大数据之hive_hive中集合类型的使用
集合数据类型
数据类型 描述 语法示例
STRUCT(结构体)对象 和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 struct()
MAP 映射 MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 map()
ARRAY 数组 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 Array()
案例实操
1)假设某表有如下一行,我们用JSON格式来表示其数据结构。在Hive下访问的格式为
{
“name”: “songsong”,
“friends”: [“bingbing” , “lili”] , //列表Array,
“children”: { //键值Map,
“xiao song”: 18 ,
“xiaoxiao song”: 14
}
“address”: { //结构Struct,
“street”: “hui long guan” ,
“city”: “beijing”
}
}
2)基于上述数据结构,我们在Hive里创建对应的表,并导入数据。
创建本地测试文件test.txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
注意:MAP,STRUCT和ARRAY里面的每个元素之间的区分符都可以用同一个字符进行分割,这里用“_”。
3)创建测试表
create table test(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)
--指定字段间的切割符
row format delimited fields terminated by ','
--指定字段内要放入数组或集合的多个元素之间的切割符
collection items terminated by '_'
--指定map集合分辨k,v的切割符
map keys terminated by ':'
--指定读取行切割符
lines terminated by '\n';
- 导入文本数据到测试表
hive (default)> load data local inpath ‘/opt/module/datas/test.txt’into table test
5)访问三种集合列里的数据,以下分别是ARRAY,MAP,STRUCT的访问方式
hive中map数据类型的数据的常用函数
取值方式一:
hive (default)> select friends[1],children['xiao song'],address.city from test
where name="songsong";
OK
_c0 _c1 city
bingbing 18 hui long guan
取值方式二:
select name , friends [1] , map_keys(children ) , address.street , address.city from test;
+-----------+-------+--------------------------------+----------------+----------+--+
| name | _c1 | _c2 | street | city |
+-----------+-------+--------------------------------+----------------+----------+--+
| songsong | lili | ["xiao song","xiaoxiao song"] | hui long guan | beijing |
| yangyang | susu | ["xiao yang","xiaoxiao yang"] | chao yang | beijing |
+-----------+-------+--------------------------------+----------------+----------+--+
取值总结:
1.单纯指定字段,会将集合或数组中所以的值都取出来
2.单个取值,数组:friends[1] 取0号索引的值,角标越界会返回null
集合:children[‘xiao song’] 取map中key为’xiao song’的value
3.使用函数对集合取值,map_keys(children) 取map中所有的key
map_values(children) 取map中所有的value
4.对结构化数据struct取值,之间使用字段名点它里面的属性就行:address.street
对集合操作的常用函数:
size(children) 返回集合或数组的长度
array_contains(friends,‘lili’) 查看集合或数组中是否包含该元素
sort_array(friends) 按字典顺序对数组排序,只能升序排序
解析json格式数据:表生成函数
需求:有如下json格式的电影评分数据:
{“movie”:“1193”,“rate”:“5”,“timeStamp”:“978300760”,“uid”:“1”}
{“movie”:“661”,“rate”:“3”,“timeStamp”:“978302109”,“uid”:“1”}
{“movie”:“914”,“rate”:“3”,“timeStamp”:“978301968”,“uid”:“1”}
{“movie”:“3408”,“rate”:“4”,“timeStamp”:“978300275”,“uid”:“1”}
{“movie”:“2355”,“rate”:“5”,“timeStamp”:“978824291”,“uid”:“1”}
{“movie”:“1197”,“rate”:“3”,“timeStamp”:“978302268”,“uid”:“1”}
需要做各种统计分析。
发现,直接对json做sql查询不方便,需要将json数据解析成普通的结构化数据表。可以采用hive中内置的json_tuple()函数
实现步骤:
1、创建一个原始表用来对应原始的json数据
create table t_json(json string);
load data local inpath ‘/root/rating.json’ into table t_json;
2、利用json_tuple进行json数据解析
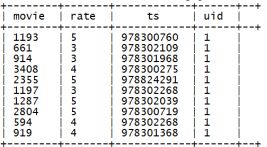
测试,示例:
select json_tuple(json,'movie','rate','timeStamp','uid') as (movie,rate,ts,uid) from t_json limit 10;
产生结果:
3.真正解析整张json表,将解析结果数据插入一张新表
create table t_movie_rate
as
select json_tuple(json,'movie','rate','timeStamp','uid') as(movie,rate,ts,uid) from t_json;
– TODO 练习–
– TODO 练习–
1/ 统计每部电影的平均得分
create table t_rate_m_avg as select movie,avg(rate) from t_rate group by movie;
2/ 统计数据中一共有多少部电影
select count(distinct movie) from t_rate;
3/ 统计每部电影的被评分次数(热门度)
create table t_rate_m_cnt as select movie,count(1) as cnt from t_rate group by movie order by cnt desc;
4/ 统计每个人的所有电影评分的平均值
create table t_rate_u_avg as select uid,avg(rate) from t_rate group by uid;
5/ 查询出每个人评分最高的20部电影信息
select
a.uid,a.rate,a.movie,a.ts
from(
select
*,
row_number() over (partition by uid order by rate desc ) num
from tb_movie) a where a.num<=20;
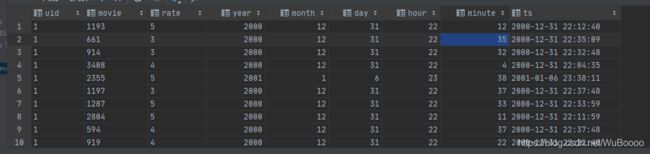
6/利用json_tuple从原始json数据表中,etl出一个评论时间的详细信息表:
create table t_rate
as
select
uid,
movie,
rate,
--将字符串转换成bigint,然后转换成时间格式,再获取年月日时分
year(from_unixtime(cast(ts as bigint))) as year,
month(from_unixtime(cast(ts as bigint))) as month,
day(from_unixtime(cast(ts as bigint))) as day,
hour(from_unixtime(cast(ts as bigint))) as hour,
minute(from_unixtime(cast(ts as bigint))) as minute,
from_unixtime(cast(ts as bigint)) as ts
from
(select
json_tuple(rateinfo,'movie','rate','timeStamp','uid') as(movie,rate,ts,uid)
from t_json) tmp
;