2019_WWW_Dual graph attention networks for deep latent representation of multifaceted social effect
[论文阅读笔记]2019_WWW_Dual graph attention networks for deep latent representation of multifaceted social effects in recommender systems—(The World Wide Web Conference, 2019.05)-- Qitian Wu, Hengrui Zhang, Xiaofeng Gao, Peng He, Paul Weng, Han Gao, Guihai Chen
论文下载地址:https://dl.acm.org/doi/abs/10.1145/3308558.3313442
发表期刊:The World Wide Web Conference
Publish time: 2019.05
作者单位:上交,腾讯
数据集:
- Epinios,
- Wechat Top story
代码:https://github.com/echo740/DANSER-WWW-19
本文最大的创新(贡献)–个人的理解
- (1) 对user或item,从2个方面考虑的:
一是:homophily,它global的,是static的
(就是想找一个东西,代表自己的inherent的一些东西)
二是:influence,它是local的,是dynamic的
(就是想找一个东西,代表在自己可选可不选的时候,会被其他uer影响的情形)- (2) 是context-awared的(a context is a user item pair)
个人理解,context aware本身就是作者自己定义的。就像马哲里说的,就是一个具体的情形(specific condition)
作者用Dual GAT 去学习two-fold social effects的权重参数- (3)采取一个有效的策略(方法,机制,流程),对这4种interactions进行fuse,因为到最后总要利用这些信息得到一个结果
作者propose a new policy-based fusion strategy based on contextual multi-armed bandit(多臂老虎机,这个就是强化学习RL的内容,感觉现在趋势就是多种方法一起用,融合)
Abstract(本文的创新点)
(1) However, most existing models assume that social effects from friend users are static and under the forms of constant weights or fixed constraints.
(2) To relax this strong assumption, in this paper, we propose dual graph attention networks to collaboratively learn representations for two-fold social effects, where one is modeled by a user-specific attention weight and the other is modeled by a dynamic and context-aware attention weight
(3) we propose a new policy-based fusion strategy based on contextual multi-armed bandit to weigh interactions of various social effects
1 Introduction
1.1 Prior Works and Limitations
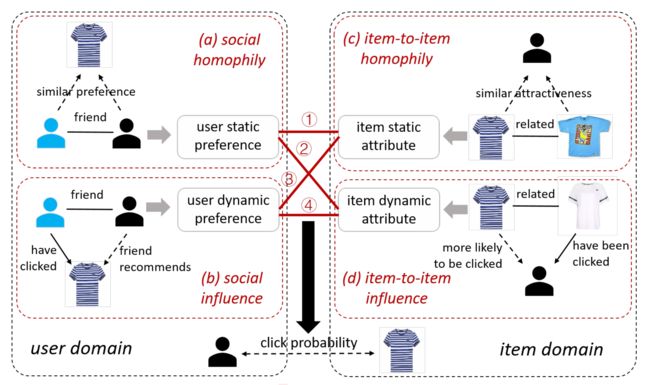
(1) First, most studies assume that linked users all share similar preferences. This assumption cannot suit well contemporary SNS since there could be various types of online friends, such as close friends, casual friends, and event friends.(朋友分很多种)
(2) Second, most works model friends’ influences statically under the forms of constant weights or fixed constraints. This assumption ignores the dynamic pattern of social effects.(忽略了社会影响的动态模式)
(3) Third, previous methods lack interpretability for social effects
1.2 Motivations and Rationales
1.3 Methodologies and Results
(1) we propose DANSER (Dual graph Attention Networks for modeling multifaceted Social Effects in Recommender systems)
(3) such dual mechanism possesses two advantages:

(4) we propose a policy-based strategy to dynamically weigh the four interactions.
Specifically, we model the problem as a contextual multi-armed bandit, and treat the weighing strategy as a policy conditional on the context (the targeted user-item pair). Then our goal is to optimize a reward (w.r.t predicted loss)
(5) For model training, we use stochastic policy gradient to update our neural network-based policy unit, and design a local-graph aware regularization technique to reduce computational cost for regularization
(6)数据集
Epinions
WeChat Top Story
1.4 Our Contributions(与上面重复,但算是一个小总结)
1.4.1 General Aspects
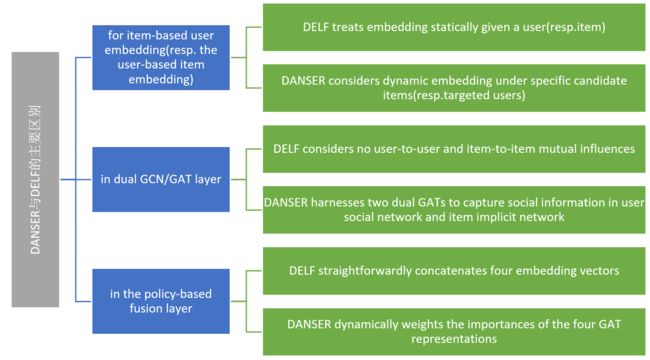
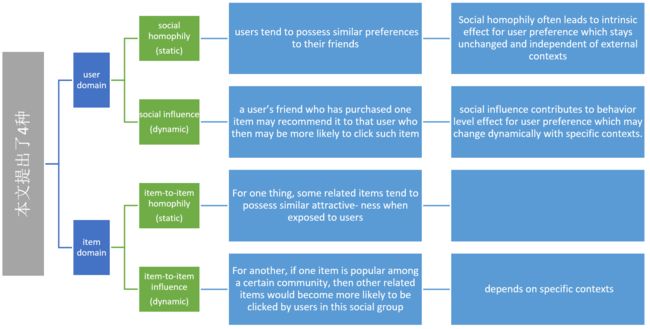
We distinguish the social homophily and social influence notions in view of static and dynamic effects. Also, we extend the two-fold social effects in user domain to item domain, and therefore investigate four social effects in recommender systems
1.4.2 Novel Methodologies
We propose DANSER with two dual GATs and a policy-based fusion unit. The dual GATs can collaboratively model four social effects in both user and item domains, while the policy unit, based on a contextual multi-armed bandit, dynamically weighs four interactions of social effects in two domains according to specific contexts
1.4.3 Multifaceted Experiments
2 Preliminary and Background
R i ( u ) R_i(u) Ri(u) denote the set of items rated by user u u u
R u ( i ) R_u(i) Ru(i) denote the set of users who have rated item i
F u ( u ) F_u(u) Fu(u) denote the set of nodes adjacent to u u u in G u G_u Gu
user-item interaction matrix R R R
user social network G U G_U GU
Problem Formulation
3 Methodologies
3.1 Model Framework
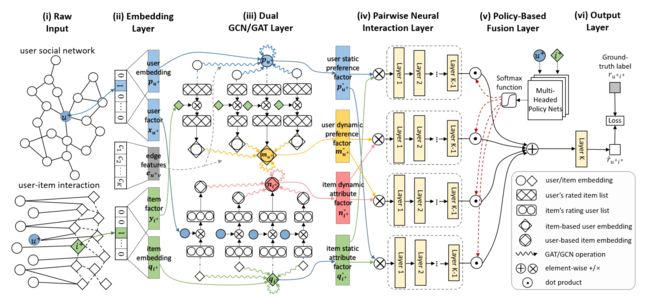
Figure 2: DANSER framework. Blue circles denote a targeted user u + u^+ u+ while green rhombuses denote a candidate item i + i^+ i+. i)
The model requires user-item interaction records and user social network as raw input. We use common users who rate both items to calculate the item-item relevance and link the related items to form an item implicit network (the dotted lines be- tween items). ii) In the embedding layer, we represent one user (resp. item) as a low-dimensional embedding vector and a latent factor. Besides, interaction frequencies between users are used as edge features. iii) In the dual GCN/GAT layer, four different graph attention networks are to capture the two two-fold social effects, where the upper (resp. lower) two of them output representations for user (resp. item) static and dynamic preferences (resp. attributes) under the effect of homophily and influence, respectively. iv) These four deep factors will be pairwisely combined as four interacted features, which are then fed into four independent neural networks to obtain more condensed representations. v) Then a policy net with the input of item i + i^+ i+’s and user u + u^+ u+’s embeddings as context information outputs weights for four interacted features, which will be aggregated as one synthetic vector. vi) Finally, the synthetic vector is input into the output layer to give the final predicted score r ^ u + i + \hat{r}_{u^+i^+} r^u+i+.
3.3.1 Raw Input and Item Implicit Network
(1) Most existing methods treat items independently since there is no prior information that explicitly expresses the relationship between items
(2) One way to calculate the similarity or relevance between two items is by the common users who clicked or rated them . For any item i i i and item j j j, we define their similarity coefficient S i j S_{ij} Sij as the number of users who clicked both items. These coefficients induce an equivalence relation over items as follows: item i i i is related to item j j j if S i j > τ S_{ij} > \tau Sij>τ with τ \tau τ a fixed threshold. (物品间的相似度,可以用共同rate它们的user数量来定义)
(3) We define the item implicit network as the graph G I = ( V I , E I ) G_I = (V_I, E_I) GI=(VI,EI) where V I V_I VI is the set of items and E I E_I EI is the set of edges that connects two related items.
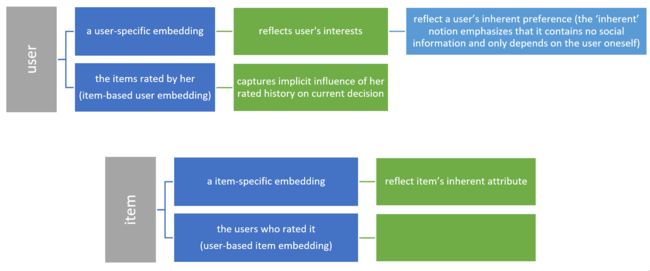
3.1.2 Embedding Layer
(1) The raw input of each user (resp. item) is a one-hot vector with high dimension, and the embedding operation is to project each user to a low-dimensional representation
3.1.3 Dual GCN/GAT Layer
(1) 说一下GCN GAT在干嘛,能干嘛(GCN GAT特性,是前人的工作)
Graph convolution network (GCN) conducts local convolutional operation over neighbor nodes in graph and outputs a new representation for each node, in order to encode the graph structure information as low-dimensional node representations. Such operation can be viewed as an extension of convolution neural network (CNN) from a grid structure to general graphs. GCN equally aggregates the neighbors’ embedding in each convolution and treats each neighbor nodes with equal importance. In contrast, Graph Attention Network (GAT) [31] leverages attention mechanism to consider different weights from neighbor nodes, which enables the model to filter out noises and focus on important adjacent nodes.
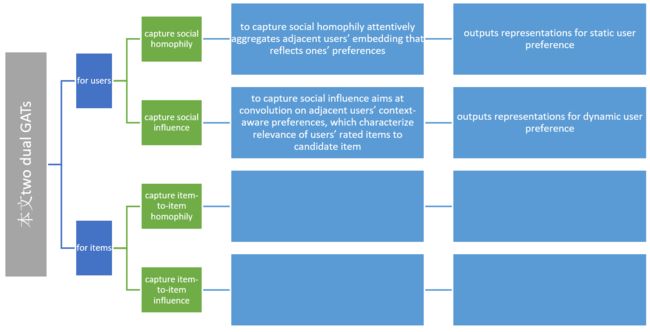
(2) DANSER uses two dual GATs to collaboratively learn different deep representations for user static/dynamic preference and item static/dynamic attribute
(I) GAT to capture social homophily (marked as blue in Fig. 2).
(1) via user embedding, we have P P P as representation of inherent user preference factor.
Then the GCN/GAT operation could output a new representation, the user static preference factor P ∗ P^* P∗
![]()
Where σ \sigma σ, W p W_p Wp, b p b_p bp are activation function, weight matrix, bias vector respectively, and P ∗ P^* P∗ is the updated representation of users, which incorporates social information by using the attention weights. A p ( G U ) = { α U V P } M × N A_p(G_U)=\{ \alpha^P_{UV}\}_{M\times N} Ap(GU)={αUVP}M×N obtained from G U G_U GU. Its elements are defined as follows

where W E W_E WE is weight matrix, Γ U ( u ) = { u } ∪ F { u } \Gamma_U(u)=\{u\} \cup F\{u\} ΓU(u)={u}∪F{u}, a t t n U ( x , y , z ) = L e a k y R e l u ( w U T z ⊗ ( x ∥ y ) ) attn_U(x,y,z)=LeakyRelu(w^T_Uz\otimes(x\parallel y)) attnU(x,y,z)=LeakyRelu(wUTz⊗(x∥y)), and w U w_U wU is weight vector. Here ⊗ \otimes ⊗ and ∥ \parallel ∥ denote the element-wise product and concatenation, respectively.
Note that the above GAT weight α u v P \alpha^P_{uv} αuvP remains unchanged given user u u u and v v v, which means factor matrix P ∗ P^* P∗ is fixed for users
(II) GAT to capture social influence (marked as yellow in Fig. 2)
(1) In contrast to social homophily, social influence effect is often context-aware, and the model needs to output different attention weights for friends w.r.t different candidate items
(2) Through the embedding layer, we have y u y_u yu as the embedding of the items clicked by user u u u. Then we let each item clicked by user u u u interact with candidate item i + i^+ i+
![]()
(3) This product operation can help to focus on the candidate item and model dynamic social influence under a specific context. We define the item-based user embedding M i + = { m u i + } D × M M_{i^+}=\{m^{i^+}_u\}_{D\times M} Mi+={mui+}D×M which depends on candidate item i + i^+ i+ with max pooling to select the most dominating features for D dimensions

where m u d i + m^{i^+}_{ud} mudi+, y i + d y_{i^+d} yi+d, and y + j d y+{jd} y+jd are the d-th feature of m u i + m^{i^+}_{u} mui+, y i + y_{i^+} yi+, y j y_j yj respectively.
(4) The max pooling operation can help to focus on the most important value and alleviate noises in users’ clicked history.
(5) The item-based embedding m u i + m^{i^+}_{u} mui+ includes two information: i) user u u u’s context-aware preference (w.r.t candidate item i+), and ii) inherent representation for u u u (independent of social information).
(6) In order to define the user dynamic preference factor M i + ∗ M^{*}_{i^+} Mi+∗, we proceed to incorporate the social information from friend users,
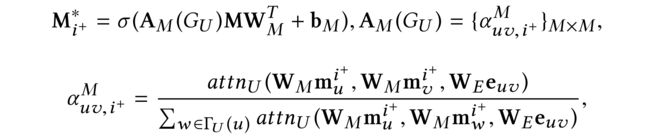
for v ∈ Γ U ( u ) v \in\Gamma_U(u) v∈ΓU(u). Note that the above attention weight α u v , i + M \alpha^M_{uv,i^+} αuv,i+M depends on the user’s history of rated items as well as specific candidate item i + i^+ i+, which indicates that factor matrix M i + ∗ M^{*}_{i^+} Mi+∗ would change dynamically with different contexts.
(III) GAT to capture item-to-item homophily (marked as green in Fig. 2)
Similarly, we use the item embedding Q as representation of inherent item attribute factor, and then leverage GAT to incorporate social information
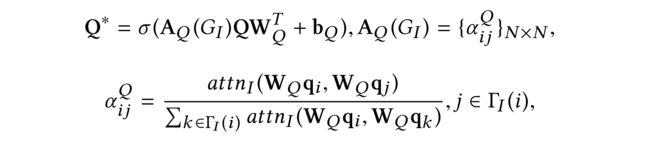
where a t t n i ( x , y ) = L e a k y R e l u ( w I T ( x ∥ y ) ) attn_i(x,y)=LeakyRelu(w^T_I(x\parallel y)) attni(x,y)=LeakyRelu(wIT(x∥y)), and w I w_I wI is a weight vector. The GAT weight α i j Q \alpha^Q_{ij} αijQ remains unchanged given item i i i and j j j.
Correspondingly, item-to-item homophily contributes to static effect for item’s attribute, and we call it static attribute factor.
(IV) GAT to capture item-to-item influence (marked as red in Fig.2)
We now model item-to-item influence, which is context-aware and depends on the specific targeted user. Hence, our model needs to output different attention weights for distinct related items w.r.t different targeted users. Similarly to social influence, the user-based item representation N u + = ( n i u + ) D × N N_{u^+}=(n^{u^+}_{i})_{D\times N} Nu+=(niu+)D×N for a given targeted user u + u^+ u+ can be defined as follows:
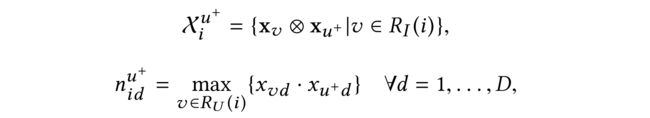
where n i d u + n^{u^+}_{id} nidu+, x u + d x_{u^+d} xu+d, and x v d x_{vd} xvd are the d d d-th feature of n i u + n^{u^+}_{i} niu+, x u + x_{u^+} xu+, x v x_v xv respectively.
Then the representation for item dynamic attribute N u + ∗ N^{*}_{u^+} Nu+∗ can be computed as follows:
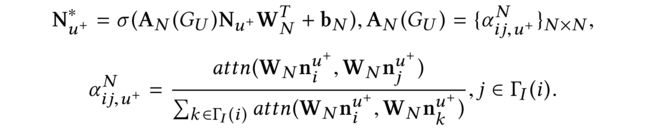
3.1.4 Pairwise Neural Interaction Layer
Since user’s decision on one item often depends on both user preference and item attribute feeding the four results into different neural networks indexed by a∈ {1, 2, 3, 4}
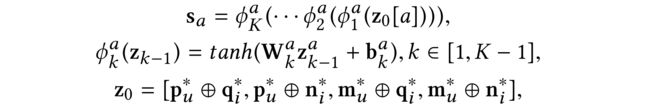
Here we employ a tower structure for each network, where higher layers have smaller number of neurons(DELF中就是这样做的)
3.1.5 Policy-Based Fusion Layer
(1) we propose a new policy-based fusion strategy to dynamically allocate weights to the four interacted features according to specific user-item pairs
We model the weight allocation as a contextual multi-armed bandit problem, where an action, denoted by γ ∈ {1, 2, 3, 4}, indicates which feature to choose, a context is a user-item pair and the reward after playing an action represents a recommendation loss
(2) In this problem, a stochastic policy can be written as the conditional probability p ( γ ∣ p u , q i ) p(\gamma|p_u, q_i) p(γ∣pu,qi)
(3) To make the problem solvable, we approximate by a neural network (called policy network):
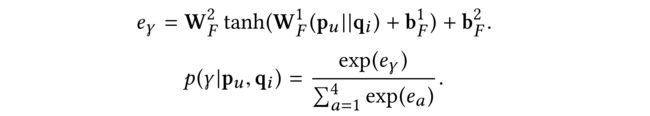
Then the synthetic representation can be expressed as
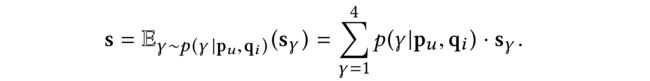
We call the above strategy single-headed policy-based fusion(单头基于策略的混合)
we can extend it to a multi-headed version. We harness L different independent policy networks and the final weights are given by the averaged weights given by each policy net. The training of policy networks is by stochastic policy gradient
3.1.6 Output Layer
Then probability of user u clicking item i can be predicted by
r ^ u i = n n ( s ) \hat{r}_{ui}=nn(s) r^ui=nn(s)
(1) If a clicking probability is required (for implicit feedback), n n ( ⋅ ) nn(\cdot) nn(⋅) can be a fully-connected layer with a sigmoid activation function
(2) If a rating value is needed (for explicit feedback), n n ( ⋅ ) nn(\cdot) nn(⋅) can be a fully-connected layer without activation function
3.1.7 Loss Function
(1) For implicit feedback, the most widely adopted loss function is the cross-entropy defined as
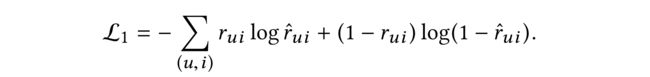
(2) For explicit feedback, we adopt the mean square loss

3.2 Training
3.2.1 Mini-Batch Training.
We also leverage mini-batch training to calculate the gradient
We observe that number of friends tends to obey a long-tail distribution
3.2.2 Local-Graph Aware Regularization
(1) In our model, we adopt L1 regularization to constrain the embedding parameters to sparse forms. The regularization loss can be expressed as
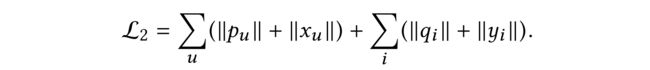
In each batch training, only the embedding parameters for user-item pair ( u , i ) (u,i) (u,i) in the batch will be used to calculate the regularization loss. Here we extend this idea to graph structure and call it as local-graph aware regularization. The new regularization loss can be written as

To sum up, the final loss function is
![]()
(2) Besides, for parameters in neural networks (weight matrix and bias vectors), we adopt dropout strategy to replace the traditional regularization
3.2.3 Policy Gradient
(1) In training stage, we train the policy networks in a stochastic way
(2) The policy gradient method REINFORCE can be used to update parameters in one policy network (denoted as θ), and the gradient can be derived as follows:

3.2.4 Training Algorithm

3.3 Discussions
3.3.1 Justification of Dual GATs
(1)
[外链图片转存失败,源站可能有防盗在这里插入!链机制,建描述]议将图片上https://传(imblog.csdmg.-n/96ed9d9actSb2e264f13a4062056537781dd.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAaGFueGluXw==,size_20,color_FFFFFF,t_70,g_se,x_16,#pic_center)ihttps://img-blog.csdnimg.cn/96ed9d9a2e264f13a4062056537781dd.png?text_Q1NETiBAaGFueGluXw==,size_20,color_FFFFFF,t_70,g_se,x_16,width=")]
(2) for the recommendation of candidate item i + i^+ i+ to targeted user u + u^+ u+
item i + i^+ i+ is similar to item i 1 i_1 i1
item i + i^+ i+ is similar to item i 2 i_2 i2
here, we assume that user u + u^+ u+ has only clicked on i i i_i ii and i 2 i_2 i2, and users u 1 u_1 u1 to u 4 u_4 u4 are u + u^+ u+'s friends.
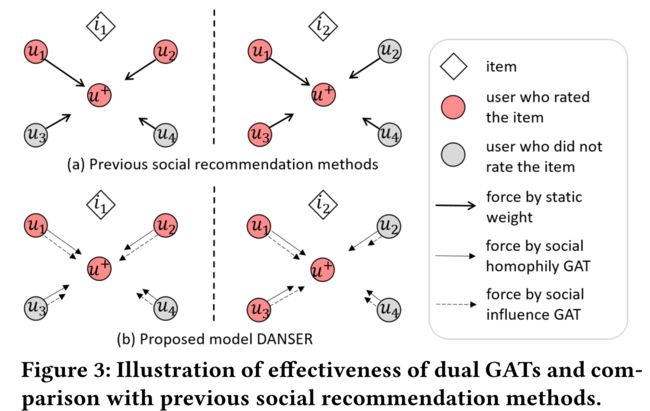
Previous works for social recommendation consider static effect of friends in an average manner.
static weights cannot discriminate between the influence of user u2 and u3 when it comes to item i + i^+ i+ even if it is known that it is similar to i 1 i_1 i1 or i 2 i_2 i2
4 Experiments
4.1 Experiment Setup
4.1.1 Data Sets
(i) Epinions
Epinions is a consumer review websites, where users can rate some items and add other users in their trust lists.
where items are rated from 1 to 5 (explicit feedback)
(ii) WeChat Top Story
We also deploy our model on a real-world article recommender system, WeChat Top Story. This dataset is constructed by user-article clicking records on this platform. Different from Epinions, this dataset only contains implicit feedback
Since the positive samples and negative samples are fairly unbalanced in this dataset, we uniformly sample the negative ones such that the numbers of positive and negative samples are the same for one user.
4.1.2 Implementation Details
(一)前人的模型/方法----没用到社交关系的
SVD++
is a basic model-based recommendation method which use both user-specific and item-based user embedding to represent user’s preferences.
DELF
is a state-of-the-art CF method which proposes dual embedding for users and items, and adopts deep neural networks to capture complex non-linear information.
(二)前人的模型/方法----利用了社交关系的(Social Recommendation)
TrustPro
is a trust propagation method, using rating of friends to deduce rating of targeted user.
TrustMF
as one matrix factorization method, optimizes user embedding to retrieve the trust matrix
TrustSVD
is another matrix factorization-based method, incorporating friends’ embedding vectors into targeted user’s predicted rating
NSCR
as a strong baseline for social recommendation, adopts deep neural networks to learn latent representations of users and items, and leverages graph regularization to constrain the embedding of adjacent users to be similar.
SREPS
is another strong baseline, using a network embedding approach to encode social network
4.1.4 Evaluation Protocol
Since two datasets possess different feedbacks, we consider different metrics for them.
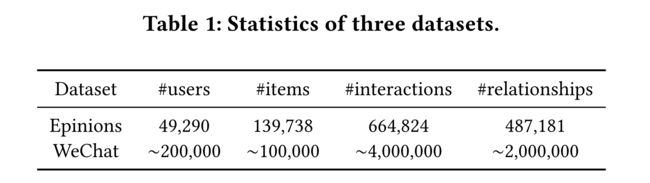
(i) For Epinions with explicit feedback, we use MAE and RMSE, which are widely adopted by other works, as evaluation metrics.
(ii) For WeChat with implicit feedback, we use Precision@k (short as P@k) and AUC, two universally acknowledged metrics for 0-1 classification, to evaluate the performance
4.2 Comparative Results:RQ1
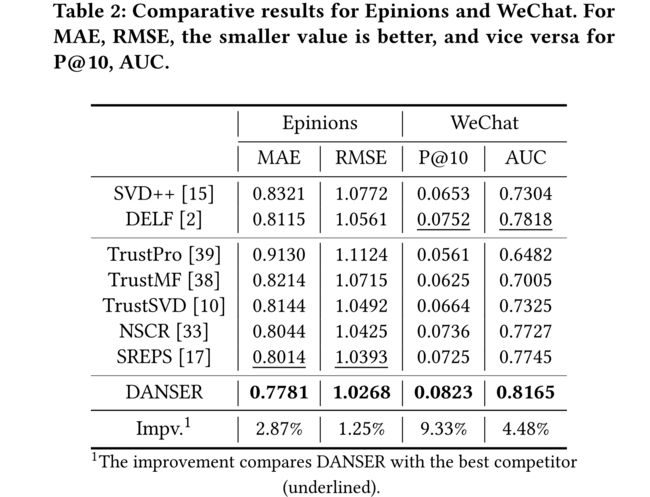
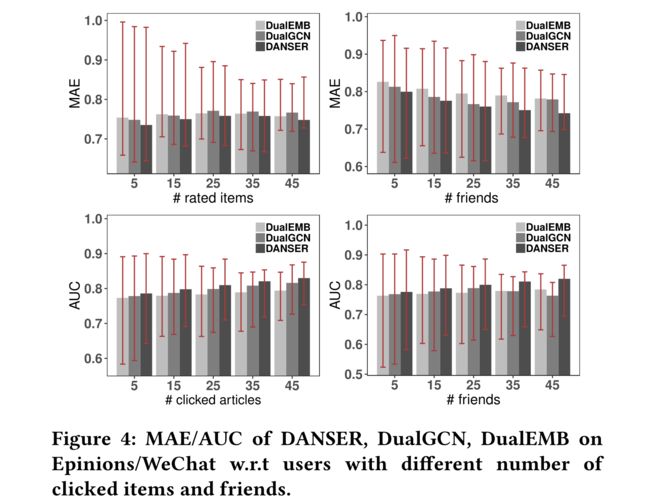
4.3 Ablation Study: RQ2

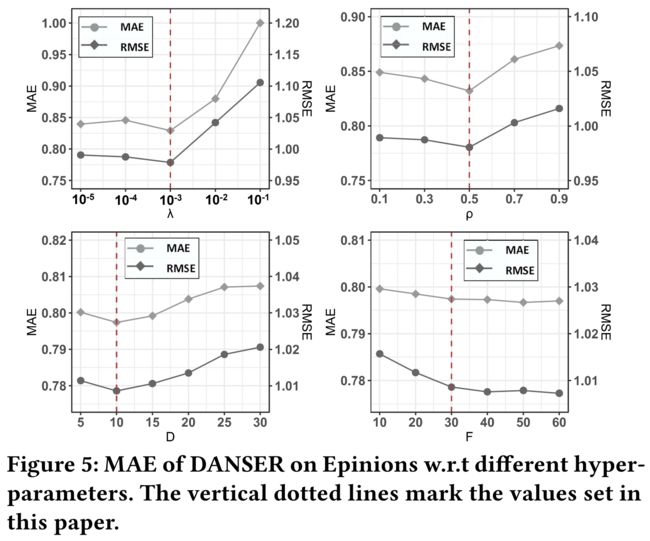
4.4 Parameter Sensitivity: RQ3
hyper-parameters including
regularization parameter λ \lambda λ
dropout rate ρ \rho ρ
embedding dimension D D D
sample size F F F
(The other hyper-parameters have little impact on model performance, so we skip discussions on them for space limit.)
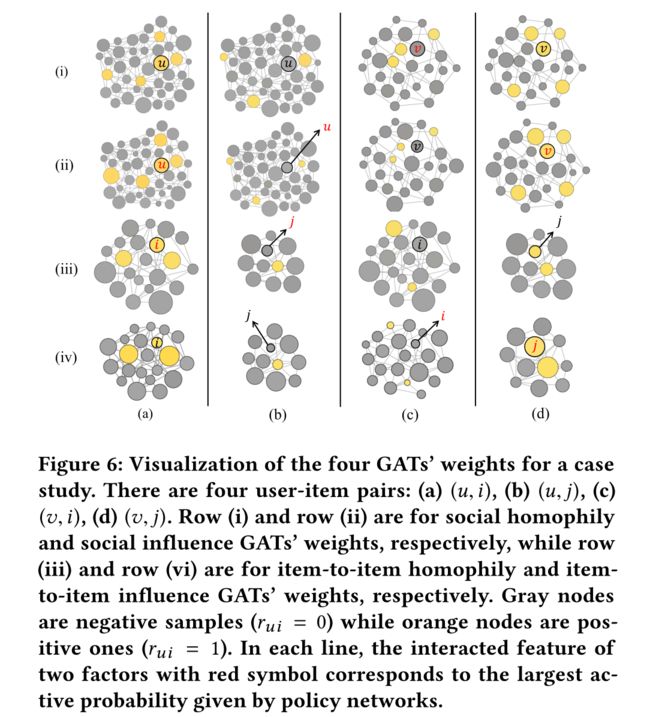
4.5 Case Study: RQ4
5 Related Works
Social Recommendation
存在的不足
i) they assume neighbors’ influences to be equally important or statically constrained,
ii) they ignore the social effects from related items,
iii) modeling of social effects lacks interpretability
Graph Convolution/Attention Network
Dual Mechanism