基于改进OpenPose的舞蹈动作规范度评判系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
舞蹈作为一种艺术形式,具有独特的美感和表现力。舞蹈动作的规范度评判是舞蹈教学和表演中的重要环节,对于提高舞蹈水平、培养舞蹈人才具有重要意义。然而,传统的舞蹈动作规范度评判主要依赖于人工评判,存在主观性强、评判标准不一致等问题。因此,基于改进OpenPose的舞蹈动作规范度评判系统的研究具有重要的实际意义和应用价值。
首先,基于改进OpenPose的舞蹈动作规范度评判系统可以提高评判的客观性和准确性。传统的舞蹈动作评判主要依赖于人工评判,评判标准容易受到主观因素的影响,导致评判结果不一致。而基于改进OpenPose的系统可以通过计算机视觉技术对舞蹈动作进行自动识别和分析,减少了人为因素的干扰,提高了评判的客观性和准确性。
其次,基于改进OpenPose的舞蹈动作规范度评判系统可以提高舞蹈教学的效果。传统的舞蹈教学主要依赖于教师的示范和学生的模仿,存在教学效果难以量化、学生难以准确理解和掌握舞蹈动作等问题。而基于改进OpenPose的系统可以对学生的舞蹈动作进行实时监测和评估,及时发现和纠正错误动作,帮助学生更好地理解和掌握舞蹈动作,提高舞蹈教学的效果。
此外,基于改进OpenPose的舞蹈动作规范度评判系统还可以为舞蹈表演提供技术支持。舞蹈表演需要舞者具备高度的技术水平和艺术表现力,而舞者自身对于自己的舞蹈动作难以全面评估。基于改进OpenPose的系统可以对舞者的舞蹈动作进行全面的评估和分析,帮助舞者发现和改进自己的不足之处,提高舞蹈表演的质量和水平。
综上所述,基于改进OpenPose的舞蹈动作规范度评判系统的研究具有重要的实际意义和应用价值。它可以提高评判的客观性和准确性,提高舞蹈教学的效果,为舞蹈表演提供技术支持。通过研究和开发这样的系统,可以推动舞蹈教学和表演的发展,促进舞蹈艺术的传承和创新。
2.图片演示

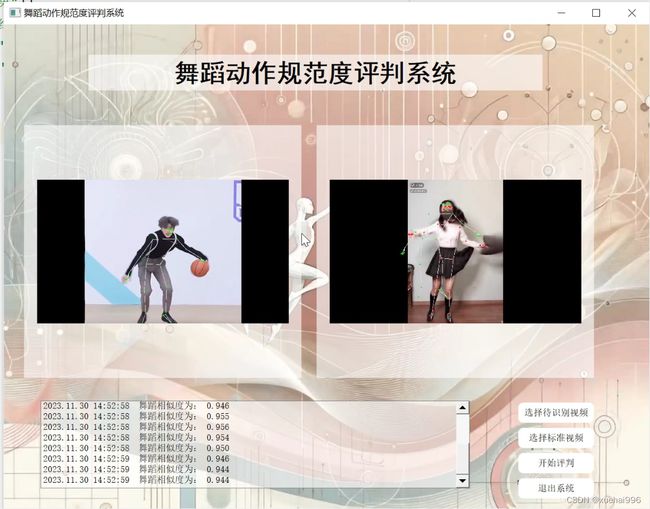
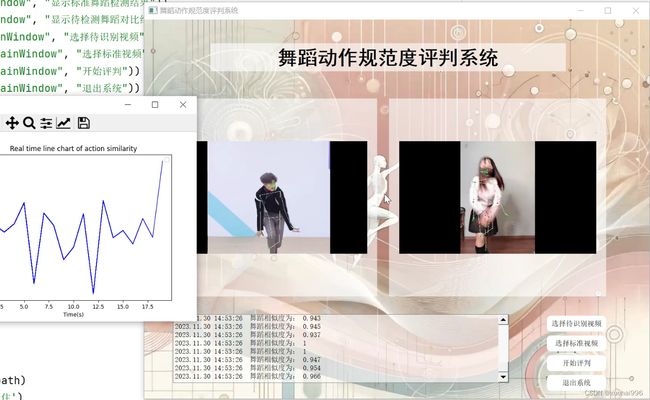
3.视频演示
基于改进OpenPose的舞蹈动作规范度评判系统_哔哩哔哩_bilibili
4.OpenPose简介
OpenPose 人体姿态识别项目由美国的卡耐基梅隆大学(CMU)的人工智能算法团队CAOP等人提出。此算法结合CPM和 PAFs算法实现对人体姿态的识别,包括面部表情、身体动作、手指变化等行为估计。该算法具有非常好的鲁棒性,具有非常广阔的应用前景。
传统的人体姿态识别方法大都采用自顶向下的检测方法,而OpenPose采用自底向上的检测方法,适合多人场景。依靠内部卷积神经网络,其可
以在复杂场景下,买现对人1个E沛面恍取。相比于传统方法,OpenPose的方法具有速度快、
准确率高的特点,满足工业场景的需要。
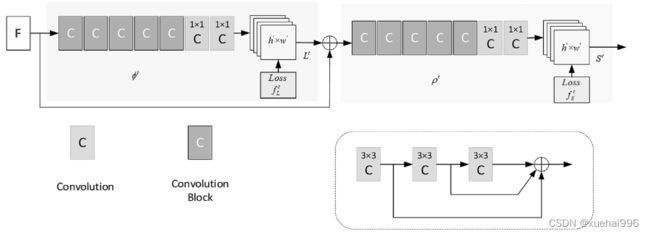
OpenPose算法的网络结构可以分为两部分,
然后作为输入进入到双分支stage模块。该模块内部串行,相互间的结构和功能一样。上支线branch
生成关节点热度置信度图S’( Part Confidence Map,PCM ),下支线branch 用来预测部分亲和度L(PartAffinity Fields,PAF) 。
5.核心代码讲解
5.1 location.py
根据给定的代码,可以将其封装为一个名为 VideoProcessor 的类。以下是封装后的代码:
from moviepy.editor import *
class VideoProcessor:
def __init__(self, video_path):
self.video = VideoFileClip(video_path)
def get_resolution(self):
return self.video.size
def get_duration(self):
return self.video.duration
def speed_up(self, factor):
self.video = self.video.speedx(factor)
def save_video(self, output_path):
self.video.write_videofile(output_path)
这样,你可以通过实例化 VideoProcessor 类来处理视频文件,获取分辨率、时长,加速视频,并保存处理后的视频。
这个程序文件名为location.py,主要功能是使用moviepy库对视频文件进行处理。以下是对代码的概述:
- 导入moviepy库中的所有模块。
- 创建一个VideoFileClip对象,参数为"./1.mp4",即当前目录下的1.mp4视频文件。
- 打印video对象的所有属性和方法,使用dir()函数获取。
- 打印video对象的size属性,即视频的分辨率。
- 打印video对象的duration属性,即视频的总时长。
- 创建一个新的video2对象,通过video对象的speedx()方法将视频加速2倍。
- 将video2对象写入一个新的视频文件"./3.mp4"中。
5.2 ui.py
class PoseEstimation:
def __init__(self, checkpoint_path, height_size=256, cpu=False, track=1, smooth=1):
self.net = PoseEstimationWithMobileNet()
self.net = load_state(self.net, checkpoint_path)
self.height_size = height_size
self.cpu = cpu
self.track = track
self.smooth = smooth
def infer_fast(self, img, net_input_height_size, stride, upsample_ratio, cpu,
pad_value=(0, 0, 0), img_mean=np.array([128, 128, 128], np.float32), img_scale=np.float32(1/256)):
height, width, _ = img.shape
scale = net_input_height_size / height
scaled_img = cv2.resize(img, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR)
scaled_img = normalize(scaled_img, img_mean, img_scale)
min_dims = [net_input_height_size, max(scaled_img.shape[1], net_input_height_size)]
padded_img, pad = pad_width(scaled_img, stride, pad_value, min_dims)
tensor_img = torch.from_numpy(padded_img).permute(2, 0, 1).unsqueeze(0).float()
if not cpu:
tensor_img = tensor_img.cuda()
stages_output = self.net(tensor_img)
stage2_heatmaps = stages_output[-2]
heatmaps = np.transpose(stage2_heatmaps.squeeze().cpu().data.numpy(), (1, 2, 0))
heatmaps = cv2.resize(heatmaps, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
stage2_pafs = stages_output[-1]
pafs = np.transpose(stage2_pafs.squeeze().cpu().data.numpy(), (1, 2, 0))
pafs = cv2.resize(pafs, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
return heatmaps, pafs, scale, pad
def run_demo(self, image_provider):
self.net = self.net.eval()
if not self.cpu:
self.net = self.net.cuda()
stride = 8
upsample_ratio = 4
num_keypoints = Pose.num_kpts
previous_poses = []
delay = 1
for img in image_provider:
orig_img = img.copy()
heatmaps, pafs, scale, pad = self.infer_fast(img, self.height_size, stride, upsample_ratio, self.cpu)
total_keypoints_num = 0
all_keypoints_by_type = []
for kpt_idx in range(num_keypoints): # 19th for bg
total_keypoints_num += extract_keypoints(heatmaps[:, :, kpt_idx], all_keypoints_by_type, total_keypoints_num)
pose_entries, all_keypoints = group_keypoints(all_keypoints_by_type, pafs)
for kpt_id in range(all_keypoints.shape[0]):
all_keypoints[kpt_id, 0] = (all_keypoints[kpt_id, 0] * stride / upsample_ratio - pad[1]) / scale
all_keypoints[kpt_id, 1] = (all_keypoints[kpt_id, 1] * stride / upsample_ratio - pad[0]) / scale
current_poses = []
for n in range(len(pose_entries)):
if len(pose_entries[n]) == 0:
continue
pose_keypoints = np.ones((num_keypoints, 2), dtype=np.int32) * -1
for kpt_id in range(num_keypoints):
if pose_entries[n][kpt_id] != -1.0: # keypoint was found
pose_keypoints[kpt_id, 0] = int(all_keypoints[int(pose_entries[n][kpt_id]), 0])
pose_keypoints[kpt_id, 1] = int(all_keypoints[int(pose_entries[n][kpt_id]), 1])
pose = Pose(pose_keypoints, pose_entries[n][18])
current_poses.append(pose)
if self.track:
track_poses(previous_poses, current_poses, smooth=self.smooth)
previous_poses = current_poses
for pose in current_poses:
pose.draw(img)
img = cv2.addWeighted(orig_img, 0.6, img, 0.4, 0)
for pose in current_poses:
cv2.rectangle(img, (pose.bbox[0], pose.bbox[1]),
(pose.bbox[0] + pose.bbox[2], pose.bbox[1] + pose.bbox[3]), (0, 255, 0))
if self.track:
cv2.putText(img, 'id: {}'.format(pose.id), (pose.bbox[0], pose.bbox[1] - 16),
cv2.FONT_HERSHEY_COMPLEX, 0.5, (0, 0, 255))
cv2.imshow('Lightweight Human Pose Estimation Python Demo', img)
key = cv2.waitKey(delay)
if key == 27: # esc
return
elif key == 112: # 'p'
if delay == 1:
delay = 0
else:
delay = 1
这个程序文件是一个使用OpenPose模型进行人体姿势估计的Demo。它包含了以下功能:
- 引入了一些必要的库,如argparse、cv2、numpy、torch等。
- 定义了一些辅助函数和类,如ImageReader用于读取图片,VideoReader用于读取视频,infer_fast用于进行轻量化预测,run_demo用于运行Demo。
- 提供了一个CMD接口,可以通过命令行参数来指定模型路径、输入图像或视频等。
- 加载了OpenPose模型,并使用它对静态图像进行姿势估计。
- 在图像上绘制了检测到的关键点和姿势框,并显示在窗口中。
这个程序文件的主要功能是使用OpenPose模型对图像或视频中的人体进行姿势估计,并将结果可视化显示出来。
5.3 val.py
class PoseEstimation:
def __init__(self, labels, images_folder, checkpoint_path):
self.labels = labels
self.images_folder = images_folder
self.checkpoint_path = checkpoint_path
def run_coco_eval(self, gt_file_path, dt_file_path):
annotation_type = 'keypoints'
print('Running test for {} results.'.format(annotation_type))
coco_gt = COCO(gt_file_path)
coco_dt = coco_gt.loadRes(dt_file_path)
result = COCOeval(coco_gt, coco_dt, annotation_type)
result.evaluate()
result.accumulate()
result.summarize()
def normalize(self, img, img_mean, img_scale):
img = np.array(img, dtype=np.float32)
img = (img - img_mean) * img_scale
return img
def pad_width(self, img, stride, pad_value, min_dims):
h, w, _ = img.shape
h = min(min_dims[0], h)
min_dims[0] = math.ceil(min_dims[0] / float(stride)) * stride
min_dims[1] = max(min_dims[1], w)
min_dims[1] = math.ceil(min_dims[1] / float(stride)) * stride
pad = []
pad.append(int(math.floor((min_dims[0] - h) / 2.0)))
pad.append(int(math.floor((min_dims[1] - w) / 2.0)))
pad.append(int(min_dims[0] - h - pad[0]))
pad.append(int(min_dims[1] - w - pad[1]))
padded_img = cv2.copyMakeBorder(img, pad[0], pad[2], pad[1], pad[3],
cv2.BORDER_CONSTANT, value=pad_value)
return padded_img, pad
def convert_to_coco_format(self, pose_entries, all_keypoints):
coco_keypoints = []
scores = []
for n in range(len(pose_entries)):
if len(pose_entries[n]) == 0:
continue
keypoints = [0] * 17 * 3
to_coco_map = [0, -1, 6, 8, 10, 5, 7, 9, 12, 14, 16, 11, 13, 15, 2, 1, 4, 3]
person_score = pose_entries[n][-2]
position_id = -1
for keypoint_id in pose_entries[n][:-2]:
position_id += 1
if position_id == 1: # no 'neck' in COCO
continue
cx, cy, score, visibility = 0, 0, 0, 0 # keypoint not found
if keypoint_id != -1:
cx, cy, score = all_keypoints[int(keypoint_id), 0:3]
cx = cx + 0.5
cy = cy + 0.5
visibility = 1
keypoints[to_coco_map[position_id] * 3 + 0] = cx
keypoints[to_coco_map[position_id] * 3 + 1] = cy
keypoints[to_coco_map[position_id] * 3 + 2] = visibility
coco_keypoints.append(keypoints)
scores.append(person_score * max(0, (pose_entries[n][-1] - 1))) # -1 for 'neck'
return coco_keypoints, scores
def infer(self, net, img, scales, base_height, stride, pad_value=(0, 0, 0), img_mean=(128, 128, 128), img_scale=1/256):
normed_img = self.normalize(img, img_mean, img_scale)
height, width, _ = normed_img.shape
scales_ratios = [scale * base_height / float(height) for scale in scales]
avg_heatmaps = np.zeros((height, width, 19), dtype=np.float32)
avg_pafs = np.zeros((height, width, 38), dtype=np.float32)
for ratio in scales_ratios:
scaled_img = cv2.resize(normed_img, (0, 0), fx=ratio, fy=ratio, interpolation=cv2.INTER_CUBIC)
min_dims = [base_height, max(scaled_img.shape[1], base_height)]
padded_img, pad = self.pad_width(scaled_img, stride, pad_value, min_dims)
tensor_img = torch.from_numpy(padded_img).permute(2, 0, 1).unsqueeze(0).float().cuda()
stages_output = net(tensor_img)
stage2_heatmaps = stages_output[-2]
heatmaps = np.transpose(stage2_heatmaps.squeeze().cpu().data.numpy(), (1, 2, 0))
heatmaps = cv2.resize(heatmaps, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC)
heatmaps = heatmaps[pad[0]:heatmaps.shape[0] - pad[2], pad[1]:heatmaps.shape[1] - pad[3]:, :]
heatmaps = cv2.resize(heatmaps, (width, height), interpolation=cv2.INTER_CUBIC)
avg_heatmaps = avg_heatmaps + heatmaps / len(scales_ratios)
stage2_pafs = stages_output[-1]
pafs = np.transpose(stage2_pafs.squeeze().cpu().data.numpy(), (1, 2, 0))
pafs = cv2.resize(pafs, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC)
pafs = pafs[pad[0]:pafs.shape[0] - pad[2], pad[1]:pafs.shape[1] - pad[3], :]
pafs = cv2.resize(pafs, (width, height), interpolation=cv2.INTER_CUBIC)
avg_pafs = avg_pafs + pafs / len(scales_ratios)
return avg_heatmaps, avg_pafs
def evaluate(self, output_name, net, multiscale=False, visualize=False):
net = net.cuda().eval()
base_height = 368
scales = [1]
if multiscale:
scales = [0.5, 1.0, 1.5, 2.0]
stride = 8
dataset = CocoValDataset(self.labels, self.images_folder)
coco_result = []
for sample in dataset:
file_name = sample['file_name']
img = sample['img']
avg_heatmaps, avg_pafs = self.infer(net, img, scales, base_height, stride)
total_keypoints_num = 0
all_keypoints_by_type = []
for kpt_idx in range(18): # 19th for bg
total_keypoints_num += extract_keypoints(avg_heatmaps[:, :, kpt_idx], all_keypoints_by_type, total_keypoints_num)
pose_entries, all_keypoints = group_keypoints(all_keypoints_by_type, avg_pafs)
coco_keypoints, scores = self.convert_to_coco_format(pose_entries, all_keypoints)
image_id = int(file_name[0:file_name.rfind('.')])
for idx in range(len(coco_keypoints)):
coco_result.append({
'image_id': image_id,
'category_id': 1, # person
'keypoints': coco_keypoints[idx],
'score': scores[idx]
})
if visualize:
for keypoints in coco_keypoints:
for idx in range(len(keypoints) // 3):
cv2.circle(img, (int(keypoints[idx * 3]), int(keypoints[idx * 3 + 1])),
3, (255, 0, 255), -1)
cv2.imshow('keypoints', img)
key = cv2.waitKey()
if key == 27: # esc
return
with open(output_name, 'w') as f:
json.dump(coco_result, f, indent=4)
self.run_coco_eval(self.labels, output_name)
这个程序文件名为val.py,主要功能是对COCO数据集中的图像进行姿态估计,并评估估计结果的准确性。
程序首先导入了一些必要的库,包括argparse、cv2、json、math、numpy、torch等。然后,它导入了一些自定义的模块和函数,包括CocoValDataset、PoseEstimationWithMobileNet、extract_keypoints、group_keypoints等。
接下来,程序定义了一些辅助函数,包括run_coco_eval、normalize、pad_width、convert_to_coco_format、infer等。这些函数用于数据预处理、推断姿态估计结果等。
最后,程序定义了一个evaluate函数,该函数接受一些参数,包括标签文件路径、输出文件名、图像文件夹路径、模型检查点路径等。在evaluate函数中,程序加载模型并对每个图像进行姿态估计。然后,将估计结果转换为COCO格式,并保存到输出文件中。最后,程序调用run_coco_eval函数评估估计结果的准确性。
如果直接运行该程序文件,它会解析命令行参数,并调用evaluate函数进行姿态估计和评估。
5.4 datasets\transformations.py
class ConvertKeypoints:
def __call__(self, sample):
label = sample['label']
h, w, _ = sample['image'].shape
keypoints = label['keypoints']
for keypoint in keypoints: # keypoint[2] == 0: occluded, == 1: visible, == 2: not in image
if keypoint[0] == keypoint[1] == 0:
keypoint[2] = 2
if (keypoint[0] < 0
or keypoint[0] >= w
or keypoint[1] < 0
or keypoint[1] >= h):
keypoint[2] = 2
for other_label in label['processed_other_annotations']:
keypoints = other_label['keypoints']
for keypoint in keypoints:
if keypoint[0] == keypoint[1] == 0:
keypoint[2] = 2
if (keypoint[0] < 0
or keypoint[0] >= w
or keypoint[1] < 0
or keypoint[1] >= h):
keypoint[2] = 2
label['keypoints'] = self._convert(label['keypoints'], w, h)
for other_label in label['processed_other_annotations']:
other_label['keypoints'] = self._convert(other_label['keypoints'], w, h)
return sample
def _convert(self, keypoints, w, h):
# Nose, Neck, R hand, L hand, R leg, L leg, Eyes, Ears
reorder_map = [1, 7, 9, 11, 6, 8, 10, 13, 15, 17, 12, 14, 16, 3, 2, 5, 4]
converted_keypoints = list(keypoints[i - 1] for i in reorder_map)
converted_keypoints.insert(1, [(keypoints[5][0] + keypoints[6][0]) / 2,
(keypoints[5][1] + keypoints[6][1]) / 2, 0]) # Add neck as a mean of shoulders
if keypoints[5][2] == 2 or keypoints[6][2] == 2:
converted_keypoints[1][2] = 2
elif keypoints[5][2] == 1 and keypoints[6][2] == 1:
converted_keypoints[1][2] = 1
if (converted_keypoints[1][0] < 0
or converted_keypoints[1][0] >= w
or converted_keypoints[1][1] < 0
or converted_keypoints[1][1] >= h):
converted_keypoints[1][2] = 2
return converted_keypoints
class Scale:
def __init__(self, prob=1, min_scale=0.5, max_scale=1.1, target_dist=0.6):
self._prob = prob
self._min_scale = min_scale
self._max_scale = max_scale
self._target_dist = target_dist
def __call__(self, sample):
prob = random.random()
scale_multiplier = 1
if prob <= self._prob:
prob = random.random()
scale_multiplier = (self._max_scale - self._min_scale) * prob + self._min_scale
label = sample['label']
scale_abs = self._target_dist / label['scale_provided']
scale = scale_abs * scale_multiplier
sample['image'] = cv2.resize(sample['image'], dsize=(0, 0), fx=scale, fy=scale)
label['img_height'], label['img_width'], _ = sample['image'].shape
sample['mask'] = cv2.resize(sample['mask'], dsize=(0, 0), fx=scale, fy=scale)
label['objpos'][0] *= scale
label['objpos'][1] *= scale
for keypoint in sample['label']['keypoints']:
keypoint[0] *= scale
keypoint[1] *= scale
for other_annotation in sample['label']['processed_other_annotations']:
other_annotation['objpos'][0] *= scale
other_annotation['objpos'][1] *= scale
for keypoint in other_annotation['keypoints']:
keypoint[0] *= scale
keypoint[1] *= scale
return sample
class Rotate:
def __init__(self, pad, max_rotate_degree=40):
self._pad = pad
self._max_rotate_degree = max_rotate_degree
def __call__(self, sample):
prob = random.random()
degree = (prob - 0.5) * 2 * self._max_rotate_degree
h, w, _ = sample['image'].shape
img_center = (w / 2, h / 2)
R = cv2.getRotationMatrix2D(img_center, degree, 1)
abs_cos = abs(R[0, 0])
abs_sin = abs(R[0, 1])
bound_w = int(h * abs_sin + w * abs_cos)
bound_h = int(h * abs_cos + w * abs_sin)
dsize = (bound_w, bound_h)
R[0, 2] += dsize[0] / 2 - img_center[0]
R[1, 2] += dsize[1] / 2 - img_center[1]
sample['image
该程序文件是一个数据集转换的模块,文件名为datasets\transformations.py。该模块包含了几个类,用于对数据集进行不同的转换操作。
-
ConvertKeypoints类:该类用于将关键点的坐标进行转换。根据关键点的坐标值和图像的宽高,对关键点进行一些处理,如判断关键点是否在图像范围内,将关键点的顺序进行重新排序等。
-
Scale类:该类用于对图像进行缩放操作。根据给定的概率和缩放范围,随机选择一个缩放比例对图像进行缩放,并相应地调整关键点的坐标。
-
Rotate类:该类用于对图像进行旋转操作。根据给定的旋转角度范围,随机选择一个旋转角度对图像进行旋转,并相应地调整关键点的坐标。
-
CropPad类:该类用于对图像进行裁剪和填充操作。根据给定的裁剪范围和填充颜色,随机选择一个裁剪位置对图像进行裁剪,并相应地调整关键点的坐标。
-
Flip类:该类用于对图像进行翻转操作。根据给定的概率,随机选择是否对图像进行水平翻转,并相应地调整关键点的坐标。
这些类的实例都可以作为函数调用,接受一个样本作为输入,并对样本进行相应的转换操作,并返回转换后的样本。
5.6 models\with_mobilenet.py
import torch
from torch import nn
from modules.conv import conv, conv_dw, conv_dw_no_bn
class Cpm(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.align = conv(in_channels, out_channels, kernel_size=1, padding=0, bn=False)
self.trunk = nn.Sequential(
conv_dw_no_bn(out_channels, out_channels),
conv_dw_no_bn(out_channels, out_channels),
conv_dw_no_bn(out_channels, out_channels)
)
self.conv = conv(out_channels, out_channels, bn=False)
def forward(self, x):
x = self.align(x)
x = self.conv(x + self.trunk(x))
return x
class InitialStage(nn.Module):
def __init__(self, num_channels, num_heatmaps, num_pafs):
super().__init__()
self.trunk = nn.Sequential(
conv(num_channels, num_channels, bn=False),
conv(num_channels, num_channels, bn=False),
conv(num_channels, num_channels, bn=False)
)
self.heatmaps = nn.Sequential(
conv(num_channels, 512, kernel_size=1, padding=0, bn=False),
conv(512, num_heatmaps, kernel_size=1, padding=0, bn=False, relu=False)
)
self.pafs = nn.Sequential(
conv(num_channels, 512, kernel_size=1, padding=0, bn=False),
conv(512, num_pafs, kernel_size=1, padding=0, bn=False, relu=False)
)
def forward(self, x):
trunk_features = self.trunk(x)
heatmaps = self.heatmaps(trunk_features)
pafs = self.pafs(trunk_features)
return [heatmaps, pafs]
class RefinementStageBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.initial = conv(in_channels, out_channels, kernel_size=1, padding=0, bn=False)
self.trunk = nn.Sequential(
conv(out_channels, out_channels),
conv(out_channels, out_channels, dilation=2, padding=2)
)
def forward(self, x):
initial_features = self.initial(x)
trunk_features = self.trunk(initial_features)
return initial_features + trunk_features
class RefinementStage(nn.Module):
def __init__(self, in_channels, out_channels, num_heatmaps, num_pafs):
super().__init__()
self.trunk = nn.Sequential(
RefinementStageBlock(in_channels, out_channels),
RefinementStageBlock(out_channels, out_channels),
RefinementStageBlock(out_channels, out_channels),
RefinementStageBlock(out_channels, out_channels),
RefinementStageBlock(out_channels, out_channels)
)
self.heatmaps = nn.Sequential(
conv(out_channels, out_channels, kernel_size=1, padding=0, bn=False),
conv(out_channels, num_heatmaps, kernel_size=1, padding=0, bn=False, relu=False)
)
self.pafs = nn.Sequential(
conv(out_channels, out_channels, kernel_size=1, padding=0, bn=False),
conv(out_channels, num_pafs, kernel_size=1, padding=0, bn=False, relu=False)
)
def forward(self, x):
trunk_features = self.trunk(x)
heatmaps = self.heatmaps(trunk_features)
pafs = self.pafs(trunk_features)
return [heatmaps, pafs]
class PoseEstimationWithMobileNet(nn.Module):
def __init__(self, num_refinement_stages=1, num_channels=128, num_heatmaps=19, num_pafs=38):
super().__init__()
self.model = nn.Sequential(
conv( 3, 32, stride=2, bias=False),
conv_dw( 32, 64),
conv_dw( 64, 128, stride=2),
conv_dw(128, 128),
conv_dw(128, 256, stride=2),
conv_dw(256, 256),
conv_dw(256, 512), # conv4_2
conv_dw(512, 512, dilation=2, padding=2),
conv_dw(512, 512),
conv_dw(512, 512),
conv_dw(512, 512),
conv_dw(512, 512) # conv5_5
)
self.cpm = Cpm(512, num_channels)
self.initial_stage = InitialStage(num_channels, num_heatmaps, num_pafs)
self.refinement_stages = nn.ModuleList()
for idx in range(num_refinement_stages):
self.refinement_stages.append(RefinementStage(num_channels + num_heatmaps + num_pafs, num_channels,
num_heatmaps, num_pafs))
def forward(self, x):
backbone_features = self.model(x)
backbone_features = self.cpm(backbone_features)
stages_output = self.initial_stage(backbone_features)
for refinement_stage in self.refinement_stages:
stages_output.extend(
refinement_stage(torch.cat([backbone_features, stages_output[-2], stages_output[-1]], dim=1)))
return stages_output
这个程序文件是一个用于姿势估计的模型,基于MobileNet网络结构。它包含了几个不同的模块和阶段。
-
Cpm模块:这个模块包含了一个卷积层和几个深度可分离卷积层,用于对输入进行特征提取和对齐操作。
-
InitialStage模块:这个模块包含了一个由卷积层组成的主干网络和两个分支网络,用于生成初始的热图和关键点位置向量场。
-
RefinementStageBlock模块:这个模块包含了一个卷积层和一个深度可分离卷积层,用于对输入进行特征提取和细化操作。
-
RefinementStage模块:这个模块包含了多个RefinementStageBlock模块和两个分支网络,用于对姿势估计结果进行进一步的细化。
-
PoseEstimationWithMobileNet模块:这个模块是整个姿势估计模型的主体部分,包含了一个MobileNet主干网络、一个Cpm模块、一个InitialStage模块和多个RefinementStage模块。它通过前向传播将输入图像经过主干网络、Cpm模块和各个阶段的模块,最终输出姿势估计的结果。
整个模型的输入是一张图像,输出是一系列的热图和关键点位置向量场,用于表示人体的姿势。这个模型可以用于姿势估计的任务,例如人体关键点检测和动作识别等。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于改进OpenPose的舞蹈动作规范度评判系统。它使用OpenPose模型进行人体姿势估计,并通过对姿势进行评估和分析,来评判舞蹈动作的规范度。
该项目包含了多个程序文件,每个文件都有不同的功能。下面是每个文件的功能整理:
| 文件路径 | 功能 |
|---|---|
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\location.py | 使用moviepy库对视频文件进行处理,包括读取视频、获取视频属性和方法、加速视频等操作。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\train.py | 训练模型的脚本,包括数据加载、模型训练、保存模型等操作。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\ui.py | 使用OpenPose模型进行人体姿势估计的Demo,包括图像姿势估计和可视化显示。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\val.py | 对COCO数据集中的图像进行姿态估计,并评估估计结果的准确性。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\datasets\coco.py | 定义了一个COCO数据集的类,用于加载和处理COCO数据集。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\datasets\transformations.py | 定义了一些数据集转换的类,用于对数据集进行不同的转换操作。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\datasets_init_.py | 数据集模块的初始化文件,定义了datasets模块的导入行为和功能。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\models\with_mobilenet.py | 定义了一个基于MobileNet网络结构的姿势估计模型。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\models_init_.py | 模型模块的初始化文件,定义了models模块的导入行为和功能。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\modules\conv.py | 定义了一些卷积相关的函数和类,用于构建卷积层。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\modules\get_parameters.py | 定义了一些获取模型参数的函数和类。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\modules\keypoints.py | 定义了一些处理关键点的函数和类,用于关键点的转换和可视化。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\modules\load_state.py | 定义了一些加载模型状态的函数和类。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\modules\loss.py | 定义了一些损失函数的函数和类,用于模型训练时的损失计算。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\modules\one_euro_filter.py | 定义了一个OneEuroFilter类,用于进行姿势估计结果的滤波。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\modules\pose.py | 定义了一个Pose类,用于表示姿势估计的结果。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\modules_init_.py | 模块模块的初始化文件,定义了modules模块的导入行为和功能。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\scripts\convert_to_onnx.py | 将模型转换为ONNX格式的脚本。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\scripts\make_val_subset.py | 生成验证集子集的脚本。 |
| E:\视觉项目\shop\基于改进OpenPose的舞蹈动作规范度评判系统\code\scripts\prepare_train_labels.py | 准备训练标签的脚本。 |
以上是对每个文件功能的简要概述,具体的实现细节可能需要进一步查看每个文件的代码。
7.改进OpenPose
为了达到网络优化的目的,在保证精确度的前提下,本文提出采用MobileNet v3-Small替代原模型中的VGG19 网络。原网络内部为传统卷积核,随着网络的深度增加,容易出现梯度为零的情况,达不到更好的训练效果。MobileNet v3网络具有特殊的结构,比如其内部的深度可分离卷积核,其次是为了缓解梯度消失而采用的残差结构。算法运行过程中,该网络会先采用将输入维度提升后降低的方法,实现梯度的增强传播,这样极大地避免了运算时的存储过大的问题,不仅减少了计算量,而且提高了运算速度。
MobileNet v3
MobileNet v3网络是 MobileNet v1、MobileNetv2的衍生网络,经过两代的叠加与优化,同时兼顾v1网络的深度可分离卷积特点和 v2网络的线性瓶颈的残差结构,性能以及速度得到了很大的提升。并且与MobileNet v1, v2相比,MobileNet v3准确率更高,模型更小。MobileNet v3网络的核心是结合了v1的深度可分离卷积 Depthwise卷积、v2的超参数α、β及倒残差结构,同时自身又引入SE模块,加入 benck模块,在网络传播中实现了通道中可分离卷积与SE通道注意力机制和残差连接,将原有网络中Relu6用新的激活函数 h-swish (x )进行替换。
Depthwise卷积核
深度卷积核(Depthwise)每个卷积核的通道数为1,每个卷积核和输入特征矩阵通道—一对应,同样,输出特征矩阵通道和卷积核也相互对应,即输入特征和卷积核矩阵的通道数与输出特征矩阵的通道数相等。相比普通卷积核需要与每个输入通道进行卷积,然后再将通道相同位置进行叠加而言,Depthwise卷积核只需要单方面负责一个通道进行
独立卷积,大大减少了参数量和运算的冗余性。1.3.2超参数
超参数宽度乘数(Width Multiplier ) a、分辨率乘数( Resolution Multiplier )B是模型的瘦身参数,前者代表卷积核个数的一个倍域,也就是来控制卷积过程中所采用卷积核的个数,后者代表分辨率参数。两者都可以在保证准确度相对变化较小的情况下,大大减少网络参数量。
倒残差结构
普通的残差结构如 ResNet5’,在对输入矩阵进行压缩的过程中,通常采用1×1的卷积核,也就是减少输入的通道数。随后采用3×3的卷积核再对其进行卷积处理,卷积处理后就会采用1×1的卷积核来扩充通道数量,网络形状两头大、中间小,类似于瓶颈结构。MobileNet采用倒残差结构,先采用l ×1的卷积核进行升维操作,将模型变得更深,然后通过3×3的 Depthwise卷积核进行卷积,最后使用1×1的卷积核进行降维处理。
bneck
MobileNet v3网络是由一系列的bneck堆叠形成的。首先通过一个1×1卷积层来进行升维处理,在卷积后会跟有BN和 ReLU6激活函数。紧接着是一个3×3大小DW卷积,卷积后面依旧会跟有BN和 ReLU6激活函数。最后一个卷积层是1×1卷积,起到降维作用。

8.基于人体关节点提取的动作相似性计算
基于人体关节点提取的动作相似性计算方法主要包括以下几个步骤:①关节点定位。首先,提取标准图像和目标图像中的人体关节点位置信息;然后将两幅图片上的动作进行标准化,对其坐标进行转换,将其叠加到同一个坐标系中。②偏移量计算。计算标准化后各个关节点的方向和长度差异,推理计算目标图像关节点在三维空间中与标准动作的角度差异。③动作阶梯型相似度计算。依据②计算出学习者动作与标准动作各个关节点之间的偏移角度,设计动作相似度定量指标,计算舞蹈动作与标准动作各个关节点的相似度。④姿态还原。选取分数最低的关节,将标准动作图像中对应的关节位置信息再次进行坐标修正,通过坐标变化,将动作不标准的关节位置所对应的标准动作还原到目标图像中,获得相应的动作纠正建议。
关节点定位
由于存在人体身高差异、学习者在拍照的过程中也有摄像头视角差异以及与镜头的距离不同等问题,本文在进行学习者姿态与标准动作姿态对比之前需要对目标图像(学习者所拍摄的图像进行标准化操作。
由于本文所提出的算法是一种实时动作对比算法,因此在获得所拍摄学习者动作图像之后,先对图像进行预处理,即人体检测框提取和人体关节点估计,从而获得图像中学习者的各个关节点位置信息。17个关节点从上到下依次为:左右眼、左右耳、鼻、左右肩关节、左右肘关节、左右手、左右髋关节、左右膝关节和左右脚,按1至17分别编号。
根据其活动程度的大小将所获得的17个关节点分为两类:第一类为活动范围较小的左右肩关节和左右髋关节,将其定义为静止关节点;第二类为其余的关节点,其运动范围相对较大,将其定义为活动关节点。本文所定义的静止关节点主要是用来定位和确定放缩比例,从而较好地实现目标图像与标准图像人体关节的位置对比。
根据所定义的两类关节点,先以目标图像中的左肩关节点作为基准位置,然后在标准图像中所有关节点保持相对位置不变的前提下,将其叠加到带有关节点信息的目标图像中,使得标准图像和目标图像的左肩关节点重合,实现第一次坐标修正,第一次坐标修正后关节点p;表示为
![]()
其中:i为图片编号,j为关节点编号,6为左肩关节点的编号。
接着,以所定义的静止关节点(左、右肩关节点和左、右髋关节点)的欧几里得距离分别作为人体肩宽和腾宽。用目标图像和标准图像的肩宽和胯宽之和的比例作为标准化依据,对目标图像中关节点间的连线做等比例放缩,并对相应关节点坐标进行修正,获得标准化处理的第二次坐标修正关键点pi ',表示为
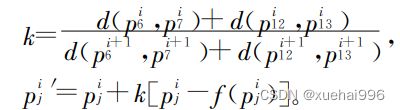
其中:7、12、13号分别为右肩、左髋、右髋关节点的编号; f§表示与该关节点相连的关节点; d( pjl ,pjz )表示点p与点pe之间的欧几里得距离
偏移量计算
本文以舞蹈学习者的动作对比为研究对象,由于舞者动作姿态变化,舞蹈动作反映在二维图像上时,会出现四肢频繁摆动现象。当舞者肢体发生前后摆动时,会产生关节点之间距离的长短变化,因此为了精确地推理舞者动作姿态在三维空间中与标准动作的差异,本文依据舞者肢体角度变化和长度信息变化进行偏移量计算。
由于舞蹈动作主要依赖于舞者四肢动作的变化,所以本文仅考虑8个关节点的偏移量,分别为左、右肩关节、左、右肘关节,左、右髋关节,左、右膝关节,由1至8分别编号。
经过关节点标准化二次修正后,对上述的8个关节点进行偏移量对比计算。当肢体在空间中有前后偏移的时候,肢体在图片上的二维投影长度会发生变化,所以可以使用肢体的长度信息推导肢体在空间中的前后偏移角度da ,通过推导得出
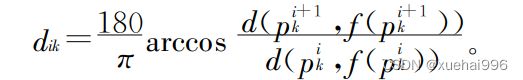
其中:h一作用关节的位针旋转角度,世过然后,使用关节的位置信息推理关节点角度信
得出:

最后,依据公式(4)和(5)计算所得的两个角度信息,推理三维空间内关节的偏移角度,即

其中deg ∈ (o°,180°)。
学习者动作阶梯型相似度计算
计算出学习者舞蹈动作与标准动作各个关节点之间的偏移角度之后,设计动作相似度定量指标,计算学习者动作与标准动作各个关节点的相似度sk。在专业舞蹈老师的指导下,定义阶梯型动作相似度计算方法,当公式(6中偏移角≤5°时相似度si为1 ;偏移角为5~30°时,相似度sia从1至0.6线性下降;当偏移角大于30°时,相似度sk从0 .6至О线性下降,如公式(7)所示:

根据公式(7)计算所定义8个主要肢体关节点的相似度sk。根据各个关键点的相似度计算结果,获得整体舞蹈动作的总体相似度
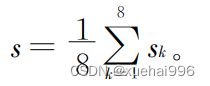
当总体相似度为1时,认为学习者的动作是标准的;否则,依据相似度最低的关键点信息,给出最终的动作相似度。
在计算出学习者各个关节的相似度分数后,选取分数最低的关节,将标准动作图像中对应的关节位置信息再次进行坐标修正:

通过坐标变化,最终叠加到目标图像中,使学习者可以按照图像中标准动作修正自己的动作,提高舞蹈学习的效果。
9.训练结果分析
目前,对学习者舞蹈动作是否标准的判断没有科学统一的评估方法,依赖于主观视觉评价的人工评价方法是目前最主流的评估方法,但是人工评价结果很容易受主观影响,缺乏一个可量化的客观评价方式。因此,本文提出一种基于姿态估计的舞蹈动作对比算法,对舞蹈者的动作是否标准进行定量计算。为了验证所提出算法的有效性,本文采用专业舞者主观评价和定量客观评价方法对舞蹈动作是否标准进行评估。
专业舞蹈教师主观评价对学习者动作通过专业舞蹈教师进行标准与否评价。在此,选取277组舞蹈数据,分为专业舞者动作和学习者舞蹈动作,如图所示。图a为专业舞蹈者动作姿态图像,b为学习者根据专业舞者动作进行学习的舞蹈姿势,舞蹈者视角分为正视图、侧视图、背视图。专业舞蹈教师对学习者动作是否标准判断正确的有247组,总体正确率为89.17% ;正视图、背视图和侧视图的正确率分别为:90 .67%、88 .68%和78.13%。侧视图的正确率较低,这是因为教师在对侧视图中舞蹈者进行动作姿态标准判断时,无法依靠二维图像中因视角变化及角度遮挡情况下的舞蹈者姿态进行舞者肢体及关节点的准确定位。
10.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《基于改进OpenPose的舞蹈动作规范度评判系统》
11.参考文献
[1]毕雪超.基于空间骨架时序图的舞蹈特定动作识别方法[J].信息技术.2019,(11).DOI:10.13274/j.cnki.hdzj.2019.11.004 .
[2]田堉橦.高校舞蹈教学方法的发展历程研究综述[J].辽宁高职学报.2018,(10).DOI:10.3969/j.issn.1009-7600.2018.10.019 .
[3]李红竹.舞蹈视频图像中动作识别方法研究[J].电视技术.2018,(7).DOI:10.16280/j.videoe.2018.07.008 .
[4]陈利峰.舞蹈视频图像中人体动作识别技术的研究[J].现代电子技术.2017,(3).DOI:10.16652/j.issn.1004-373x.2017.03.014 .
[5]章彭敏,俞培明,胡小岗.体育教学情境下的师生交流研究[J].陕西师范大学学报(自然科学版).2008,(S1).
[6]谢志斌.对新时期高校体育课改革的分析与研究[J].陕西师范大学学报(自然科学版).2008,(S1).
[7]王露晨.基于动作捕捉技术的舞蹈姿态分析与教学方法研究[J].辽宁师范大学.2016.
[8]郭辰琳.舞蹈教育数字化开发应用研究[D].2015.
[9]黄忠源.我国高校舞蹈教育的现状及发展[D].2013.