Spring系列19:SpEL详解
本文内容
SpEL概念
快速入门
关键接口
全面用法
bean定义中使用
SpEL概念
Spring 表达式语言(简称“SpEL”)是一种强大的表达式语言,支持在运行时查询和操作对象图。语言语法类似于 Unified EL,但提供了额外的功能,最值得注意的是方法调用和基本的字符串模板功能。
虽然 SpEL 是 Spring 产品组合中表达式评估的基础,但它不直接与 Spring 绑定,可以独立使用。
表达式语言支持以下功能:
- 字面表达式
- 布尔和关系运算符
- 正则表达式
- 类表达式
- 访问属性、数组、列表和映射
- 方法调用
- 关系运算符
- 调用构造函数
- bean引用
- 数组构造
- 内联的list
- 内联的map
- 三元运算符
- 变量
- 用户自定义函数
- 集合选择
- 模板化表达式
快速入门
通过几个案例快速体验SpEL表达式的使用。
案例1 Hello World
纯字面意义的字符串输出,体验使用的基本步骤。
@Test
public void test_hello() {
// 1 定义解析器
SpelExpressionParser parser = new SpelExpressionParser();
// 2 使用解析器解析表达式
Expression exp = parser.parseExpression("'Hello World'");
// 3 获取解析结果
String value = (String) exp.getValue();
System.out.println(value);
}
// 结果
Hello World案例2 字符串方法的字面调用
在表达式中调用字符串的普通方法和构造方法。
@Test
public void test_String_method() {
// 1 定义解析器
SpelExpressionParser parser = new SpelExpressionParser();
// 2 使用解析器解析表达式
Expression exp = parser.parseExpression("'Hello World'.concat('!')");
// 3 获取解析结果
String value = (String) exp.getValue();
System.out.println(value);
exp = parser.parseExpression("'Hello World'.bytes");
byte[] bytes = (byte[]) exp.getValue();
exp = parser.parseExpression("'Hello World'.bytes.length");
int length = (Integer) exp.getValue();
System.out.println("length: " + length);
// 调用
exp = parser.parseExpression("new String('hello world').toUpperCase()");
System.out.println("大写: " + exp.getValue());
}
// 结果
Hello World!
length: 11
大写: HELLO WORLD案例3 针对特定对象解析表达式
SpEL 更常见的用法是提供针对特定对象实例(称为根对象)进行评估的表达式字符串。案例演示如何从 Inventor 类的实例中检索名称属性或创建布尔条件。
Inventor相关类定义如下
public class Inventor {
private String name;
private String nationality;
private String[] inventions;
private Date birthdate;
private PlaceOfBirth placeOfBirth;
// 省略其它方法
}
public class PlaceOfBirth {
private String city;
private String country;
// 省略其它方法
}表达式解析测试
@Test
public void test_over_root() {
// 创建 Inventor 对象
GregorianCalendar c = new GregorianCalendar();
c.set(1856, 7, 9);
Inventor tesla = new Inventor("Nikola Tesla", c.getTime(), "Serbian");
// 1 定义解析器
ExpressionParser parser = new SpelExpressionParser();
// 指定表达式
Expression exp = parser.parseExpression("name");
// 在 tesla对象上解析
String name = (String) exp.getValue(tesla);
System.out.println(name); // Nikola Tesla
exp = parser.parseExpression("name == 'Nikola Tesla'");
// 在 tesla对象上解析并指定返回结果
boolean result = exp.getValue(tesla, Boolean.class);
System.out.println(result); // true
}执行过程分析和关键接口
执行过程分析
上面的案例中SpEL表达式的使用步骤中涉及了几个概念和接口:
- 用户表达式:我们定义的表达式,如
1+1!=2 - 解析器:ExpressionParser 接口,负责将用户表达式解析成SpEL认识的表达式对象
- 表达式对象:Expression接口,SpEL的核心,表达式语言都是围绕表达式进行的
- 评估上下文:EvaluationContext 接口,表示当前表达式对象操作的对象,表达式的评估计算是在上下文上进行的。
通过下面的简单案例debug分析执行过程。
@Test
public void test_debug(){
SpelExpressionParser parser = new SpelExpressionParser();
SimpleEvaluationContext context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
Boolean value = parser.parseExpression("1+1!=2").getValue(context, Boolean.class);
System.out.println(value);
}源码debug如下,分2大阶段,建议自行debug一次:
解析阶段:InternalSpelExpressionParser#doParseExpression() 无关源码已经删除
// 用户提供的表达式1+1!=2
private String expressionString = "";
// 分词流
private List tokenStream = Collections.emptyList();
@Override
protected SpelExpression doParseExpression(String expressionString, @Nullable ParserContext context)
throws ParseException {
try {
// 1 读取到用户的表达式 1+1!=2
this.expressionString = expressionString;
// 2.1 定义分词器Tokenizer
Tokenizer tokenizer = new Tokenizer(expressionString);
// 2.2 分词器将字符串拆分为分词流
this.tokenStream = tokenizer.process();
this.tokenStreamLength = this.tokenStream.size();
this.tokenStreamPointer = 0;
this.constructedNodes.clear();
// 3 将分词流解析成抽象语法树 表示为SpelNode接口
SpelNodeImpl ast = eatExpression();
Assert.state(ast != null, "No node");
// 4、将抽象语法树包装成 Expression 表达式对象
return new SpelExpression(expressionString, ast, this.configuration);
}
catch (InternalParseException ex) {
throw ex.getCause();
}
} 评估求值阶段:SpelExpression#getValue(),无关源码已经删除
// 解析阶段生成的抽象语法树对象 SpelNodeImpl
private final SpelNodeImpl ast;
public T getValue(EvaluationContext context, @Nullable Class expectedResultType) throws EvaluationException {
Assert.notNull(context, "EvaluationContext is required");
// ...
// 6.1 应用活动上下文和解析器的配置
ExpressionState expressionState = new ExpressionState(context, this.configuration);
// 6.2 在上下中抽象语法树进行评估求值
TypedValue typedResultValue = this.ast.getTypedValue(expressionState);
checkCompile(expressionState);
// 6.3 将结果进行类型转换
return ExpressionUtils.convertTypedValue(context, typedResultValue, expectedResultType);
} 方便理解,流程图如下图:
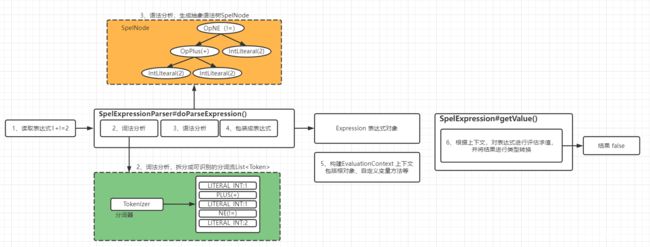
汇总下执行过程:
- 解析器 SpelExpressionParser 读取用户提供的表达式
1+1!=2 - 词法分析:解析器 SpelExpressionParser 使用分词器拆分用户字符串表达式成分词流
- 语法分析:解析器 SpelExpressionParser 将分词流生成内部的抽象语法树
- 包装表达式:对外提供Expression接口来简化表示抽象语法树,从而隐藏内部实现细节,并提供getValue简单方法用于获取表达式
- 用户提供表达式上下文对象(非必须),SpEL使用EvaluationContext接口表示上下文对象,用于设置根对象、自定义变量、自定义函数、类型转换器等
- 在表达式上下文中调用内部抽象语法树进行评估求值并转换结果类型到目标类型。
ExpressionParser 接口
ExpressionParser 接口将表达式字符串解析为可以计算的编译表达式。支持解析模板以及标准表达式字符串。
关键方法parseExpressio(),在解析失败时抛出 ParseException 异常。
public interface ExpressionParser {
// 解析表达式字符串并返回一个可用于重复评估的表达式对象。
Expression parseExpression(String expressionString) throws ParseException;
// 解析表达式字符串并返回一个可用于重复评估的表达式对象。 指定解析评估上下文
Expression parseExpression(String expressionString, ParserContext context) throws ParseException;
}实现类 TemplateAwareExpressionParser 增加了对模板的解析支持。
<