL 作为唯一开发语言, 让用户以 Table 形式操作 Stream.
程序开发三部曲:First make it work, then make it right, and, finally, make it fast.
让程序运行起来
- 开发者能用 SQL 方便地表达问题.
- 开发者能通过任务管理系统一体化地管理任务, 如:开发, 上线, 调优, 监控和排查任务.
让程序运行正确
- 简单数据清洗之外的流计算开发需求通常会涉及到 Streaming SQL 的两个核心扩展:Window 和 Emit.
- 开发者深入理解 Window 和 Emit 的语义是正确实现这些业务需求的关键,
- 否则无法在数据时效性和数据准确性上做适合各个业务场景的决策和折中.
让程序运行越来越快
流计算系统每年也会有很大的性能提升和功能扩展, 但想要深入调优及排错, 还是要学习分布式系统的各个组件及原理, 各种算子实现方法, 性能优化技术等知识.
以后, 随着系统的进一步成熟和完善, 开发者在性能优化上的负担会越来越低, 无需了解底层技术实现细节和手动配置各种参数, 就能享受性能和稳定性的逐步提升.
**分布式系统的一致性和可用性是一对矛盾, 流计算系统的数据准确性和数据时效性也是一对矛盾. ** 应用开发者都需要认识到这些矛盾, 并且知道自己在什么场景下该作何种取舍.
本文希望通过剖析Flink Streaming SQL的三个具体例子:Union, Group By 和 Join , 来依次阐述流式计算模型的核心概念: What, Where, When, How . 以便开发者加深对 Streaming SQL 的 Window 和 Emit 语义的理解, 从而能在数据准确性和数据时效性上做适合业务场景的折中和取舍, 也顺带介绍 **Streaming SQL 的底层实现, 以便于 SQL 任务的开发和调优. **
Union
代码
通过这个例子来阐述 Streaming SQL 的底层实现和优化手段:Logical Plan Optimization 和 Operator Chaining.
例子改编自 Flink StreamSQLExample . 只在最外层加了一个Filter, 以便触发Filter下推及合并.
Code:
package com.atguigu.tableapi
import com.atguigu.bean.Order
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala._
object UnionTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
val orderA: DataStream[Order] = env.fromCollection(Seq(
Order(1L, "bear", 3),
Order(1L, "diaper", 4),
Order(3L, "rubber", 2)
))
val orderB: DataStream[Order] = env.fromCollection(Seq(
Order(2L, "pen", 3),
Order(2L, "rubber", 3),
Order(4L, "bear", 1)
))
// 以流注册表
tEnv.createTemporaryView("OrderA", orderA)
tEnv.createTemporaryView("OrderB", orderB)
// sql
val sql =
"""
|select *
|from (
| select *
| from OrderA
| where user < 3
| union all
| select *
| from OrderB
|where product <> 'rubber') OrderAll
|where amount > 2
|""".stripMargin
val result: Table = tEnv.sqlQuery(sql)
result.toAppendStream[Order].print()
env.execute()
}
}
运行结果:
5> Order(1,diaper,4)
9> Order(2,pen,3)
4> Order(1,bear,3)
转换 Table 为 Stream: Flink 会把基于 Table 的 Streaming SQL 转为基于 Stream 的底层算子, 并同时完成 Logical Plan 及 Operator Chaining 等优化
转为逻辑计划 Logical Plan
上述 UNION ALL SQL 依据 Relational Algebra 转换为下面的逻辑计划:
LogicalProject(user=[$0], product=[$1], amount=[$2])
LogicalFilter(condition=[>($2, 2)])
LogicalUnion(all=[true])
LogicalProject(user=[$0], product=[$1], amount=[$2])
LogicalFilter(condition=[<($0, 3)])
LogicalTableScan(table=[[OrderA]])
LogicalProject(user=[$0], product=[$1], amount=[$2])
LogicalFilter(condition=[<>($1, _UTF-16LE'rubber')])
LogicalTableScan(table=[[OrderB]])
SQL字段与逻辑计划有如下的对应关系:

Logical Plan 优化
理论基础
幂等
数学: 19 * 10 * 1 * 1 = 19 * 10 = 190
SQL: SELECT * FROM (SELECT user, product FROM OrderA) = SELECT user, product FROM OrderA
交换律
数学:10 * 19 = 19 * 10 = 190
SQL: tableA UNION ALL tableB = tableB UNION ALL tableA
结合律
数学:
(1900 * 0.5)* 0.2 = 1900 * (0.5 * 0.2) = 190
1900 * (1.0 + 0.01) = 1900 * 1.0 + 1900 * 0.01 = 1919
SQL:
SELECT * FROM (SELECT user, amount FROM OrderA) WHERE amount > 2
SELECT * FROM (SELECT user, amount FROM OrderA WHERE amount > 2)
优化过程
Flink 的逻辑计划优化规则清单请见: FlinkRuleSets.
此 Union All 例子根据幂等, 交换律和结合律来完成以下三步优化:
消除冗余的Project
利用幂等特性, 消除冗余的 Project:

下推Filter
利用交换率和结合律特性, 下推 Filter:
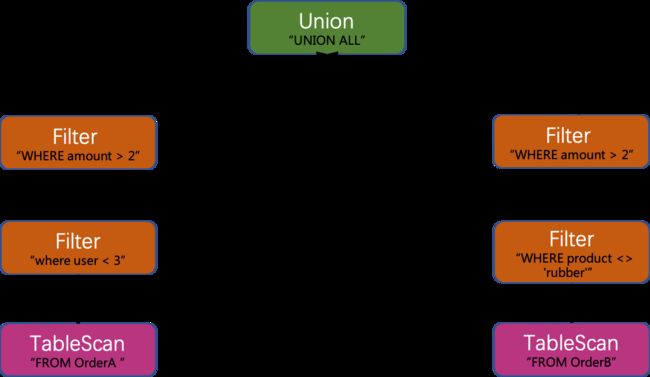
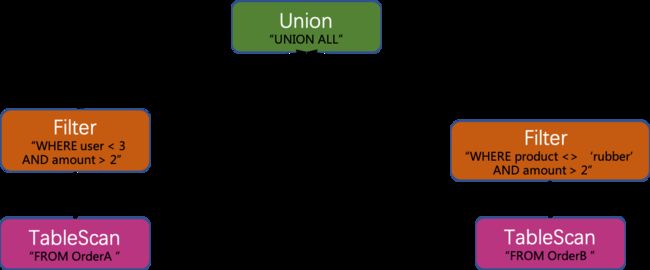
合并Filter
利用结合律, 合并 Filter:
转为物理计划 Physical Plan
转换后的 Flink 的物理执行计划如下:
DataStreamUnion(all=[true], union all=[user, product, amount])
DataStreamcCalc(select][user, product, amount], where=[AND(<(user, 3), >(amount, 2))])
DataStreamScan(table=[[OrderA]])
DataStreamcCalc(select][user, product, amount], where=[AND(<>(product, _UTF-16LE'rubber'), >(amount, 2))])
DataStreamScan(table=[[OrderB]])
优化 Physical Plan
有 Physical Plan 优化这一步骤, 但对以上例子没有效果, 所以忽略.
优化 Stream Graph
Stream Graph
这样, 加上 Source 和 Sink, 产生了如下的 Stream Graph:

通过 Task Chaining 来减少上下游算子的数据传输消耗, 从而提高性能:
Chaining 判断条件
private boolean isChainable(StreamEdge edge, boolean isChainingEnabled, StreamGraph streamGraph) {
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
StreamOperatorFactory headOperator = upStreamVertex.getOperatorFactory();
StreamOperatorFactory outOperator = downStreamVertex.getOperatorFactory();
return downStreamVertex.getInEdges().size() == 1
&& outOperator != null
&& headOperator != null
&& upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
&& outOperator.getChainingStrategy() == ChainingStrategy.ALWAYS
&& (headOperator.getChainingStrategy() == ChainingStrategy.HEAD ||
headOperator.getChainingStrategy() == ChainingStrategy.ALWAYS)
&& (edge.getPartitioner() instanceof ForwardPartitioner)
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
&& isChainingEnabled;
}
Chaining 结果
按深度优先的顺序遍历 Stream Graph, 最终产生 5 个 Task 任务:
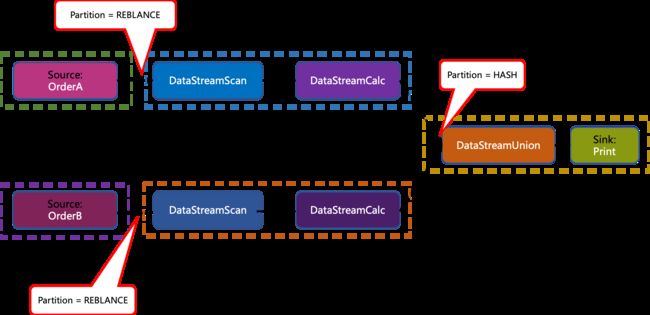
Group By
代码
package com.atguigu.tableapi
import java.sql.Timestamp
import java.text.SimpleDateFormat
import java.util.TimeZone
import com.atguigu.bean.OrderT
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala._
import org.apache.flink.types.Row
/**
* Title:
*
* Description:
*
* @author Zhang Chao
* @version java_day
* @date 2020/10/28 4:15 下午
*/
object GroupByTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val tEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
val orderA: DataStream[OrderT] = env.fromCollection(Seq(
OrderT(1L, "bear", 3, Timestamp.valueOf("2020-10-10 2:11:00")),
OrderT(3L, "rubber", 2,Timestamp.valueOf("2020-10-10 2:38:35")),
OrderT(1L, "diaper", 4, Timestamp.valueOf("2020-10-10 3:11:03")),
OrderT(1L, "diaper", 1, Timestamp.valueOf("2020-10-10 2:48:05"))
)).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[OrderT](Time.milliseconds(3000)) {
override def extractTimestamp(element: OrderT) = {
val dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
dateFormat.setTimeZone(TimeZone.getTimeZone("GMT"+8))
dateFormat.parse(element.rowtime.toString).getTime
}
})
// 以流注册表
tEnv.createTemporaryView("OrderA", orderA, 'user, 'product, 'amount, 'rowtime.rowtime)
// sql
val sql =
"""
|select
| user,
| TUMBLE_START(rowtime, INTERVAL '1' HOUR) AS startDate,
| SUM(amount) AS totalAmount
|FROM
| OrderA
|GROUP BY user, tumble(rowtime, INTERVAL '1' HOUR)
|""".stripMargin
val result: Table = tEnv.sqlQuery(sql)
result.toAppendStream[Row].print()
env.execute()
}
}
输出:
12> 3,2020-10-10 02:00:00.0,2
4> 1,2020-10-10 02:00:00.0,4
4> 1,2020-10-10 03:00:00.0,4
转换Table为Stream: 因为 Union All 例子比较详细地阐述了转换规则, 此处只讨论特殊之处.
转为逻辑计划 Logical Plan
LogicalProject(user=[$0], startDate=[TUMBLE_START($1)], totalAmount=[$2])
LogicalAggregate(group=[{0, 1}], totalAmount=[SUM($2)])
LogicalProject(user=[$0], $f1=[TUMBLE($4, 86400000)], amount=[$2])
LogicalTableScan(table=[[OrderA]])
优化 Logical Plan
FlinkLogicalCalc(expr#0..5=[{inputs}], user=[$t0], rowtime=[$t2],amount=[$t1])
FlinkLogicalWindowAggregate(group=[{0}], totalAmount=[SUM($2)])
FlinkLogicalCalc(expr#0..4=[{inputs}], user=[$t0], rowtime=[$t4],amount=[$t2])
FlinkLogicalNativeTableScan(table=[[OrderA]])
GROUP BY 优化: 把 {"User + Window" -> SUM} 转为 {User -> {Window -> SUM}}.
新的数据结构确保同一 User 下所有 Window 都会被分配到同一个 Operator, 以便实现 SessionWindow 的 Merge 功能:

转为物理计划 Physical Plan
DataStreamCala(select=[user, w$start AS startDate, totalAmount])
DataStreamGroupWindowAggregate(
groupBy=[user],
window=[TumblingGroupWindow('w$, 'rowtime, 86400000.millis)],
select=[user,
SUM(amount) AS totalAmount,
start('w$') AS w$start,
end('w$') AS w$end,
rowtime('w$') AS w$rowtime,
proctime('W$) AS w$proctime])
DataStreamCalc(select=[user, rowtime, amount])
DataStreamScan(table=[[OrderA]])
优化 Stream Graph
经过 Task Chaining 优化后, 最终生成 3 个 Task:

Streaming 各基本概念之间的联系
此处希望以图表的形式阐述各个概念之间的关系:
Window 和 EventTime
Flink 支持三种 Window 类型: Tumbling Windows , Sliding Windows 和 Session Windows.
每个事件的 EventTime 决定事件会落到哪些 TimeWindow, 但只有 Window 的第一个数据来到时, Window 才会被真正创建.
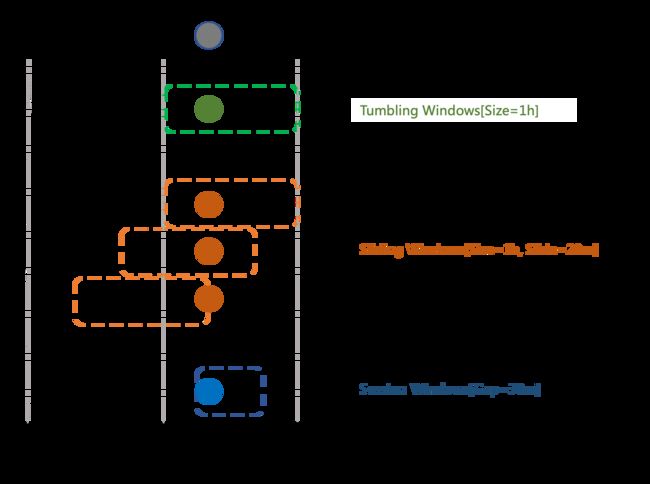
Window 和 WaterMark
可以设置 TimeWindow 的 AllowedLateness, 从而使 Window 可以处理延时数据.
只有当 WaterMark 超过 TimeWindow.end + AllowedLateness 时, Window 才会被销毁.

TimeWindow, EventTime, ProcessTime 和 Watermark
我们以 WaterMark 的推进图来阐述这四者之间的关系.
Window 为 TumbleWindow, 窗口大小为 1 小时, 允许的数据延迟为 1 小时:
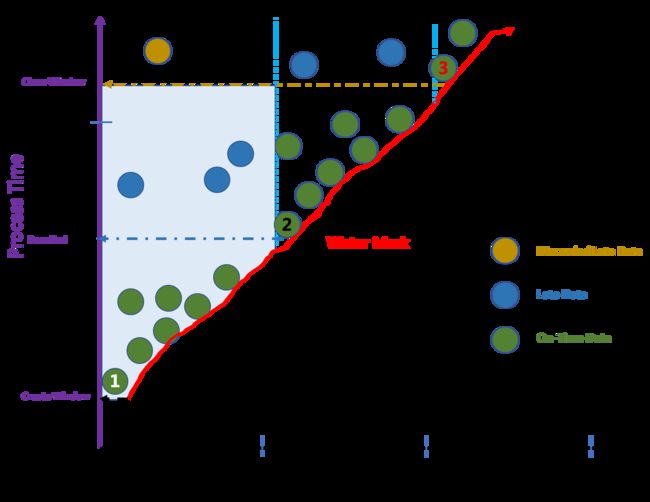
WaterMark 和 EventTime: 新数据的最新 Eventime 推进 WaterMark
TimeWindow 的生命周期:
以下三条数据的 EventTime 决定 TimeWindow 的状态转换.
数据 1 的 Eventtime 属于 Window[10:00, 11,00), 因为Window不存在, 所以创建此 Window.
数据 2 的 Eventime 推进 WaterMark 超过11:00 (Window.end), 所以触发Pass End.
数据 3 的 Eventime 推进 WaterMark 超过 12:00 (Window.end + allowedLateness), 所以关闭此Window.
TimeWindow 的结果输出:
用户可以通过 Trigger 来控制窗口结果的输出, 按窗口的状态类型有以下三种 Trigger.
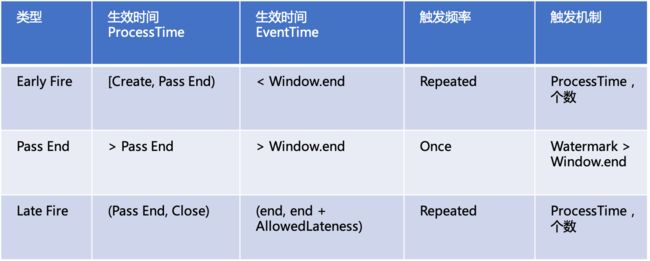
Flink 的 Streaming SQL 目前只支持 PassEnd Trigger, 且默认 AllowedLateness = 0.
如果触发频率是 Repeated, 比如:每分钟, 往下游输出一次. 那么这个时间只能是 ProcessTime.
因为 WarkMark 在不同场景下会有不同推进速度, 比如处理一小时的数据,
可能只需十分钟 (重跑), 一个小时(正常运行) 或 大于1小时(积压) .
运行结果:
允许数据乱序是分布式系统能够并发处理消息的前提.
当前这个例子, 数据如果乱序可以产生不同的输出结果.
数据有序SUM算子接收到的数据
数据的 Eventtime 按升序排列:
OrderT(1L, "bear", 3, Timestamp.valueOf("2020-10-10 2:11:00"))
OrderT(3L, "rubber", 2,Timestamp.valueOf("2020-10-10 2:38:35"))
OrderT(1L, "diaper", 1, Timestamp.valueOf("2020-10-10 2:48:05"))
OrderT(1L, "diaper", 4, Timestamp.valueOf("2020-10-10 3:11:03"))
WarterMark推进图
每条新数据都能推进 Watermark:

结果输出
所有数据都被处理, 没有数据被丢弃:
12> 3,2020-10-10 02:00:00.0,2
4> 1,2020-10-10 02:00:00.0,4
4> 1,2020-10-10 03:00:00.0,4
数据乱序SUM算子接收到的数据
第四条事件延时到来:
OrderT(1L, "bear", 3, Timestamp.valueOf("2020-10-10 2:11:00"))
OrderT(3L, "rubber", 2,Timestamp.valueOf("2020-10-10 2:38:35"))
OrderT(1L, "diaper", 4, Timestamp.valueOf("2020-10-10 3:11:03"))
OrderT(1L, "diaper", 1, Timestamp.valueOf("2020-10-10 2:48:05"))
WarterMark 推进图
延迟的数据不会推进WaterMark, 且被丢弃.
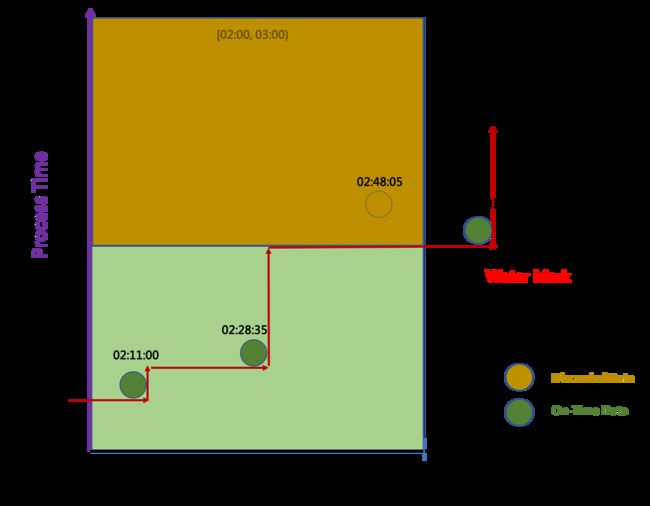
输出结果
没有统计因延迟被丢弃的第四条事件:
12> 3,2020-10-10 02:00:00.0,2
4> 1,2020-10-10 02:00:00.0,3
4> 1,2020-10-10 03:00:00.0,4
Join
代码
package com.atguigu.tableapi
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala._
import java.sql.Timestamp
import org.apache.flink.types.Row
case class Show(var impressionId: String, var name: String, eventTime: String)
case class Click(var impressionId: String, var name: String, eventTime: String)
object JoinTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
val showAd: DataStream[Show] = env.fromCollection(Seq(
Show("1", "show", "2020-10-10 10:10:10"),
Show("2", "show", "2020-10-10 10:11:10"),
Show("3", "show", "2020-10-10 10:12:10")
))
Thread.sleep(1000)
val clickAd: DataStream[Click] = env.fromCollection(Seq(
Click("1", "click", "2020-10-10 10:13:11"),
Click("3", "click", "2020-10-10 10:12:33"),
))
// 以流注册表
tEnv.createTemporaryView("ShowAd", showAd, 'impressionId, 'name, 'eventTime)
tEnv.createTemporaryView("ClickAd", clickAd, 'impressionId, 'name, 'eventTime)
// sql
val sql =
"""
|select
| ShowAd.impressionId AS impressionId,
| ShowAd.eventTime As showTime,
| CASE WHEN ClickAd.eventTime <> '' THEN 'clicked' ELSE 'showed' END AS status
|FROM ShowAd
|LEFT JOIN ClickAd ON ShowAd.impressionId = ClickAd.impressionId
|""".stripMargin
val result: Table = tEnv.sqlQuery(sql)
result.toRetractStream[Row].print()
env.execute()
}
}
转为逻辑计划 Logical Plan
LogicalProject(impressId=[$0], showTime=[$2], clickTime=[$5])
LogicalJoin(condition=[=($0, $3)], joinType=[left])
LogicalTableScan(table=[[ShowAd]])
LogicalTableScan(table=[[ClickAd]])
优化 Logical Plan
LogicalProject(impressId=[$0], showTime=[$2], clickTime=[$5])
LogicalJoin(condition=[=($0, $3)], joinType=[left])
LogicalTableScan(table=[[ShowAd]])
LogicalTableScan(table=[[ClickAd]])
转为物理计划 Physical Plan
DataStreamCalc(Select=[impressionId AS impressId, eventTime AS showTime, eventTime0 AS clickTime])
DataStreamJoin(where=[=(impressionId, impressionId0)], join=[impressionId, eventTime, impressionId0, eventTime0], joinType=[LeftOuterJoin])
DataStreamCalc(select=[impressionId, eventTime])
DataStreamScan(table=[[ShowAd]])
DataStreamCalc(select=[impressionId, eventTime])
DataStreamScan(table=[[ClickAd]])
优化 Stream Graph
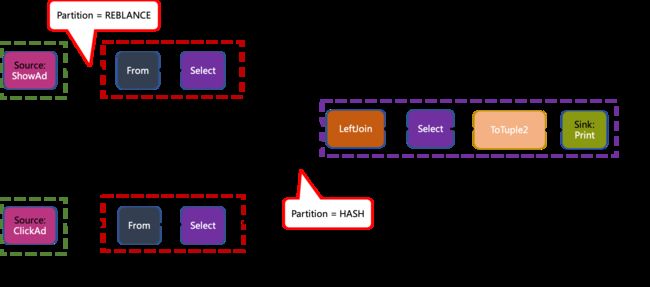
运行结果
1> (true,2,2020-10-10 10:11:10,showed )
11> (true,3,2020-10-10 10:12:10,showed )
11> (false,3,2020-10-10 10:12:10,showed )
11> (true,3,2020-10-10 10:12:10,clicked)
11> (true,1,2020-10-10 10:10:10,showed )
11> (false,1,2020-10-10 10:10:10,showed )
11> (true,1,2020-10-10 10:10:10,clicked)
Retraction Stream
虽然 Retraction 机制最多增加一倍的数据传输量, 但能降低下游算子的存储负担和撤销实现难度.
我们在 Left Join 的输出流后加一个 GROUP BY, 以观察 Retraction 流的后续算子的输出:
val sql2 = "select status, count(1) from (" + sql + ") impressionStatus group by status"
输出:
5> (true,showed ,1)
4> (true,clicked,1)
4> (false,clicked,1)
4> (true,clicked,2)
5> (false,showed ,1)
5> (true,showed ,2)
5> (false,showed ,2)
5> (true,showed ,1)
5> (false,showed ,1)
5> (true,showed ,2)
5> (false,showed ,2)
5> (true,showed ,1)
由此可见, Retraction 具有传递性, RetractStream 的后续的 Stream 也会是RetractionStream.
终止
最终需要支持 Retraction 的 Sink 来终止 RetractionStream, 比如:
class RetractingSink extends RichSinkFunction[(Boolean, Row)] {
val retractedResults = scala.collection.mutable.Map[String, String]()
override def invoke(value: (Boolean, Row)): Unit = {
retractedResults.synchronized{
val flag = value._1
val status = value._2.getField(0).toString
val count = value._2.getField(1).toString
if(flag == false){
retractedResults -= status
}else{
retractedResults += (status -> count)
}
}
}
override def close(): Unit = println(retractedResults)
}
result.toRetractStream[Row].addSink(new RetractingSink).setParallelism(1)
最终输出 retractedResults:
Map(showed -> 1, clicked -> 2)
存储
只有外部存储支持 UPDATE 或 DELETE 操作时, 才能实现 RetractionSink, 常见的KV 存储和数据库, 如HBase, Mysql 都可实现 RetractionSink.
后续程序总能从这些存储中读取最新数据, 上游是否是 Retraction 流对用户是透明的.
常见的消息队列, 如Kafka, 只支持 APPEND 操作, 则不能实现 RetractionSink.
后续程序从这些消息队列可能会读到重复数据, 因此用户需要在后续程序中处理重复数据.
总结
Flink Streaming SQL的实现从上到下共有三层:
- Streaming SQL
- Streaming 和 Window
- Distributed Snapshots
其中 Streaming Data Model 和 Distributed Snapshot 是 Flink 这个分布式流计算系统的核心架构设计.
Streaming Data Model 的 What, Where, When, How 明确了流计算系统的表达能力及预期应用场景.
Distributed Snapshots 针对预期的应用场景在数据准确性, 系统稳定性和运行性能上做了合适的折中.
操作, 则不能实现 RetractionSink.
后续程序从这些消息队列可能会读到重复数据, 因此用户需要在后续程序中处理重复数据.
总结
Flink Streaming SQL的实现从上到下共有三层:
- Streaming SQL
- Streaming 和 Window
- Distributed Snapshots
其中 Streaming Data Model 和 Distributed Snapshot 是 Flink 这个分布式流计算系统的核心架构设计.
Streaming Data Model 的 What, Where, When, How 明确了流计算系统的表达能力及预期应用场景.
Distributed Snapshots 针对预期的应用场景在数据准确性, 系统稳定性和运行性能上做了合适的折中.
本文通过实例阐述了流计算开发者需要了解的最上面两层的概念和原理, 以便流计算开发者能在数据准确性和数据时效性上做适合业务场景的折中和取舍.