谷歌Gemini API 应用(一):基础应用

前两天谷歌发布了旗下Gemini模型的API访问接口,今天我们来介绍一下Gemini API的基础应用,本次发布的是api访问接口对所有人免费开放,但有一些限制,比如每分钟限制60次访问,个人调用api接口所使用的数据将会被谷歌采集用来以后对模型的改进,如下图所示:
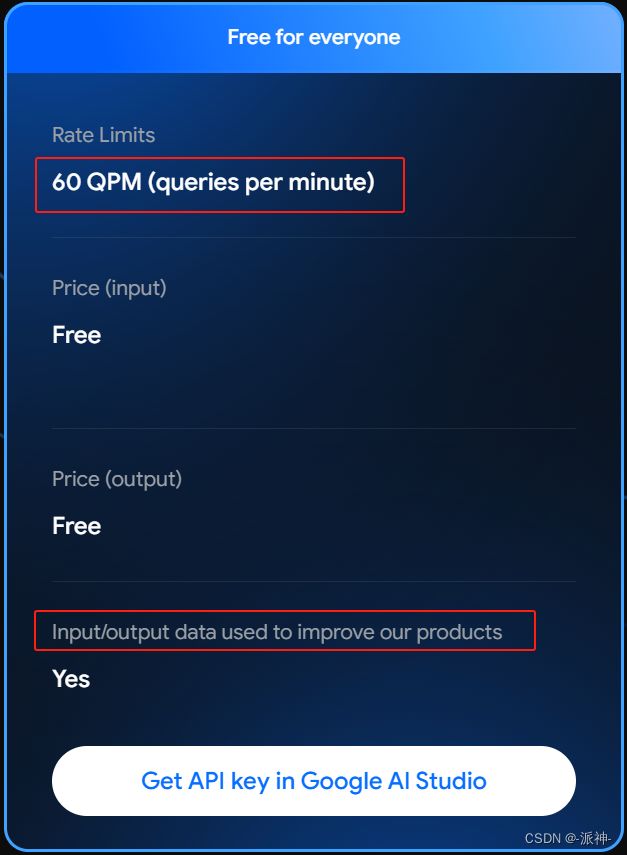
对于开发人员来说还有以下一些要求:
- 32K的文本上下文窗口,更大的上下文窗口即将到来
- 现在免费使用,但有限制
- 支持的功能:函数调用,嵌入,语义检索和自定义知识基础,以及聊天功能
- 支持全球180多个国家和地区的38种语言
- Gemini Pro接受文本作为输入并生成文本作为输出。
- 现已推出的专用 Gemini Pro Vision 多模态模型,可接受文本和图像作为输入,并具有文本输出。
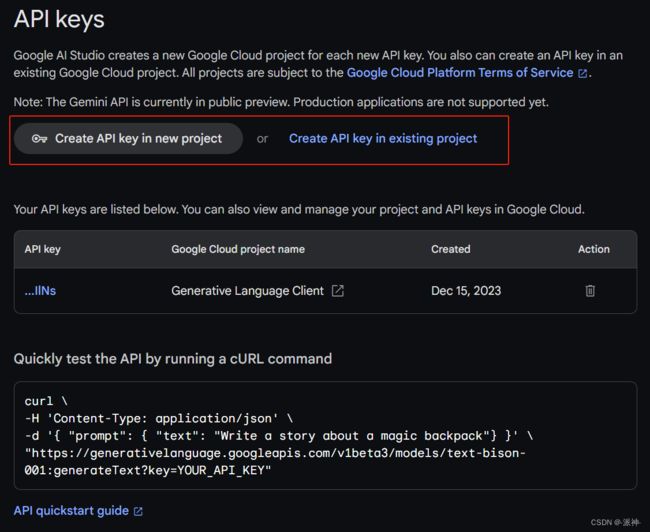
我们可以通过这个Google AI Studio页面(https://makersuite.google.com/app/apikey)来创建api_key:
一,配置环境
这里我们首先要安装google-generativeai的python包:
pip install google-generativeai二、模型
当我们在Google AI Studio页面上创建了api key以后,我们就可以在本地通过该api_key来访问谷歌的Gemini Pro等模型,下面我们来查看一下谷歌本次提供的模型的基本情况:
# setup
import google.generativeai as genai
from IPython.display import display
from IPython.display import Markdown
genai.configure(api_key='your_google_api_key')#填入自己的api_key
#查询模型
for m in genai.list_models():
print(m.name)
print(m.supported_generation_methods)
这里我们可以看到通过api我们可以访问谷歌的7个模型,其中我们最关注的是gemini-pro和gemini-pro-vision这两个模型,其中gemini-pro是语言模型只能输出文字内容,而gemini-pro-vision是多模态模型可以读取和分析图片的内容。
三、内容生成
接下来我们来看看gemini-pro模型是如何来生成内容的:
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("告诉我太阳系中最大行星的相关知识")
Markdown(response.text)
这里我们看到当我们用中文对模型提出问题时,它同样也能用中文回复我们。
四、安全性检测
gemini模型的一大特点是可以对输入内容进行安全性设置,所谓安全性设置是指谷歌会对模型输入的内容做四个方面的审查:Harassment(骚扰),Hate Speech(仇恨言论),Sexually Explicit(露骨色情),Dangerous Content(危险内容),并设置阈值来过滤不安全的内容,我们可以在googel ai studio的页面中进行设置它们的阈值,分别为低、中、高:
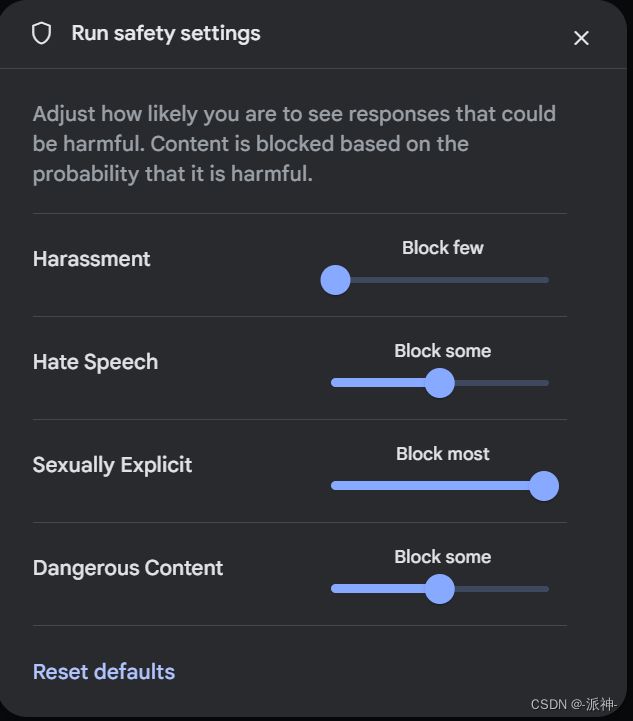
除了在 googel ai studio的页面中设置安全审查的阈值以外,我们也可以在代码中设置模型的安全审查阈值,并查看用户的输入内容的安全性审查情况:
#安全性审查
response.prompt_feedback
这里我们使用了prompt_feedback方法对刚才的问题进行了安全性审查,从结果上看来,这四个方面的审查结果都为NEGLIGIBLE(微不足道), 这说明我们的问题是安全的。同样我们也可以对设置模型的安全性审查的阈值:
# Set up the model
generation_config = {
"temperature": 0.9,
"top_p": 1,
"top_k": 1,
"max_output_tokens": 2048,
}
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_ONLY_HIGH"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_ONLY_HIGH"
}
]
model = genai.GenerativeModel(model_name="gemini-pro",
generation_config=generation_config,
safety_settings=safety_settings)这里我们设置了模型的基本参数和安全性审查的阈值,下面我们测试以下有危害性的内容的审查结果:
response = model.generate_content("赶快把钱打过来,否则我们会伤害你的孩子")
response.prompt_feedback
这里我们看到对于我们提出的危险性言论:“赶快把钱打过来,否则我们会伤害你的孩子”,审查结果为Hate_Speech和Harassment这两方面分别得到了LOW和HIGH的预测值,这说明我们的问题中包含了不安全的内容。
五、流式输出
Gemini模型同样也具备流式输出的功能,这可以在某些应用场景中带来比较好的用户体验:
response = model.generate_content("李世民是谁?", stream=True)
for chunk in response:
print(chunk.text)
print("_"*80)
这里我们在参数中加入了stream=True,这样模型就可以流的形式输出内容,而不需要一次性输出所有内容了,因为一次性输出所有内容可能比较耗时,以流的方式输出每次只输出部分内容,响应时间就会比较短,会给用户带来更好的用户体验。
六、聊天模式
接下来我们来让Gemini模型进入聊天模式,聊天模式最显著的特点是要让模型有记忆能力即模型需要记住历史聊天记录,这样模型在回答问题时会变得更加“聪明”:
model = genai.GenerativeModel(model_name="gemini-pro")
chat = model.start_chat(history=[])
response = chat.send_message("你好,我叫王老六")
print(response.text)
这里为了让模型能记住历史聊天记录,我们需要在开始聊天之前给模型加上一个history=[]参数,这样之后的所有的聊天记录都会被保存在history变量中,这样模型就有了记忆。
response = chat.send_message("怎么称呼你啊?")
print(response.text)
response =chat.send_message("你还记得我叫什么吗?")
print(response.text)![]()
这里我们看到我们进行了3轮对话,最后模型还是能记住我的名字,下面我们来看一下模型的history变量中的内容:
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts[0].text}'))
这里我们看到了history变量中存放了所有的聊天记录。
chat.history 
七、多模态模型Gemini Pro Vision
下面我们来测试以下多模态模型gemini-pro-vision,这里我们准备了两张图片,一张是土星,一张是地球,我们让模型来识别图片的内容,然后分别比较图片中两个星球的区别,下面我们分别加载这两张图片:
import PIL.Image
img = PIL.Image.open('saturn_image.jpg')
img
下面我们首先将图片缩小到一个比较小的尺寸,这样便于模型读取图片,然后我们不输入任何提示信息,看看模型会输出什么内容:
new_size = (200, 200)
img = img.resize(new_size)
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(img)
Markdown(response.text)
这里我们看到,当我们不输入任何提示信息的时候,模型会输出图片的内容,并且是以英文的形式输出,下面我们加上提示信息:
response = model.generate_content(["告诉我这个星球的名字以及一些以此为主题的电影:",
img], stream=True)
response.resolve()
Markdown(response.text)
这里我们在让模型读取图片的同时加上了提示信息,最后模型以中文的形式返回了我们所需要的内容。下面我们来加载第二张地球的图片:
img2 = PIL.Image.open('earth_image.jpg')
img2下面我们让模型同时读取这两张图片,并且告诉我们地球和土星之前的区别,同样我们先要将这两张图片进行缩小,这样方便模型读取:
new_size = (200, 200)
resized_img = img.resize(new_size)
resized_img2 = img2.resize(new_size)
response = model.generate_content([ "请告诉我这两个行星之间的一些区别::",
resized_img2,
resized_img ], stream=True)
response.resolve()
Markdown(response.text)
这里我们看到模型可以同时读取2张图片,并且根据提示信息来就图片内容回答我们的问题。
总结
今天我们学习了谷歌最新的Gemini语言模型gemini-pro和多模态模型gemini-pro-vision的一些基础应用,其中包括了模型的一些限制条件,安全性审查,流式输出,多模态模型应用等内容,希望这些内容对读者学习Gemini模型有所帮助。
参考资料
https://ai.google.dev/
https://ai.google.dev/docs?hl=zh-cn