【深度学习】注意力机制(五)
本文介绍一些注意力机制的实现,包括CSRA/Spatial Shift/Triplet Attention/Coordinate Attention/ACmix。
【深度学习】注意力机制(一)
【深度学习】注意力机制(二)
【深度学习】注意力机制(三)
【深度学习】注意力机制(四)
目录
一、CSRA(class-specific residual attention)
二、Spatial Shift
三、Triplet Attention
四、Coordinate Attention
五、ACmix
一、CSRA(class-specific residual attention)
一种新颖的head,论文地址:Residual Attention: A Simple but Effective Method for Multi-Label Recognition
如下图:
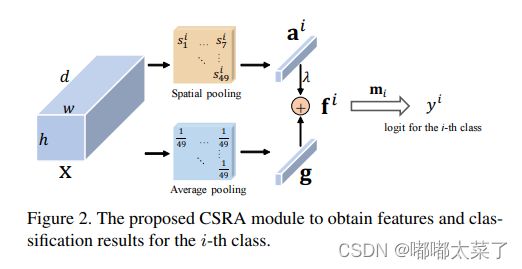
代码如下(代码地址):
import torch
import torch.nn as nn
class CSRA(nn.Module): # one basic block
def __init__(self, input_dim, num_classes, T, lam):
super(CSRA, self).__init__()
self.T = T # temperature
self.lam = lam # Lambda
self.head = nn.Conv2d(input_dim, num_classes, 1, bias=False)
self.softmax = nn.Softmax(dim=2)
def forward(self, x):
# x (B d H W)
# normalize classifier
# score (B C HxW)
score = self.head(x) / torch.norm(self.head.weight, dim=1, keepdim=True).transpose(0,1)
score = score.flatten(2)
base_logit = torch.mean(score, dim=2)
if self.T == 99: # max-pooling
att_logit = torch.max(score, dim=2)[0]
else:
score_soft = self.softmax(score * self.T)
att_logit = torch.sum(score * score_soft, dim=2)
return base_logit + self.lam * att_logit
class MHA(nn.Module): # multi-head attention
temp_settings = { # softmax temperature settings
1: [1],
2: [1, 99],
4: [1, 2, 4, 99],
6: [1, 2, 3, 4, 5, 99],
8: [1, 2, 3, 4, 5, 6, 7, 99]
}
def __init__(self, num_heads, lam, input_dim, num_classes):
super(MHA, self).__init__()
self.temp_list = self.temp_settings[num_heads]
self.multi_head = nn.ModuleList([
CSRA(input_dim, num_classes, self.temp_list[i], lam)
for i in range(num_heads)
])
def forward(self, x):
logit = 0.
for head in self.multi_head:
logit += head(x)
return logit二、Spatial Shift
论文地址:S 2 -MLPV2: IMPROVED SPATIAL-SHIFT MLP ARCHITECTURE FOR VISION
如下图:

代码如下(代码来源):
import torch
from torch import nn
from einops.layers.torch import Reduce
from .utils import pair
class PreNormResidual(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = nn.LayerNorm(dim)
def forward(self, x):
return self.fn(self.norm(x)) + x
def spatial_shift1(x):
b,w,h,c = x.size()
x[:,1:,:,:c//4] = x[:,:w-1,:,:c//4]
x[:,:w-1,:,c//4:c//2] = x[:,1:,:,c//4:c//2]
x[:,:,1:,c//2:c*3//4] = x[:,:,:h-1,c//2:c*3//4]
x[:,:,:h-1,3*c//4:] = x[:,:,1:,3*c//4:]
return x
def spatial_shift2(x):
b,w,h,c = x.size()
x[:,:,1:,:c//4] = x[:,:,:h-1,:c//4]
x[:,:,:h-1,c//4:c//2] = x[:,:,1:,c//4:c//2]
x[:,1:,:,c//2:c*3//4] = x[:,:w-1,:,c//2:c*3//4]
x[:,:w-1,:,3*c//4:] = x[:,1:,:,3*c//4:]
return x
class SplitAttention(nn.Module):
def __init__(self, channel = 512, k = 3):
super().__init__()
self.channel = channel
self.k = k
self.mlp1 = nn.Linear(channel, channel, bias = False)
self.gelu = nn.GELU()
self.mlp2 = nn.Linear(channel, channel * k, bias = False)
self.softmax = nn.Softmax(1)
def forward(self,x_all):
b, k, h, w, c = x_all.shape
x_all = x_all.reshape(b, k, -1, c) #bs,k,n,c
a = torch.sum(torch.sum(x_all, 1), 1) #bs,c
hat_a = self.mlp2(self.gelu(self.mlp1(a))) #bs,kc
hat_a = hat_a.reshape(b, self.k, c) #bs,k,c
bar_a = self.softmax(hat_a) #bs,k,c
attention = bar_a.unsqueeze(-2) # #bs,k,1,c
out = attention * x_all # #bs,k,n,c
out = torch.sum(out, 1).reshape(b, h, w, c)
return out
class S2Attention(nn.Module):
def __init__(self, channels=512):
super().__init__()
self.mlp1 = nn.Linear(channels, channels * 3)
self.mlp2 = nn.Linear(channels, channels)
self.split_attention = SplitAttention(channels)
def forward(self, x):
b, h, w, c = x.size()
x = self.mlp1(x)
x1 = spatial_shift1(x[:,:,:,:c])
x2 = spatial_shift2(x[:,:,:,c:c*2])
x3 = x[:,:,:,c*2:]
x_all = torch.stack([x1, x2, x3], 1)
a = self.split_attention(x_all)
x = self.mlp2(a)
return x
class S2Block(nn.Module):
def __init__(self, d_model, depth, expansion_factor = 4, dropout = 0.):
super().__init__()
self.model = nn.Sequential(
*[nn.Sequential(
PreNormResidual(d_model, S2Attention(d_model)),
PreNormResidual(d_model, nn.Sequential(
nn.Linear(d_model, d_model * expansion_factor),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(d_model * expansion_factor, d_model),
nn.Dropout(dropout)
))
) for _ in range(depth)]
)
def forward(self, x):
x = x.permute(0, 2, 3, 1)
x = self.model(x)
x = x.permute(0, 3, 1, 2)
return x
class S2MLPv2(nn.Module):
def __init__(
self,
image_size=224,
patch_size=[7, 2],
in_channels=3,
num_classes=1000,
d_model=[192, 384],
depth=[4, 14],
expansion_factor = [3, 3],
):
image_size = pair(image_size)
oldps = [1, 1]
for ps in patch_size:
ps = pair(ps)
assert (image_size[0] % (ps[0] * oldps[0])) == 0, 'image must be divisible by patch size'
assert (image_size[1] % (ps[1] * oldps[1])) == 0, 'image must be divisible by patch size'
oldps[0] = oldps[0] * ps[0]
oldps[1] = oldps[1] * ps[1]
assert (len(patch_size) == len(depth) == len(d_model) == len(expansion_factor)), 'patch_size/depth/d_model/expansion_factor must be a list'
super().__init__()
self.stage = len(patch_size)
self.stages = nn.Sequential(
*[nn.Sequential(
nn.Conv2d(in_channels if i == 0 else d_model[i - 1], d_model[i], kernel_size=patch_size[i], stride=patch_size[i]),
S2Block(d_model[i], depth[i], expansion_factor[i], dropout = 0.)
) for i in range(self.stage)]
)
self.mlp_head = nn.Sequential(
Reduce('b c h w -> b c', 'mean'),
nn.Linear(d_model[-1], num_classes)
)
def forward(self, x):
embedding = self.stages(x)
out = self.mlp_head(embedding)
return out三、Triplet Attention
论文地址:Rotate to Attend: Convolutional Triplet Attention Module
如下图:

代码如下(代码来源):
import torch
import torch.nn as nn
class BasicConv(nn.Module):
def __init__(
self,
in_planes,
out_planes,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
relu=True,
bn=True,
bias=False,
):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(
in_planes,
out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
self.bn = (
nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True)
if bn
else None
)
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ZPool(nn.Module):
def forward(self, x):
return torch.cat(
(torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1
)
class AttentionGate(nn.Module):
def __init__(self):
super(AttentionGate, self).__init__()
kernel_size = 7
self.compress = ZPool()
self.conv = BasicConv(
2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2, relu=False
)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.conv(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, no_spatial=False):
super(TripletAttention, self).__init__()
self.cw = AttentionGate()
self.hc = AttentionGate()
self.no_spatial = no_spatial
if not no_spatial:
self.hw = AttentionGate()
def forward(self, x):
x_perm1 = x.permute(0, 2, 1, 3).contiguous()
x_out1 = self.cw(x_perm1)
x_out11 = x_out1.permute(0, 2, 1, 3).contiguous()
x_perm2 = x.permute(0, 3, 2, 1).contiguous()
x_out2 = self.hc(x_perm2)
x_out21 = x_out2.permute(0, 3, 2, 1).contiguous()
if not self.no_spatial:
x_out = self.hw(x)
x_out = 1 / 3 * (x_out + x_out11 + x_out21)
else:
x_out = 1 / 2 * (x_out11 + x_out21)
return x_out四、Coordinate Attention
论文地址:Coordinate Attention for Efficient Mobile Network Design
如下图:
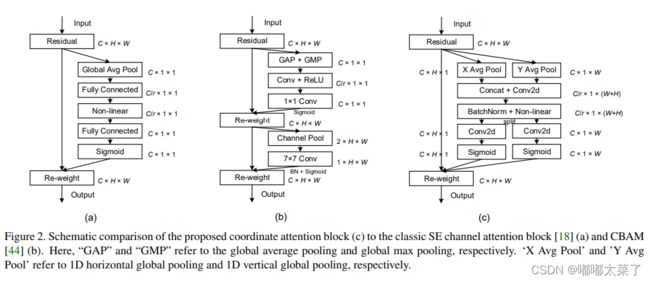
代码如下(代码来源):
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out五、ACmix
ACmix拥有卷积和Self-attention的优势,论文地址:On the Integration of Self-Attention and Convolution
如下图:
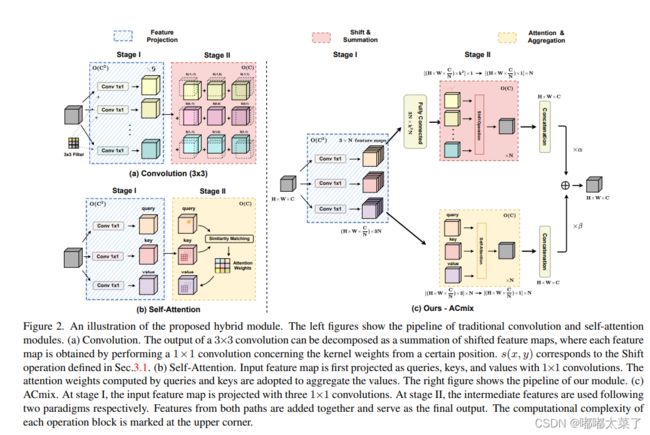
代码如下(代码来源):
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
def position(H, W, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3*self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes, kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1, stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i//self.kernel_conv, i%self.kernel_conv] = 1.
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h//self.stride, w//self.stride
# ### att
# ## positional encoding
pe = self.conv_p(position(h, w, x.is_cuda))
q_att = q.view(b*self.head, self.head_dim, h, w) * scaling
k_att = k.view(b*self.head, self.head_dim, h, w)
v_att = v.view(b*self.head, self.head_dim, h, w)
if self.stride > 1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # 1, head_dim, k_att^2, h_out, w_out
att = (q_att.unsqueeze(2)*(unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
## conv
f_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h*w), k.view(b, self.head, self.head_dim, h*w), v.view(b, self.head, self.head_dim, h*w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv