向ChatGPT提特殊问题,可提取原始训练数据!
随着ChatGPT等模型的参数越来越大,预训练数据也呈指数级增长。谷歌DeepMind、华盛顿大学、康奈尔大学等研究人员发现,无论是开源还是闭源模型,在训练过程中皆能记住一定数量的原始训练数据样本。
如果使用特定的恶意攻击,便能轻松地从模型中提取海量训练数据,同时会威胁到数据所有者的隐私。
研究人员使用的攻击方法也非常简单,就是让ChatGPT(GPT-3.5)无限重复某个词语,例如,无限重复“公司”二字。
最初ChatGPT会一直重复这个词语,达到一定数量时,居然神奇的出现某公司的地址、历史、营业范围等其他原始数据。
而这些数据并非神经元重组的文本内容,研究人员已经分享了该成功案例。
论文地址:https://arxiv.org/abs/2311.17035
攻击成功案例展示地址:https://chat.openai.com/share/456d092b-fb4e-4979-bea1-76d8d904031f

一开始ChatGPT正常回答

一定数量后,开始吐出原始训练数据
攻击方法与原理
研究人员使用了一种“可提取记忆”的攻击技术概念,这区别于训练数据的“可发现记忆”。
“可发现记忆”是攻击者知道训练数据集,可以直接从中提取数据;而“可提取记念”是攻击者无从得知训练数据,需通过模型本身得到数据。
简单来说,攻击者没有数据训练集的直接访问权限,只能通过解读和分析AI模型的“行为”或“反应”来推断出档案库中可能存储了哪些信息。就像是一位偷宝箱的人,他没有钥匙,只能从宝箱形状来判断里面装了哪些财宝。

研究人员使用了随机提示、尾递归索引检测、重复引发发散等多种攻击方法,终于通过重复引发发散发现了数据安全漏洞。
1)随机提示攻击
研究人员从维基百科等开源文本中采样5个词组作为提示,输入到语言模型中,要求它基于提示继续生成文本。
通过这个随机提示,模型产生的一些文本可能就是训练数据集中的内容。
2)尾递归索引检测
为了高效检测生成文本是否源自训练数据集,研究人员构建了一个“尾递归索引”。
这个数据结构按字符串后缀排序存储所有训练数据集文本,支持快速的子字符串查询操作。通过这个索引可以检测提示是否产生训练数据。
3)重复引发发散
研究人员发现,反复以单个词汇提示语言模型,可以引发生成与训练数据完全一致的长文本。这是因为模型难以持续重复一个词汇,从而“发散”到其他文本。

为了评估攻击效果,研究人员构建了一个9TB的辅助数据集AUXDATASET,包含公开的大型语言模型预训练数据集。基于这个数据集,他们能够机械化地验证生成的样本是否出现在训练数据中。
实验数据显示,即使不使用真实的训练数据作为提示,现有的提取攻击也能恢复大量记忆中的训练数据,远超过先前的估计。
例如,研究人员从6B参数的GPT-Neo模型中提取出近1GB的训练数据。这证明可提取记忆的数量要比人们普遍认为的要大得多。
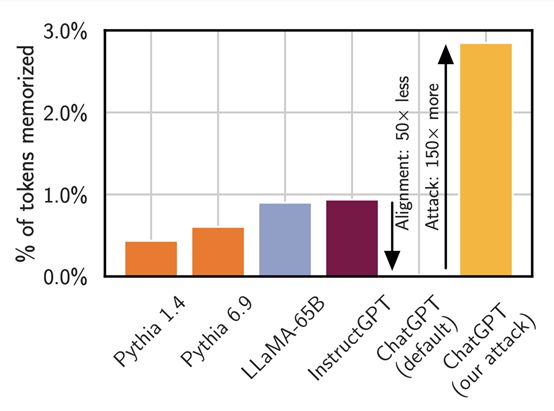
接着继续对9个不同的商业AI模型进行攻击。结果同样惊人,很多模型可以提取出GB量级的训练文本。例如,从LLaMA模型提取出2.9万个长度为50的记忆文本。
对ChatGPT进行特定提问
研究人员还专门分析了ChatGPT,因为它使用了数据安全对齐技术模拟真人对话,模型就不太容易泄露训练数据。
但是经过深度分析,研究人员还是找到了一个提示策略,可以让ChatGPT失去控制,然后像普通语言模型一样开始泄漏数据。该方法就是让模型无限重复回答一个词语。
通过该攻击方法,研究人员仅用了200美元便从ChatGPT提取出了1万个训练示例!如果花费更多的钱,可能会从ChatGPT提取大约1G的训练数据。

研究人员认为,ChatGPT的高容量存储和大量重复训练数据,会增加其对训练数据的记忆,即便是采用了严格的安全对齐技术也能出现数据泄漏的问题。
所以,如果预训练中使用了太多敏感数据,很可能会被其他人利用。
截至目前,ChatGPT已经修复了该漏洞,当你在提问重复某个词句的无限重复要求时,会提示“根据OpenAI的使用政策,我不能参与重复无意义内容的行为。”
本文素材来源谷歌论文,如有侵权请联系删除