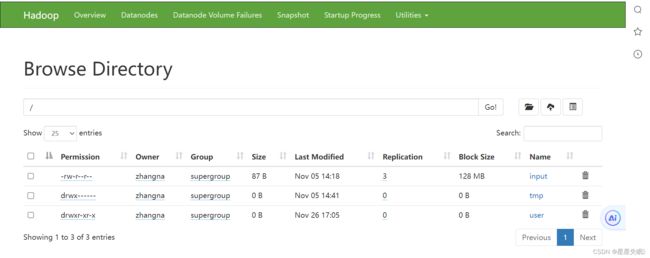
大数据基础 HDFS客户端操作
一、Maven概述
Maven是一个专门用于管理和构建Java项目的工具。我们之所以要使用Maven,是因为Maven可以为我们提供一套标准化的项目结构、一套标准化的构建流程和一套方便的依赖管理机制,这些功能可以使得我们的项目结构更加清晰,导入jar包的方式更加方便和标准,进而使得我们的开发更加的便捷高效。maven是Apache的顶级项目,解释为“专家,内行”,它是一个项目管理的工具,maven自身是纯java开发的,可以使用maven对java项目进行构建、依赖管理。
2. Maven的作用
依赖管理
依赖指的就是 我们项目中需要使用的第三方Jar包, 一个大一点的工程往往需要几十上百个Jar包,按照我们之前的方式,每使用一种Jar,就需要导入到工程中,还要解决各种Jar冲突的问题.
Maven可以对Jar包进行统一的管理,包括快速引入Jar包,以及对使用的 Jar包进行统一的版本控制
一键构建项目
之前我们创建项目,需要确定项目的目录结构,比如src 存放Java源码, resources存放配置文件,还要配置环境比如JDK的版本等等,如果有多个项目 那么就需要每次自己搞一套配置,十分麻烦
Maven为我们提供了一个标准化的Java项目结构,我们可以通过Maven快速创建一个标准的Java项目.
二、创建Maven项目
使用IDEA创建Maven项目,首先需要配置好Maven
二、Maven 的下载安装
1. Maven软件的下载
使用 Maven 管理工具,我们首先要到官网去下载它的安装软件。
Maven – Download Apache Maven

2. Maven软件的安装
Maven 下载后,将 Maven 解压到一个没有中文没有空格的路径下,比如:H:\software\maven 下面。 解压后目录结构如下:
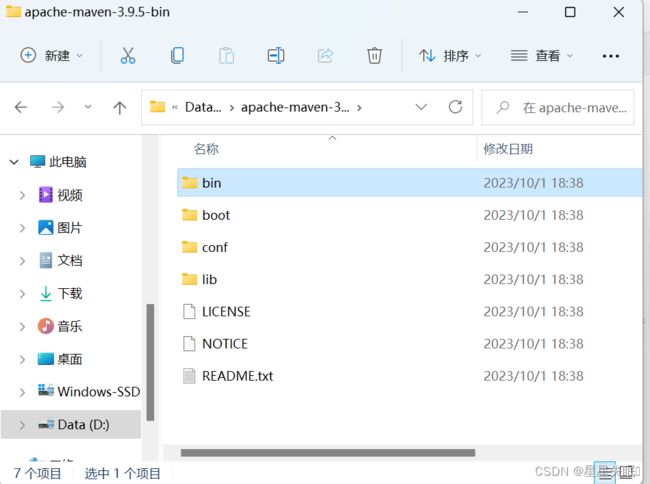
- bin:存放了 maven 的命令
- boot:存放了一些 maven 本身的引导程序,如类加载器等
- conf:存放了 maven 的一些配置文件,如 setting.xml 文件
- lib:存放了 maven 本身运行所需的一些 jar 包
3. Maven环境变量配置
- 配置 MAVEN_HOME ,变量值就是你的 maven 安装的路径(bin 目录之前一级目录)

- 将MAVEN_HOME 添加到Path系统变量

4. Maven 软件版本测试
win+R 打开dos窗口,通过 mvn -v命令检查 maven 是否安装成功,看到 maven 的版本为3.9.5 及 java 版本为 jdk1.8即为安装 成功。 打开命令行,输入 mvn –v命令,如下图:

三、Maven 仓库
Maven中的仓库是用来存放maven构建的项目和各种依赖的(Jar包)。
1. Maven的仓库分类
本地仓库: 位于自己计算机中的仓库, 用来存储从远程仓库或中央仓库下载的插件和 jar 包,
远程仓库: 需要联网才可以使用的仓库,阿里提供了一个免费的maven 远程仓库。
中央仓库: 在 maven 软件中内置一个远程仓库地址 http://repo1.maven.org/maven2 ,它是中 央仓库,服务于整个互联网,它是由 Maven 团队自己维护,里面存储了非常全的 jar 包,它包 含了世界上大部分流行的开源项目构件
2. Maven 本地仓库的配置
1.maven仓库默认是在 C盘 .m2 目录下,我们不要将仓库放在C盘,所以这里要重新配置一下.
2.将 “repository.rar”解压至自己的 电脑上,我解压在 H:\software\repository 目录下(注意最好放在没有中文及空格的目录下)。
3.在maven安装目录中,进入 conf文件夹, 可以看到一个 settings.xml 文件中, 我们在这个文件中, 进行本地仓库的配置
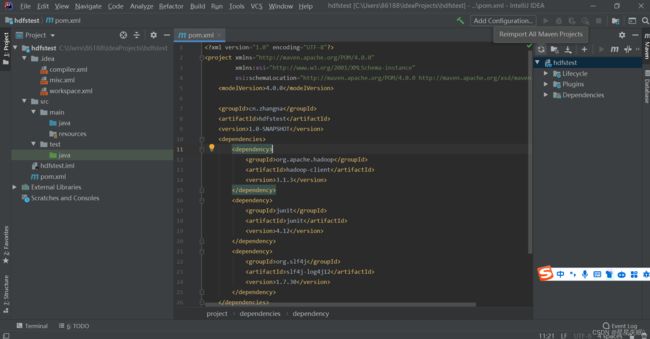
5)在IDEA中创建一个Maven工程HdfsClientDemo,并导入相应的依赖坐标+日志添加
org.apache.hadoop
hadoop-client
3.1.3
junit
junit
4.12
org.slf4j
slf4j-log4j12
1.7.30
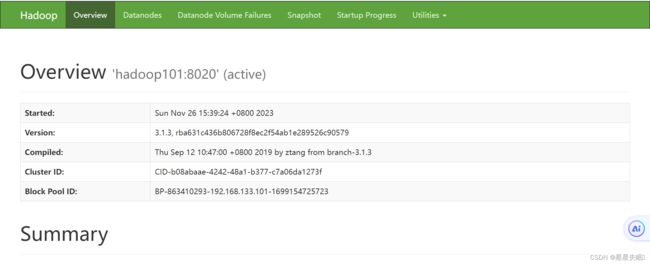
创建目录
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class hdfsapitest {
@Test
public void testMkdirs() throws URISyntaxException, IOException,InterruptedException
{
Configuration configuration=new Configuration();
FileSystem fs=FileSystem.get(new URI("hdfs://hadoop101:8020"),configuration,"zhangna");
fs.mkdirs(new Path("dashuju/class/"));
fs.close();
}
}
上课老师讲的进行验证