LLM之RAG实战(六)| 高级RAG 02:选择最佳embedding和重排序模型

在构建检索增强生成(RAG)Pipeline时,一个关键组件是Retriever。我们有多种embedding模型可供选择,包括OpenAI、CohereAI和开源sentence transformers。此外,CohereAI和sentence transformers还提供了几个重排序器。
但是,有了所有这些选项,我们如何确定最佳组合以获得一流的检索性能?我们如何知道哪种embedding模型最适合我们的数据?或者哪种重新排序对我们的结果提升最大?
在这篇博客文章中,我们将使用LlamaIndex的Retrieval Evaluation模块来快速确定embedding和重排序模型的最佳组合。让我们一起来了解一下吧!
让我们首先了解Retrieval Evaluation中可用的评估指标!
一、理解Retrieval Evaluation中的评估指标:
为了衡量我们的检索系统的有效性,我们选择被广泛接受的两个指标:Hit Rate和 Mean Reciprocal Rank (MRR)。让我们深入研究这些指标,以了解它们的重要性以及它们是如何运作的。
命中率(Hit Rate):
命中率计算在前k个检索到的文档中找到正确答案的查询的百分比。简单地说,这是关于我们的系统在前几次猜测中正确的频率。
平均倒数排名(MRR):
对于每个查询,MRR通过查看排名最高的相关文档的排名来评估系统的准确性。具体来说,它是所有查询中这些排名的倒数的平均值。因此,如果第一个相关文档是最高结果,则倒数为1;如果是第二个,则倒数为1/2,依此类推。
既然我们已经确定了评估指标,现在是时候开始实验了。
二、设置环境
!pip install llama-index sentence-transformers cohere anthropic voyageai protobuf pypdf三、设置Key
openai_api_key = 'YOUR OPENAI API KEY'cohere_api_key = 'YOUR COHEREAI API KEY'anthropic_api_key = 'YOUR ANTHROPIC API KEY'openai.api_key = openai_api_key
四、下载数据
!wget --user-agent "Mozilla" "https://arxiv.org/pdf/2307.09288.pdf" -O "llama2.pdf"五、加载数据
让我们加载数据。我们前36页来进行实验,不包括目录、参考文献和附录。
然后将这些数据转换为节点进行解析,这些节点表示我们想要检索的数据块。我们设置chunk_size为512。
documents = SimpleDirectoryReader(input_files=["llama2.pdf"]).load_data()node_parser = SimpleNodeParser.from_defaults(chunk_size=512)nodes = node_parser.get_nodes_from_documents(documents)
六、生成问题上下文对
为了评估,我们创建了一个问题上下文对数据集,该数据集包括一系列问题及其相应的上下文。为了消除embedding(OpenAI/CohereAI)和重排序(CohereAI)评估的偏差,我们使用Anthropic LLM生成问题上下文对。
让我们初始化一个Prompt模板来生成问题上下文对。
# Prompt to generate questionsqa_generate_prompt_tmpl = """\Context information is below.---------------------{context_str}---------------------Given the context information and not prior knowledge.generate only questions based on the below query.You are a Professor. Your task is to setup \{num_questions_per_chunk} questions for an upcoming \quiz/examination. The questions should be diverse in nature \across the document. The questions should not contain options, not start with Q1/ Q2. \Restrict the questions to the context information provided.\"""
llm = Anthropic(api_key=anthropic_api_key)qa_dataset = generate_question_context_pairs(nodes, llm=llm, num_questions_per_chunk=2)
过滤句子的函数,例如——以下是基于所提供上下文的两个问题
# function to clean the datasetdef filter_qa_dataset(qa_dataset):"""Filters out queries from the qa_dataset that contain certain phrases and the correspondingentries in the relevant_docs, and creates a new EmbeddingQAFinetuneDataset object withthe filtered data.:param qa_dataset: An object that has 'queries', 'corpus', and 'relevant_docs' attributes.:return: An EmbeddingQAFinetuneDataset object with the filtered queries, corpus and relevant_docs."""# Extract keys from queries and relevant_docs that need to be removedqueries_relevant_docs_keys_to_remove = {k for k, v in qa_dataset.queries.items()if 'Here are 2' in v or 'Here are two' in v}# Filter queries and relevant_docs using dictionary comprehensionsfiltered_queries = {k: v for k, v in qa_dataset.queries.items()if k not in queries_relevant_docs_keys_to_remove}filtered_relevant_docs = {k: v for k, v in qa_dataset.relevant_docs.items()if k not in queries_relevant_docs_keys_to_remove}# Create a new instance of EmbeddingQAFinetuneDataset with the filtered datareturn EmbeddingQAFinetuneDataset(queries=filtered_queries,corpus=qa_dataset.corpus,relevant_docs=filtered_relevant_docs)# filter out pairs with phrases `Here are 2 questions based on provided context`qa_dataset = filter_qa_dataset(qa_dataset)
七、自定义检索器
为了寻找最优检索器,我们采用embedding模型和重排序器的组合。最初,我们建立了一个基本的VectorIndexRetriever。在检索节点后,我们引入一个重排序器来进一步细化结果。值得注意的是,对于这个特定的实验,我们将similarity_top_k设置为10,并用reranker选择了前5名。但是,您可以根据具体实验的需要随意调整此参数。我们在这里展示了OpenAIEmbedding的代码,其他embedding代码请参阅笔记本(https://colab.research.google.com/drive/1TxDVA__uimVPOJiMEQgP5fwHiqgKqm4-?usp=sharing)。
embed_model = OpenAIEmbedding()service_context = ServiceContext.from_defaults(llm=None, embed_model = embed_model)vector_index = VectorStoreIndex(nodes, service_context=service_context)vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k = 10)
class CustomRetriever(BaseRetriever):"" "Custom retriever that performs both Vector search and Knowledge Graph search"""def __init__(self,vector_retriever: VectorIndexRetriever,) -> None:"""Init params."""self._vector_retriever = vector_retrieverdef _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:"""Retrieve nodes given query."""retrieved_nodes = self._vector_retriever.retrieve(query_bundle)if reranker != 'None':retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)else:retrieved_nodes = retrieved_nodes[:5]return retrieved_nodesasync def _aretrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:"""Asynchronously retrieve nodes given query.Implemented by the user."""return self._retrieve(query_bundle)async def aretrieve(self, str_or_query_bundle: QueryType) -> List[NodeWithScore]:if isinstance(str_or_query_bundle, str):str_or_query_bundle = QueryBundle(str_or_query_bundle)return await self._aretrieve(str_or_query_bundle)custom_retriever = CustomRetriever(vector_retriever)
八、评估
为了评估我们的检索器,我们计算了平均倒数排名(MRR)和命中率指标:
retriever_evaluator = RetrieverEvaluator.from_metric_names(["mrr", "hit_rate"], retriever=custom_retriever)eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)
九、结果
我们对各种嵌入模型和重新排序进行了测试。以下是我们考虑的模型:
- embedding模型:
- OpenAI Embedding
- Voyage Embedding
- CohereAI Embedding (v2.0/ v3.0)
- Jina Embeddings (small/ base)
- BAAI/bge-large-en
- Google PaLM Embedding
重排序模型:
- CohereAI
- bge-reranker-base
- bge-reranker-large
下表显示了基于命中率和平均倒数排名(MRR)指标的评估结果:
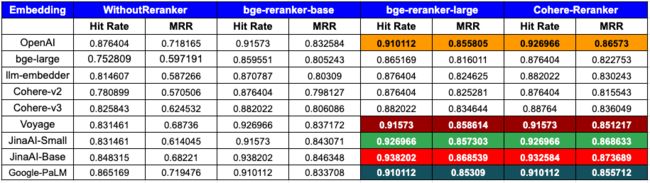
10、分析
embedding性能:
- OpenAI:展示顶级性能,尤其是CohereRerank(0.926966命中率,0.86573 MRR)和bge-reranker-large(0.910112命中率,0.8 55805 MRR),表明与重排序工具有很强的兼容性。
- bge-large:使用重排序时效果显著改进,CohereRerank的结果最好(0.876404命中率,0.822753 MRR)。
- llm-embedder:从重排序中受益匪浅,特别是使用CohereRebank(0.882022命中率,0.830243 MRR),性能提升显著。
- Cohere:Cohere最新的v3.0 embedding模型优于v2.0,并且通过集成原生CohereRebank,显著提高了其指标,有0.88764的命中率和0.836049的MRR。
- Voyage:具有强大的初始性能,CohereRerank进一步放大了这一性能(0.91573命中率,0.851217 MRR),表明对重排列的响应性很高。
- JinaAI:表现非常强劲,bge-reranker-large(0.938202命中率,0.868539 MRR)和CohereRerank(0.932584命中率,0.8 73689)涨幅显著,表明重新评级显著提升了其表现。
- Google-PaLM:该模型表现出强大的性能,在使用CohereRebank时有可测量的增益(0.910112命中率,0.855712 MRR)。这表明,重排序明显提升了其整体性能。
重排序的影响:
- WithoutReranker:这为每个embedding提供了baseline性能。
- bge-reranker-base:通常可以提高embedding的命中率和MRR。
- bge-reranker-large:这个reranker经常为embedding提供最高或接近最高的MRR。对于几种embedding,其性能可以与CohereRebank相媲美或超越。
- CohereRerank:持续提高所有embedding的性能,通常提供最佳或接近最佳的结果。
重排序的必要性:
- 上述实验表明了重排序在细化搜索结果方面的重要性。几乎所有embedding都受益于重新排序,其可以提高命中率和MRR。
- Reranker,尤其是CohereRerank,已经证明了他们可以提高任何embedding能力。
总体优势:
- 当同时考虑命中率和MRR时,OpenAI+CohereRebank和JinaAI Base+bge-reranker-large/CohereRebank的组合成为顶级竞争者。
- 然而,CohereRerank/bge-reranker在各种embedding中都可以一致性改进增强搜索的质量,适用于何种embedding。
总之,为了在命中率和MRR方面实现峰值性能,OpenAI或JinaAI Base嵌入与CohereRerank/bge重ranker大型重ranker的组合脱颖而出。
11、结论:
在这篇博客文章中,我们展示了如何使用各种embedding和重排序来评估和增强检索器的性能。以下是我们的最终结论。
- Embeddings:OpenAI和JinaAI-Base embedding,尤其是与CohereRerank/bge-reranker-large reranker配对时,为命中率和MRR设定了黄金标准。
- Rerankers:重新排序的影响,特别是CohereRerank/bge-reranker-large 重新排序,怎么强调都不为过。它们在改善许多embedding的MRR方面发挥着关键作用,表明了它们在改善搜索结果方面的重要性。
- Foundation is Key:为初始搜索选择正确的embedding至关重要;如果基本搜索结果不好,即使是最好的重新排序也无济于事。
- Working Together:为了让检索器发挥出最大的作用,找到embedding和重新排序的正确组合是很重要的。这项研究表明,仔细测试并找到最佳配对是多么重要。
参考文献:
[1] https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83
[2] https://colab.research.google.com/drive/1TxDVA__uimVPOJiMEQgP5fwHiqgKqm4-?usp=sharing