Hash表
Hash表
- 前言
- 存储结构
-
- 链表法
-
- 初始哈希表
- 大致的思路
- 代码讲解及实现
-
- 声明
- 插入
- 寻找
- 主函数
- 开放寻址法
-
- 大致的思路
- 代码讲解及实现
-
- 声明
- find
- 主函数
- 实际运用
-
- 字符串前缀哈希法
-
- 大致思路
- 代码实现
前言
hello! 这里是欧_aita的博客。
每日一汤:不管你做什么,都要全心全意地投入其中。这是取得成功的秘诀。
我的主页:欧_aita
欢迎大家关注我的专栏:
数据结构与算法
MySQL数据库

存储结构
链表法
初始哈希表
哈希表(Hash Table)是一种数据结构,它使用哈希函数来将键映射到数组的特定位置,从而实现快速的数据检索。哈希表通常是通过数组实现的,这个数组的每个位置被称为桶(bucket),而哈希函数将键映射到特定的桶。
哈希表的基本思想是通过哈希函数将键转换为数组的索引,使得可以直接访问数组中的特定位置以获取或存储数据。这样,查找、插入和删除的平均时间复杂度都可以达到常数级别(O(1))
大致的思路

在初始的h数组中(槽)下以链表形式存储数据。
代码讲解及实现
声明
h[N]就是上文提起的槽,而e[],ne[],idx都是为了使用数组模拟链表。
#include 插入
这里的k向N取模后再加N是为了得到一个非负数,在槽中,下标没有负数,在C++语法中负数取模后得到的还是负数。
void insert(int x)
{
int k = (x % N + N) % N;
e[idx] = k,ne[idx] = h[k],h[k] = idx++;
}
寻找
bool find(int x)
{
int k = (x % N + N) % N;
for(int i = h[k];i != -1;i++)
if(e[i]==x)
return true;
return false;
}
主函数
使用scanf()可以忽略回车符,制表符,空格,不容易出现其他错误。
int main()
{
int n;
cin >> n;
memset(h,-1,sizeof h);
while(n--)
{
char op[2];
int x;
scanf("%s%d",op,&x);
if(*op == 'I')insert(x);
else
{
if(find(x))puts("Yes");
else puts("No");
}
}
return 0;
}
开放寻址法
大致的思路
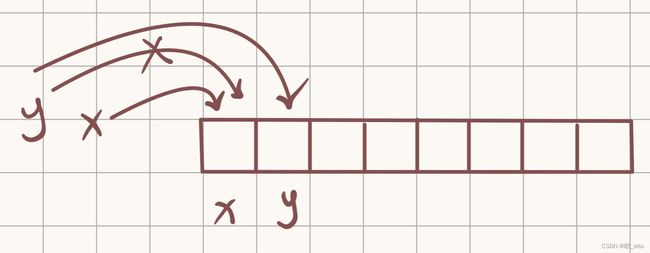
开放寻址法就是在寻找空的槽位,当y这个数据元素在寻找槽位时发现第一个槽位已满,此时发生冲突,y就会寻找下一个空槽位。
这也暴露出了开放寻址法有一个弊端,当哈希表变得拥挤,插入操作就会降低效率。
代码讲解及实现
声明
这里的0*3f3f3f3f是指无穷大的意思,大致是10^9。
不难发现此时的N相较于链表法多了一倍,解释如下:
在开放寻址法中,选择 N 取得较大的原因可能是为了避免过早的冲突。如果哈希表的大小较小,那么在插入一些元素后,就可能很快发生冲突,导致性能下降。通过选择较大的 N,可以减少冲突的可能性,延迟哈希表填满槽位的时间。
对于链表法,由于每个槽可以存储多个元素,相对较小的 N 也可能足够处理大量的元素。链表法的优势在于能够处理高度冲突的情况,而且不需要像开放寻址法那样在数组中线性搜索。
#include find
若k==N即表示已经遍历到了槽的末端,此时将k赋值为0,从头开始。
int find(int x)
{
int k = (x % N + N) % N;
while (h[k] != null && h[k] != x)
{
k++;
if (k == N)k = 0;
}
return k;
}
主函数
这里与链表法有略微的不同,就是在插入部分。
0x3f代表0。
int main()
{
int n;
scanf("%d", &n);
//清空槽
memset(h, 0x3f, sizeof h);
while (n--)
{
char op[2];
//scanf可以自动忽略空格、回车、制表符,可以提高代码的准确率
int x;
scanf("%s%d",op,&x);
int k = find(x);
if (*op == 'I')
{
h[k] = x;
}
else
{
if (h[k]!=null)puts("Yes");
else puts("No");
}
}
return 0;
}

实际运用
字符串前缀哈希法
使用Hash表判断两段字符串是否相同
大致思路

使用前缀和的哈希值判断这串字符串是否相等。
代码实现
#include p[i] = p[i - 1] * P;:这一行代码计算了 P 的第 i 次幂,将结果存储在 p[i] 中。这是为了在后续计算哈希值时使用,引入了不同位置上的权值。
h[i] = h[i - 1] * P + str[i];:这一行代码计算了字符串 str 的前缀哈希值,存储在 h[i] 中。每次循环,它计算了字符串的前 i 个字符的哈希值,其中 h[i - 1] 是前 i-1 个字符的哈希值,P 是前面计算的幂次方,str[i] 是当前字符的 ASCII 码值
这篇文章就到此结束了,如果对你有所帮助就点个赞吧。