3-D Scene Graph: A Sparse and SemanticRepresentation of Physical Environmentsfor Intelligent Agent
摘要
智能体在执行给定任务之前收集信息并感知环境中的语义。智能体以环境模型的形式存储收集到的信息,环境模型紧凑地表示周围环境。然而,如果没有高效且有效的环境模型,智能体只能执行有限的任务。因此,这样的环境模型对于智能体的自治系统起着至关重要的作用。我们声称多功能环境模型具有以下特征:准确性、适用性、可用性和可扩展性。尽管许多研究人员尝试开发这种在一定程度上精确表示环境的模型,但它们缺乏广泛的适用性、直观的可用性和令人满意的可扩展性。为了解决这些限制,我们提出 3D 场景图作为环境模型和 3D 场景图构建框架。简洁且广泛使用的图结构很容易保证3D场景图的可用性和可扩展性。我们通过展示 3D 场景图在实际应用中的部署来证明 3D 场景图的准确性和适用性。此外,我们通过在各种条件下进行一系列综合实验来验证所提出的 3D 场景图和框架的性能。
介绍
理解周围环境的能力是智能体成功完成给定任务的关键因素之一[1]。如果没有这种能力,智能体只能执行简单且有限的任务。为了实现多功能性能,智能体不仅必须感知环境的物理属性,还必须感知环境中固有的语义信息。在观察环境和存储收集到的信息的过程中,智能体构建环境模型,该模型紧凑地表示周围的空间[2]。此类模型包括由 SLAM [3] 生成的密集地图以及由计算机视觉和自然语言处理 (NLP) 算法生成的场景描述 [4]。环境模型让智能体计划如何执行给定的任务,并为推理和推理提供依据。因此,智能体的有效环境模型非常重要。
我们声称以下属性是智能体的有效环境模型。 1)准确性:模型应精确地描绘环境并为智能体提供正确的信息。 2)适用性:智能体应该能够利用该模型执行各种类型的任务,而不仅仅是一项特定任务。 3)可用性:模型不应要求复杂的使用过程,而是为应用程序提供直观的用户界面。 4)可扩展性:模型应该能够描述大尺度和小尺度的环境,并逐步增加覆盖范围。
环境模型所声称的属性增强了智能体的自主性。智能体可以在构建模型的过程中收集有关环境的正确信息(准确性),利用模型轻松地完成环境中的各种任务(适用性),并扩展模型的知识环境增量(可扩展性)。
在本文中,我们定义了3D场景图,它以稀疏和语义的方式表示物理环境,并提出了3D场景图构建框架。所提出的 3D 场景图通过将环境抽象为图来紧凑地描述环境,其中节点描述对象,边描述对象对之间的关系。由于所提出的 3D 场景图以稀疏的方式说明环境,因此该图可以覆盖广泛的物理空间,从而保证了可扩展性。即使智能体必须处理广泛的环境或在中间遇到新环境,3D 场景图也提供了访问和更新环境模型的快速方法。此外,3D场景图的简洁结构确保了直观的可用性。图结构很简单,因为3D场景图遵循常见图结构的约定,并且由于其广泛使用,图结构已经为大多数研究人员所熟悉。接下来,我们通过演示两个主要应用来验证 3D 场景图的适用性:1)视觉问答(VQA)和 2)任务规划。这两种应用正在计算机视觉 [5]、NLP [6] 和机器人协会 [7] 中进行积极的研究。
所提出的 3D 场景图构建框架在生成 3D 场景图的过程中提取环境中的相关语义,例如对象类别和对象之间的关系以及物理属性,例如 3D 位置和主要颜色。该框架接收 RGB-D 图像帧形式的一系列观察结果。为了获得鲁棒的性能,该框架使用提出的自适应模糊图像拒绝(ABIR)算法过滤掉不稳定的观察结果(即模糊图像)。然后,该框架分解出关键帧组,以避免对相同信息进行冗余处理。关键帧组包含合理重叠的帧。接下来,该框架通过识别模块提取环境中的语义和物理属性。在识别过程中,虚假检测会被拒绝。最后,收集到的信息被融合到 3D 场景图中,并且该图根据新的观察结果进行更新。
本文的主要贡献如下。 1)我们定义了3D场景图的概念,它以准确、适用、可用和可扩展的方式表示环境。 2)我们设计了 3D 场景图构建框架,该框架在收到一系列观察结果后生成环境的 3D 场景图。 3)我们提供了 3-D 场景图的两个应用示例:a)VQA 和 b)任务规划。 4)我们进行了一系列彻底的实验,并对实验进行定量和定性分析,以验证3D场景图的性能。
整体系统架构

图2显示了所提出的3D场景图构建框架的总体系统架构。所提出的框架接收图像流并对输入图像进行预处理。在预处理步骤中,图像中的噪声被去除,并应用适当的缩放和裁剪。然后,预处理后的图像进入模糊图像剔除模块。模糊图像被拒绝,以保证后续模块的稳定性能。然后,姿态估计模块使用视觉里程计或 SLAM 提取附近帧之间的相对姿态。该模块中估计的姿势用于在以下模块中提取关键帧组和对象的物理特征。在此框架中,我们使用 ElasticFusion [3] 和 BundleFusion [8] 来估计姿势。接下来,关键帧组提取 (KGE) 模块将每个帧分类为关键帧、锚帧或垃圾帧,以提高效率。在 KGE 之后,框架仅处理合理重叠的帧。
提取的关键帧组经过region proposal和对象识别模块。region proposal模块检测对象实例的合理区域,并且对象识别模块对区域内的对象进行分类。具体来说,我们使用 Faster-RCNN [21] 来识别对象实例(region proposal)和对象类别(对象识别)。对象识别模块输出带有对象置信度分数的候选类别列表。在提取出具有相应类别的对象实例后,关系提取模块识别对象实例之间的成对关系。这些关系包括动作(例如,跳过)、空间(后面)和介词(例如,与)关系。可分解网络(F-Net)[17]被纳入所提出的关系提取过程框架中。
尽管识别模块遵循后处理程序,但在图像流上运行识别模块不可避免地会产生虚假检测。虚假检测拒绝 (SDR) 模块使用 3D 位置信息、word2vec [22] 的语义和规则库来消除虚假和重复检测。局部3D场景图构建模块接收处理后的检测结果,并为一个输入帧构建局部3D场景图。该局部 3-D 场景图仅覆盖一小部分物理空间,并且第一个局部 3-D 场景图成为初始全局 3-D 场景图。在全局3D场景图构建模块中,初始全局3D场景图在接收到从后续图像帧生成的局部3D场景图时被更新和扩展。
数据处理
在本节中,我们描述所提出的 3D 场景图构建框架的主要数据处理模块。本文提出的三个模块可以高效且有效地生成 3D 场景图。
自适应模糊图像抑制
为了稳定的性能,对象识别和关系提取模块需要干净且静止的图像作为输入。模糊的输入图像会降低性能,因为物体的形状、大小甚至颜色在模糊图像中显得不同。所提出的 3D 场景图构建框架的输入图像序列可能包含由于突然的相机运动而导致的模糊图像。为了防止图像模糊并保证识别模块的鲁棒性能,我们采用拉普拉斯方差定义为:
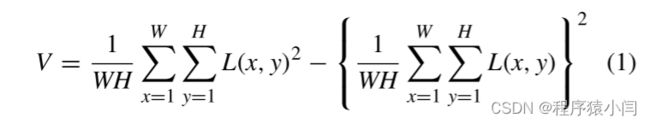
其中 W 和 H 分别表示图像的宽度和高度, 是拉普拉斯算子。拉普拉斯方差测量图像中像素之间的强度变化。通过过滤拉普拉斯方差小于阈值的图像,可以去除模糊图像。然而,固定阈值可以将具有低纹理的非模糊图像检测为模糊帧,因为低纹理图像的强度在像素之间没有显着变化。
是拉普拉斯算子。拉普拉斯方差测量图像中像素之间的强度变化。通过过滤拉普拉斯方差小于阈值的图像,可以去除模糊图像。然而,固定阈值可以将具有低纹理的非模糊图像检测为模糊帧,因为低纹理图像的强度在像素之间没有显着变化。
为了应对纹理变化的问题,我们提出了ABIR算法。首先,所提出的算法评估指数移动平均值 (EMA) ,拉普拉斯方差St为:

其中 t 是时间步长,Vt 是 t 处拉普拉斯算子的方差,α 是区间 [0, 1) 中的常数平滑因子。较低的 α 会更快地降低旧观测值的影响。在初始阶段,EMA 不遵循观测值,因为一开始只有少量观测值可用。这种现象称为偏差,我们按如下方式纠正偏差:

然后,我们修改偏差校正平均值![]() ,以生成自适应阈值 tblurry,如下所示:
,以生成自适应阈值 tblurry,如下所示:

其中 g 和 b 分别表示增益和偏移。
关键帧组提取
KGE模块1)接收预处理后的图像帧序列; 2)通过将输入帧分为三类来过滤掉不必要的帧; 3) 形成关键帧组。输入帧的三类如下:
1) 关键帧:关键帧作为参考。关键帧决定了第一个锚帧和关键帧组的覆盖范围。 2) 锚框:锚框要么是活动的,要么是非活动的。只有最新的锚帧才处于活动状态,并且活动的锚帧决定下一个锚帧。 3)垃圾帧:除了关键帧和锚帧之外的帧被归类为垃圾帧并因冗余而被丢弃。
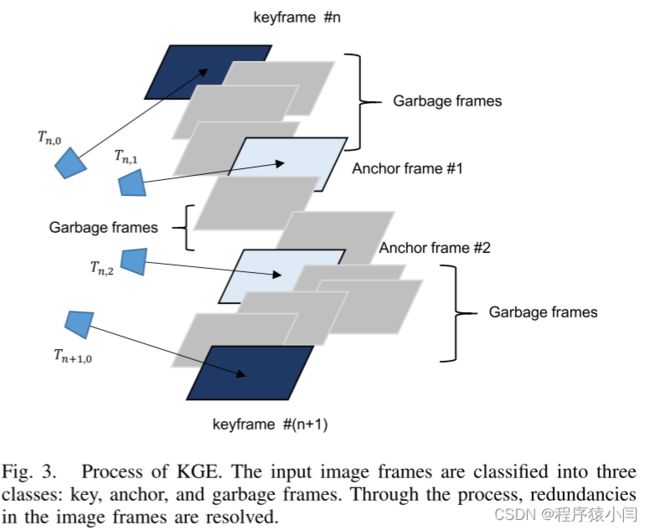

图3和算法1描述了KGE模块的流程。首先,该模块将第一个非模糊传入帧设置为第一个关键帧。其余的帧经历分类过程。每个传入帧都会与当前关键帧和活动锚帧进行比较。与活动锚帧重叠小于 tanchor % 的帧保留为下一个锚帧。为了提取第一个锚帧,将输入帧与关键帧进行比较。随着检测到新的锚帧,当前活动的锚帧变为不活动并且新的锚帧变为活动。如果传入帧与关键帧的重叠小于 tkeyframe %,则传入帧将成为新的关键帧,并且之前的关键帧和到目前为止检测到的锚帧形成关键帧组。我们将 tanchor 设置为大于 tkeyframe。
两帧之间的重叠是通过将一帧投影到另一帧的坐标来计算的,如下所示:
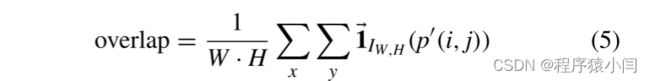
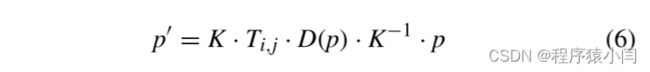
通过将关键帧和锚帧作为两个参考,所提出的 KGE 可以有效地处理连续图像序列中固有的冗余信息。此外,所提出的框架不会爆炸,即使当相机捕获长时间停留在同一点的输入帧时,也能有效地处理冗余。算法1的时间复杂度为O(NWH),其中N表示输入图像帧的数量。算法1中的单个while循环使得总时间复杂度为O(N·overlap)。overlap函数的时间复杂度为 O(WH),因为该函数在水平和垂直方向上进行迭代,如 (5) 所示,并且每次投影都需要恒定时间,如 (6) 所示。
SDR虚假检测
处理图像流不可避免地会产生错误的结果,因为识别模块无法实现完美的性能,并且传感设备捕获的图像帧会被噪声破坏。 SDR 的目的在于通过从其他知识库中提取人类知识和先验知识来消除虚假和重复检测。 SDR 适用于多个模块:region proposal、对象识别和关系提取模块。首先,SDR 删除region proposal模块提出的冗余对象区域。它利用流行的非极大值抑制(NMS)[23]来实现目标。对于物体识别模块,SDR模块去除不相关的物体。此外,SDR删除了预定义的不相关对象,例如道路、天空、建筑物和移动对象。这些对象不能存在于 3D 场景图的设置中。
对于关系提取模块,SDR 模块检查一个关键帧组中多个帧的对象对之间检测到的关系,并且最常出现的关系保留在图中。如果出现平局,则所有排名靠前的关系都会添加到图表中。然后,SDR 应用关系字典作为先验。关系字典存储对象对的关系统计数据。我们提前使用视觉基因组数据集[24]构建关系字典。我们收集对象对之间关系的统计数据,并将像素距离信息(dpixel)存储为高斯分布。
为了应用先验,SDR 收集相关对象对,搜索关系字典,并计算检测到的关系的概率。从图中删除概率低于阈值的关系。在计算概率时,我们利用对象之间的像素距离来过滤掉对象对之间的关系,而这些关系的距离是没有意义的。关系概率 Pr(r|dpixel) 同时考虑像素距离和频率,如下所示:
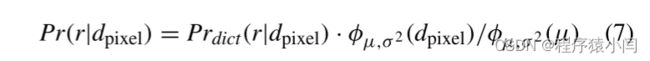
其中 Prdict(r|dpixel) 是视觉基因组数据集的统计数据,φμ,σ2 (k) = (1/ √ 2πσ2) exp(−[1/2]([k − μ]/σ)2) 是高斯函数。我们通过归一化概率密度函数来近似点之间距离的概率。
3D场景图构建
在本节中,我们定义了所提出的 3D 场景图及其属性。接下来,我们详细介绍3D场景图构建算法以及全局3D场景图的合并和更新算法。
图表示
3-D 场景图 G 定义一对集合 G = (V, E),其中 V 和 E 分别表示顶点和边的集合。一方面,顶点代表环境中存在的对象,每个顶点都包含有关它所代表的对象的信息。每个顶点包含的信息如下:
1) 标识号 (ID):分配给环境中每个对象的唯一编号。 2)语义标签:物体识别模块所分类的物体的类别。 3) 物理属性:物理特性,例如尺寸(高度和宽度)、主要颜色或相对于第一个关键帧的位置。 4) 视觉特征:缩略图、颜色直方图或带有描述符的提取视觉特征。
另一方面,下面列出了边可以代表的关系类型:
1) 动作:一个物体对另一个物体表现出的行为(例如,喂食)。 2)空间关系:空间关系,例如距离和相对位置(例如,在前面)。 3) 描述:一个对象与另一对象相关的状态(例如wear)。 4)介词:用介词表达的语义关系(例如with)。 5)比较:一个物体与另一个物体相比的相对属性(例如较小)。
由于给定一对对象,一个对象是主观的,另一个对象是客观的,因此 3D 场景图中的边是有向的(主观对象指向客观对象)。因此,3-D 场景图是有向图(或有向图)。
局部图构建
关系提取模块,所提出的3D场景图构建框架提取了部分对象属性和对象之间的关系,这可以形成输入帧的2D版本的场景图。在局部3D场景图构建模块中,2D属性被转换为3D属性并提取附加属性。为一个图像帧构建的局部 3-D 场景图在以下模块中合并并更新为全局 3-D 场景图。
对象的 ID 是临时分配的,稍后模块根据全局 3-D 场景图确定 ID。此外,前面的模块很容易为对象提供具有相应分数的候选语义标签。之后我们保留前 k 个标签和相关分数以进行相同的节点检测。另一方面,物体的 3D 位置表示为高斯分布,因为仅使用一个中心点来确定物体的位置很容易产生测量误差。将对象区域划分为 5 × 5 的子区域后,我们从region proposal模块给出的对象边界框中切出中心矩形。然后,中心矩形中每个点相对于第一个关键帧![]() 的 3-D 位置由下式评估:
的 3-D 位置由下式评估:

其中 i 和 o 分别表示当前帧和第一个关键帧的索引。然后,我们评估 3-D 位置 ∼ N(μ, σ2) 的高斯分布的均值 (μ) 和方差 (σ2)。在此过程中,我们假设每个维度 x、y 和 z 独立同分布,并保留用于评估的点数。
接下来,我们计算对象的颜色直方图 ![]() ,如下所示:
,如下所示:

其中(H,S,V)表示色彩空间的三个轴,N是像素数。据报道,(H,S,V)空间总体上表现出优于(R,G,B)空间的性能[25]。我们将颜色空间的每个轴数字化为 c-bin,使直方图的大小为 ![]() 。最后,边界框内的区域成为对象的缩略图。
。最后,边界框内的区域成为对象的缩略图。
此步骤中提取的属性由后续模块更新和修改,这些模块从多个帧中收集对象信息,然后做出最终决策。
图的合并和更新
图合并和更新过程将单个图像帧的各个3-D场景图合并为一个全局3-D场景图,并相应地更新全局3-D场景图的节点和边。随着摄像机视角和位置的变化,识别模块将从相同的物体中提取不同的信息。以下内容补偿了此类变化并为整个环境构建了全局 3D 场景图:
相同的节点检测
如果没有相同节点检测,3D 场景图将会因多次添加相同节点而爆炸,并且无法有效地集成对相同对象的多个观察。我们利用以下功能进行相同的节点检测:对象标签、3D 位置和颜色直方图。根据这些特征,评估标签相似度:

其中下标o和c分别指全局3D场景图中的原始节点和当前帧中的候选节点,Co和Cc包含对象的top-k标签,lo和lc是对象的标签得分最高的对象。当两个标签集共享相同元素时,公共元素的数量与分数相辅相成,否则分数会受到词向量之间的距离的惩罚。标签相似度的得分通过以下方式评估:
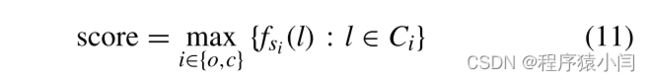
3D位置的相似度![]() :
:

色彩相似度:
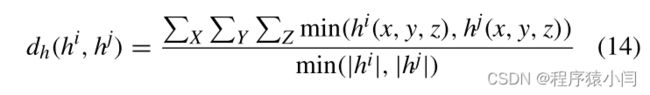

最后,融合三部分内容,判断最后相同节点的相似度。
合并和更新
由第一个关键帧构建的 3D 场景图形成了环境的初始全局 3D 场景图。接收到图像帧后,生成局部 3-D 场景图并将其合并到全局 3-D 场景图。合并过程将新构建的场景图中的节点与全局3D场景图中的节点进行比较并检测相同的节点。未包含在全局 3-D 场景图中的节点将添加到图中,并检测到相应的边和节点,因为相同的节点会更新全局图中的节点。更新过程如下。同一节点的标签集从Co∪Cc中选择得分最高的top-k标签。 3-D 位置现在考虑新采样的点并重新计算平均值和方差。颜色直方图与传入的颜色直方图相结合。节点中保留的点数变为原始点数加上新点数。如果最高分数的标签来自传入的场景图,则缩略图将替换为传入的缩略图。
应用:VQA和任务规划
所提出的 3D 场景图可以让智能体更深入地了解环境。因此,智能体可以以多种方式执行各种任务。此类任务包括 VQA、任务规划、3D 空间字幕、3D 环境模型生成和地点识别。我们在本节中说明 3D 场景图的两个主要应用。
VQA
通过提出问题并评估答复的答案,可以评估智能体对给定实体(例如图像或文本)的理解程度。在本文中,我们采用类似的问答(QA)方法来演示 3D 场景图在智能体环境理解中的性能,并提供 3D 场景图的主要应用之一。
与正在进行的 QA 方法研究相比,其中 QA 对以及要理解的实体作为训练数据集提供,此类 QA 数据集并未为 3D 场景图准备,因为该区域正处于开始阶段。因此,我们将问题类型限制如下:
1) 对象计数:可以是简单的(例如,环境中有多少个杯子?),也可以是分层的(例如,有多少件餐具?)。2)属性计数:具有特定属性的对象数量,例如大小、视觉特征和位置(例如,环境中有多少张红色椅子?)。 3)通过关系进行计数:与特定对象明显相关的对象数量(例如,架子上有多少对象?)。 4) 多模态 VQA:通过提供对象的缩略图来回答(例如,向我展示环境中最大的碗)。
即使通过采用一些 NLP 算法以自由形式和开放式方式提出问题,上面列出的问题也可以轻松转换为查询形式(机器可读形式)。智能体可以通过构建的 3D 场景图搜索所询问的实体来回答问题。许多图搜索算法都是现成的,包括深度优先搜索和广度优先搜索。
任务规划
机器人在实际执行任务之前计划如何执行给定的任务,这称为任务规划。在任务规划过程中,机器人利用收集到的环境信息生成原始动作序列以实现目标。环境信息包括环境中物体的位置、状态和属性。任务规划假设在开始生成行动计划之前已经给出了环境信息。因此,环境信息(3D 场景图的目的)在任务规划中起着核心作用。
实验
在本节中,我们首先关注准确性的验证,因为广泛使用且众所周知的图结构已经保证了可用性和可扩展性。接下来验证3D场景图的适用性。
性能验证
数据集
我们从 ScanNet 数据集中选择了一些序列 [28]。 ScanNet 由 1513 个序列组成,这些序列是使用一种 RGBD 传感器收集的。图像帧的分辨率为1269×968(彩色)和640×480(深度),帧速率为30 Hz,并且所有图像和深度帧都经过校准。还提供 RGB 和深度传感器的成像参数,成像环境的类别包括卧室、教室、办公室、公寓等。在过滤掉物体过少、覆盖范围窄或多个模糊图像的序列后,我们选择了具有挑战性的序列,序列长度为5578,客厅的序列号为0。
算法
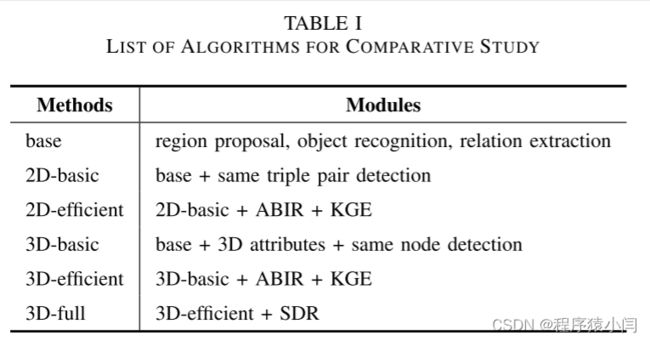
我们将 3D 场景图的质量与一些基线方法进行了比较。我们使用基本场景图生成算法(F-Net)[17]的扩展版本作为基线(见表一)。第一个基线计算每个图像帧的二维场景图,然后在删除相同的(主题、关系、对象)对后连接所有生成的图。第二条基线应用 ABIR 和 KGE 来提高效率。第三条基线为每个输入帧构建 3D 场景图,并使用所提出的相同节点检测来组合这些图。第四条基线建立在第三条基线的基础上,另外还采用了 ABIR 和 KGE 来提高效率。最后一个算法参考完整模型,即所提出的 3D 场景图构建框架,它将 SDR 添加到第四基线。