Elasticsearch学习心得及常见问题
目录
- 1.Elasticsearch和elasticsearch-headr跨域问题
- 2.Elasticsearch的插件ik分词器
- 3.ElasticSearch的核心概念
-
- 1.分片
- 2.倒排索引(重点,数据库可能会问)
- 3.基本Rest命令说明
- 4.Spring boot集成ElasticSearch
- ES 基础一网打尽
1.1 ES定义
ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.2 Lucene与ES关系?
1)Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
2)Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.3 ES主要解决问题:
1)检索相关数据;
2)返回统计结果;
3)速度要快。
1.4 ELK是什么?
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示
1.Elasticsearch和elasticsearch-headr跨域问题
首先保证两者启动成功

然后需要在elasticsearch的config中找到elasticsearch的配置文件

添加两行配置,重启Elasticsearch即可。

ElasticSearch和Solr的比较总结
- es基本是开箱即用(解压就可以使用) 非常简单 Solr安装略微复杂一丢丢
- Solr利用Zookeeper进行分布式管理,而ElasticSearch 自身带有分布式协调管理功能
- Solr支持更多格式的数据,比如JSON、XML、CSV,而ElasticSearch仅支持json文件格式
- Solr光放提供的功能更多,而ElasticSearch本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
- Solr 查询快,但更新索引慢(插入删除慢),用于电商等查询多的应用
- ES建立索引快(查询慢),即实时性查询快,用于facebook、新浪等搜索
- Solr是传统搜索应用的有力解决方案,但ElasticSearch更适用于新兴的实时搜索应用
2.Elasticsearch的插件ik分词器
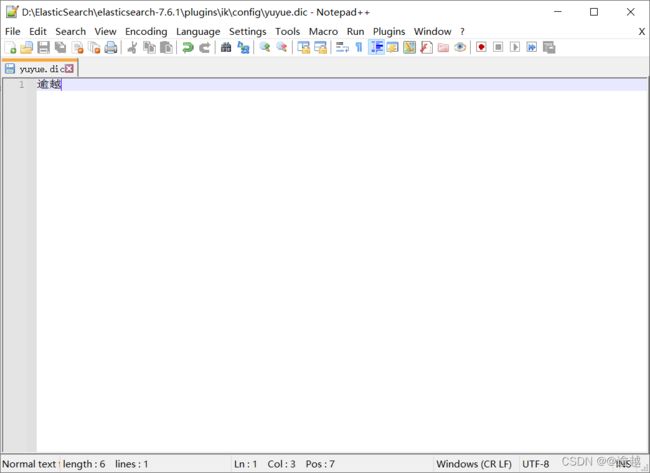
引入ik插件后,如何自定义自己的字典(用来分隔词)
在ik的config创建一个后缀名为dic的文件,输入自己的分词。
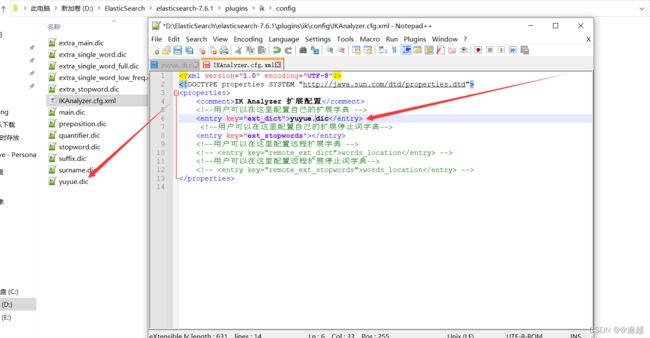
将写好的分词字典引入IKAnalyzer.cfg.xml中
3.ElasticSearch的核心概念
- 索引
- 字段类型(mapping)
- 文档(documents)
- 分片(倒排索引)
对于初学者就可以把ElasticSearch看作为数据库
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables)) | types |
| 行(row) | documents |
| 字段(columns) | fields |
1.分片
一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的有个5个分片( primary shard ,又称主分片)构成的,每一个主分片会有一个副本( replica shard ,又称复制分片)

上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字
2.倒排索引(重点,数据库可能会问)
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层,一个elasticsearch索引是由多个Lucene索引组成的。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。将文档分解为单个词 根据词的出现的权重,返回相应的文档。
3.基本Rest命令说明

特别注意keyword类型。是指不可分割类型,不会被分词器解析。还有一些分页查询,布尔值查询,过滤器,精确查询,多个值匹配的精确查询,高亮查询。
4.Spring boot集成ElasticSearch
引入依赖
版本号一定要和你下载的Elasticsearch版本号一致
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.6.2version>
dependency>
根据官方文档创建配置类
package com.yue.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
@Component
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")));
return client;
}
}
测试所需要的方法,例如 crud,批处理等
@SpringBootTest
class YueEsApiApplicationTests {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
@Test
void contextLoads() {
}
//测试索引的创建 Request PUT kuang_index
@Test
void testCreateIndex() throws IOException {
//1. 创建索引请求
CreateIndexRequest request = new CreateIndexRequest("yue_index");
//2. 客户端执行创建请求 IndicesClient 请求后获得响应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
//测试获取索引 判断其是否存在
@Test
void testExists() throws IOException {
GetIndexRequest request = new GetIndexRequest("yue_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
//测试删除索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("yue_index");
//删除
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
//测试添加文档
@Test
void testAddDocument() throws IOException {
//创建对象
User user = new User("aa", 3);
//创建请求
IndexRequest request = new IndexRequest("yue_index");
//规则 put /kuang_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
//将我们的数据放入请求 json
request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求,获取响应的结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
//对应我们命令返回的状态 CREATED
System.out.println(indexResponse.status());
}
//获取文档,判断是否存在
@Test
void testIsExists() throws IOException {
GetRequest request = new GetRequest("yue_index", "1");
//不获取返回的 _source 的上下文了
request.fetchSourceContext(new FetchSourceContext(false));
request.storedFields("_none_");
boolean exists = client.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
//获得文档的信息
@Test
void testGetDocument() throws IOException {
GetRequest request = new GetRequest("yue_index", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//打印文档的内容
System.out.println(response.getSourceAsString());
//返回的全部内容和命令是一样的
System.out.println(response);
}
//更新文档的信息
@Test
void testUpdateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("yue_index", "1");
request.timeout("1s");
User user = new User("狂神说Java", 18);
request.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse updateResponse = client.update(request, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
//删除文档的记录
@Test
void testdeleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("yue_index", "1");
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
//特殊的,真实项目一般都会批量插入数据
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
List<User> list = new ArrayList<>();
list.add(new User("k1", 3));
list.add(new User("k2", 3));
list.add(new User("k3", 3));
list.add(new User("g1", 3));
list.add(new User("g2", 3));
list.add(new User("g3", 3));
//批处理请求
for (int i = 0; i < list.size(); i++) {
// 批量更新和批量删除,就在这里修改对应请求就可以了
bulkRequest.add(new IndexRequest("yue_index")
.id("" + (i + 1))
.source(JSON.toJSONString(list.get(i)), XContentType.JSON)
);
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
//是否失败 ,返回 false 表示成功
System.out.println(bulkResponse.hasFailures());
}
//查询
//SearchRequest 搜索请求
//SearchSourceBuilder 条件构造
//HighlightBuilder 构建高亮
//TermQueryBuilder 精确查询
//MatchAllQueryBuilder
//xxx QueryBuilder 对应我们刚才看到的命令
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("yue_index");
//构建搜索的条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件,我们可以使用QueryBuilders工具类来实现
//QueryBuilders.termQuery 精确
//QueryBuilders.matchAllQuery() 匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "q1");
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(termQueryBuilder);
sourceBuilder.from();
sourceBuilder.size();
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
System.out.println("===================");
for (SearchHit searchHit : searchResponse.getHits().getHits()) {
System.out.println(searchHit.getSourceAsMap());
}
}
}
本博客学自狂神说