elk7.10.2安装(vm版)
elk7.10.2分布式集群安装(centos7)
ELK安装
主机规划
192.168.31.101 cancer01 es master/es datanode/logstash
192.168.31.102 cancer02 es master/es datanode/logstash
192.168.31.103 cancer03 es master/es datanode/logstash/kibana
ES安装
下载
elasticsearch-7.10.2-linux-x86_64.tar.gz
logstash-7.10.2-linux-x86_64.tar.gz
kibana-7.10.2-linux-x86_64.tar.gz
elasticsearch-analysis-ik-7.10.2.zip
jdk-11.0.9_linux-x64_bin.rpm
环境准备
设置IP
在每台主机上设置IP
| 1、修改配置文件 # vim /etc/sysconfig/network-scripts/ifcfg-eth0(ifcfg-eth0为网卡名,不同主机可能名称不同) BOOTPROTO=static ONBOOT=yes IPADDR=192.168.31.101 NETMASK=255.255.255.0 GATEWAY=192.168.31.1 DNS1=192.168.31.1 DNS2=0.0.0.0 2、重启服务 # service network restart |
设置主机名
在每台主机上设置主机名
| 1、查看主机名 # hostnamectl 2、用命令修改 # hostnamectl set-hostname cancer01 (修改当前主机名) 3、修改配置文件 # vim /etc/hosts (每台主机hosts文件均为如下内容) 127.0.0.1 localhost 192.168.116.101 cancer01 192.168.116.102 cancer02 192.168.116.103 cancer03 4、重启主机 # reboot now |
关闭防火墙
在每台主机上关闭防火墙
| # systemctl stop firewalld.service centos7停止firewall # systemctl disable firewalld.service centos7禁止firewall开机启动 |
关闭selinux
在每台主机上关闭selinux
| # vim /etc/sysconfig/selinux selinux=disabled |
禁用透明大页
在每台主机上禁用Transparent Hugepage
| 查看状态 # cat /sys/kernel/mm/transparent_hugepage/enabled 返回结果 [always] madvise never 永久关闭 # vim /etc/rc.local if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi 或者直接运行下面命令: # echo never > /sys/kernel/mm/transparent_hugepage/enabled # echo never > /sys/kernel/mm/transparent_hugepage/defrag 重启机器 查看状态 # cat /sys/kernel/mm/transparent_hugepage/enabled 返回结果 always madvise [never] |
设置虚拟内存
在每台主机上设置最大虚拟内存区
| echo "vm.max_map_count=262144" > /etc/sysctl.conf 或者 sysctl -w vm.max_map_count=262144 > /etc/sysctl.conf sysctl -p
|
设置文件句柄数量和进程数量
在每台主机上设置文件句柄打开数量和进程数量
| 1、查看 最大打开文件句柄数和最大进程数 # ulimit -a 最大打开文件句柄数 #ulimit -n 最大进程数 #ulimit -u 2、查看应用进程打开文件句柄数 # lsof -n|awk '{print $2}'|sort|uniq -c|sort -nr|more 根据进程ID号来查看进程名 # ps aef|grep 24204 3、用户级限制修改 # vim /etc/security/limits.conf * soft nofile 65535 * hard nofile 65535 * soft nproc 32000 * hard nproc 32000 centos7修改用户进程数和文件描述符 soft nproc: 单个用户可用的最大进程数量(软限制) hard nproc:单个用户可用的最大进程数量(硬限制) soft nofile: 可打开的文件句柄的最大数(软限制) hard nofile: 可打开的文件句柄的最大数(硬限制) * : 代表所有用户,也可以写成你需要修改的用户名 4、系统级限制修改 # echo 6553560 > /proc/sys/fs/file-max (临时生效,重启机器后会失效) # vim /etc/sysctl.conf fs.file-max = 6553560 (永久生效) # reboot now |
主机时间同步
在每台主机上安装ntp时间同步插件
| 1.检查是否有时间同步的插件: # rpm -qa | grep ntp 2.没有就安装(每台都要安装): # yum -y install ntp ntpdate 3.选择一台服务器作为集群的时间服务器,主节点 比如:cancer01:时间服务器,cancer02、cancer03、cancer04、cancer05时间同步cancer01 4.修改主节点配置 #vim /etc/ntp.conf ## 1 同步网络时间地址 server 0.asia.pool.ntp.org server 1.asia.pool.ntp.org server 2.asia.pool.ntp.org server 3.asia.pool.ntp.org ## 2 当外部时间不可用,则使用当前硬件时间 server 127.127.1.0 iburst local lock ## 3 允许哪些网段的机器,来同步时间 restrict 192.168.31.0 mask 255.255.255.0 nomodify notrap ##注:1位置为修改原有的配置,2,3位置的新增加的,其余原有文件配置保持不动 5.修改从节点配置 #vim /etc/ntp.conf ## 客户端节点配置同步时间的主节点,表示向主节点cancer01同步时间 server cancer01 prefer server 127.127.1.0 fudge 127.127.1.0 stratum 10 #vim /etc/ntp/step-tickers cancer01 6.重启所有节点ntp服务,并设置开机启动 #systemctl restart ntpd #systemctl enable ntpd 7.在从节点从主节点同步时间 #ntpdate -u cancer01 8.从节点设置定时任务 #crontab -e ## follow time from master host 0 * * * * ntpdate -u cdh01 ## write system time to hardware time 1 * * * * hwclock –systohc ## 同步时间后,还需把同步到的时间写入机器硬件时间,命令为 hwclock --systohc ## 或者 ## 每10分钟同步一次时间 0-59/10 * * * * /sbin/service ntpd stop 0-59/10 * * * * /usr/sbin/ntpdate -u node1 0-59/10 * * * * /sbin/service ntpd start |
配置免密
在每台主机上配置ssh免密
| # ssh-keygen -t rsa 然后三次回车,运行结束会在~/.ssh下生成两个新文件: id_rsa.pub和id_rsa就是公钥和私钥 然后也是在每台主机上都执行: # ssh-copy-id cancer01 # ssh-copy-id cancer02 # ssh-copy-id cancer03 |
安装JDK
elasticsearch要求jdk为11.
在每台主机上安装jdk
| 下载jdk-11.0.9_linux-x64_bin.rpm,使用rz命令上传。 1、安装前,最好先删除Linux自带的OpenJDK: (1)运行java -version,会发现Linux自带的OpenJDK,运行rpm -qa | grep jdk,找出自带的OpenJDK名称; (2)运行rpm -e --nodeps OpenJDK名称,删除OpenJDK; 2、运行rpm -ivh jdk-11.0.9_linux-x64_bin.rpm 或者yum localinstall jdk-11.0.9_linux-x64_bin.rpm 3、运行vim /etc/profile,在文件末尾输入以下几行: export JAVA_HOME=/usr/java/jdk-11.0.9 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin 4、运行source /etc/profile,使文件生效; 5、运行java -version,查看返回结果。 |
添加用户
在每台主机上添加用户es,elasticsearch需要使用非root用户启动
| # groupadd es # useradd -g es es # passwd es |
授权sudo
在每台主机上给es用户授权sudo
| # vim /etc/sudoers es ALL=(ALL) ALL |
安装ES
先在cancer01上安装配置,完成后拷贝到其他主机
解压缩
tar -zxvf elasticsearch-7.10.0-linux-x86_64.tar.gz -C /usr/local/
mv /usr/local/elasticsearch-7.10.2 /usr/local/elasticsearch
cd /usr/local/elasticsearch
mkdir data
mkdir logs
设置属主
chown -R es.es /usr/local/elasticsearch
设置环境变量
| vim /etc/profile export ES_HOME=/usr/local/elasticsearch export PATH=$PATH:$ES_HOME/bin source /etc/profile |
配置ES
| vim /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elk node.name: cancer01 node.master: true node.data: true network.host: 0.0.0.0 http.port: 9200 path.data: /usr/local/elasticsearch/data path.logs: /usr/local/elasticsearch/logs
discovery.seed_hosts: - cancer01 - cancer02 - cancer03 cluster.initial_master_nodes: ["cancer01", "cancer02", "cancer03"] |
参数说明
cluster.name 集群名称,各节点配成相同的集群名称。
node.name 节点名称,各节点配置不同。
node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
network.host 绑定节点IP。
http.port 监听端口。
path.data 数据存储目录。
path.logs 日志存储目录。
discovery.seed_hosts 指定集群成员,用于主动发现他们,所有成员都要写进来,包括自己,每个节点中应该写一样的信息。
cluster.initial_master_nodes 指定有资格成为 master 的节点
http.cors.enabled 用于允许head插件访问ES。
http.cors.allow-origin 允许的源地址。
当您为提供自定义设置时 network.host,Elasticsearch会假设您正在从开发模式过渡到生产模式,并将许多系统启动检查从警告升级到异常。
cluster.initial_master_nodes 中的节点名称需要和 node.name 的名称一致。
#开启安全访问
xpack.security.enabled: true
#跨域访问设置
http.cors.enabled: true
http.cors.allow-origin: "*"
#ca设置
xpack.security.transport.ssl.enabled: true #开启ssl加密传输
xpack.security.transport.ssl.verification_mode: certificate #开启加密传输验证
xpack.security.transport.ssl.keystore.path: /usr/local/elasticsearch/elastic-certificates.p12 #秘钥 需要预先创建
xpack.security.transport.ssl.truststore.path: /usr/local/elasticsearch/elastic-certificates.p12
#忽略ca验证设置
xpack.security.transport.ssl.verification_mode: none #加密传输验证关闭
xpack.security.http.ssl.client_authentication: none #关闭秘钥验证
xpack.http.ssl.verification_mode: none #关闭秘钥验证,此处很多文档写的不一样,可能是版本变化,亲测此方法最有效。
transport.tcp.port: 9300
transport.tcp.compress: true
network.publish_host: cancer01 ##本机IP
配置log
| vim /usr/local/elasticsearch/config/log4j2.properties appender.rolling.strategy.action.condition.nested_condition.type = IfLastModified appender.rolling.strategy.action.condition.nested_condition.age = 30D |
限制集群日志增长,这里只保存30天的日志
默认会每天rolling一个文件,当到达2G的时候,才开始清除超出的部分,当一个文件只有几十K的时候,文件会一直累计下来。
配置jvm
| vim /usr/local/elasticsearch/config/jvm.options -Xms2g -Xmx2g
-XX:HeapDumpPath=data
|
说明:
Xmx和Xms两个设置必须彼此相等,大小应该不超过你物理内存的50%,最大不要超过 32G, 通常 26G是可以的。
HeapDumpPath是内存不足异常上的堆转储到默认数据目录。
拷贝到其他主机
| scp -r /usr/local/elasticsearch es@cancer02:/usr/local/ scp -r /usr/local/elasticsearch es@cancer03:/usr/local/ |
配置其他主机
在cancer02、cancer03主机上,设置属主
| chown -R es.es /usr/local/elasticsearch |
在cancer02、cancer03主机上,设置环境变量
| vim /etc/profile export ES_HOME=/usr/local/elasticsearch export PATH=$PATH:$ES_HOME/bin source /etc/profile |
在cancer02主机上,配置ES
| vim /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elk node.name: cancer02 node.data: true network.host: 0.0.0.0 http.port: 9200
discovery.seed_hosts: - cancer01 - cancer02:9300 - cancer03 cluster.initial_master_nodes: ["cancer01", "cancer02", "cancer03"] |
在cancer03主机上,配置ES
| vim /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elk node.name: cancer03 node.data: true network.host: 0.0.0.0 http.port: 9200
discovery.seed_hosts: - cancer01 - cancer02:9300 - cancer03 cluster.initial_master_nodes: ["cancer01", "cancer02", "cancer03"] |
启动ES
在每台主机上启动elasticsearch,
| su - es cd /usr/local/elasticsearch ./bin/elasticsearch -d -p /tmp/elasticsearch.pid |
-d 后台运行
-p 指定一个文件,用于存放进程的 pid
关闭ES
pkill -F /tmp/elasticsearch.pid
验证
查看日志,$ES_HOME/logs/
ls logs/elk.log
查看集群健康状态
curl -X GET "localhost:9200/_cat/health?v" 或者 http://localhost:9200/_cluster/health?pretty
三种不同状态的含义
黄色 如果您仅运行单个Elasticsearch实例,则集群状态将保持黄色。单节点群集具有完整的功能,但是无法将数据复制到另一个节点以提供弹性。
绿色 副本分片必须可用,群集状态为绿色。
红色 如果群集状态为红色,则某些数据不可用。
查看集群节点信息
curl -X GET "localhost:9200/_cat/nodes?v"
排查错误
| # 找到进程 [es@cancer01 elasticsearch]$ jdk/bin/jps 8244 Jps 7526 Elasticsearch
# 杀死进程 [es@cancer01 elasticsearch]$ kill -9 7526
# 删除数据目录中的所有文件 [es@cancer01 elasticsearch]$ rm -rf data/*
# 删除 keystore 文件 [es@cancer01 elasticsearch]$ rm -rf config/elasticsearch.keystore
# 重新启动进程 [es@cancer01 elasticsearch]$ bin/elasticsearch -d -p /tmp/elk.pid |
Logstash安装
Kibana安装
Kafka安装
Filebeat安装
ELK案例
1. 需求分析
确认需要收集的日志类型及使用的相关插件
系统日志: /var/log/* (可以使用 input 的 syslog 插件)
访问日志: Apache/Nginx/Tomcat 等的访问日志( 使用 input 的 file/json 等插件,filter 的 grok 插件)
错误日志: error log、Java 日志 (使用访问日志类似的插件,Java 的日志需要使用 codec 多行插件)
运行日志: 程序自己生成的 (使用 input 的 file/json 等插件)
网络日志: 防火墙、交换机、路由器等的日志 (可以使用 input 的 syslog 插件)
2. 日志标准化
2.1 日志放置目录及命名规范
规范日志放置目录和命名 ,以下是一个示例参考:
[root@linux-node1 logs]# tree /data/logs
/data/logs
├── access-log # 访问日志目录
├── error-log # 错误日志目录
└── runtime-log # 运行日志目录
2.2 日志切割
对于不同程序,有的程序可以自定义日志切割,有的可能需要自己编写脚本来进行日志切割。
日志文件切割时间可以按天、按小时等,这个需要根据实际业务的日志情况来确定。
2.3 日志接入格式标准
我们可以规定,如果要接入 ELK 日志系统,程序日志格式应该是 JSON 格式,方便日志的统一接收。
这个和研发去协商,为了实现 DevOps,研发和运维应该相互配合,如果日志格式不是 JSON,我们可以不接收。
2.4 原始日志文件删除和归档策略
比如可以将本地原始日志文件 rsync 到一个共享存储文件系统后,然后删除本地最近 7 天前的日志文件。 这个也是根据具体业务的日志情况来制定。
如果业务一天能产生海量日志,那么可能就要删除最近一天前的日志。
3. 工具化
如何使用 Logstash 等 Agent 工具进行日志收集。 需要规划好方案和画好架构图。
ES介绍
ELK是三个开源软件的缩写,分别为:Elasticsearch 、 Logstash以及Kibana , 它们都是开源软件。不过现在还新增了一个Beats,它是一个轻量级的日志收集处理工具(Agent),Beats占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具,目前由于原本的ELK Stack成员中加入了 Beats 工具所以已改名为Elastic Stack。早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。目前Beats包含六种工具:
Packetbeat: 网络数据(收集网络流量数据)
Metricbeat: 指标 (收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
Filebeat: 日志文件(收集文件数据)
Winlogbeat: windows事件日志(收集 Windows 事件日志数据)
Auditbeat:审计数据 (收集审计日志)
Heartbeat:运行时间监控 (收集系统运行时的数据)
0 架构概览

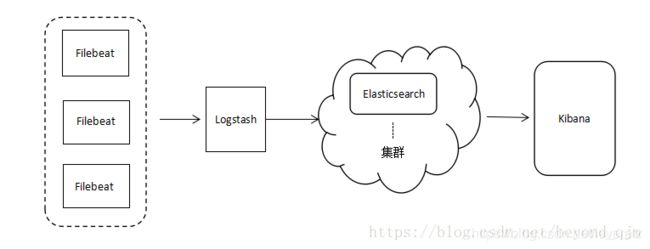
ELK日志分析系统
Elasticsearch:存储,索引池
Logstash:日志收集器
Kibana:数据可视化
日志处理步骤
1,将日志进行集中化管理
2,将日志格式化(Logstash)并输出到Elasticsearch
3,对格式化后的数据进行索引和存储(Elasticsearch)
4,前端数据的展示(Kibana)
Elasticsearch的概述
提供了一个分布式多用户能力的全文搜索引擎
Elasticsearch的概念
接近实时
集群
节点
索引:索引(库)-->类型(表)-->文档(记录)
分片和副本
Logstash介绍
一款强大的数据处理工具,可以实现数据传输、格式处理、格式化输出
数据输入、数据加工(如过滤,改写等)以及数据输出
LogStash主要组件
Shipper
Indexer
Broker
Search and Storage
Web Interface
Kibana介绍
一个针对Elasticsearch的开源分析及可视化平台
搜索、查看存储在Elasticsearch索引中的数据
通过各种图表进行高级数据分析及展示
Kibana主要功能
Elasticsearch无缝之集成
整合数据,复杂数据分析
让更多团队成员受益
接口灵活,分享更容易
配置简单,可视化多数据源
简单数据导出
1 集群条件
集群最少 3 个节点, 集群的每个节点都需要使用非 root 用户启动。
2 Elasticsearch 基本概念介绍
2.1 文档


2.2 文档源数据

_all 字段在7.0版本中已被废除
_version 为了解决在大量并发写入时候文档冲突问题
_score 用于标识在一次查询结果中某条数据和希望查询到的目标的相似度
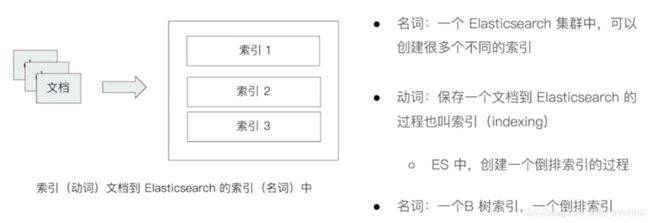
2.3 索引

索引在不同环境下的语义
2.4 Type
在 7.0 之前,一个 Index 可以设置多个 Types
7.0 开始一个索引只能建立一个 Type: _doc
2.5 和RDBMS的比较

2.6 增删改查
要增删改查 Elasticsearch 的中数据,需要使用 REST API
3 集群的基本概念
3.1 集群的特性
Elasticsearch 集群是一个多节点组成的高可用可扩展的分布式系统

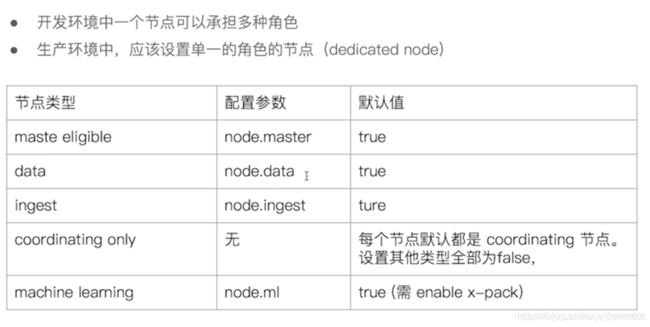
3.2 集群中的节点角色
Master-eligible Node 和 Master Node

Date Node 和 Coordinating Node
3.3 设置节点角色的建议
4 分片
4.1 主分片和副本

分片分布示例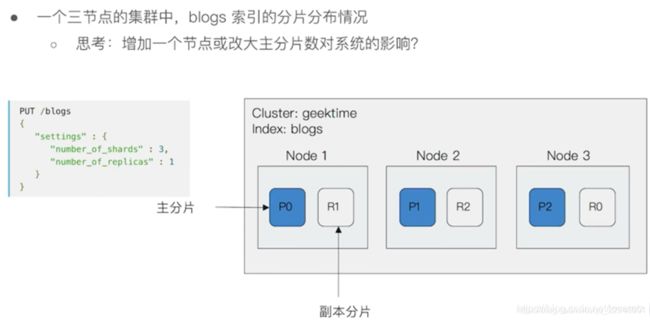
4.2 分片的设定
主分片是在一开始建立索引时候设置的,后期无法更改
生产中要做好数据容量规划。
分片过少
后期如果数量量不断增多,也无法通过增加节点来实现水平扩展
也会导致单个分片存储数据量过多,在以后数据重新分配时耗时。
分片过多
假如长期分片过多,会影响查询结果的相关性打分,从而影响查询结果的准确性
单节点上存放过多的分片会造成资源的浪费,也会影响性能
Logstash介绍
Logstash是一款强大的数据处理工具,它可以实现数据传输,格式处理,格式化输出,还有强大的插件功能,常用于日志处理。
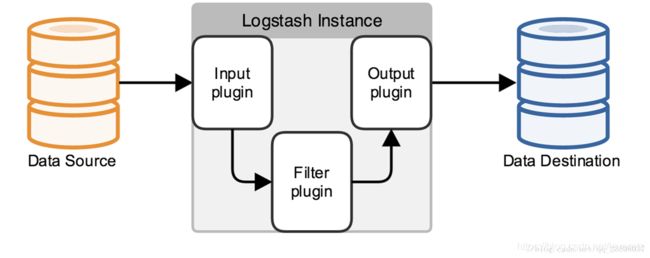
Logstash工作的三个阶段:
input数据输入端,可以接收来自任何地方的源数据。
* file:从文件中读取
* syslog:监听在514端口的系统日志信息,并解析成RFC3164格式。
* redis:从redis-server list中获取
* beat:接收来自Filebeat的事件
Filter数据中转层,主要进行格式处理,数据类型转换、数据过滤、字段添加,修改等,常用的过滤器如下。
* grok:通过正则解析和结构化任何文本。Grok目前是logstash最好的方式对非结构化日志数据解析成结构化和可查询化。logstash内置了120个匹配模式,满足大部分需求。
* mutate:在事件字段执行一般的转换。可以重命名、删除、替换和修改事件字段。
* drop:完全丢弃事件,如debug事件。
* clone:复制事件,可能添加或者删除字段。
* geoip:添加有关IP地址地理位置信息。
output是logstash工作的最后一个阶段,负责将数据输出到指定位置,兼容大多数应用,常用的有:
* elasticsearch:发送事件数据到Elasticsearch,便于查询,分析,绘图。
* file:将事件数据写入到磁盘文件上。
* mongodb:将事件数据发送至高性能NoSQL mongodb,便于永久存储,查询,分析,大数据分片。
* redis:将数据发送至redis-server,常用于中间层暂时缓存。
* graphite:发送事件数据到graphite。http://graphite.wikidot.com/
* statsd:发送事件数据到statsd。
input
我们今天先讨论input组件的功能和基本插件。前面我们意见介绍过了,input组件是Logstash的眼睛和鼻子,负责收集数据的,那么们就不得不思考两个问题,第一个问题要清楚的就是,元数据在哪,当然,这就包含了元数据是什么类型,属于什么业务;第二个问题要清楚怎么去拿到元数据。只要搞明白了这两个问题,那么Logstash的input组件就算是弄明白了。
对于第一个问题,元数据的类型有很多,比如说你的元数据可以是日志、报表、可以是数据库的内容等等。元数据是什么样子的我们不需要关心,我们要关系的是元数据是什么类型的,只要你知道元数据是什么类型的,你才能给他分类,或者说给他一个type,这很重要,type对于你后面的工作处理是非常有帮助的。所以第一个问题的重心元数据在吗,是什么,现在已经是清楚了。那么进行第二个问题。
第二个问题的核心是怎么拿到这些不同类型的原数据?这是一个真个input组件的核心内容了,我们分门别类的来看待这和解决个问题。
首先,我们肯定需要认同的,什么样的数据源,就需要使用什么样的方式去获取数据。
我们列举几种:
1、文件类型:文件类型,顾名思义,文件数据源,我们可以使用input组件的file插件来获取数据。file{}插件有很多的属性参数,我们可以张开讲解一下。
input{
file{
#path属性接受的参数是一个数组,其含义是标明需要读取的文件位置
path => [‘pathA’,‘pathB’]
#表示多就去path路径下查看是够有新的文件产生。默认是15秒检查一次。
discover_interval => 15
#排除那些文件,也就是不去读取那些文件
exclude => [‘fileName1’,‘fileNmae2’]
#被监听的文件多久没更新后断开连接不在监听,默认是一个小时。
close_older => 3600
#在每次检查文件列表的时候,如果一个文件的最后修改时间超过这个值,就忽略这个文件。默认一天。
ignore_older => 86400
#logstash 每隔多久检查一次被监听文件状态( 是否有更新),默认是1秒。
stat_interval => 1
#sincedb记录数据上一次的读取位置的一个index
sincedb_path => ’$HOME/. sincedb‘
#logstash 从什么 位置开始读取文件数据, 默认是结束位置 也可以设置为:beginning 从头开始
start_position => ‘beginning’
#注意:如果你需要每次都从同开始读取文件的话,关设置start_position => beginning是没有用的,你可以选择sincedb_path 定义为 /dev/null
}
}
2、数据库类型:数据库类型的数据源,就意味着我们需要去和数据库打交道了是吗?是的!那是必须的啊,不然怎么获取数据呢。input组件如何获取数据库类的数据呢?没错,下面即将隆重登场的是input组件的JDBC插件jdbc{}。同样的,jdbc{}有很多的属性,我们在下面的代码中作出说明;
input{
jdbc{
#jdbc sql server 驱动,各个数据库都有对应的驱动,需自己下载
jdbc_driver_library => "/etc/logstash/driver.d/sqljdbc_2.0/enu/sqljdbc4.jar"
#jdbc class 不同数据库有不同的 class 配置
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
#配置数据库连接 ip 和端口,以及数据库
jdbc_connection_string => "jdbc:sqlserver://200.200.0.18:1433;databaseName=test_db"
#配置数据库用户名
jdbc_user =>
#配置数据库密码
jdbc_password =>
#上面这些都不重要,要是这些都看不懂的话,你的老板估计要考虑换人了。重要的是接下来的内容。
# 定时器 多久执行一次SQL,默认是一分钟
# schedule => 分 时 天 月 年
# schedule => * 22 * * * 表示每天22点执行一次
schedule => "* * * * *"
#是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => false
#是否需要记录某个column 的值,如果 record_last_run 为真,可以自定义我们需要表的字段名称,
#此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => true
#如果 use_column_value 为真,需配置此参数. 这个参数就是数据库给出的一个字段名称。当然该字段必须是递增的,可以是 数据库的数据时间这类的
tracking_column => create_time
#是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => true
#们只需要在 SQL 语句中 WHERE MY_ID > :last_sql_value 即可. 其中 :last_sql_value 取得就是该文件中的值
last_run_metadata_path => "/etc/logstash/run_metadata.d/my_info"
#是否将字段名称转小写。
#这里有个小的提示,如果你这前就处理过一次数据,并且在Kibana中有对应的搜索需求的话,还是改为true,
#因为默认是true,并且Kibana是大小写区分的。准确的说应该是ES大小写区分
lowercase_column_names => false
#你的SQL的位置,当然,你的SQL也可以直接写在这里。
#statement => SELECT * FROM tabeName t WHERE t.creat_time > :last_sql_value
statement_filepath => "/etc/logstash/statement_file.d/my_info.sql"
#数据类型,标明你属于那一方势力。单了ES哪里好给你安排不同的山头。
type => "my_info"
}
#注意:外载的SQL文件就是一个文本文件就可以了,还有需要注意的是,一个jdbc{}插件就只能处理一个SQL语句,
#如果你有多个SQL需要处理的话,只能在重新建立一个jdbc{}插件。
}
好了,废话不多说了,接着第三种情况:
input {
beats {
#接受数据端口
port => 5044
#数据类型
type => "logs"
}
#这个插件需要和filebeat进行配很这里不做多讲,到时候结合起来一起介绍。
}
现在我们基本清楚的知道了input组件需要做的事情和如何去做,当然他还有很多的插件可以进行数据的收集,比如说TCP这类的,还有可以对数据进行encode,这些感兴趣的朋友可以自己去查看,我说的只是我自己使用的。一般情况下我说的三种插件已经足够了。
filter
Logstash三个组件的第二个组件,也是真个Logstash工具中最复杂,最蛋疼的一个组件,当然,也是最有作用的一个组件。
1、grok插件 grok插件有非常强大的功能,他能匹配一切数据,但是他的性能和对资源的损耗同样让人诟病。
filter{
grok{
#只说一个match属性,他的作用是从message 字段中吧时间给抠出来,并且赋值给另个一个字段logdate。
#首先要说明的是,所有文本数据都是在Logstash的message字段中中的,我们要在过滤器里操作的数据就是message。
#第二点需要明白的是grok插件是一个十分耗费资源的插件,这也是为什么我只打算讲解一个TIMESTAMP_ISO8601正则表达式的原因。
#第三点需要明白的是,grok有超级多的预装正则表达式,这里是没办法完全搞定的,也许你可以从这个大神的文章中找到你需要的表达式
#http://blog.csdn.net/liukuan73/article/details/52318243
#但是,我还是不建议使用它,因为他完全可以用别的插件代替,当然,对于时间这个属性来说,grok是非常便利的。
match => ['message','%{TIMESTAMP_ISO8601:logdate}']
}
}
2、mutate插件 mutate插件是用来处理数据的格式的,你可以选择处理你的时间格式,或者你想把一个字符串变为数字类型(当然需要合法),同样的你也可以返回去做。可以设置的转换类型 包括: "integer", "float" 和 "string"。
filter {
mutate {
#接收一个数组,其形式为value,type
#需要注意的是,你的数据在转型的时候要合法,你总是不能把一个‘abc’的字符串转换为123的。
convert => [
#把request_time的值装换为浮点型
"request_time", "float",
#costTime的值转换为整型
"costTime", "integer"
]
}
}
3、ruby插件 官方对ruby插件的介绍是——无所不能。ruby插件可以使用任何的ruby语法,无论是逻辑判断,条件语句,循环语句,还是对字符串的操作,对EVENT对象的操作,都是极其得心应手的。
filter {
ruby {
#ruby插件有两个属性,一个init 还有一个code
#init属性是用来初始化字段的,你可以在这里初始化一个字段,无论是什么类型的都可以,这个字段只是在ruby{}作用域里面生效。
#这里我初始化了一个名为field的hash字段。可以在下面的coed属性里面使用。
init => [field={}]
#code属性使用两个冒号进行标识,你的所有ruby语法都可以在里面进行。
#下面我对一段数据进行处理。
#首先,我需要在把message字段里面的值拿到,并且对值进行分割按照“|”。这样分割出来的是一个数组(ruby的字符创处理)。
#第二步,我需要循环数组判断其值是否是我需要的数据(ruby条件语法、循环结构)
#第三步,我需要吧我需要的字段添加进入EVEVT对象。
#第四步,选取一个值,进行MD5加密
#什么是event对象?event就是Logstash对象,你可以在ruby插件的code属性里面操作他,可以添加属性字段,可以删除可以修改,同样可以进行树脂运算。
#进行MD5加密的时候,需要引入对应的包。
#最后把冗余的message字段去除。
code => "
array=event。get('message').split('|')
array.each do |value|
if value.include? 'MD5_VALUE'
then
require 'digest/md5'
md5=Digest::MD5.hexdigest(value)
event.set('md5',md5)
end
if value.include? 'DEFAULT_VALUE'
then
event.set('value',value)
end
end
remove_field=>"message"
"
}
}
4、date插件 这里需要合前面的grok插件剥离出来的值logdate配合使用(当然也许你不是用grok去做)。
filter{
date{
#还记得grok插件剥离出来的字段logdate吗?就是在这里使用的。你可以格式化为你需要的样子,至于是什么样子。就得你自己取看啦。
#为什什么要格式化?
#对于老数据来说这非常重要,应为你需要修改@timestamp字段的值,如果你不修改,你保存进ES的时间就是系统但前时间(+0时区)
#单你格式化以后,就可以通过target属性来指定到@timestamp,这样你的数据的时间就会是准确的,这对以你以后图表的建设来说万分重要。
#最后,logdate这个字段,已经没有任何价值了,所以我们顺手可以吧这个字段从event对象中移除。
match=>["logdate","dd/MMM/yyyy:HH:mm:ss Z"]
target=>"@timestamp"
remove_field => 'logdate'
#还需要强调的是,@timestamp字段的值,你是不可以随便修改的,最好就按照你数据的某一个时间点来使用,
#如果是日志,就使用grok把时间抠出来,如果是数据库,就指定一个字段的值来格式化,比如说:"timeat", "%{TIMESTAMP_ISO8601:logdate}"
#timeat就是我的数据库的一个关于时间的字段。
#如果没有这个字段的话,千万不要试着去修改它。
}
}
5、json插件,这个插件也是极其好用的一个插件,现在我们的日志信息,基本都是由固定的样式组成的,我们可以使用json插件对其进行解析,并且得到每个字段对应的值。
filter{
#source指定你的哪个值是json数据。
json {
source => "value"
}
#注意:如果你的json数据是多层的,那么解析出来的数据在多层结里是一个数组,你可以使用ruby语法对他进行操作,最终把所有数据都装换为平级的。
}
json插件还是需要注意一下使用的方法的,下图就是多层结构的弊端:
对应的解决方案为:
ruby{
code=>"
kv=event.get('content')[0]
kv.each do |k,v|
event.set(k,v)
end"
remove_field => ['content','value','receiptNo','channelId','status']
}
Logstash filter组件的插件基本介绍到这里了,这里需要明白的是:
add_field、remove_field、add_tag、remove_tag 是所有 Logstash 插件都有。相关使用反法看字段名就可以知道。不如你也试试吧。
output
Logstash的output模块,相比于input模块来说是一个输出模块,output模块集成了大量的输出插件,可以输出到指定文件,也可输出到指定的网络端口,当然也可以输出数据到ES.在这里我只介绍如何输出到ES,至于如何输出到端口和指定文件,有很多的文档资料可查找.
elasticsearch{
hosts=>["172.132.12.3:9200"]
action=>"index"
index=>"indextemplate-logstash"
#document_type=>"%{@type}"
document_id=>"ignore"
template=>"/opt/logstash-conf/es-template.json"
template_name=>"es-template.json"
template_overwrite=>true
}
action=>”index” #es要执行的动作 index, delete, create, update
index:将logstash.时间索引到一个文档
delete:根据id删除一个document(这个动作需要一个id)
create:建立一个索引document,如果id存在 动作失败.
update:根据id更新一个document,有一种特殊情况可以upsert--如果document不是已经存在的情况更新document 。参见upsert选项。
A sprintf style string to change the action based on the content of the event. The value %{[foo]} would use the foo field for the action
document_id=>” ” 为索引提供document id ,对重写elasticsearch中相同id词目很有用
document_type=>” ”事件要被写入的document type,一般要将相似事件写入同一type,可用%{}引用事件type,默认type=log
index=>”logstash-%{+YYYY,MM.dd}” 事件要被写进的索引,可是动态的用%{foo}语句
hosts=>[“127.0.0.0”] ["127.0.0.1:9200","127.0.0.2:9200"] "https://127.0.0.1:9200"
manage_template=>true 一个默认的es mapping 模板将启用(除非设置为false 用自己的template)
template=>”” 有效的filepath 设置自己的template文件路径,不设置就用已有的
template_name=>”logstash” 在es内部模板的名字
这里需要十分注意的一个问题是,document_id尽量保证值得唯一,这样会解决你面即将面临的ES数据重复问题,切记切记!
配置实例(日志到ES)
编辑nginx配置文件,修改以下内容(在http模块下添加)
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domian":"$host",'
'"host":"$server_addr",'
'"size":"$body_bytes_sent",'
'"responsetime":"$request_time",'
'"referer":"$http_referer",'
'"ua":"$http_user_agent"'
'}';
修改access_log的输出格式为刚才定义的json
access_log logs/elk.access.log json;
继续修改apache的配置文件
LogFormat "{ \
\"@timestamp\": \"%{%Y-%m-%dT%H:%M:%S%z}t\", \
\"@version\": \"1\", \
\"tags\":[\"apache\"], \
\"message\": \"%h %l %u %t \\\"%r\\\" %>s %b\", \
\"clientip\": \"%a\", \
\"duration\": %D, \
\"status\": %>s, \
\"request\": \"%U%q\", \
\"urlpath\": \"%U\", \
\"urlquery\": \"%q\", \
\"bytes\": %B, \
\"method\": \"%m\", \
\"site\": \"%{Host}i\", \
\"referer\": \"%{Referer}i\", \
\"useragent\": \"%{User-agent}i\" \
}" ls_apache_json
一样修改输出格式为上面定义的json格式
CustomLog logs/access_log ls_apache_json
编辑logstash配置文件,进行日志收集(由于MySQL的慢日志查询格式比较特殊,所以需要用正则进行匹配,并使用multiline能够进行多行匹配(看具体配置))
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
file {
path => "/var/log/secure"
type => "secure"
start_position => "beginning"
}
file {
path => "/var/log/httpd/access_log"
type => "http"
start_position => "beginning"
}
file {
path => "/usr/local/nginx/logs/elk.access.log"
type => "nginx"
start_position => "beginning"
}
file {
path => "/var/log/mysql/mysql.slow.log"
type => "mysql"
start_position => "beginning"
codec => multiline {
pattern => "^# User@Host:"
negate => true
what => "previous"
}
}
redis {
host => "192.168.1.202"
port => "6379"
password => 'test'
type => "redis"
db => '1'
data_type => "list"
key => 'elk-test'
batch_count => 1 #这个值是指从队列中读取数据时,一次性取出多少条,默认125条(如果redis中没有125条,就会报错,所以在测试期间加上这个值)
}
}
filter {
grok {
match => { "message" => "SELECT SLEEP" }
add_tag => [ "sleep_drop" ]
tag_on_failure => []
}
if "sleep_drop" in [tags] {
drop {}
}
grok {
match => { "message" => "(?m)^# User@Host: %{USER:User}\[[^\]]+\] @ (?:(?
}
date {
match => [ "timestamp", "UNIX" ]
remove_field => [ "timestamp" ]
}
}
output {
if [type] == "system" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-system-%{+YYYY.MM.dd}"
}
}
if [type] == "secure" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-secure-%{+YYYY.MM.dd}"
}
}
if [type] == "http" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-http-%{+YYYY.MM.dd}"
}
}
if [type] == "nginx" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-nginx-%{+YYYY.MM.dd}"
}
}
if [type] == "mysql" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-mysql-slow-%{+YYYY.MM.dd}"
}
}
if [type] == "redis" {
elasticsearch {
hosts => ['192.168.1.202:9200']
index => 'redis-test-%{+YYYY.MM.dd}'
}
}
}
配置实例(日志到Redis)
input {
file {
path => "/var/log/httpd/access_log"
type => "http"
start_position => "beginning"
}
file {
path => "/usr/local/nginx/logs/elk.access.log"
type => "nginx"
start_position => "beginning"
}
file {
path => "/var/log/secure"
type => "secure"
start_position => "beginning"
}
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
if [type] == "http" {
redis {
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_http'
}
}
if [type] == "nginx" {
redis {
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_nginx'
}
}
if [type] == "secure" {
redis {
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_secure'
}
}
if [type] == "system" {
redis {
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_system'
}
}
}
配置实例(Redis到ES)
input {
redis {
type => "system"
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_system'
batch_count => 1
}
redis {
type => "http"
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_http'
batch_count => 1
}
redis {
type => "nginx"
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_nginx'
batch_count => 1
}
redis {
type => "secure"
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_secure'
batch_count => 1
}
}
output {
if [type] == "system" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-system-%{+YYYY.MM.dd}"
}
}
if [type] == "http" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-http-%{+YYYY.MM.dd}"
}
}
if [type] == "nginx" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-nginx-%{+YYYY.MM.dd}"
}
}
if [type] == "secure" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-secure-%{+YYYY.MM.dd}"
}
}
}