Hadoop完全分布式安装(Centos7+Hadoop2.5.0)
Hadoop部署模式
Hadoop部署模式有:本地模式、伪分布模式、完全分布式模式、HA完全分布式模式。
区分的依据是NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程、几个机器。
模式名称
各个模块占用的JVM进程数
各个模块运行在几个机器数上
本地模式
1个
1个
伪分布式模式
N个
1个
完全分布式模式
N个
N个
HA完全分布式
N个
N个
本地模式介绍
本地模式是最简单的模式,所有模块都运行与一个JVM进程中,使用的本地文件系统,而不是HDFS,本地模式主要是用于本地开发过程中的运行调试用。下载hadoop安装包后不用任何设置,默认的就是本地模式。
完全布式环境部署Hadoop
完全分部式是真正利用多台Linux主机来进行部署Hadoop,对Linux机器集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上。
HA部署
HA的意思是High Availability高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用。
HA方式安装部署才是最常见的生产环境上的安装部署方式。Hadoop HA是Hadoop 2.x中新添加的特性,包括NameNode HA 和 ResourceManager HA。因为DataNode和 NodeManager本身就是被设计为高可用的,所以不用对他们进行特殊的高可用处理。
完全分布式环境安装
壹、环境准备
- 3台虚拟机都配置好JDK【Linux】CentOS7下安装JDK详细过程
Hadoop Version >=2.7 需要JDK>=7(OpenJDK and Oracle (HotSpot)'s JDK/JRE);Hadoop Version <=2.6 需要Java 6。
可以一台电脑安装完,然后scp命令复制jdk到其他电脑,然后记得修改/etc/profile文件的JAVA_HOME,修改完使用source 命令重启下profile配置。
本文安装的hadoop-2.10.1.tar.gz和jdk-8u301-linux-x64.tar.gz。
(1)下载指定版本的jdk Java Downloads | Oracle
(2)解压 tar zxvf jdk
(3)/etc/profile加入如下环境变量
export JAVA_HOME=/opt/java/jdk-19.0.2 export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar export PATH=$PATH:${JAVA_HOME}/bin2.修改hostname vi /etc/sysconfig/network ,给每台虚拟机添加域名hostname。
[root@localhost hadoop-2.10.1]# vi /etc/sysconfig/network # Created by anaconda fang1.fri.com
ip地址 域名 别名 192.168.41.252 fang1.fri.com bigdata01 192.168.41.115 fang2.fri.com bigdata02 192.168.41.116 fang3.fri.com bigdata03 3.配置hosts
配置文件尽量使用域名,这样当ip变化时,仅需要更改hosts文件即可。
BigData01、BigData02、BigData03三台机器hosts都添加如下配置:
[root@localhost hadoop-2.10.1]# vi /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.41.115 fang2.fri.com 192.168.41.116 fang3.fri.com 192.168.41.252 fang1.fri.com
IP
域名
机器名字
192.168.41.252 fang1.fri.com BigData01
192.168.41.115 fang2.fri.com BigData02
192.168.41.116 fang3.fri.com BigData03
4. 配置Windows上的SSH客户端
如果你的操作系统是 Windows,而你想要连接 Linux 服务器相互传送文件,那么你需要一个简称 SSH 的 Secure Shell 软件。实际上,SSH 是一个网络协议,它允许你通过网络连接到 Linux 和 Unix 服务器。SSH 使用公钥加密来认证远程的计算机。你可以有多种途径使用 SSH,无论是自动连接,还是使用密码认证登录。本文推荐使用FinalShell。
5.关闭所有虚拟机的防火墙
# 查看防火墙状态 [root@localhost ~]# firewall-cmd --state running # 关闭防火墙 [root@localhost ~]# systemctl stop firewalld # 永久关闭防火墙 [root@localhost ~]# systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.6. 关闭selinux服务(重启生效)
SELINUX是对系统安全级别更细粒度的设置,由于SELINUX配置设置的太严格,可能会与其他服务的功能相冲突,然后在控制台输入reboot命令重启系统,让配置生效。
vim /etc/selinux/config SELINUX=disabled修改selinux导致虚拟机无法开启问题
贰、服务器功能规划
fang1.fri.com
fang2.fri.com
fang3.fri.com
NameNode
ResourceManage
DataNode
DataNode
DataNode
NodeManager
NodeManager
NodeManager
HistoryServer
SecondaryNameNode
叁、在第一台机器上安装新的Hadoop
我们采用先在第一台机器上解压、配置Hadoop,然后再分发到其他两台机器上的方式来安装集群。
1、官网下载Apache Hadoop
2、 解压Hadoop目录:
[hadoop@bigdata-senior01 modules]$ tar -zxf /opt/sofeware/hadoop-2.5.0.tar.gz -C /opt/modules/app/3、 配置Hadoop JDK路径。 hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的添加如下JDK路径:
export JAVA_HOME="/opt/modules/jdk1.7.0_67"4、 配置core-site.xml。
注:如下操作都是在进入Hadoop解压后的文件下进行。
[hadoop@bigdata-senior01 hadoop-2.5.0]$ vim etc/hadoop/core-site.xmlfs.defaultFS hdfs://192.168.41.252:8020 hadoop.tmp.dir /opt/modules/app/hadoop-2.5.2/data/tmp
- fs.defaultFS为NameNode的地址。
- hadoop.tmp.dir为hadoop临时目录的地址,默认情况下,NameNode和DataNode的数据文件都会存在这个目录下的对应子目录下。应该保证此目录是存在的,如果不存在,先创建。
5、 配置hdfs-site.xml
[hadoop@bigdata-senior01 hadoop-2.5.0]$ vim etc/hadoop/hdfs-site.xmldfs.namenode.secondary.http-address 192.168.41.116:50090
- dfs.namenode.secondary.http-address是指定secondaryNameNode的http访问地址和端口号,因为在规划中,我们将BigData03规划为SecondaryNameNode服务器。所以这里设置为:192.168.41.116:50090或者直接使用域名fang3.fri.com
6、 配置slaves。在hadoop安装目录下的etc目录
[root@localhost hadoop]# vi etc/hadoop/slaves 192.168.41.252 192.168.41.115 192.168.41.116
- slaves文件是指定HDFS上有哪些DataNode节点。
7、 配置yarn-site.xml
[hadoop@bigdata-senior01 hadoop-2.5.0]$ vim etc/hadoop/yarn-site.xmlyarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname fang1.fri.com yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 106800
- 根据规划yarn.resourcemanager.hostname这个指定resourcemanager服务器指向fang2.fri.com
- yarn.log-aggregation-enable是配置是否启用日志聚集功能。
- yarn.log-aggregation.retain-seconds是配置聚集的日志在HDFS上最多保存多长时间。
8、 配置mapred-site.xml
[hadoop@bigdata-senior01 hadoop-2.5.0]$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xmlmapreduce.framework.name yarn mapreduce.jobhistory.address 192.168.41.252:10020 mapreduce.jobhistory.webapp.address 192.168.41.252:19888 从mapred-site.xml.template复制一个mapred-site.xml文件。
- mapreduce.framework.name设置mapreduce任务运行在yarn上。
- mapreduce.jobhistory.address是设置mapreduce的历史服务器安装在BigData01机器上。
- mapreduce.jobhistory.webapp.address是设置历史服务器的web页面地址和端口号。
肆、设置SSH无密码登录
Hadoop集群中的各个机器间会相互地通过SSH访问,每次访问都输入密码是不现实的,所以要配置各个机器间的SSH使其可以无密码登录。
1、 在BigData01上生成公钥
[hadoop@bigdata-senior01 hadoop-2.5.0]$ ssh-keygen -t rsassh-keygen命令用于为“ssh”生成、管理和转换认证密钥,它支持RSA和DSA两种认证密钥。
一路回车,都设置为默认值,然后在当前用户的Home目录下的.ssh目录中会生成公钥文件(id_rsa.pub)和私钥文件(id_rsa)。
2、 分发公钥:也需要给本机分发一个公钥
ssh-copy-id命令可以把本地主机的公钥复制到远程主机的authorized_keys文件上,ssh-copy-id命令也会给远程主机的用户主目录(home)和~/.ssh, 和~/.ssh/authorized_keys设置合适的权限。
[hadoop@bigdata-senior01 hadoop-2.5.0]$ ssh-copy-id fang1.fri.com [hadoop@bigdata-senior01 hadoop-2.5.0]$ ssh-copy-id fang2.fri.com [hadoop@bigdata-senior01 hadoop-2.5.0]$ ssh-copy-id fang3.fri.com3、 设置BigData02、BigData03到其他机器的无密钥登录
同样的在BigData02、BigData03上生成公钥和私钥后,将公钥分发到三台机器上。
伍、分发Hadoop文件
1、 首先在其他两台机器上创建存放Hadoop的目录
[hadoop@bigdata-senior02 ~]$ mkdir /opt/modules/app [hadoop@bigdata-senior03 ~]$ mkdir /opt/modules/app2、 通过scp分发
scp命令用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。可能会稍微影响一下速度。-r:以递归方式复制;-q以不显示进度方式拷贝
Hadoop根目录下的share/doc目录是存放的hadoop的文档,文件相当大,建议在分发之前将这个目录删除掉,可以节省硬盘空间并能提高分发的速度。doc目录大小有1.6G。注意不要误删除share下的其他文件,否则会报错: java.lang.ClassNotFoundException: org.apache.hadoop.hdfs.server.namenode.NameNode
df命令用于显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
du命令也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的。-s或--summarize 仅显示总计,只列出最后加总的值。-h或--human-readable 以K,M,G为单位,提高信息的可读性。-m或--megabytes 以MB为单位输出。du -sh 文件或者目录 :显示文件或者目录的大小
[hadoop@bigdata-senior01 hadoop-2.5.0]$ du -sh /opt/modules/app/hadoop-2.5.0/share/doc 1.6G /opt/modules/app/hadoop-2.5.0/share/doc [hadoop@bigdata-senior01 hadoop-2.5.0]$ scp -rq /opt/modules/app/hadoop-2.5.0/ fang2.fri.com:/opt/modules/app [hadoop@bigdata-senior01 hadoop-2.5.0]$ scp -rq /opt/modules/app/hadoop-2.5.0/ fang3.fri.com:/opt/modules/app
陆、格式NameNode
在NameNode机器上执行格式化:
[hadoop@bigdata-senior01 hadoop-2.5.0]$ /opt/modules/app/hadoop-2.5.0/bin/hdfs namenode –format注意:
如果需要对同一个hadoop程序重新格式化NameNode,需要先将原来关于NameNode和DataNode的文件全部删除,不然会报clusterid不匹配的错误,NameNode和DataNode所在目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。默认情况下,Namenode和Datanode存放在hadoop.tmp.dir的子目录下
删除集群上的所有虚拟机的hadoop.tmp.dir属性指定文件夹下的内容
cd /opt/modules/app/hadoop-2.5.2/data/tmp rm -rf * 在集群每一个虚拟机上这么删除
hadoop.tmp.dir /opt/modules/app/hadoop-2.5.2/data/tmp dfs.namenode.name.dir file://${hadoop.tmp.dir}/dfs/name dfs.datanode.data.dir file://${hadoop.tmp.dir}/dfs/data 重新执行hdfs namenode -format,导致namenode的current目录会被删除并进行重建,其clusterID也会发生变化,而datanode中的配置并没有随namenode发生变化,造成了两个clusterID不一致问题。
因此为避免这种情况的发生,在namenode重新格式化后,需要修改datanode的clusterID的配置。即修改data/tmp/dfs/data/current/VERSION里面的clusterID配置值为namenode生成的id即可。
或者格式化前删除datanode的current文件夹,以保持namenode和datanode配置一致。每次格式化时,namenode会更新clusterID,但是datanode只会在首次格式化或者不存在时才会重新生。
另一种方法是格式化时指定集群ID参数,指定为旧的集群ID。这样新生成的namdnode就和以前的datanode的id相同
bin/hdfs namenode –format -clusterId 旧的id名字
柒、启动集群
1、 BigData01电脑启动HDFS。关闭对应命令stop-dfs.sh,用来启动关闭namenode、secondarynamenode、datanode节点
注: sbin/start-all.sh命令会启动dfs、yarn、ambari-server等
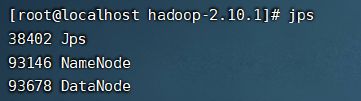
使用jps查看是否启动成功
2、 BigData01电脑启动YARN
[hadoop@bigdata-senior01 hadoop-2.5.0]$ /opt/modules/app/hadoop-2.5.0/sbin/start-yarn.sh
同理关闭命令为 stop-yarn.sh
//目前我将ResourceManager也放在了fang1.fri.com虚拟机上,故BigData02不需要在开启ResourceManager
在BigData02上启动ResourceManager:
[hadoop@bigdata-senior02 hadoop-2.5.0]$ sbin/yarn-daemon.sh start resourcemanager
同理关闭命令为 yarn-daemon.sh stop resourcemanager
3、 启动日志服务器
因为我们规划的是在BigData01服务器上运行MapReduce日志服务,所以要在BigData01上启动。
启动命令:sbin/mr-jobhistory-daemon.sh start historyserver
关闭命令:sbin/mr-jobhistory-daemon.sh stop historyserver
JPS查看启动情况
4、 查看HDFS Web页面。http://192.168.41.252:50070/
5、 查看YARN Web 页面。http://192.168.41.252:8088/cluster



捌、测试Job
我们这里用hadoop自带的wordcount例子来在本地模式下测试跑mapreduce。
HDFS Shell 官网命令
1、 准备mapreduce输入文件wc.input
[hadoop@bigdata-senior01 modules]$ cat /opt/data/wc.input hadoop mapreduce hive hbase spark storm sqoop hadoop hive spark hadoop2、 在HDFS创建输入目录input
[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs dfs -mkdir /input3、 将wc.input上传到HDFS
[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs dfs -put /opt/data/wc.input /input/wc.input4、 运行hadoop自带的mapreduce Demo
[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/wc.input /output注意:如果提示错误:local host is: "fang16.hadoop.com/10.0.2.16"; destination host is: "fang.fri.com":8020。那么需要重新format namenode即可。
5、 查看输出文件
[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs dfs -ls /output Found 2 items -rw-r--r-- 3 hadoop supergroup 0 2016-07-14 16:36 /output/_SUCCESS -rw-r--r-- 3 hadoop supergroup 60 2016-07-14 16:36 /output/part-r-000006.查看结果
[root@localhost hadoop-2.10.1]# bin/hdfs dfs -cat /output/part-r-00000 flink 2 hadoop 2 hbase 1 hive 1 mapreduce 1 spark 2 storm 1
参考文章
hadoop单机安装,小白上手最详细教程-Ali0th