【算法系列篇】递归、搜索与回溯(一)

文章目录
- 什么是递归、搜索与回溯算法
- 1. 汉诺塔
-
- 1.1 题目要求
- 1.2 做题思路
- 1.3 代码实现
- 2. 合并两个有序链表
-
- 2.1 题目要求
- 2.2 做题思路
- 2.3 代码实现
- 3. 反转链表
-
- 3.2 题目要求
- 3.2 做题思路
- 3.3 代码实现
什么是递归、搜索与回溯算法
递归算法是一种通过重复将问题分解为同类的子问题而解决问题的方法。递归式方法可以被用于解决很多的计算机科学问题,因此它是计算机科学中十分重要的一个概念。绝大多数编程语言支持函数的自调用,在这些语言中函数可以通过调用自身来进行递归。
搜索算法是利用计算机的高性能来有目的地穷举一个问题解空间的部分或所有的可能情况,从而求出问题的解的一种方法。主要包括枚举算法、深度优先搜索、广度优先搜索、A*算法、回溯算法、蒙特卡洛树搜索和散列函数等算法。
回溯算法实际上是一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
那么,为什么会将这三个算法放在一起呢?其实搜索算法和回溯算法本质上都是递归算法,只是搜索决定了递归的方式,而回溯则是在递归搜索的时候,在函数返回值的时候将改变的量给还原回来。
在本系列算法中,我将为大家一步一步、一个阶段一个阶段的为大家分享涉及到相关知识的题目。
1. 汉诺塔
https://leetcode.cn/problems/hanota-lcci/
1.1 题目要求
在经典汉诺塔问题中,有 3 根柱子及 N 个不同大小的穿孔圆盘,盘子可以滑入任意一根柱子。一开始,所有盘子自上而下按升序依次套在第一根柱子上(即每一个盘子只能放在更大的盘子上面)。移动圆盘时受到以下限制:
(1) 每次只能移动一个盘子;
(2) 盘子只能从柱子顶端滑出移到下一根柱子;
(3) 盘子只能叠在比它大的盘子上。
请编写程序,用栈将所有盘子从第一根柱子移到最后一根柱子。
你需要原地修改栈。
示例1:
输入:A = [2, 1, 0], B = [], C = []
输出:C = [2, 1, 0]
示例2:
输入:A = [1, 0], B = [], C = []
输出:C = [1, 0]
提示:
A中盘子的数目不大于14个。
class Solution {
public void hanota(List<Integer> A, List<Integer> B, List<Integer> C) {
}
}
1.2 做题思路
这是⼀道递归⽅法的经典题⽬,我们可以先从最简单的情况考虑:
- 假设 n = 1,只有⼀个盘⼦,很简单,直接把它从 A 中拿出来,移到 C 上;
- 如果 n = 2 呢?这时候我们就要借助 B 了,因为⼩盘⼦必须时刻都在⼤盘⼦上⾯,共需要 3 步(为
了⽅便叙述,记 A 中的盘⼦从上到下为 1 号,2 号):
a. 1 号盘⼦放到 B 上;
b. 2 号盘⼦放到 C 上;
c. 1 号盘⼦放到 C 上。
⾄此,C 中的盘⼦从上到下为 1 号,2 号 - 如果 n > 2 呢?这是我们需要⽤到 n = 2 时的策略,将 A 上⾯的两个盘⼦挪到 B 上,再将最⼤的盘
⼦挪到 C 上,最后将 B 上的⼩盘⼦挪到 C 上就完成了所有步骤。例如 n = 3 时如下图

然后再假设我们要将 4 个圆盘从 A 柱上借助 B 柱给移动到 C 柱上。
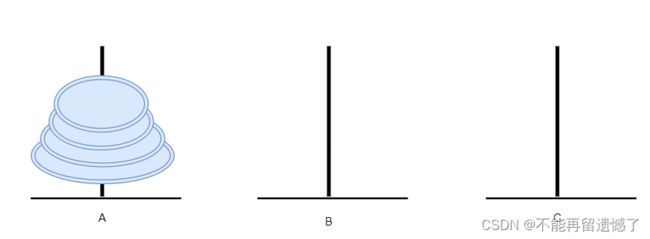
先将上面的三个盘子从 A 柱借助 C 柱移动到 B 柱。


然后将 A 柱剩下的那个最大的盘子移动到 C 柱之后,再将 B 柱上的 3 个盘子通过 A 柱移动到 C 柱上。

汉诺塔的规则是一次只能移动一个盘子并且需要保证较小的盘子在较大盘子的上面。那么要想将这 4 个盘子从 A 柱上借助 B 柱移动到 C 柱的话,首先就需要想办法将 A 柱上的 3 个盘子给移动到 B 柱上,然后将剩下的最大的盘子移动到 C 柱上,然后再将 B 柱上的 3 个盘子借助 A 柱移动到 C 柱上,最终就能达到我们的目标。而将 3 个盘子从 A 柱借助 B 柱移动到 C 柱就可以借助最上面的那个例子实现。
我们只看上面三个盘子的起点和终点就可以发现这三个盘子是从 A 柱借助 B 柱移动到 C 柱上,跟上面 3 个盘子的情况是一样的。当盘子为 5 个的时候,也是先将上面的 4 个盘子借助 C 柱移动到 B 柱,然后将剩下的一个盘子移动到 C 柱,最后再将 B 柱上的 4 个盘子借助 A 柱给移动到 C 柱上。上面 4 个盘子的移动路径也是
A柱 -> C柱,符合将大事化小的思想,所以我们就可以将汉诺塔的问题看成是一个递归。
并且通过上面的例子,我们可以总结出:当 A 柱只有一个盘子的时候,可以直接将这个盘子从 A 柱移动到 C 柱上,其他情况则遵循下面的步骤。
- 将 n-1 个盘子从 A 柱借助 C 柱移动到 B 柱。
- 将 A 柱上剩余的 1 个盘子直接移动到 C 柱
- 将 B 柱上的 n-1 个盘子借助 A 柱移动到 C 柱
那么知道了思路是什么,那么代码该怎么写呢?递归代码该如何写才不会出现栈溢出/死递归的问题呢?
其实我们要有这样的一种思想:以宏观的角度来解决微观问题,这是什么意思呢?就是当我想要将 n-1 个盘子从 A 柱借助 C 柱移动到 B 柱的时候,我们只需要将这件事交给函数,并且相信这个函数一定能够帮助我们解决这个问题。
1.3 代码实现
class Solution {
public void hanota(List<Integer> A, List<Integer> B, List<Integer> C) {
dfs(A, B, C, A.size()); //将n个盘子从A柱借助B柱移动到C柱
}
private void dfs(List<Integer> A, List<Integer> B, List<Integer> C, int n) {
//当A柱上只有一个盘子的时候,则只需要将这个盘子移动到C柱上
if (n == 1) {
C.add(A.remove(A.size() - 1));
return;
}
dfs(A, C, B, n - 1); //将n-1个盘子从A柱上借助C柱移动到B柱
C.add(A.remove(A.size() - 1)); //将A柱剩下的那个盘子移动到C柱
dfs(B, A, C, n - 1); //将B柱上的n-1个盘子借助A柱移动到C柱
}
}

如果大家对这个代码有疑问的话,大家可以详细的画出这个代码的递归函数过程。
其实想要做好递归的题目,关键就在于我们能够总结出规律,只要发现这个提供通过一个函数就可以解决,那么基本就可以做出这个决定:使用递归来解决,并且在做递归类的题目的时候,我建议大家不要去细究它是如何递归的,我们只需要相信这个函数一定能帮助我们解决问题就可以了。
2. 合并两个有序链表
https://leetcode.cn/problems/merge-two-sorted-lists/
2.1 题目要求
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
两个链表的节点数目范围是 [0, 50]
-100 <= Node.val <= 100
l1 和 l2 均按 非递减顺序 排列
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
}
}
2.2 做题思路
这道题目,相比大家之前肯定做过了吧,之前的做法就是用两个指针分别遍历这两个链表,一开始两个指针 cur1 和 cur2 都指向链表的头结点,如果 cur1 指向的节点的值小于 cur2 指针指向的节点的值,那么就将 cur1 节点的下一个节点指向 cur2 ,然后 cur2 向后移动一位,一次操作就能达到合并两个有序链表的操作了。
那么为什么在写递归算法的时候,还会将这个题目给搬出来呢?这是因为这道题目同样可以使用递归的方式来解决,为什么这么说呢?合并链表的操作也是跟上面的思路相同,比较两个指针指向的节点的大小,然后根据这两个节点的大小来讲这两个节点进行排序,也就是说两个节点排序可以使用同一个函数来实现,并且合并两个整个链表,实际上也是这两个链表中的两个节点在比较。这就适合递归将大事化小,可以使用同一个函数解决的思路。
那么,如何使用递归解决这个问题呢?在一个函数中我们只解决两个节点的比较,如果 cur1 指针指向的节点的值小于 cur2 指向的节点的值的话,那就需要 cur2 指向的节点与 cur1.next 之后的节点进行比较,并且将比较的结果给接到 cur1 节点的后面。


2.3 代码实现
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
//当l1链表或者l2链表为空的时候可以直接返回
if (l1 == null) return l2;
if (l2 == null) return l1;
if (l1.val < l2.val) {
l1.next = mergeTwoLists(l1.next, l2);
return l1;
}else {
l2.next = mergeTwoLists(l1, l2.next);
return l2;
}
}
}

3. 反转链表
https://leetcode.cn/problems/reverse-linked-list/
3.2 题目要求
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:

输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:

输入:head = [1,2]
输出:[2,1]
示例 3:
输入:head = []
输出:[]
提示:
链表中节点的数目范围是 [0, 5000]
-5000 <= Node.val <= 5000
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
}
}
3.2 做题思路
反转整个链表其实还是两两节点进行反转,并且反转的过程是一样的,所以就可以使用我们的递归来解决这个问题。
看到这个题目我们可以想到的方法就是从链表的第一个节点开始,将该节点的指向指向前一个节点,那么就可以将这个链表分为两个部分,一个就是第一个节点,另一部分就是后n-1个节点,我们先将后面n-1个节点进行反转,然后将反转的链表的头结点返回,最后在将这个第一个节点接在反转后的链表的尾部,就得到了最终的反转链表。


3.3 代码实现
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
if (head == null || head.next == null) return head;
ListNode newHead = reverseList(head.next); //先反转后面n-1个节点
//将head节点加在后面n-1个节点反转后的链表的后面
head.next.next = head;
head.next = null;
return newHead;
}
}
