从微软Cosmos DB浅谈一致性模型
最近回顾了微软的Cosmos DB的提供一致性级别,重新整理下一致性模型的相关内容。
0. Cosmos DB
Cosmos DB(Azure Cosmos DB)是由微软推出的一个支持多模型、多 API 的全球分布式数据库服务。它旨在提供高度可扩展性、低延迟、强一致性和全球分布的能力,以满足各种应用程序的要求。关键特性如下:
- 多模:支持多种数据模型,包括文档、图形、列族、键值对和表格。最关键一点是多模数据类型的支持,比如地图业务很常用GIS数据类型
- 全球分布:在多个 Azure 区域中复制和分布,从而实现低延迟、高可用性和强一致性。用户可以选择多个一致性级别,比如强一致性、最终一致性。一致性就是本文所要讨论的
- 多租户: 支持多租户模型,从而不同应用/客户可以隔离,这也是很多数据库产品均提供的重要能力
- 自动扩缩容:根据负载的变化自动调整吞吐量和存储
- 多API支持:比如这次hiSQL、MongoDB、Cassandra、Gremlin和 Azure Table Storage。研发可以使用他们熟悉的编程模型和查询语言
- 全面的 SLA(服务水平协议): Cosmos DB 提供了强大的 SLA,包括在读写延迟、可用性、一致性和吞吐量等方面的保证
- …
一、一致性模型
在之前的一篇文章:浅谈CAP+ACID+BASE理论 介绍了在为什么会有CAP理论( PACELC theorem),其中C就是本身所述的一致性模型。
理想情况下,真正的一致性模型只有一种,即强一致性(或者说严格一致性,或者说满足linearizability )。
- 强一致性模型含义
在分布式系统中,当对某个数据项进行了写入后,所有后续的读者都可以看到该数据项的更新。它确保所有的操作看起来像在一个全局的、实时的、顺序的序列中执行,而且这个序列必须满足实际发生的操作顺序。线性一致性提供了最高的一致性保证,但也可能对系统的性能造成较大的影响。
为了保证强一致性的语义,这无疑会增加写入的耗时。因此在真实的系统中,有的系统采用了最终一致性,但是会因为过程中数据不一致会导致逻辑和语义不清晰。
二、Cosmos DB-一致性模型
Cosmos DB特点在于:目前市场上大多数商业可用的分布式NoSQL数据库仅提供强一致性和最终一致性。Azure Cosmos DB却提供了五个明确定义的一致性级别,从最强到最弱分别是:
- Strong:强一致性模型
- Bounded staleness:有界旧一致性模型
- Session:会话一致性模型
- Consistent prefix
- Eventual:最终一致性模型
Cosmos DB提供更为精准的一致性模型选择,客户可以基于业务自身需求以及真实场景,选择合适的一致性模型,从而在读写耗时、吞吐、性能、一致性等多个角度获取权衡。
参考的Cosmos DB一张图:
Strong具备最强的一致性,一致性级别越低,写延迟越低、吞吐越高。
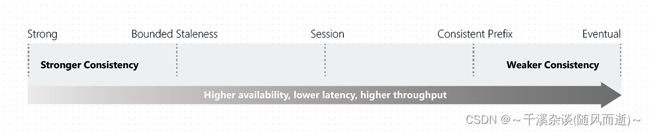
如果只分为两类:
- 强一致性模型:Cosmos DB的写入会被复制到本地区域Region的至少三个副本(四个副本满足多数派),并同步复制到所有其他区域
- 弱一致性模型:写入会被复制到本地区域Region的至少三个副本(在四个副本满足多数派),并异步复制到所有其他区域
2.1 Strong
强一致性提供了线性一致性(linearizability )的保证。线性一致性是指并发多个读写请求。读操作始终保证返回数据项的最新已提交版本。客户端永远不会看到未提交或部分写入。用户始终保证读取到最新已提交的写入。
具体的例子可以参考Cosmos DB文章中的一个基于音符的动态图。
在数据从任何一个Region写入后,从其他任何Region都可以读取到该数据项的最新写入。
2.2 Bounded staleness consistency
Cosmos DB单个租户数据可能分布在多个Region中,可能出现如下两种场景:
- 客户只在单个Region中写入,写入的数据会从主Region(即写入的Region)复制到其他只读的Region
- 客户在多个Region写入,写入的数据会从所属Region(即写入的Region)复制到其他的Region
因为存在数据复制,不同的Region的不同副本可能会存在延迟。在数据复制过程,任意两个Region之间的数据落后始终小于指定的数量,该数量可以是“K”个版本,也可以是“T”个时间间隔。因此Bounded staleness consistency-有界旧一致性,定义两个指标如下:
- 数据项的版本数(K),简单理解即一个数据项被写过几次
- 读取可能落后于写入的时间间隔(T)
当选择有界旧一致时,可以通过上述两种方式配置任何区域中数据的最大“陈旧”程度:
- 如果租户分布在多个Region,单个Region中写入,数据复制到其他Region;当数据落后于指定上述配置,那么写入会限速,避免落后持续变大,直至数据落后程度恢复到配置值之内
- 如果租户只分布在单个Region中,有界旧一致性提供与会话一致性和最终一致性相同的写入一致性保证。有界旧一致性将数据复制到单Region中的本地多数(即满足多数派,比如四个副本,三个副本复制成功)。
Cosmos DB提到两个注意事项:
- 使用有界旧一致性,陈旧性检查仅在Region之间进行,而不在Region内进行。在给定Region内,数据复制满足多数派,而不论一致性级别如何。在Region内读取,通过读取两个可用副本的数据(因为多数派)来获取本Region内最新的数据
- 使用有界旧一致性,对非主Region发出的读取操作可能不会返回全局最新版本的数据,但是保证返回该Region中最新版本的数据,且该版本在全局最大陈旧度边界之内。
2.3 Session consistency
会话一致性保证在单个客户端会话内,读取操作将遵守“ read-your-writes,”和“write-follows-reads”的保证。此保证假定存在单个“写入者”会话或在多个写入者之间共享会话令牌。会话一致性本质的语义就在于满足:
Read-Your-Writes (RYW)
- 定义: 如果一个进程在某个时间点读取了一个数据项,并在之后写入了该数据项,那么该进程之后的任何读操作(不管读几次)都将能够看到其之前的写入。一个进程写入的任何变化对其自己后续的读操作都是可见的。
Write-Follows-Reads (WFR)
- 定义: 如果一个进程在某个时间点读取了一个数据项,并在之后写入了该数据项,那么该进程的写操作不会被安排在其之前的读操作之前。一个进程的写入不会立即影响到其之前的读取。
工作流程
- 如果客户端没有对物理分区发起写操作,则客户端在其缓存中不包含会话令牌(Token),对该物理分区的读取将表现为最终一致性的读取。如果客户端被重新创建,其会话令牌缓存也会被重新创建。在这种情况下,读取操作遵循最终一致性。
- 在每次写操作之后,客户端会从服务器接收一个更新的会话令牌(Token)。客户端缓存这些令牌,并在指定的Region中的读取操作中将它们发送给服务器。
- 如果执行读取操作的副本包含指定令牌(或更近的令牌)的数据,则返回请求的数据。
- 如果副本不包含该会话的数据,客户端将在该Region内对另一个副本重试该请求。如果有需要,客户端会在额外的可用Region内重试读取,直到检索到指定会话令牌的数据。
同时需要注意:
- 会话一致性的令牌保证数据读取不能太旧(最小版本Barrier),但不是具备类似MVCC指定版本读取的语义。当使用会话一致性中,客户端使用会话令牌确保永远不会读取与较旧会话对应的数据。如果客户端使用的是较旧的会话令牌,而数据库已经有了更新的写入(比如Token=100, 数据A已经有一系列修改1 2 3 4,Token=100其实对应的3的修改时间),那么尽管使用的是较旧的会话令牌100,也会返回更近版本的数据4。会话令牌被用作最小版本Barrier,但不用作从数据库指定的数据版本。
- 令牌分区绑定分区
2.4 Consistent prefix consistency
前缀一致性中表示:如果一个操作在一个进程中排在另一个操作的前面,那么在所有进程的操作中,这个顺序将得到保持。它保证操作的顺序形成一个一致的前缀,虽然不一定反映实时的顺序。
举例而言:假设在事务T1和T2中对文档Doc1和Doc2进行了事务性的(要不成功,要不失败)两个写操作。当客户端在任何副本中进行读取时,用户将看到“Doc1 v1和Doc2 v1”或“Doc1 v2和Doc2 v2”,或者如果副本落后,则两个文档都不可见,但永远不会看到,“Doc1 v1和Doc2 v2”或“Doc1 v2和Doc2 v1”。
2.5 Eventual consistency
最终一致性的含义在于:
- 客户端发出读取请求,针对指定Region中的任何一个四个副本。这个副本可能落后,因此可能返回陈旧甚至无数据返回。
- 随着时间的推移,最终的修改也是能读取到的。
最终一致性是一致性模型的最弱保证,因为客户端可能读取比其过去读取的值更旧的值。最终一致性在应用程序不需要任何排序保证的情况下是理想的,性能、吞吐等最高。对于某些业务,比如微博点赞数、评论数量,采用最终一致性其实很合适。
三、Cosmos DB 一致性模型总结
- 如果数据库上没有写操作,使用最终一致性、会话一致性或前缀一致性级别的读取操作可能会产生与使用强一致性级别的读取操作相同的结果。
- Cosmos DB提供了之统计和指标,了解客户端可能在您的工作负载中获得强一致性读取的概率。通过Probabilistically bounded staleness指标
3.1 latency-延迟保
- 读延迟:对于所有一致性级别,读取的延迟在99%始终保证小于10毫秒。平均读取延迟,在50%通常为4毫秒或更短。
- 写延迟:对于所有一致性级别,写入的延迟在99%上始终保证小于10毫秒。平均写入延迟,在50%通常为5毫秒或更短。如果跨越多个区域并配置为强一致性级别无法保证(跨区域的RT各种因素)
3.2 throughput-吞吐
- 对于强一致性和有界旧一致性,读取是在四个副本集中的两个副本(少数派法定人数)上进行的,以提供一致性保证。会话、前缀一致和最终一致性执行单个副本读取。因此,对于相同数量的请求单元,强一致性和有界旧一致性的读取吞吐量是其他一致性级别的一半。读两个副本和读单个副本的区别。
- 对于给定类型的写入操作,例如insert、replace、upsert和delete,请求单元的写入吞吐量在所有一致性级别上都是相同的。对于强一致性,写入需要在每个区域(全局多数派)中提交,而对于所有其他一致性级别,使用的是本地多数派(四个副本中的三个副本)
| Consistency Level | Quorum Reads | Quorum Writes |
|---|---|---|
| Strong | Local Minority | Global Majority |
| Bounded Staleness | Local Minority | Local Majority |
| Session | Single Replica (using session token) | Local Majority |
| Consistent Prefix | Single Replica | Local Majority |
| Eventual | Single Replica | Local Majority |
上述表格总结了不同一致性级别(Consistency Level)下的读取和写入的情况。这些一致性级别是在分布式系统中用于平衡一致性和性能的不同保证。其中:
“Quorum Reads” 表示需要读取的副本数量,以满足一定一致性级别。
“Quorum Writes” 表示需要写入的副本数量,以满足一定一致性级别。
3.3 data durability- 数据持久性
首先解释两个概念:
在数据库系统领域,RPO(Recovery Point Objective)和 RTO(Recovery Time Objective)是两个关键的恢复目标,用于确定业务连续性和灾难恢复计划。
-
RPO(Recovery Point Objective):
定义: RPO是指在灾难事件发生之前,客户可以接受的数据丢失的最大时间间隔。RPO确定了业务可以接受的数据损失的程度。 -
RTO(Recovery Time Objective):
定义: RTO是指在灾难事件发生后,客户需要将其业务系统和功能恢复到正常运行状态所需的最长时间。RTO表示了业务能够接受的最大停机时间。
在金融领域的数据库,一个最重要的保证是任何场景下,不能丢失数据,因此往往PRO要做到0,即不管任何异常都不能丢失任何数据;同时尽量降低RTO,即异常后恢复可服务的时间,这个时间越小越好。
在全球分布的数据库环境中,一致性级别的设置与在发生区域性故障时数据持久性之间存在直接关系。即客户需要了解在不同的级别下,在异常场景下是否会出现数据受损。即RPO指标。
| Region(s) | Replication mode | Consistency level | RPO |
|---|---|---|---|
| 1 | Single or Multiple write regions | Any Consistency Level | < 240 Minutes |
| >1 | Single write region | Session, Consistent Prefix, Eventual | < 15 minutes |
| >1 | Single write region | Bounded Staleness | K & T |
| >1 | Single write region | Strong | 0 |
| >1 | Multiple write regions | Session, Consistent Prefix, Eventual | < 15 minutes |
| >1 | Multiple write regions | Bounded Staleness | K & T |
其中:K是数据项的版本数;T是上次更新后的时间间隔。
对于Region帐户, K 和 T 的最小值为 10 次写入操作或 5 秒。对于多Region帐户,K 和 T 的最小值为 100,000 次写入操作或 300 秒。
- 当只有一个Region时,任何一致性级别,RPO都很大。
- 当有多个Region,和复制模型有关:
(1) 当只写一个Region, Session, Consistent Prefix, Eventual 的RPO小于15分钟;而Bounded Staleness 的PRO和K、T有关系;Strong保证不丢失数据
(2) 当写多个Region, Session, Consistent Prefix, Eventual 的RPO小于15分钟;而Bounded Staleness 的PRO和K、T有关系
(3) Azure Cosmos DB帐户配置了多个写入区域后,无法配置为强一致性,因为对于分布式系统来说,提供零的RPO=0(恢复点目标)和RTO=0(恢复时间目标)是不可能的,既要也要做不到!
| Consistency Level | Guarantees |
|---|---|
| Strong | Linearizable reads |
| Bounded Staleness | Consistent Prefix. Reads lag behind writes by k prefixes or t interval |
| Session | Consistent Prefix. Monotonic reads, monotonic writes, read-your-writes, write-follows-reads |
| Consistent Prefix | Updates returned are some prefix of all the updates, with no gaps |
| Eventual | Eventual |
四、小结
一致性模型最重要的还是需要结合具体的场景、业务需求,到底在延迟、吞吐、数据一致性等方面最大的诉求的是什么,从而选择合适的一致性级别。甚至业务设计时需要提前做好业务。整体:技术服务于场景