c++的堆与拷贝构造函数
关于堆的知识
一般情况下c程序会存放在rom或flash中,运行再拷贝到对应的内存中。c++程序中内存分别存放不同的信息,
(1)全局数据区:存放全局变量、常量、静态数据
(2)代码区:存放程序的代码
(3)栈区:存放局部变量、函数的参数、返回数据、返回地址等
(4)堆区(自由存储区):作为其他操作的使用的资源
当我们的程序通过new或者malloc申请到了一些堆内存时,我们就有责任去回收它们,否则会造成内存泄漏,另外c++管理这些内存时很辛苦的一件事情,频繁的申请和释放内存,会产生大量的堆碎块
堆区和栈区的比较
栈区:
栈是向下增长的,存放的是一些局部变量,参数,返回地址、返回值等,栈中分配局部变量空间,(由系统分配)
堆区:
堆是向上增长的,用于分配程序申请的内存区。
区别
堆区和栈区的区别就是在于内存分配的方式上,另外就是内存空间回收方式上,栈区的内存也是系统自动完成的,当函数运行完后,栈上的内容就被释放了。堆中的内容只要程序不去释放,它就一直都在,但是这样会造成内存泄漏。
申请后的反应
栈区:
只要栈区中有大于申请的空间的内存,系统就会为程序提供内存,否则,会发生异常
堆区:
操作系统中有一个记录闲时的内存地址的链表,当系统收到空间申请时,就会去查找那个表,找到第一个空闲空间大于申请空间的结点,然后把该结点从该链表中删除,并将该结点的空间分配给程序。另外,多数系统会在该结点的首地址记录分配的内存的大小,从而可以在delete时,释放正确的内存空间。
申请效率比较
栈区:
系统自动分配,速度快,但是空间有限,WINDOWS下只有2M,
堆区:
由于分配堆区后,还有很多后续工作,如删除结点,记录分配的空间的大小等。所以效率较低,但是空间充足,程序员可以很好的控制它。
需要new和delete的原因
以前看过一个文章写的是“学好c++必须做到的50条”,我很同意里面的一句话:“不要因为c和c++中有一些语法和关键字看上去相同,就认为它们的意义和作用完全一样;”,这句话正好在这里可以显示其正确性,
c++中不能使用malloc的一个原因就是:它在为指针对象分配空间时,不能够调用构造函数。一个类的对象的建立包括三个部分:
- 分配空间
- 构造结构
- 初始化
但是上述三个部分统一由构造函数完成的。于是我们就需要new和delete来完成对对象的空间的分配和内存的释放。其分配的内存空间就是在堆区中的内存。另外由于类的构造函数是可以有参数的,所以new后来的类类型也是可以有参数的。
#include输出结果:

另外从堆中还可以分配对对象数组,下面给个范例:
#include输出结果:
但是这里有一个需要注意的地方,如果我们自己为类提供了一个有参的构造函数时,但是你又要构建一个对象数组的时候,你就需要手动的为类添加一个无参的构造函数,否则程序将会报错,如下图所示:
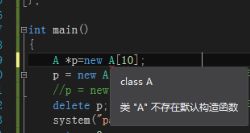
报错的原因是,我们在声明一个对象的数组时,最后面是跟数组的大小,无法再添加构造函数的参数了,所以它只能够调用无参构造函数了。
delete [] p,这个是告诉系统,该指针指向一个数组,如果没有添加[],程序会产生运行错误。
类对象数组初始化的方法
(1)对象数组
A p[2]={A(10,1),A(10,2)};
//A p[2];
//p[0]=new A(10,1); 这种方式是错误的
//A *p=new A[2];
//p[0]=new A(10,1); 这种方式同样是错误的。
//其实通过A p[2]和A *p来声明一个对象数组时,要初始化,只有靠其构造函数自己提供默认的初始值。(2)指针数组
typedef A * p;
p P[2]; //相当于p * P =new p[2],P相当于一个二级指针
for (int i = 0; i < 2; i++)
P[i] = new A(10, i); //相当于P就是一个二级指针,所以可以对P[i]直接使用new
for (int i = 0; i < 2; i++)
delete P[i]; //因为P是一个二级指针,P[i]相当于就是一个指针拷贝构造函数
因为对象的类型多种多样,不像基本数据类型这么简单,所以并不能像普通类型一样直接拷贝,如:
int a=5;
int b=a; //用a的值拷贝给新建的b类对象中,如果要用一个对象去初始化另外一个对象,则必须是调用的类的拷贝构造函数去初始化那个对象
下面是一个使用拷贝构造函数的例子
#include输出结果:
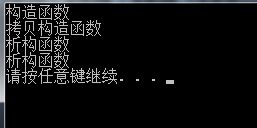
通过上述代码的输出结果,我们可以发现stu1的创建时,通过调用stu1的拷贝构造函数,从而把对象stu整个复制到stu1,
默认拷贝构造函数
c++的类定义中,如果程序中没有为类提供拷贝构造函数,那么系统提供一个默认的拷贝构造函数。
#include输出结果:

我们都知道函数参数的传递有两种方式:
- 值传递:会产生实参的副本,将副本传给函数
- 引用传递:不产生副本,直接把自己传给函数
所以需要产生副本,那么就需要调用拷贝构造函数啦。
c++中使用拷贝构造函数的三种情况
(1). 使用已经存在的对象去初始化另外一个对象
Student stu(10, "Ouyang");
Student stu1 = stu; //等价于:stu1(stu);这种方式,我们可以更容易的理解,拷贝构造函数只是特殊注释:两个对象必须是同类的对象,stu1都是通过调用其拷贝构造函数来初始化自己。
(2):作为函数的返回值
#include输出结果:

注释:
第一行:创建主函数中的stu对象时,调用了无参构造函数,
第二行:进入了函数fun,调用了有参构造函数,从而创建了fun中的stu对象,
第三行:生成了一个临时对象,我们就叫他为stu_copy,stu_copy是通过调用拷贝构造函数,所以输出了 第四行,完成对fun中的stu对象的拷贝,然后把stu给析构了。所以输出了第五行。
第六行:由于主函数中的stu首先是通过无参构造函数创建过一次,如果要重新对其赋值的话,就要先把原来那个对象给析构了,
第七行:同样是进入fun后,完成了第三行工作,第八行时完成了第四行的工作,第九行完成了第五行的工作。
(3):作为函数的参数进行值传递的时候
#include输出结果:

第一行:调用构造函数,创建s对象
第二行:调用构造函数,创建s1对象
第三行:当s对象要传入fun的形参时,会先产生一个临时对象,设定就是stu,然后调用拷贝构造函数,把s对象的值拷贝到stu中。
第四行:此时就是调用函数的过程
第五行:第三行产生的临时对象,在函数调用完成时,就会被析构。
第六行:由于当我们调用函数fun1时,使用的引用传递,所以不需要产生临时对象,只有函数调用
浅拷贝和深拷贝
(1)浅拷贝
当我们使用默认拷贝函数的时,它采取的一个成员一个成员的拷贝,但是当成员涉及使用资源(堆区)时,由于默认拷贝函数只是简单的制作了一个对象对拷贝,而不对它本身进行资源分配和复制,这样就会发生一种现象就是:两个对象同时拥有同一块资源,当对象析构时候,该资源会发生两次归还。
#include输出结果:
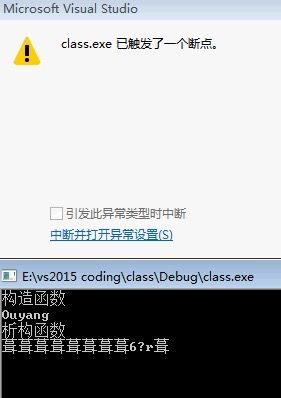
第一行:调用构造函数,创建了对象s
第二行:调用了析构函数,输出了了name,析构对象s1。
第三行:同样是析构函数中的内容,
第四行:打算析构对象s,首先还是先输出name,由于在析构s1时,我们就已经归还了资源,此时输出就是一堆乱码,
最后就是程序想再次归还已经归还的资源,程序就爆出来异常。
浅拷贝可以用下图形象的表示:
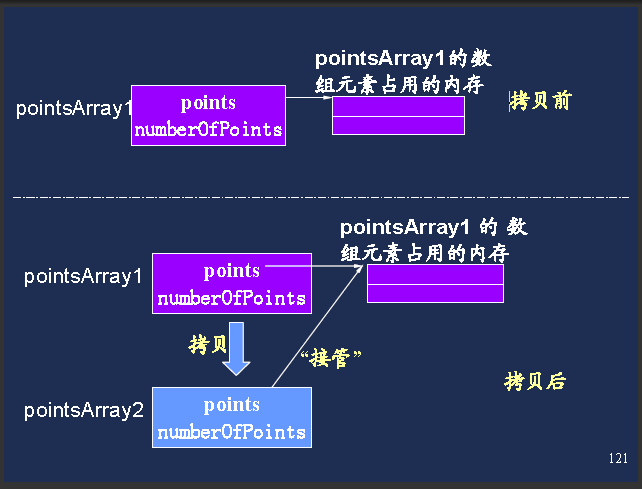
(2)深拷贝
深拷贝就是不但复制了对象的空间,也复制了对象的资源,从而不会出现两个对象共用一份资源的现象。
#include0]='\0';
if (name!=NULL)
delete name;
cout << "析构函数" << endl;
}
};
int main()
{
Student s(10, "Ouyang");
Student s1 = s;
//system("pause");
return 0;
} 输出结果:

这次是在codeBlocks中跑出来的结果,因为对vs不是很熟悉,总是会跑出异常,
第一行:创建s时,调用了构造函数
第二行:创建s1时,调用了拷贝构造函数
最后就是分别析构两个对象了,我们可以发现这两个对象的析构是一样,当s1被析构后,它只是归还了其申请的内存,对s对象没有影响,所以有个明文规则:如果类的析构函数会被用来归还对象的申请的资源时,则它也需要一个拷贝构造函数。
拷贝构造函数细节
为啥要用引用:
在函数调用中,具有非引用类型的参数要进行拷贝初始化,这也就解释了为什么拷贝构造函数的参数必须是引用的了,如果不是,那么它就相当于一个普通的函数,需要调用拷贝构造函数来初始化它的非引用的参数,从而就是一个无限循环了。