实战文本分类对抗攻击
文章写得比较长,先列出大纲,以便读者直取重点。

“文本分类对抗攻击”是清华大学和阿里安全2020年2月举办的一场AI比赛,从开榜到比赛结束20天左右,内容是主办方在线提供1000条辱骂样本,参赛者用算法逐条扰动,使线上模型将其判别为非辱骂样本,尽量让扰动较小同时又保留辱骂性质(辱骂性质前期由模型判定,最终由人工判定)。
比赛规则
线上模型和评测使用的1000条样本不公开,选手根据赛方指定的接口实现算法,并用docker方式提交以供线上评测,每天最多评测15次,单次运行时间需控制在30分钟之内。
(第一个知识点:熟悉Docker,简单环境调试)
其评价公式如下:
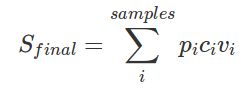
共1000条评测样本(samples=1000且全部为辱骂文本),vi为最终的人工评测结果,1为辱骂,0为非辱骂在(只对最终入围数据作人工评测,前期提交都认为vi=1);ci是分类结果,由多个线上模型作出评判并取均值,攻击成功为1,攻击失败为0;pi是原始文本与扰动文本的差异,综合考虑了字符差异和语义差异,最终结果Sfinal满分为1000分。详见赛题介绍: https://tianchi.aliyun.com/competition/entrance/231762/information 细看之下,可以发现,其中最重要值是ci,如果未攻击成功,该样本ci得分为0,而修改的多少pi相对ci没那么重要,只作为判断句意变化的辅助手断(否则整句替换将取得高分)。
比赛提供一个线下评测模型,它可能是多个线上模型之一,明显弱于线上模型,也就是说能攻击线下模型的算法,不一定能攻击线上模型;过分与线下模型对抗还可能造成对线下模型过拟合,反而影响算法的线上效果。但对选手来说,线下模型是一个重要参考,可以使用它做基础评价,此次比赛不提供训练数据,因此自行收集数据后,可用线下模型来判别其辱骂性质。
赛题可分解成两部分:定位哪些词是决定辱骂与否的关键词,以及如何替换,一开始笔者的工作重心在前者,认为只要能定位得足够精准,定位到足够少的词,随意替换成特殊字符即可;后来发现替换特殊字符可能改变其辱骂性质,而替换成特殊字符与替换成词线上得分差异非常大。因此,定位和生成都很重要。
收集数据
比赛不提供任何辱骂数据,靠选手自行采集,赛方给出一个辱骂文本生成网站:骂人宝典https://nmsl.shadiao.app/,可使用它生成一些辱骂数据(骂得够狠),试了一下,使用爬虫只能抓取1500条左右,去重之后仅400多条,可见一斑,但不足以训练。
(第二个知识点:爬虫与寻找辱骂场景,简单的数据工程)
笔者绞尽脑汁寻找网络辱骂的密集地带,典型场景,却始终未果。最终定位到豆瓣的低分影评,发现一星两星的影评辱骂比例在10-20%左右。觉得挺奇怪,不喜欢还买票去看,看完了还骂,这是怎么想的,看了评分最低的10部电影,还真不是没听说的电影和演员,还不乏王晶、郭德纲、周润发等明星,引起大家负面情绪可能不是实际的好坏,而是实际与期待的差异(差值):评价=实际-期待。
最终觉得下载太麻烦,于是在CSDN下载了影评数据库,花一些C币节省了时间。从中过滤出20000+辱骂数据,这样的数据量也可供简单训练了。
另外,还下载了“网络敏感词”,用于关键字判别。一开始笔者认为带脏字的才叫辱骂,毕竟网络上长期以来都以此作为评价标准,后来发现,如果只屏蔽脏字,得分在100之内(约只占10%)。目前的模型可以通过词之间的相互作用识别出大部分不带脏字却有攻击性的语言,只是要消耗一些时间和算力。
算法尝试
本次比赛笔者尝试了很多算法,虽然最终模型用到的不多,但也算对自然语言对抗的一些学习和尝试,在此分享。
对抗模型GAN
目前常用的对抗模型源自2014年的论文《Generative Adversarial Nets》,它同时训练两个深度学习网络,生成模型G(进攻)和判别模型D(防守),比如用对抗模型生成卡通头像,模型G用于生成头像,模型D用于判别图片是模型G生成的,还是实际的头像。两个模型交替训练,迭代提升。具体方法是通过梯度调整网络参数。由于图片是连续型数据,因此可以通过逐步微调来改进模型。
对抗网络生成序列数据时常使用SeqGAN方法,它源自2016年的论文《SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient》,与简单对抗不同的是,在一单次生成过程中,模型多次用到了生成模型G和判别模型D。以生成文字为例,每生成新词时,调用生成模型G根据当前已生成的词生成多个备选项,并使用判别模型对其评分(reward),根据评分选择最好的策略Policy,并调整策略模型(Policy Gradient)。这里涉及很多强化学习中的概念。
本赛题只需要替换句中的少数文字,较少涉及GAN生成连续数据时遇到的问题,可以将语言模型(比如BERT)作为生成模型,线下模型作为判别模型,用生成语句的评分变化调整生成模型,从而生成不易被察觉的辱骂文本,但这样做不能保证保留辱骂性质。
(第二个知识点:对抗网络)
强化学习模型
强化模型中最重要的概念是状态S,行为A,奖励R,根据当前状态,选择行为A,获得奖励R,然后逐步调整模型参数,以便再次遇到状态S时选择更好的行为,以便得到更大奖励。
近年来强化模型中最流行的算法是蒙特卡洛梯度策略,也是SeqGAN中用到的强化学习算法,蒙特卡洛树搜索常用于情况非常多,无法一一列举的场景,比如:当前比赛中一句话“ABCDEFGHIJKLMNOPQRSTUVWXYZ”,共26个词,如果从中删除三个词(多数情况不止三个)能达到最佳效果,则有2600种可能,若判别每种可能性,并且每次都生成这几个字的换代方案,将非常耗费时间。
最简单的方法是随机抽取,但是随机抽取的效果又不好,蒙特卡洛树搜索方法比较复杂,简单地说,就是一开始随机抽取一些组合,对其评分,并记录下来,对于评分越高的组合赋予更高的下次被选中的概率,经过多次迭代,使随机抽取偏向评分更高的策略。梯度策略一般使用深度学习网络与蒙特卡洛树搜索相结合,用两个模型分别调整策略和状态价值,使模型更快收敛。
(第四个知识点:强化学习模型)
笔者借鉴了蒙特卡洛梯度策略中的强化高分项随机抽取方法,作为定位辱骂关键词的算法。
Attention模型
Attention模型最几年超越了Text-CNN,RNN成为最流行的自然语言处理算法,其中又以GPT和BERT最为流行。GPT常用于生成文章,而BERT则更加灵活,由于其可参考前后两个方向的上下文,在完型填空类的应用中有明显优势。
本赛题在定位了辱骂位置之后,需要用其它词替换辱骂词,类似于完型填空,非常适合使用BERT模型,且BERT模型源码中提供了完型填空功能的API(笔者使用的是Transformers库Pytorch版本的BertForMaskedLM)。由于BERT可下载中文的预训练模型,由此无需训练也可生成较为通顺的语句。
(第五个知识点:自然语言处理模型)
在使用模型中也遇到一些问题:
-
BERT是结构和参数都很巨大的模型,每次预测都很耗时(尤其是在没有GPU支持的情况下),因此必须限制使用次数,还有一种方案是使用ALBERT,它是一个简化版的BERT,效果差异不大,但模型只有BERT的几十分之一大小,速度也更快一些。
-
是否需要使用自己构建的辱骂数据集对BERT做fine-tune,这是个两难选择,如果find-tune,那么BERT生成的文本更趋近辱骂,更容易被模型识别,如果不fine-tune,生成非辱骂文本,最终版本又可能通不过人工评测。且本地数据集都使用线下模型过滤得到,这样训练也可能会过拟合线下模型。
笔者还做了另外一些尝试,比如训练GPT,使用BERT训练一个辱骂判别模型,把数据拆分成8:2分别用于训练和验证时,测试集的成功率在97-98%,从它模型的Embedding层以及隐藏层中抽取数据,希望能定位到一些辱骂的关键词,但是由于数据过于细碎,最终没能实现(当时没想到用gensim根据Embedding找同义词,以及用加减法做组合减去辱骂性质的方法,后来觉得非常值得尝试)。
笔者在本次比赛提交的最终版本中只使用了基本的BERT模型,每次选可能性最高的topN个词作为备选项,选出其中辱骂评分最低的,并限制了调用次数,同时尝试批量预测以节约时间。但调用次数太少,线上没能达到期望的效果。感觉最好的方法可能是使用BERT模型与评测工具相结合,先用辱骂数据fine-tune辱骂模型,然后在生成词的过程中将评测工具的得分作为评价,让模型向生成非辱骂的方向进化,听起来就很矛盾,也还没来得及尝试。
其它算法
除了上述典型方案之外,笔者还尝试了其它一些方法,下面列出其中比较有效的方法。
-
计算差异
对于句子“ABCDEFGHIJKLMKOPQRSTUVWXYZ”,从第1个字符开始,每添加一个字符,对该句进行一次评分,如:第一次“A”,第二次“AB”,并将二者差异作为B的评分,最终排序各词的辱骂性质,依次替换分数最高的词,如果替换后判别不是辱骂,则完成修改。这样的好处在于,对于26个词组成的句子,基础判别只需要做26次,也明显减少了替换次数。原理是如果某词加入后分数明显增加,则说明它是关键词(可能由于与前词组合后才变得关键),分越高越应该被替换。 除了从前向后添加,还尝试了从后向前添加,去掉某个词后对句子评分等方法,其中上述的从前向后添加方法效果最好。 在强化学习的评价中也涉及差异对比,用相对打分(绝对分值减均值)替代绝对分数,该方法在机器学习中也常用于抽取关键特征。 -
辱骂词替换
估计绝大多数选手都使用了,敏感词替换,比如把“某个亲属”,“某个动词”替换成非敏感词。这里笔者将其作为辅助手段,在其它处理完成之后进行了辱骂词替换。主要根据“网络敏感词”表中“色情”中的内容判别辱骂词。 -
高频词
另外一种定位高频词的方法是使用蒙特卡罗方法定位各句中可能性最大的辱骂词,并统计其中最高频的词,然后对各句替换这些词。

可以看到,最高频的词是“你”,当时笔者认为这个词太普遍,并未加以处理(此处埋下伏笔),而对其它一些更明显的辱骂词做了变换。
- 与黑盒对抗
线上模型对选手来说几乎是黑盒,它与线下评测版本的差异只能靠猜测和试榜(尽可能多提交版本,通过线上得分猜测其内部逻辑)。这样对抗限制了很多模型的效果,因为线下评分变好,可能是对线下模型的过拟合,线上反而可能变差。换言之,这不完全是一个有监督学习问题,因为线下的label并非线上的label,同样也不完全算强化学习问题,因为线下的reward也不是真实的reward,除非我们自己在线下实现与线上类似的评测逻辑(短时间内很难做到)。
另外一个难点在于,最后还加入了人工评测,需要让线上模型认为不是骂人,而人认为是骂人,又增加了一层难度,且这个层面的判别完成没有label和reward可用。
借鉴他人算法
终于在比赛结束前的最后一个小时冲进了排行榜第一页(Top20),感觉像长跑比赛里,已经筋疲力尽,还被前面的同学落下好几圈,终于坚持跑到了终点,然后豁然轻松。晚上大家就在钉钉群里公开了很多方法,果然脑洞大开,总结如下:
弱点攻击
一位大侠的算法是把实例中所有的“你”字替换成与之类似的同音同意字,并在该字之后加一个阿拉伯数字,只用一行代码打到600多分,完胜所有人。 相信很多同学也观察到了辱骂中“你”字的特殊性,但“你”在人的认知中明显不是辱骂词。后来赛方也在聊天时说,对有些明显的辱骂词做了保护,但也没特殊处理“你”字,这便形成了最终被击破的漏洞。 只替换“你”提分有限,更有趣的是他还在“你”后面加了数字,笔者认为这个方法可以用于攻击文字组合后的特殊含义,尤其是打破了CNN、RNN类模型的前后依赖性,能想到这点也很厉害。 (第六个知识点:模型原理) 添加的还是“数字”,其实在赛方提供的demo中,就可以看到如果将“死”替换成4就能骗过模型,数字也可以算是一个漏洞,或者说暗门。而这位排名第一的大侠有效地结合了上述三点。
在文中加减内容
大家也分别尝试了向文中加符号,加空格,加文字来降低其辱骂性质,尤其对于短文本,试想如果句子只有两个字,全部替换掉,则相似度得分为0,只替换其中一个,还可能被识别为辱骂,加入内容也是个好办法。但不知为何,笔者尝试后并没提分。删除内容也是一种方法,尤其是长文本可能导致大量计算,适当删减也是一种好办法。
用词向量找同义词
定位辱骂关键词,并找同义词替换,也是一种普遍使用的方法,有人使用了腾讯词向量,它提供800多万中文词条,相对于传统的同义词词林或词表来说,可以说非常高科技了,但是它提供的是一个通常意义上的词义,自然语言任务可用它从文字中提取特征向量化(供机器学习算法使用),下面是官方给出的示例。

除了近义词,Gensim还提供了加法减法功能,比如“king” - “man” + “woman” ≈”queen”,也是很好的想法。 腾讯词向量虽然内容丰富,但是速度也非常慢,使用赛方提供的词向量可能更好一些,另外,还可以用辱骂语料训练模型,并从中提取词向量,以及使用上面提到的减法功能。已在blog上具体用法文档。
(第七个知识点:知识面)
梯度攻击
赛方比较推荐的方法是梯度攻击,其原理是调整输入让损失函数变大,具体做法是损失函数对输入求导,然后根据导数方向调整输入数据,调整Embedding层数据后再通过词向量工具反推具体文字。很巧妙的方法,如果不看论文,自己很难想到。
Fasttext模型
赛方给出的线下评测是Fasttext模型,速度快且效果好。赛后看了fasttext相关论文,发现似乎还可以从简单模型与深度学习模型的差异下手来寻找漏洞,比如n-gram一般涉及的相关词很少,因此通过拉大词距,就可能造成干扰,也可以从中提取词向量特征,词袋模型不支持语序等等。
总结
攻击比赛需要研究对方的算法原理,弱点。这一次没有深入探索赛方提供的信息,本来是半黑盒,让我理解成了全黑盒。没好好读题,然后越走越偏,太多explore又太少exploit,需要在未来的比赛中认真对待。
比赛和真实场景有很大差别,比赛可以通过试榜、拟合评价函数争取高分,而实际场景中更重视问题本身,比如怎么能更好地识别辱骂,更好的保留句意和辱骂性质同时骗过模型,如何利用新的技术,泛化现有算法,而不仅是捕捉模型的漏洞。
这次虽然成绩不佳,但也收获颇丰:有的领域从未知到已知,有的从模糊到了解,有的从知道到使用。非常感谢赛方提供的平台以及活跃在讨论区的小伙伴们。
赛后一周回顾了比赛相关的技术,写了一些文档:
生成对抗网络GAN
https://blog.csdn.net/xieyan0811/article/details/104297872
序列对抗网络SeqGAN
https://blog.csdn.net/xieyan0811/article/details/104820731
自然语言处理——使用词向量(腾讯词向量)
https://blog.csdn.net/xieyan0811/article/details/104737002
梯度攻击
https://blog.csdn.net/xieyan0811/article/details/104790915
轻量级BERT模型ALBERT
https://blog.csdn.net/xieyan0811/article/details/104838175
强化学习(一)基本概念和工具
https://blog.csdn.net/xieyan0811/article/details/104848328
Fasttext快速文本分类
https://blog.csdn.net/xieyan0811/article/details/104873708
最近准备换一份自然语言处理(或者深度学习)相关的算法工作,工作地点最好在北京海淀附近,可以给个机会的小伙伴请与我联系哦。 :P 邮箱[email protected],微信66768512。