论文解读:Informer-AAAI2021年最佳论文
论文背景
应用背景
训练的是历史数据,但预测的是未来的数据,但是历史数据和未来数据的分布不一定是一样的,所以时间序列应用于股票预测往往不太稳定
动作预测:

基于之前的视频中每一帧动作,预测下一帧这个人要做什么动作;
流量预测:
网上购物:基于之前的流量预测出之后购买的流量应该有多少,好进行适当的补货
论文背景研究问题
拿过去20天的数据训练
1.短序列预测,则为预测未来2-3天的天气,这个比较好做;
3.精准长序列预测,则为预测10多天的天气,这个比较难做;甚至有可能拿过去半年的数据来预测未来半年的数据
解释为什么长序列预测难


传统时间序列经典算法
Prophet:非常实用的工具包,适合预测趋势,但不算精准
Arima:老牌算法了,短序列预测还算精准,但是趋势预测不准
但是一旦涉及到长序列,他俩可能就都不行了
Informer中将主要致力于长序列问题的解决,而且还可以多标签输出(即天气预测,不仅预测天气,还可以预测湿度,降雨量等)
传统办法LSTM的问题

预测是串行的,必须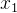 预测完才到
预测完才到
而且反向传播也得逐个逐个传,对模型训练更难了
在长序列预测中,如果序列越长,那速度肯定越慢,效果也越差(现存问题,即要解决的问题)

informer算法的核心思想

Transformer架构的优势与问题
1.万能模型,直接套用,代码实现简单,现成例子一大片
2.并行的,比LSTM快,全局信息丰富,注意力机制效果好
3.长序列中attention需要每一个点跟其他点计算(如果序列太长,效率很低),计算效率跟序列长度呈 的关系
的关系
4.Decoder输出挺墨迹的,要基于上一个预测结果来推断当前的预测结果;所以informer对encoder也进行了一些调整,对48天的数据同时输出(而不是预测了第一天之后,再根据预测第一天的结果推测第二天)。
要解决的三大问题,即论文的三大核心模块

Attention计算
左下角的图的值是Q与K内积的值,越往0代表关系越不大(Q与K接近垂直),越往1代表关系越大(Q与K将近同一条线上)
在长序列中,每一个位置的attention都很重要吗
对于每一个Q来说,只有一小部分的K是其它有较强关系

长序列中要不要进行采样呢?
群众里有坏人(有偷懒不干活的Q)
出于计算效率的考虑,那我们只需要关心有得分值大的那一小部分那些。

如何定义每一个Q是不是偷懒的
偷懒的Q感觉就像是均匀分布,没啥特点,你有我有全都有
Active的Q明显在某些位置比较活跃,权重差异较大
对于每一个Q,计算其与均匀分布的差异,差异越大则表示其越活越
论文给出的公式,没看懂┭┮﹏┭┮:

ProbAttention计算方法
挑出重要的Q
输入序列长度为96,现在要选出来的是一些重要的Q,正常情况需每一个Q跟全部(96)个K计算
这里为了节省计算量,重要的Q不用非得计算那么多,跟部分K计算的结果也可以当作其分布;即重要的Q跟一部分K做计算后应该也要能看出来它是重要的,而不需要跟全部的K去做计算。
所以在K中进行采样,随机选25个K,于是让Q跟25个K作计算。
例如源码输出结果:32, 8, 96, 25表示:32个batch,8头,96个Q分别跟25个K计算的内积。
现在每一个Q有25个得分(分别跟25个K计算后得到的),该例中![]()
论文中做法比较绝,为了进一步加速,直接选最大值与均匀分布算差异

之后按差异进行排序,在96个Q中,选出来差异前(即差异最大)的25个Q(根据序列长度来定的一个参数值)


如何更新不重要的Q
在算内积时,Q*K内积为:32, 8, 25, 96,就是只选了25个Q,但K还是96个(并不是只用随机选择的25个)
那么其它位置的Q该咋办呢?它没有参与计算其attention目前
出于节省计算量,直接用V(96个,表示每一个位置的特征)的均值来替代
也就是选出来的25个Q会更新,其他剩余的都是均值向量
Self-attention Distilling计算方法
传统transformer就是多次重复的self-attention堆叠。
这里与传统transformer不同,做完一次attention之后还要继续堆叠,只不过会96的输入序列(指96个Q、K、V)先通过1D的maxpool操作来进行下采样,下次attention的输入序列就为48了。此时Q和K的采样由于序列长度变小,也会随之变小,例如由25->20,为了去掉比较"懒"的Q。
重复堆叠多次就是Informer的Encoder架构了。

做完maxpool操作又会把比较懒、不去起作用的Q过滤掉。
Encoder改进后的效果
一方面就是速度快效率高了,论文中计算复杂度由![]()
下采样之后,特征更明显,且跟之前的特征的分布基本一致

关于Decoder的设计
传统Decoder输出
先输出第一个,在基于第一个输出第二个,以此类推

Start标志位
要让Decoder输出预测结果,你得先告诉它从哪开始输出。
先给一个引导,比如要输出20-30号的预测结果,Decoder中需先给出前面一个已知的序列结果,例如10-20号的标签值(下图 是待预测结果,
是待预测结果,![]() 是已知结果)。
是已知结果)。

从源码角度来看
源码中decoder输入长度为72,其中前48是真实值,后24是预测值

第一步还是做自身的ProbAttention
注意这回需要加上mask,mask的意思就是前面的不能看到后面的(不能透题)
自身计算完self-attention,再算与encoder的cross-attention即可
mask值举例
这里mask=1是我要的,mask=0是我要剔除的。

预测天气5应该只能用到1-4天的信息,而不能利用后面6-7天的信息
预测天气6应该只能用到1-5天的信息,而不能利用后面7-8天的信息
预测天气7应该可以用到前面1-6天的信息
位置编码信息
位置信息变得更加丰富了
不仅有绝对位置编码Local Time Stamp
还包括了跟时间相关的各种编码Global Time Stamp
Encoder与Decoder都加入了这些位置编码

节假日有可能对一些时间序列预测有关,比如说车流量,某旅游地的流量,明显会在节假日有所提高,当然,节假日对天气的预测似乎没什么关系,这里的位置编码更多的知识一种思路,希望我们读者在自己的任务中引入一些跟时间密切相关的编码。
整体网络架构
主要改进就是编码和解码器的优化,速度更快,解决长序列问题
需要注意的是:最终通过Outputs来同时预测几天的结果,而不是像传统算法那样预测一天后再预测下一天。

参考资料
论文下载
https://arxiv.org/abs/2012.07436
Informer Beyond Efficient Transformer for Long Sequence.pdf

代码地址
GitHub - zhouhaoyi/Informer2020: The GitHub repository for the paper "Informer" accepted by AAAI 2021.