python文本分类算法_基于Naive Bayes算法的文本分类
理论

什么是朴素贝叶斯算法?
朴素贝叶斯分类器是一种基于贝叶斯定理的弱分类器,所有朴素贝叶斯分类器都假定样本每个特征与其他特征都不相关。举个例子,如果一种水果其具有红,圆,直径大概3英寸等特征,该水果可以被判定为是苹果。尽管这些特征相互依赖或者有些特征由其他特征决定,然而朴素贝叶斯分类器认为这些属性在判定该水果是否为苹果的概率分布上独立的。
朴素贝叶斯分类器很容易建立,特别适合用于大型数据集,众所周知,这是一种胜过许多复杂算法的高效分类方法。
贝叶斯公式提供了计算后验概率P(X|Y)的方式:

其中,
P(c|x)是已知某样本(c,目标),(x,属性)的概率。称后验概率。
P(c)是该样本“c”的概率。称先验概率。
P(x|c)是已知该样本“x”,该样本“c”的概率。
P(x)是该样本“x”的概率。
朴素贝叶斯算法的分类流程
举一个例子。下面设计了一个天气和响应目标变量“玩”的训练数据集(计算“玩”的可能性)。我们需要根据天气条件进行分类,判断这个人能不能出去玩,以下是步骤:
步骤1:将数据集转换成频率表;
步骤2:计算不同天气出去玩的概率,并创建似然表,如阴天的概率是0.29;

步骤3:使用贝叶斯公式计算每一类的后验概率,数据最高那栏就是预测的结果。
问题:如果是晴天,这个人就能出去玩。这个说法是不是正确的?
P(是|晴朗)=P(晴朗|是)×P(是)/P(晴朗)
在这里,P(晴朗|是)= 3/9 = 0.33,P(晴朗)= 5/14 = 0.36,P(是)= 9/14 = 0.64
现在,P(是|晴朗)=0.33×0.64/0.36=0.60,具有较高的概率。
朴素贝叶斯适合预测基于各属性的不同类的概率,因此在文本分类上有广泛应用。
朴素贝叶斯的优缺点
优点:
既简单又快速,预测表现良好;
如果变量独立这个条件成立,相比Logistic回归等其他分类方法,朴素贝叶斯分类器性能更优,且只需少量训练数据;
相较于数值变量,朴素贝叶斯分类器在多个分类变量的情况下表现更好。若是数值变量,需要正态分布假设。
缺点:
如果分类变量的类别(测试数据集)没有在训练数据集总被观察到,那这个模型会分配一个0(零)概率给它,同时也会无法进行预测。这通常被称为“零频率”。为了解决这个问题,我们可以使用平滑技术,拉普拉斯估计是其中最基础的技术。
朴素贝叶斯也被称为bad estimator,所以它的概率输出predict_proba不应被太认真对待。
朴素贝叶斯的另一个限制是独立预测的假设。在现实生活中,这几乎是不可能的,各变量间或多或少都会存在相互影响。
朴素贝叶斯的4种应用
实时预测:毫无疑问,朴素贝叶斯很快。
多类预测:这个算法以多类别预测功能闻名,因此可以用来预测多类目标变量的概率。
文本分类/垃圾邮件过滤/情感分析:相比较其他算法,朴素贝叶斯的应用主要集中在文本分类(变量类型多,且更独立),具有较高的成功率。因此被广泛应用于垃圾邮件过滤(识别垃圾邮件)和情感分析(在社交媒体平台分辨积极情绪和消极情绪的用户)。
推荐系统:朴素贝叶斯分类器和协同过滤结合使用可以过滤出用户想看到的和不想看到的东西。
关于朴素贝叶斯分类器的几个黑科技
以下是一些小方法,可以提升朴素贝叶斯分类器的性能:
如果连续特征不是正态分布的,我们应该使用各种不同的方法将其转换正态分布。
如果测试数据集具有“零频率”的问题,应用平滑技术“拉普拉斯估计”修正数据集。
删除重复出现的高度相关的特征,可能会丢失频率信息,影响效果。
朴素贝叶斯分类在参数调整上选择有限。我建议把重点放在数据的预处理和特征选择。
大家可能想应用一些分类组合技术 如ensembling、bagging和boosting,但这些方法都于事无补。因为它们的目的是为了减少差异,朴素贝叶斯没有需要最小化的差异。
如何建立朴素贝叶斯的基本模型(Python和R)
scikit learn里有3种朴素贝叶斯的模型:
高斯模型:适用于多个类型变量,假设特征符合高斯分布。
多项式模型:用于离散计数。如一个句子中某个词语重复出现,我们视它们每个都是独立的,所以统计多次,概率指数上出现了次方。
伯努利模型:如果特征向量是二进制(即0和1),那这个模型是非常有用的。不同于多项式,伯努利把出现多次的词语视为只出现一次,更加简单方便。
你可以根据特定数据集选取上述3个模型中的合适模型。下面我们以高斯模型为例,谈谈怎么建立:
Python
#Import Library of Gaussian Naive Bayes model
from sklearn.naive_bayes import GaussianNB
import numpy as np
#assigning predictor and target variables
x= np.array([[-3,7],[1,5], [1,2], [-2,0], [2,3], [-4,0], [-1,1], [1,1], [-2,2], [2,7], [-4,1], [-2,7]])
Y = np.array([3, 3, 3, 3, 4, 3, 3, 4, 3, 4, 4, 4])
#Create a Gaussian Classifier
model = GaussianNB()
# Train the model using the training sets
model.fit(x, y)
#Predict Output
predicted= model.predict([[1,2],[3,4]])
print predicted
Output: ([3,4])
R
require(e1071) #Holds the Naive Bayes Classifier
Train
Test
#Make sure the target variable is of a two-class classification problem only
levels(Train$Item_Fat_Content)
model
class(model)
pred
table(pred)
文本分类的主要流程
样本数据的获取
样本数据清洗和分词
建模与评估
部署运行
R实现
完整代码及报告见另一篇博文
分词
一个好用的包:chinese.misc。说明文档:https://github.com/githubwwwjjj/chinese.misc
应用示例:
library(jiebaRD)
library(NLP)
library(chinese.misc)
library(jiebaR)
library(tm)
library(MASS)
library(klaR)
library(e1071)
##样本数据
textData
textData$NewsContent
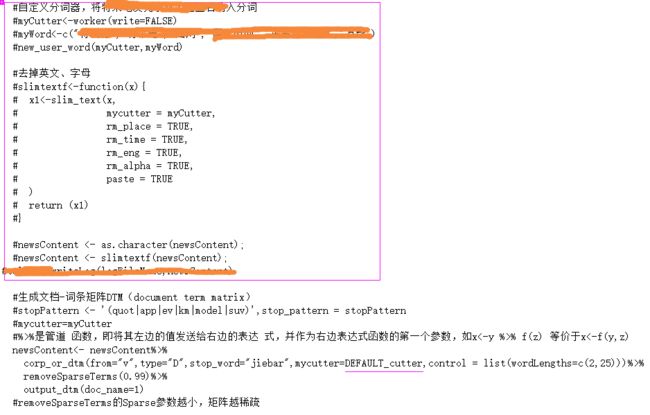
#自定义分词器,将需要特殊识别的纳入分词
myCutter
myWord
new_user_word(myCutter,myWord)
#去掉英文、字母
slimtextf
x1
mycutter = myCutter,
rm_place = TRUE,
rm_time = TRUE,
rm_eng = TRUE,
rm_alpha = TRUE,
paste = TRUE
)
return (x1)
}
textData$NewsContent
textData$TFlag
textData.Train
textData.Test
dim(textData.Train )
dim(textData.Test)
head(textData.Train)
#生成文档-词条矩阵DTM(document term matrix)
#stopPattern
#%>%是管道 函数,即将其左边的值发送给右边的表达 式,并作为右边表达式函数的第一个参数,如x% f(z) 等价于x
dtm.train%
corp_or_dtm(from="v",type="D",stop_word="jiebar",mycutter=myCutter,control = list(wordLengths=c(2,25)))%>%
removeSparseTerms(0.99)%>%
output_dtm(doc_name=textData.Train$SN)
#removeSparseTerms的Sparse参数越小,矩阵越稀疏
dim(dtm.train)# 737 382
#write.csv(dtm.train,'dtm.train10.csv')
dtm.test%
corp_or_dtm(from="v",type="D",stop_word="jiebar",mycutter=myCutter,control = list(wordLengths=c(2,25)))%>%
removeSparseTerms(0.99)%>%
output_dtm(doc_name=textData.Test$SN)
dim(dtm.test)# 334 386
建模
有两个包可用: e1071和klaR
e1071示例:
#训练朴素贝叶斯模型
model
#预测测试集
pre
#pre
#默认值type = c("class", "raw")
klaR示例:在建模时报错,后带分析说明
#训练朴素贝叶斯模型
model
#报错:Zero variances for at least one class in variables: 保时捷, 比亚迪, 戴姆勒, 环保, 混合, 集团, 加快, 开发......
#预测测试集
pre
报错:Zero variances for at least one class in variables: 保时捷, 比亚迪, 戴姆勒, 环保, 混合, 集团, 加快, 开发.....
错误原因:存在0方差的变量
错误信息对应的源码:

解决方案:如果一定要使用这个包,那就修改源码,把stop代码干掉,让它继续执行。然后自己编译这个包。
评估
在应用案例中采用了10折交叉验证,执行10次取均值。
相关指标的说明见https://www.cnblogs.com/xianhan/p/9277194.html
#性能评价
performance
performance
#准确率:4和5预测正确的比例**
accuracyrate
accuracyrate # 0.5174603->0.5434783
#灵敏度(查全率\召回率):实际5,其中预测正确的比例*****
sensitivity
sensitivity #0.8791209->0.816092
#精密性:预测5,其中预测正确的比例**
precision
precision # 0.361991-> 0.3514851
#特异性:实际4,其中预测正确的比例*
specificity
specificity #0.3705357->0.4425532
20180731后续:
该服务发布上线后,每次调用耗时2-4s不等,超过系统设置的超时阈值而频繁报警。经过分析,是自定义分词器耗时2-3s,将自定义分词器去掉后,耗时50-80ms。
参考
中文文本分析方便工具R包chinese.misc的中文说明
https://github.com/githubwwwjjj/chinese.misc
R语言-贝叶斯分类器-文本情感分析
https://zhuanlan.zhihu.com/p/26735328
R实战——大众点评-汉拿山(深国投店)评论情感浅析
https://mp.weixin.qq.com/s?__biz=MzUyNzU3MTgyOA==&mid=2247483690&idx=1&sn=9b8ea4b159e5885c0b99f3529a25c488&chksm=fa7ccf31cd0b4627d8f7321a392036686c1f59a0e365b3976c8ba4810a407f46b53cff4e63f0#rd