1、GAN(Generative Adversarial Networks)论文及pytorch实现
GAN论文及pytorch实现
- 一、论文
-
- 1、Introduction
- 2、相关工作
- 3、对抗网络 Adversarial nets
- 4and5、公式推导和实验结果展示
- 6、优势和劣势
- 7、结论
- 二、代码实现
本文是学习笔记,本人目前能力有限,对此理解远远不够,还在不断学习中,如有问题欢迎指出。
一、论文
[1]Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza..Generative Adversarial Networks:Cornell University Library,2014
1、Introduction
第一段介绍了深度学习将高维的、感官上的东西映射成了低维的一个label,这些成功的映射归功于dropout、backpropagation、分段线性单元等等。但提出了当时在深度生成网络上的表现性能不佳。由此作者提出了新的方法–adversarial nets framework,对抗网络框架;判别器discriminative model学着去区别样本是生成的还是来自真实数据。
接下来作者举了个例子:Generative model生成器就像假币制造者,它的工作就是不断精进技术来制造更逼真的假币来瞒过判别器D;判别器D就像警察一样,不断在货币中区分真币和假币;两者不断博弈之中,生成器G和判别器D也不断变好,直到D无法再分辨G生成的对象。

这个框架可以用在很多实际问题中,本文中的G和D模型是多层感知机,都采用dropout、backpropagation训练。而在生成应用时只需要用G进行前向传播即可输出。

2、相关工作
介绍了当年的相关研究工作,在生成方面多多少少存在一些问题。

3、对抗网络 Adversarial nets

用随机的简单分布的noise P z ( z ) P_z(z) Pz(z) 通过train之后来学到和真实数据 x x x一样的的 P g P_g Pg,生成器 G ( z , ∂ g ) G(z,\partial g) G(z,∂g)是接受输入 z z z,调整参数 ∂ g \partial g ∂g将 z z z映射到真实的data空间;判别器 D ( X , ∂ d ) D(X,\partial d) D(X,∂d)输出一个单标量, D ( x ) D(x) D(x)是 x x x来自data的可能性,0-1之间。
定义损失函数 V ( G , D ) V(G,D) V(G,D):
m i n G m a x D V ( D , G ) = E x ∽ p d a t a [ l o g D ( x ) ] + E z ∽ p z [ l o g ( 1 − D ( G ( z ) ) ) ] min_Gmax_DV(D,G)=E_{x{\backsim}p_{data}}[logD(x)]+E_{z{\backsim}p_{z}}[log(1-D(G(z)))] minGmaxDV(D,G)=Ex∽pdata[logD(x)]+Ez∽pz[log(1−D(G(z)))]
tips: D ( G ( z ) ) D(G(z)) D(G(z))是 D ( z ) D(z) D(z)生成数据来自true data的概率,log在0-1之间是小于0的,G效果越好, D ( G ( z ) ) D(G(z)) D(G(z))越大, 1 − D ( G ( z ) ) 1-D(G(z)) 1−D(G(z))则越小,所以 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))越小。
G的目标是让损失函数V降低,D的目标是让损失函数升高。

为了解决训练早期梯度太小的问题,将training G从最小化 l o g ( 1 − D ( G ( z ) ) ) log(1−D(G(z))) log(1−D(G(z)))改为最大化 l o g D ( G ( z ) ) logD(G(z)) logD(G(z)).
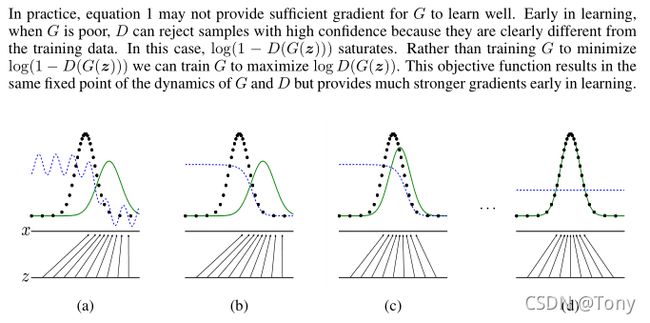
这里,z是噪声数据,从z中采样作为x,形成绿色的高耸的部分,原始数据Xdata是不变的。蓝色虚线是分类器(sigmoid),黑色虚线是原始数据,绿色实线是生成数据。最初的时候D可以很好的区分开真实数据和生成数据,看图(b),对于蓝色虚线而言,单纯的绿色部分可以很明确的划分为0,黑色虚线的部分可以很明确的划分成1,二者相交的部分划分不是很明确。看图©绿色实现生成数据更新,与原始数据相似度增加。最后一张图,经过多次更新与对抗生成之后,生成数据已经和原始数据非常相像的了,这时分类器已经无法判断到底是输出1还是0,于是就变成了0.5一条水平线。该段选自GAN入门理解及公式推导

4and5、公式推导和实验结果展示
依旧见GAN入门理解及公式推导


6、优势和劣势
缺点就在于没有显示的显示出了生成数据的分布;判别器需要大量训练,而生成器必须要在判别器训练好了的情况下训练才能效果最好;优点是只使用backprop来获取梯度,在学习过程中不需要推理,模型中可以加入各种各样的函数。

7、结论

二、代码实现
来自pytorch-MNIST-CelebA-GAN-DCGAN,感谢znxlwm的分享。
本代码是作用于MNIST数据集,生成手写数字,对原代码做了一些版本兼容性调整。
本人环境:
– python 3.7
– pytorch 1.1
– cuda 11.1
import os
import matplotlib.pyplot as plt
import itertools
import pickle
import imageio
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# G(z)
class generator(nn.Module):
# initializers
def __init__(self, input_size=32, n_class = 10):
super(generator, self).__init__()
self.fc1 = nn.Linear(input_size, 256)
self.fc2 = nn.Linear(self.fc1.out_features, 512)
self.fc3 = nn.Linear(self.fc2.out_features, 1024)
self.fc4 = nn.Linear(self.fc3.out_features, n_class)
# forward method
def forward(self, input):
x = F.leaky_relu(self.fc1(input), 0.2)
x = F.leaky_relu(self.fc2(x), 0.2)
x = F.leaky_relu(self.fc3(x), 0.2)
x = F.tanh(self.fc4(x))
x = x.squeeze(-1)
return x
class discriminator(nn.Module):
# initializers
def __init__(self, input_size=32, n_class=10):
super(discriminator, self).__init__()
self.fc1 = nn.Linear(input_size, 1024)
self.fc2 = nn.Linear(self.fc1.out_features, 512)
self.fc3 = nn.Linear(self.fc2.out_features, 256)
self.fc4 = nn.Linear(self.fc3.out_features, n_class)
# forward method
def forward(self, input):
x = F.leaky_relu(self.fc1(input), 0.2)
x = F.dropout(x, 0.3)
x = F.leaky_relu(self.fc2(x), 0.2)
x = F.dropout(x, 0.3)
x = F.leaky_relu(self.fc3(x), 0.2)
x = F.dropout(x, 0.3)
x = F.sigmoid(self.fc4(x))
x = x.squeeze(-1)
return x
fixed_z_ = torch.randn((5 * 5, 100)) # fixed noise
fixed_z_ = Variable(fixed_z_.cuda(), requires_grad= True)
def show_result(num_epoch, show = False, save = False, path = 'result.png', isFix=False):
z_ = torch.randn((5*5, 100))
z_ = Variable(z_.cuda(), requires_grad= True)
G.eval()
if isFix:
test_images = G(fixed_z_)
else:
test_images = G(z_)
G.train()
size_figure_grid = 5
fig, ax = plt.subplots(size_figure_grid, size_figure_grid, figsize=(5, 5))
for i, j in itertools.product(range(size_figure_grid), range(size_figure_grid)):
ax[i, j].get_xaxis().set_visible(False)
ax[i, j].get_yaxis().set_visible(False)
for k in range(5*5):
i = k // 5
j = k % 5
ax[i, j].cla()
ax[i, j].imshow(test_images[k, :].cpu().data.view(28, 28).numpy(), cmap='gray')
label = 'Epoch {0}'.format(num_epoch)
fig.text(0.5, 0.04, label, ha='center')
plt.savefig(path)
if show:
plt.show()
else:
plt.close()
def show_train_hist(hist, show = False, save = False, path = 'Train_hist.png'):
x = range(len(hist['D_losses']))
y1 = hist['D_losses']
y2 = hist['G_losses']
plt.plot(x, y1, label='D_loss')
plt.plot(x, y2, label='G_loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc=4)
plt.grid(True)
plt.tight_layout()
if save:
plt.savefig(path)
if show:
plt.show()
else:
plt.close()
# training parameters
batch_size = 128
lr = 0.0002
train_epoch = 100
# data_loader
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5],[0.5])
])
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True, transform=transform),
batch_size=batch_size, shuffle=True)
# network
G = generator(input_size=100, n_class=28*28)
D = discriminator(input_size=28*28, n_class=1)
G.cuda()
D.cuda()
# Binary Cross Entropy loss
BCE_loss = nn.BCELoss()
# Adam optimizer
G_optimizer = optim.Adam(G.parameters(), lr=lr)
D_optimizer = optim.Adam(D.parameters(), lr=lr)
# results save folder
if not os.path.isdir('MNIST_GAN_results'):
os.mkdir('MNIST_GAN_results')
if not os.path.isdir('MNIST_GAN_results/Random_results'):
os.mkdir('MNIST_GAN_results/Random_results')
if not os.path.isdir('MNIST_GAN_results/Fixed_results'):
os.mkdir('MNIST_GAN_results/Fixed_results')
train_hist = {}
train_hist['D_losses'] = []
train_hist['G_losses'] = []
for epoch in range(train_epoch):
D_losses = []
G_losses = []
for x_, _ in train_loader:
# train discriminator D
D.zero_grad()
x_ = x_.view(-1, 28 * 28)
mini_batch = x_.size()[0]
y_real_ = torch.ones(mini_batch)
y_fake_ = torch.zeros(mini_batch)
x_, y_real_, y_fake_ = Variable(x_.cuda()), Variable(y_real_.cuda()), Variable(y_fake_.cuda())
D_result = D(x_)
D_real_loss = BCE_loss(D_result, y_real_)
D_real_score = D_result
z_ = torch.randn((mini_batch, 100))
z_ = Variable(z_.cuda())
G_result = G(z_)
D_result = D(G_result)
D_fake_loss = BCE_loss(D_result, y_fake_)
D_fake_score = D_result
D_train_loss = D_real_loss + D_fake_loss
D_train_loss.backward()
D_optimizer.step()
D_losses.append(D_train_loss.item())
# train generator G
G.zero_grad()
z_ = torch.randn((mini_batch, 100))
y_ = torch.ones(mini_batch)
z_, y_ = Variable(z_.cuda()), Variable(y_.cuda())
G_result = G(z_)
D_result = D(G_result)
G_train_loss = BCE_loss(D_result, y_)
G_train_loss.backward()
G_optimizer.step()
G_losses.append(G_train_loss.item())
print('[%d/%d]: loss_d: %.3f, loss_g: %.3f' % (
(epoch + 1), train_epoch, torch.mean(torch.FloatTensor(D_losses)), torch.mean(torch.FloatTensor(G_losses))))
p = 'MNIST_GAN_results/Random_results/MNIST_GAN_' + str(epoch + 1) + '.png'
fixed_p = 'MNIST_GAN_results/Fixed_results/MNIST_GAN_' + str(epoch + 1) + '.png'
show_result((epoch+1), save=True, path=p, isFix=False)
show_result((epoch+1), save=True, path=fixed_p, isFix=True)
train_hist['D_losses'].append(torch.mean(torch.FloatTensor(D_losses)))
train_hist['G_losses'].append(torch.mean(torch.FloatTensor(G_losses)))
print("Training finish!... save training results")
torch.save(G.state_dict(), "MNIST_GAN_results/generator_param.pkl")
torch.save(D.state_dict(), "MNIST_GAN_results/discriminator_param.pkl")
with open('MNIST_GAN_results/train_hist.pkl', 'wb') as f:
pickle.dump(train_hist, f)
show_train_hist(train_hist, save=True, path='MNIST_GAN_results/MNIST_GAN_train_hist.png')
images = []
for e in range(train_epoch):
img_name = 'MNIST_GAN_results/Fixed_results/MNIST_GAN_' + str(e + 1) + '.png'
images.append(imageio.imread(img_name))
imageio.mimsave('MNIST_GAN_results/generation_animation.gif', images, fps=5)
生成效果如下:
epoch1:

epoch10:

epoch50:

epoch100:

训练中生成器和判别器的损失情况:
