【IJCAI2022】Uncertainty-Guided Pixel Contrastive Learning for Semi-Supervised Medical Image Segmentat
Uncertainty-Guided Pixel Contrastive Learning for Semi-Supervised Medical Image Segmentation, IJCAI2022
论文:https://www.ijcai.org/proceedings/2022/0201.pdf
代码:https://github.com/taovv/UGPCL
简介
论文将对比学习引入半监督分割,并提出了一种新的不确定性引导的半监督医学图像分割像素对比学习方法。具体来说,为每个未标记的图像构建一个不确定性图,然后重新移动不确定性图中的不确定性区域,以降低噪声采样的可能性。不确定性图由精心设计的一致性学习机制确定,该机制通过鼓励来自两个不同解码器的一致性网络输出来生成对未标记数据的全面预测。此外,论文认为由图像编码器学习的有效全局表示对于不同的几何变换应该是等变的,于是构造了一个等变对比损失来增强编码器的全局表示学习能力。
动机
现有方法主要通过构建可信的伪标签 或扰动输入强制预测一致性来利用未标记数据,但,使得每个像素的分类独立,忽略了图像像素(或特征)之间的内部相关性。
对比学习的思想在于,相似样本的表征应该是相似的,不同类型样本的表征应是不同的。
图像分割中,相似的像素分布密集,如何构建适用于像素级的对比学习呢,常见做法是使用伪标签构建对比样本。但伪标签构建样本可能与实际语义类别不一致,可能导致对比学习中的噪声采样问题。且,像素对比学习只建立了局部像素的关联,忽略了全局表示信息的学习。
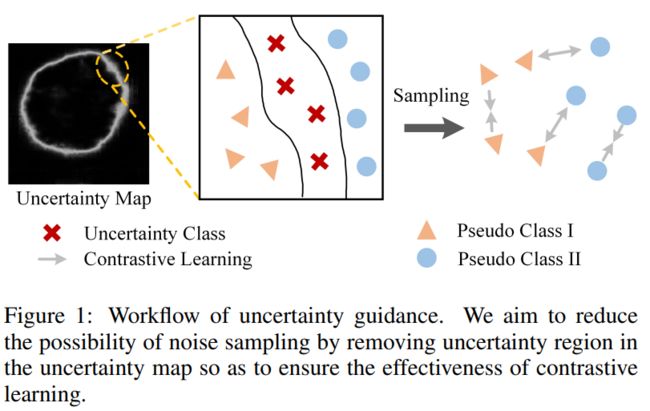
因此,论文的目标在于:
- 解决使用伪标签的对比学习的噪声采样问题,
- 增强编码器的全局表示学习能力。
为此,论文提出了一种基于不确定性的对比学习方法。图1显示了本文方法的核心思想。
- 对于未标记的数据,使用不确定性图来引导伪标签采样的区域,并减少错误样本的数量。然后计算样本对比损失,以优化网络,减少预测的不确定性区域。
- 为了获得更好的不确定性图,设计了一种具有CNN解码器和Transformer解码器的一致性学习策略,该策略可以利用两个解码器之间的结构差异从不同的角度获得精确的预测。
- 此外,分割模型应该具有识别几何变换的能力,定义了一个等变对比损失,通过在表示学习阶段添加变换类别预测,迫使网络学习几何变换的识别信息。
方法
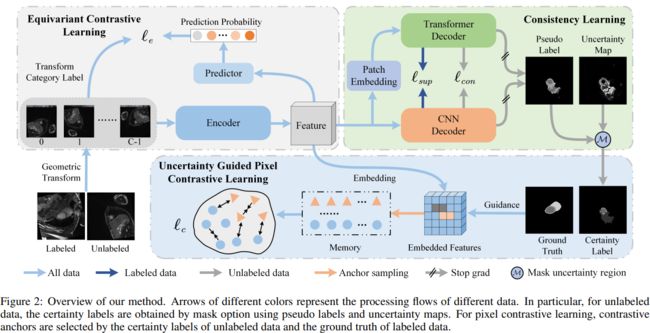 图2:方法概述。不同颜色的箭头表示不同数据的处理流程。特别是,对于未标记的数据,确定性标签是通过使用伪标签和不确定性映射的掩码选项获得的。对于像素对比学习,通过未标记数据的确定性标签和标记数据的基本事实来选择对比锚。
图2:方法概述。不同颜色的箭头表示不同数据的处理流程。特别是,对于未标记的数据,确定性标签是通过使用伪标签和不确定性映射的掩码选项获得的。对于像素对比学习,通过未标记数据的确定性标签和标记数据的基本事实来选择对比锚。
DL和DU中的图像先经过几何变换,再输入编码器网络以提取多尺度特征。再把这些特征发送到三个分支中:一致性学习分支、不确定性引导的对比学习分支和等变对比学习分支。
- Consistency Learning,一致性学习分支,提出一个异质一致性网络来预测分割结果,由监督损失Lsup和一致性损失Lcon驱动。
- uncertainty-guided contrastive learning, 不确定性引导的约束学习分支,建立一个记忆队列,以保留足够的样本用于约束学习。记忆队列中样本的选择取决于DL的标签和DU的确定性标签。对于所选样本,施加像素级的对比损失Lc,以使同一类的像素彼此靠近并且使不同类的像素相互远离。
- equivariant contrastive learning,等变对比学习分支,对所有标记和未标记的数据进行几何变换类别预测,并设计一个等变对比损失Le以迫使编码器对几何变换具有鲁棒性。
整体框架的总优化目标是:
![]()
![]()
Consistency Learning
设计一个CNN解码器和Transformer解码器结构,实现两个目标:
- 使用未标记的数据来促进分段网络的学习,
- 从网络输出中获得可靠的不确定性估计。
研究表明,使用协同训练策略可以获得更好的分割性能,其核心思想是从不同的角度做出不同的分类预测,然后将预测的差异作为不确定性估计的衡量标准。本文利用了变换器解码器和CNN解码器之间的先天差异。具体地说,构造了一个非一致的预测器来约束两个解码器产生一致的预测,然后使用均值预测的熵来估计不确定性图。
可以从两个解码器获得两个预测的概率分布pt和pc。对于标记数据,使用真实标签gt来计算监督分割损失:分割损失由CE和Dice取均值。
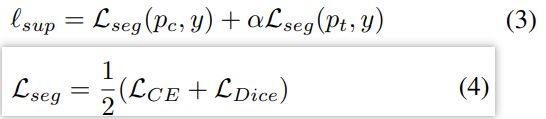
对于无标记数据,使用距离度量来计算一致性损失,使用MSE作为距离度量。
![]()
Uncertainty-Guided Contrastive Learning
使用交叉熵损失容易使得每个像素的分类是独立的,忽略了像素之间的关系。为此,设计了一种像素级对比学习机制,将同一类别(语义标签)的像素分类为正样本,将不同类别的像素归类为负样本。像素之间的关系是通过在嵌入空间中减小正样本之间的距离和扩大负样本之间的间距来建立的。为了有效地将未标记数据用于像素级对比学习,估计了未标记像素的不确定性,并选择确定性较高的像素作为对比学习的锚点。
Mask Uncertainty Region. 我们选择预测熵作为度量来近似不确定性。具体而言,首先计算预测结果的平均值![]() ,然后计算通道维度中每个像素的概率分布的熵。然后,将不确定性较大的区域去除,获得确定的伪标签。
,然后计算通道维度中每个像素的概率分布的熵。然后,将不确定性较大的区域去除,获得确定的伪标签。


H为不确定性标签的阈值,yp是确定的伪标签。
Anchor Sampling.
使用标记图像的标签和未标记图像的确定性伪标签作为使用对比样本的基础。由于原始图像分辨率太大,原始图像大小的对比学习成本很高,并且像素的原型向量包含较少的语义信息。因此,在分辨率较低的特征空间中使用对比学习。
首先,从编码器中提取的特征将被嵌入到D维空间中,其中每个D维特征向量表示。然后,将标签下采样到相同的分辨率,为每个原型向量指定类别,并且不对不确定性区域中的向量进行采样。采用随机抽样的策略,每个类别抽固定数量。如果同一类别的样本数量较少,将对其他类别的锚进行采样。对比负样本的数量极大地影响了对比学习的性能,但大量的负样本会产生大量的开销。一个更好的解决方案是使用固定大小的外部存储器来存储采样样本,并通过训练更新存储内容。论文设置了一个内存队列来存储收集到的样本。在每次迭代中,随机选择的样本被用作锚来计算对比损失,然后它们被更新到内存队列中。
Pixel Contrastive Loss.
原型向量及其像素类别保存在样本队列中。使用流行的InfoNCE损失函数来计算对比损失。在每次迭代中,随机抽取M个锚,并计算每个锚的对比损失。然后将所有锚的损失平均为整体对比损失。具体计算如下
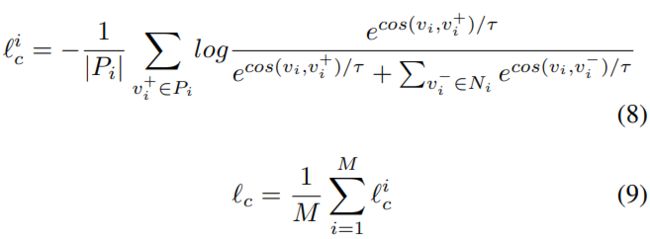
其中Pi和Ni表示像素i的正样本和负样本的原型向量集合。vi是像素i的原型向量,vi+是正原型向量,vi−是负向量,τ是温度超参数。
Equivariant Contrastive Loss
本文建议分割任务所需的有效特征表示对不同的几何变换应该是等变的(或有区别的)。
在分段模型的表示学习中添加等变对比损失,以学习全局信息。具体来说,将分割模型定义为编码器-解码器形式。对于图像xi,当它经过某种几何变换G(·)时,相应的分割结果也会发生变化,即:
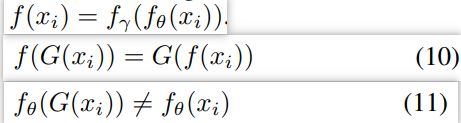
添加一个分类预测器来预测几何变换的判别结果。等比对比损失为:
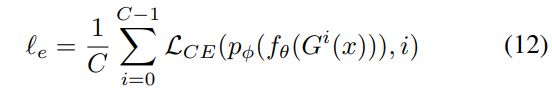
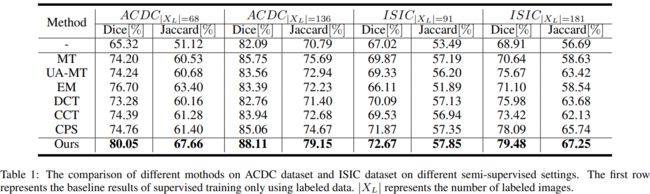
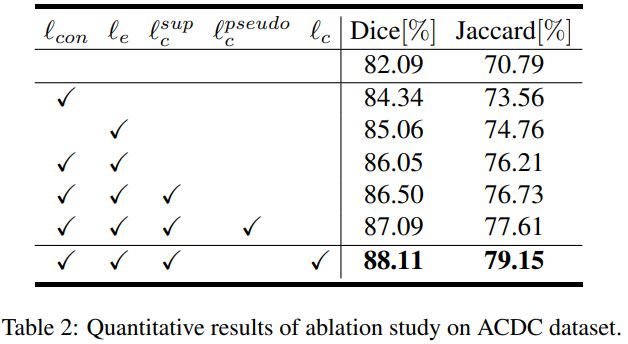
实验
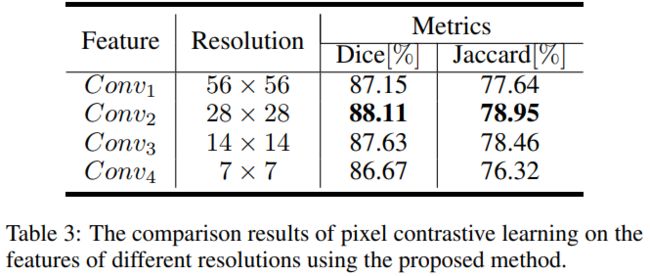
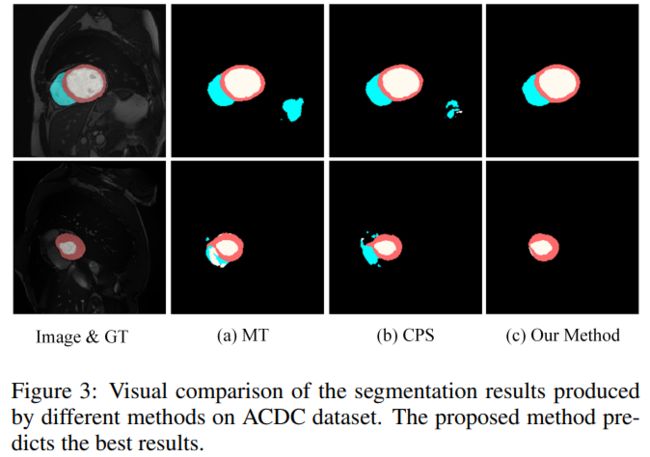

代码
ugpcl_trainer.py
# https://github.com/taovv/UGPCL/blob/master/codes/trainers/ugpcl_trainer.py
class UGPCLTrainer(BaseTrainer):
def __init__(self,
model=None,
optimizer=None,
scheduler=None,
criterions=None,
metrics=None,
logger=None,
device='cuda',
resume_from=None,
labeled_bs=8,
data_parallel=False,
ckpt_save_path=None,
max_iter=6000,
eval_interval=1000,
save_image_interval=50,
save_ckpt_interval=2000,
consistency=0.1,
consistency_rampup=40.0,
tf_decoder_weight=0.4,
cls_weight=0.1,
contrast_type='ugpcl', # ugpcl, pseudo, sup, none
contrast_weight=0.1,
temperature=0.1,
base_temperature=0.07,
max_samples=1024,
max_views=1,
memory=True,
memory_size=100,
pixel_update_freq=10,
pixel_classes=4,
dim=256) -> None:
super(UGPCLTrainer, self).__init__(model, optimizer, scheduler, criterions, metrics, logger, device,
resume_from, labeled_bs, consistency, consistency_rampup, data_parallel,
ckpt_save_path, max_iter, eval_interval, save_image_interval,
save_ckpt_interval)
self.tf_decoder_weight = tf_decoder_weight
self.cls_weight = cls_weight
self.cls_criterion = torch.nn.CrossEntropyLoss()
self.contrast_type = contrast_type
self.contrast_weight = contrast_weight
self.contrast_criterion = PixelContrastLoss(temperature=temperature,
base_temperature=base_temperature,
max_samples=max_samples,
max_views=max_views,
device=device)
# memory param
self.memory = memory
self.memory_size = memory_size
self.pixel_update_freq = pixel_update_freq
if self.memory:
self.segment_queue = torch.randn(pixel_classes, self.memory_size, dim)
self.segment_queue = nn.functional.normalize(self.segment_queue, p=2, dim=2)
self.segment_queue_ptr = torch.zeros(pixel_classes, dtype=torch.long)
self.pixel_queue = torch.zeros(pixel_classes, self.memory_size, dim)
self.pixel_queue = nn.functional.normalize(self.pixel_queue, p=2, dim=2)
self.pixel_queue_ptr = torch.zeros(pixel_classes, dtype=torch.long)
def _dequeue_and_enqueue(self, keys, labels):
batch_size = keys.shape[0]
feat_dim = keys.shape[1]
labels = torch.nn.functional.interpolate(labels, (keys.shape[2], keys.shape[3]), mode='nearest')
for bs in range(batch_size):
this_feat = keys[bs].contiguous().view(feat_dim, -1)
this_label = labels[bs].contiguous().view(-1)
this_label_ids = torch.unique(this_label)
this_label_ids = [x for x in this_label_ids if x > 0]
for lb in this_label_ids:
idxs = (this_label == lb).nonzero()
lb = int(lb.item())
# segment enqueue and dequeue
feat = torch.mean(this_feat[:, idxs], dim=1).squeeze(1)
ptr = int(self.segment_queue_ptr[lb])
self.segment_queue[lb, ptr, :] = nn.functional.normalize(feat.view(-1), p=2, dim=0)
self.segment_queue_ptr[lb] = (self.segment_queue_ptr[lb] + 1) % self.memory_size
# pixel enqueue and dequeue
num_pixel = idxs.shape[0]
perm = torch.randperm(num_pixel)
K = min(num_pixel, self.pixel_update_freq)
feat = this_feat[:, perm[:K]]
feat = torch.transpose(feat, 0, 1)
ptr = int(self.pixel_queue_ptr[lb])
if ptr + K >= self.memory_size:
self.pixel_queue[lb, -K:, :] = nn.functional.normalize(feat, p=2, dim=1)
self.pixel_queue_ptr[lb] = 0
else:
self.pixel_queue[lb, ptr:ptr + K, :] = nn.functional.normalize(feat, p=2, dim=1)
self.pixel_queue_ptr[lb] = (self.pixel_queue_ptr[lb] + 1) % self.memory_size
@staticmethod
def _random_rotate(image, label):
angle = float(torch.empty(1).uniform_(-20., 20.).item())
image = TF.rotate(image, angle)
label = TF.rotate(label, angle)
return image, label
def train_step(self, batch_data, step, save_image):
log_infos, scalars = {}, {}
images = {}
data_, label_ = batch_data['image'].to(self.device), batch_data['label'].to(self.device)
# data, label = self._random_aug(data_, label_)
if self.cls_weight >= 0.:
images_, labels_ = [], []
cls_label = []
for image, label in zip(data_, label_):
rot_times = random.randrange(0, 4)
cls_label.append(rot_times)
image = torch.rot90(image, rot_times, [1, 2])
label = torch.rot90(label, rot_times, [1, 2])
image, label = self._random_rotate(image, label)
images_.append(image)
labels_.append(label)
cls_label = torch.tensor(cls_label).to(self.device)
data = torch.stack(images_, dim=0).to(self.device)
label = torch.stack(labels_, dim=0).to(self.device)
else:
data = data_
label = label_
cls_label = None
outputs = self.model(data, self.device)
seg = outputs['seg']
seg_tf = outputs['seg_tf']
supervised_loss = 0.
for criterion in self.criterions:
loss_ = criterion(seg[:self.labeled_bs], label[:self.labeled_bs]) + \
self.tf_decoder_weight * criterion(seg_tf[:self.labeled_bs], label[:self.labeled_bs])
supervised_loss += loss_
log_infos[criterion.name] = float(format(loss_, '.5f'))
scalars[f'loss/{criterion.name}'] = loss_
loss_cls = self.cls_criterion(outputs['cls'], cls_label) if self.cls_weight > 0. else 0.
seg_soft = torch.softmax(seg, dim=1)
seg_tf_soft = torch.softmax(seg_tf, dim=1)
consistency_weight = self.get_current_consistency_weight(step // 100)
consistency_loss = torch.mean((seg_soft[self.labeled_bs:] - seg_tf_soft[self.labeled_bs:]) ** 2)
loss = supervised_loss + consistency_weight * consistency_loss + self.cls_weight * loss_cls
log_infos['loss_cls'] = float(format(loss_cls, '.5f'))
log_infos['con_weight'] = float(format(consistency_weight, '.5f'))
log_infos['loss_con'] = float(format(consistency_loss, '.5f'))
log_infos['loss'] = float(format(loss, '.5f'))
scalars['loss/loss_cls'] = loss_cls
scalars['consistency_weight'] = consistency_weight
scalars['loss/loss_consistency'] = consistency_loss
scalars['loss/total'] = loss
preds = torch.argmax(seg_soft, dim=1, keepdim=True).to(torch.float)
log_infos['loss_contrast'] = 0.
scalars['loss/contrast'] = 0.
if step > 1000 and self.contrast_weight > 0.:
# queue = torch.cat((self.segment_queue, self.pixel_queue), dim=1) if self.memory else None
queue = self.segment_queue if self.memory else None
if self.contrast_type == 'ugpcl':
seg_mean = torch.mean(torch.stack([F.softmax(seg, dim=1), F.softmax(seg_tf, dim=1)]), dim=0)
uncertainty = -1.0 * torch.sum(seg_mean * torch.log(seg_mean + 1e-6), dim=1, keepdim=True)
threshold = (0.75 + 0.25 * ramps.sigmoid_rampup(step, self.max_iter)) * np.log(2)
uncertainty_mask = (uncertainty > threshold)
mean_preds = torch.argmax(F.softmax(seg_mean, dim=1).detach(), dim=1, keepdim=True).float()
certainty_pseudo = mean_preds.clone()
certainty_pseudo[uncertainty_mask] = -1
certainty_pseudo[:self.labeled_bs] = label[:self.labeled_bs]
contrast_loss = self.contrast_criterion(outputs['embed'], certainty_pseudo, preds, queue=queue)
scalars['uncertainty_rate'] = torch.sum(uncertainty_mask == True) / \
(torch.sum(uncertainty_mask == True) + torch.sum(
uncertainty_mask == False))
if self.memory:
self._dequeue_and_enqueue(outputs['embed'].detach(), certainty_pseudo.detach())
if save_image:
grid_image = make_grid(mean_preds * 50., 4, normalize=False)
images['train/mean_preds'] = grid_image
grid_image = make_grid(certainty_pseudo * 50., 4, normalize=False)
images['train/certainty_pseudo'] = grid_image
grid_image = make_grid(uncertainty, 4, normalize=False)
images['train/uncertainty'] = grid_image
grid_image = make_grid(uncertainty_mask.float(), 4, normalize=False)
images['train/uncertainty_mask'] = grid_image
elif self.contrast_type == 'pseudo':
contrast_loss = self.contrast_criterion(outputs['embed'], preds.detach(), preds, queue=queue)
if self.memory:
self._dequeue_and_enqueue(outputs['embed'].detach(), preds.detach())
elif self.contrast_type == 'sup':
contrast_loss = self.contrast_criterion(outputs['embed'][:self.labeled_bs], label[:self.labeled_bs],
preds[:self.labeled_bs], queue=queue)
if self.memory:
self._dequeue_and_enqueue(outputs['embed'].detach()[:self.labeled_bs],
label.detach()[:self.labeled_bs])
else:
contrast_loss = 0.
loss += self.contrast_weight * contrast_loss
log_infos['loss_contrast'] = float(format(contrast_loss, '.5f'))
scalars['loss/contrast'] = contrast_loss
tf_preds = torch.argmax(seg_tf_soft, dim=1, keepdim=True).to(torch.float)
metric_res = self.metrics[0](preds, label)
for key in metric_res.keys():
log_infos[f'{self.metrics[0].name}.{key}'] = float(format(metric_res[key], '.5f'))
scalars[f'train/{self.metrics[0].name}.{key}'] = metric_res[key]
if save_image:
grid_image = make_grid(data, 4, normalize=True)
images['train/images'] = grid_image
grid_image = make_grid(preds * 50., 4, normalize=False)
images['train/preds'] = grid_image
grid_image = make_grid(tf_preds * 50., 4, normalize=False)
images['train/tf_preds'] = grid_image
grid_image = make_grid(label * 50., 4, normalize=False)
images['train/labels'] = grid_image
return loss, log_infos, scalars, images
def val_step(self, batch_data):
data, labels = batch_data['image'].to(self.device), batch_data['label'].to(self.device)
preds = self.model.inference(data)
metric_total_res = {}
for metric in self.metrics:
metric_total_res[metric.name] = metric(preds, labels)
return metric_total_res
def val_step_tf(self, batch_data):
data, labels = batch_data['image'].to(self.device), batch_data['label'].to(self.device)
preds = self.model.inference_tf(data, self.device)
metric_total_res = {}
for metric in self.metrics:
metric_total_res[metric.name] = metric(preds, labels)
return metric_total_res
@torch.no_grad()
def val_tf(self, val_loader, test=False):
self.model.eval()
val_res = None
val_scalars = {}
if self.logger is not None:
self.logger.info('Evaluating...')
if test:
val_loader = tqdm(val_loader, desc='Testing', unit='batch',
bar_format='%s{l_bar}{bar}{r_bar}%s' % (Fore.LIGHTCYAN_EX, Fore.RESET))
for batch_data in val_loader:
batch_res = self.val_step_tf(batch_data) # {'Dice':{'c1':0.1, 'c2':0.1, ...}, ...}
if val_res is None:
val_res = batch_res
else:
for metric_name in val_res.keys():
for key in val_res[metric_name].keys():
val_res[metric_name][key] += batch_res[metric_name][key]
for metric_name in val_res.keys():
for key in val_res[metric_name].keys():
val_res[metric_name][key] = val_res[metric_name][key] / len(val_loader)
val_scalars[f'val_tf/{metric_name}.{key}'] = val_res[metric_name][key]
val_res_list = [_.cpu() for _ in val_res[metric_name].values()]
val_res[metric_name]['Mean'] = np.mean(val_res_list[1:])
val_scalars[f'val_tf/{metric_name}.Mean'] = val_res[metric_name]['Mean']
val_table = PrettyTable()
val_table.field_names = ['Metirc'] + list(list(val_res.values())[0].keys())
for metric_name in val_res.keys():
if metric_name in ['Dice', 'Jaccard', 'Acc', 'IoU', 'Recall', 'Precision']:
temp = [float(format(_ * 100, '.2f')) for _ in val_res[metric_name].values()]
else:
temp = [float(format(_, '.2f')) for _ in val_res[metric_name].values()]
val_table.add_row([metric_name] + temp)
return val_res, val_scalars, val_table
def train(self, train_loader, val_loader):
# iter_train_loader = iter(train_loader)
max_epoch = self.max_iter // len(train_loader) + 1
step = self.start_step
self.model.train()
with tqdm(total=self.max_iter - self.start_step, bar_format='[{elapsed}<{remaining}] ') as pbar:
for _ in range(max_epoch):
for batch_data in train_loader:
save_image = True if (step + 1) % self.save_image_interval == 0 else False
loss, log_infos, scalars, images = self.train_step(batch_data, step, save_image)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.scheduler.step()
if (step + 1) % 10 == 0:
scalars.update({'lr': self.scheduler.get_lr()[0]})
log_infos.update({'lr': self.scheduler.get_lr()[0]})
self.logger.update_scalars(scalars, step + 1)
self.logger.info(f'[{step + 1}/{self.max_iter}] {log_infos}')
if save_image:
self.logger.update_images(images, step + 1)
if (step + 1) % self.eval_interval == 0:
if val_loader is not None:
val_res, val_scalars, val_table = self.val(val_loader)
self.logger.info(f'val result:\n{val_table.get_string()}')
self.logger.update_scalars(val_scalars, step + 1)
self.model.train()
val_res, val_scalars, val_table = self.val_tf(val_loader)
self.logger.info(f'val_tf result:\n{val_table.get_string()}')
self.logger.update_scalars(val_scalars, step + 1)
self.model.train()
if (step + 1) % self.save_ckpt_interval == 0:
if not os.path.exists(self.ckpt_save_path):
os.makedirs(self.ckpt_save_path)
self.save_ckpt(step + 1, f'{self.ckpt_save_path}/iter_{step + 1}.pth')
step += 1
pbar.update(1)
if step >= self.max_iter:
break
if step >= self.max_iter:
break
if not os.path.exists(self.ckpt_save_path):
os.makedirs(self.ckpt_save_path)
torch.save(self.model.state_dict(), f'{self.ckpt_save_path}/ckpt_final.pth')